
Table Of Content

Qwen3.5 Omni Plus World Premiere: What You Need to Know
Qwen Model Recommender
Not sure which Qwen model fits your GPU? Pick your VRAM, use case, and task type — get matched to the right model instantly. Covers Qwen3, QwQ, QVQ, Qwen2.5-VL, Qwen3-Coder, Qwen3-TTS, and 80+ models.
Table Of Content
Qwen 3.5 Omni Plus is a brand new multimodal model from Alibaba. It reads text, sees images, understands audio, watches video, and can write games. I ran it through audio transcription, document understanding, multilingual translation, and what I call audio visual web coding.
If you want a broader view of what the Qwen 3.5 line can do across media and code, see this overview of multimodal tasks in the Qwen family: Qwen 3.5 for AI video, image, code, and text.
Qwen 3.5 Omni Plus felt noticeably quicker than earlier Qwen releases in the same class. In side-by-side use, it was faster than the previous Qwen 3.5 Plus model. That speedup shows up most in long audio processing and structured document parsing.
Coding from an image
I gave it an image of a Flappy Bird game and asked for a fully playable, self-contained single HTML file clone from scratch. The model produced clean, well-formatted code, and the game worked on the first try. This is the exact prompt I used:

Build me a fully playable self-contained single HTML file clone of this game from scratch based on the provided image. The file must include HTML, CSS, and JavaScript in one document with no external dependencies.Step-by-step
Provide a clear screenshot of the target game with all UI elements visible.

Send the prompt above along with the image.
Save the returned output as index.html and open it in your browser.
If you plan to customize or adapt the code for your own workflows, you can fine-tune Qwen 3.5 8B locally for domain-specific web coding patterns.
Audio transcription and analysis
I uploaded a 3-minute audio in my voice and asked for a detailed description, a chronological storyline of everything heard, timestamps, speaker identification, and emotional tone. The output was millisecond-accurate, with correct speaker profiling including age, accent, Hertz range, WPM, and per-segment prosody tags. It also added environmental and microphone analysis unprompted, and the semantic understanding of the content was strong.
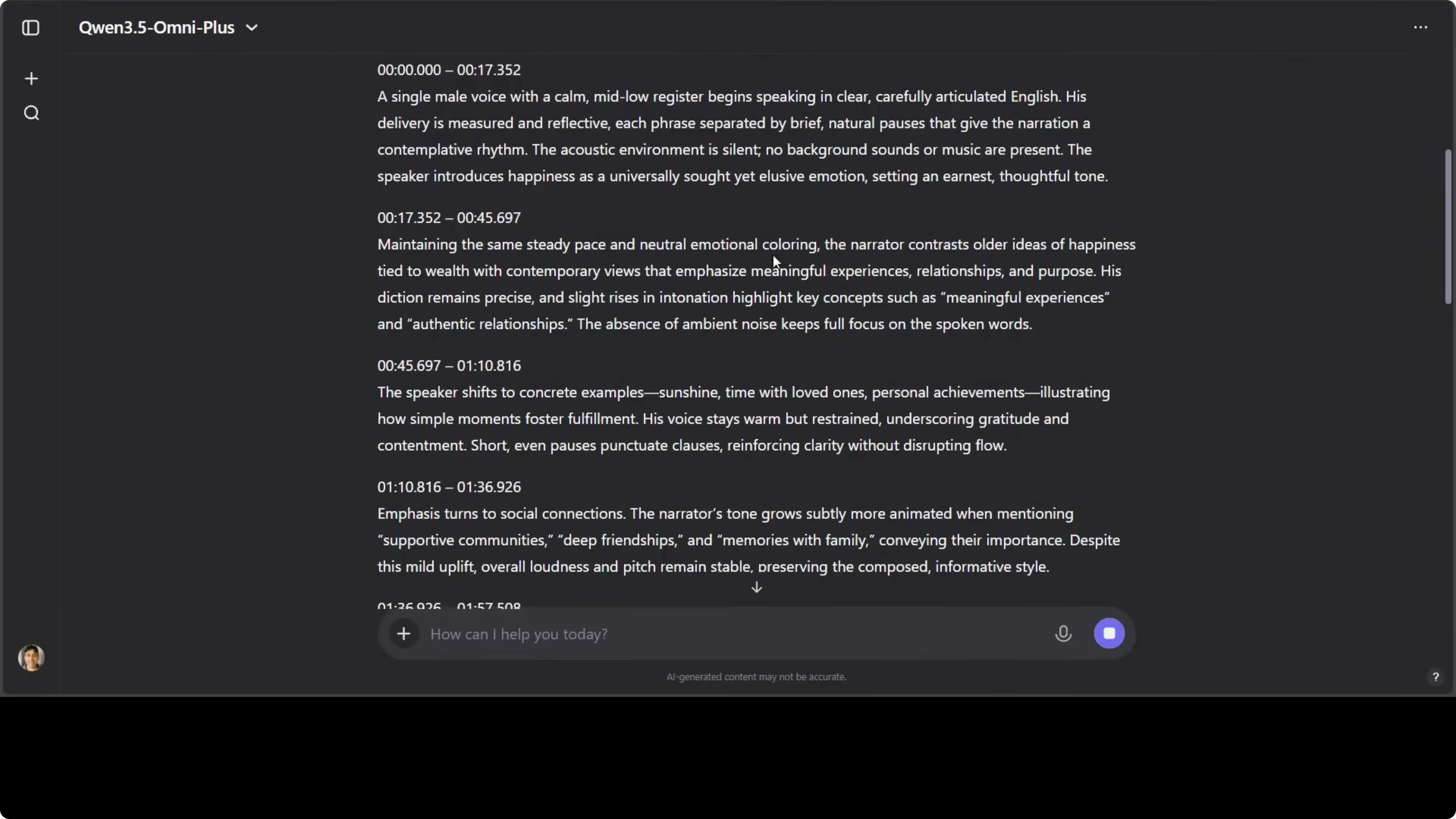
The technical side is excellent. Timestamps align tightly with speech, and speaker metadata is consistent. This precision goes beyond what most models currently output.
Multilingual translation
I asked the model to translate a short audio clip saying “What is happiness?” into around 52 to 55 world languages. As far as I can tell, the translations are strong, with some literal variations for regional and low-resource languages. Overall quality is high for quick multilingual coverage.
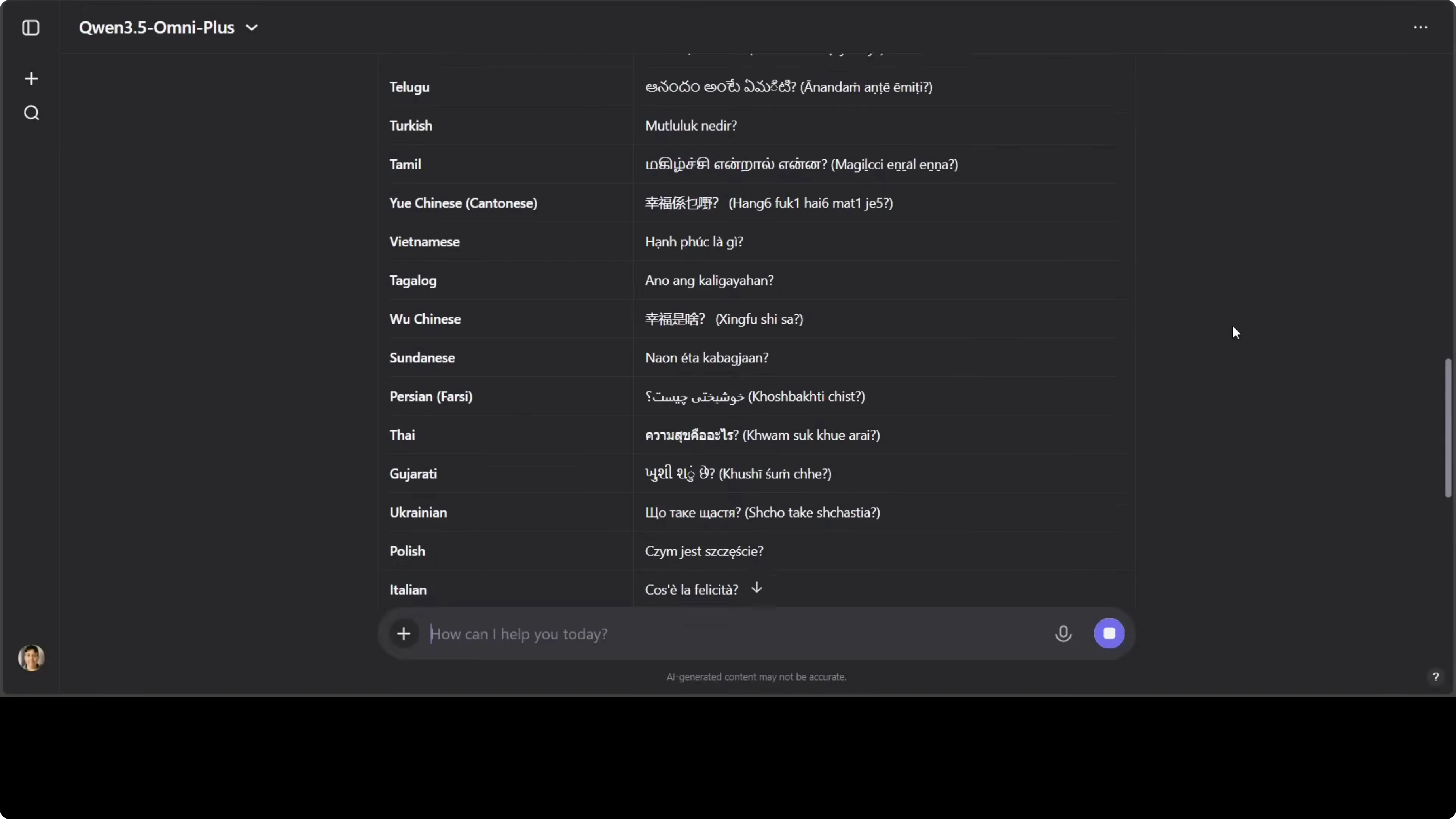
If you are exploring smaller deployments for translation and on-device inference, the compact Qwen 3.5 2B variant is a practical option.
Document OCR and structure
I tested OCR on an old archive newspaper scan from the New Zealand Herald that covered a cyclone in the 1970s affecting Darwin in Australia’s Northern Territory. The model correctly identified headers, contact numbers, ads, the main headline, subsections, and photo captions, and it extracted a lot of body text. It also produced a concise one-paragraph summary that read cleanly.
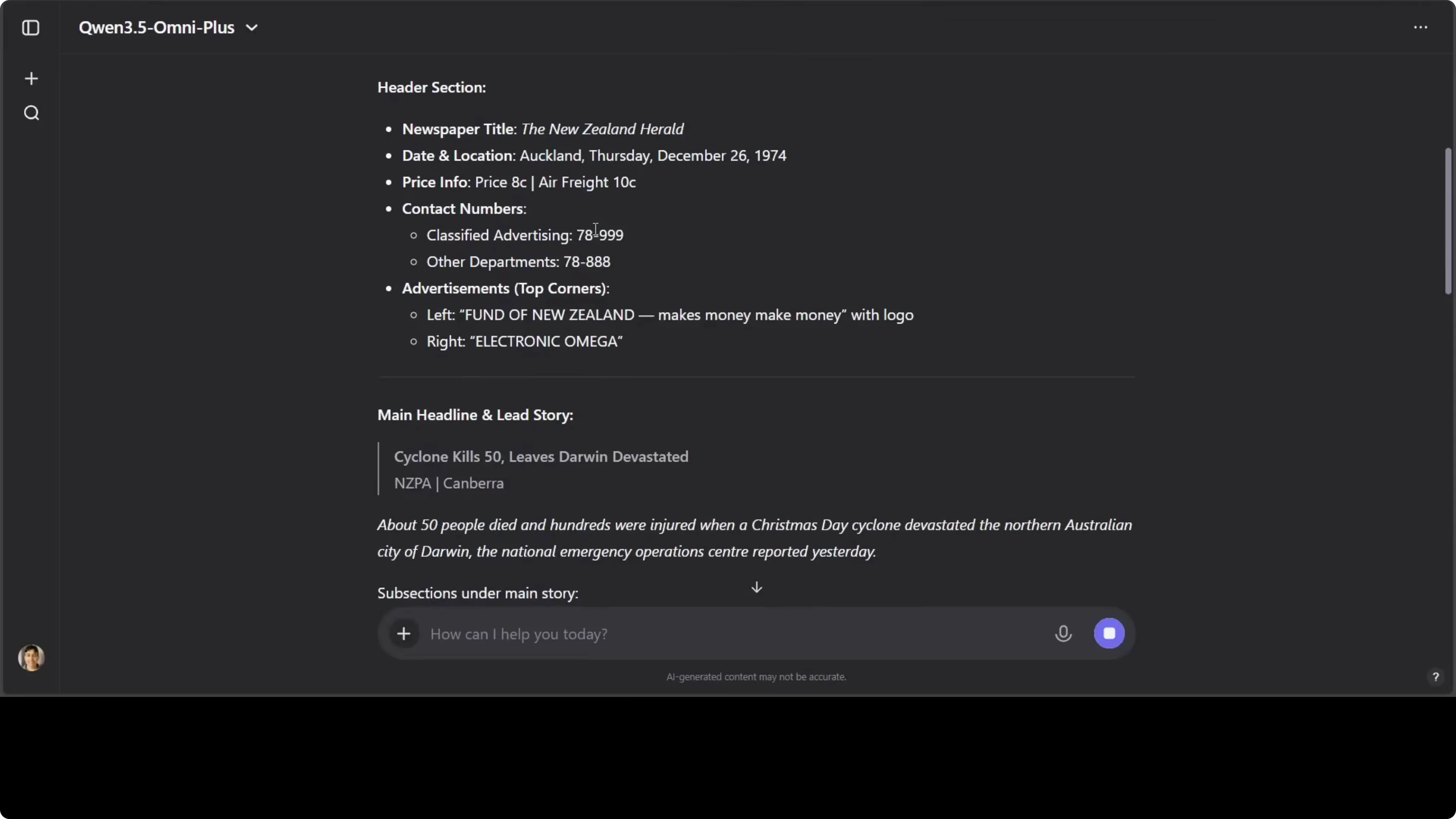
OCR quality here is significantly better than I expected. Layout parsing, section labeling, and text recovery held up even with aged print and complex page design. It captured the feel of a mid-1970s news page accurately and succinctly.
If you need a mid-size model for OCR-heavy workloads without heavy compute, consider the Qwen 3.5 4B option.
Handwritten math and physics
I provided a handwritten physics plus math sheet and asked it to solve as quickly as possible. The model extracted the text correctly and flagged that a full explanation would take time. It avoided hallucination since there was no specific equation to solve and asked me to clarify the exact question.
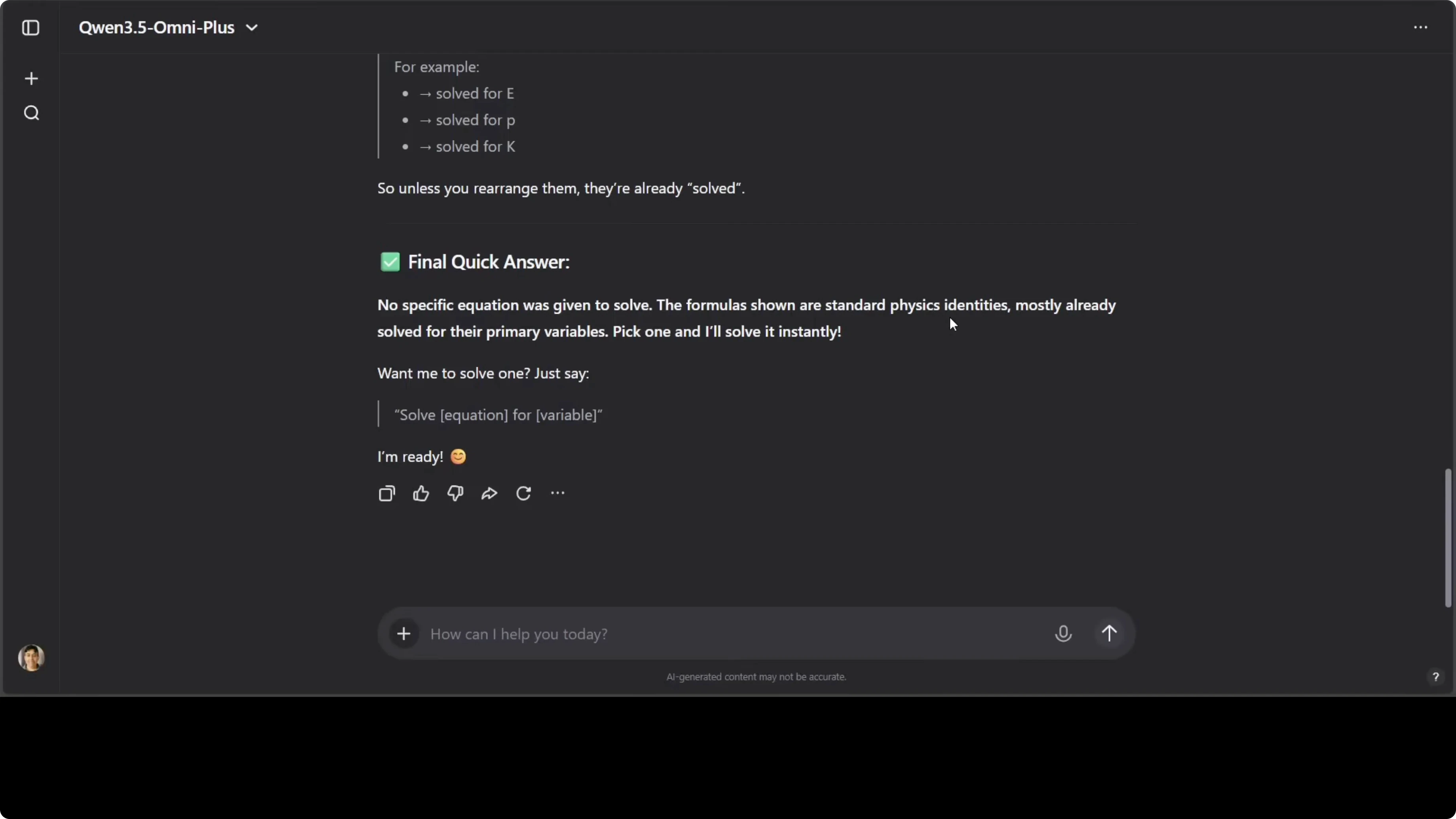
This behavior is exactly what I was looking for in a safety and reliability check. It read the handwriting accurately, recognized that the content was a set of formulas rather than a solvable prompt, and deferred to clarification. That is a strong result.
Video understanding
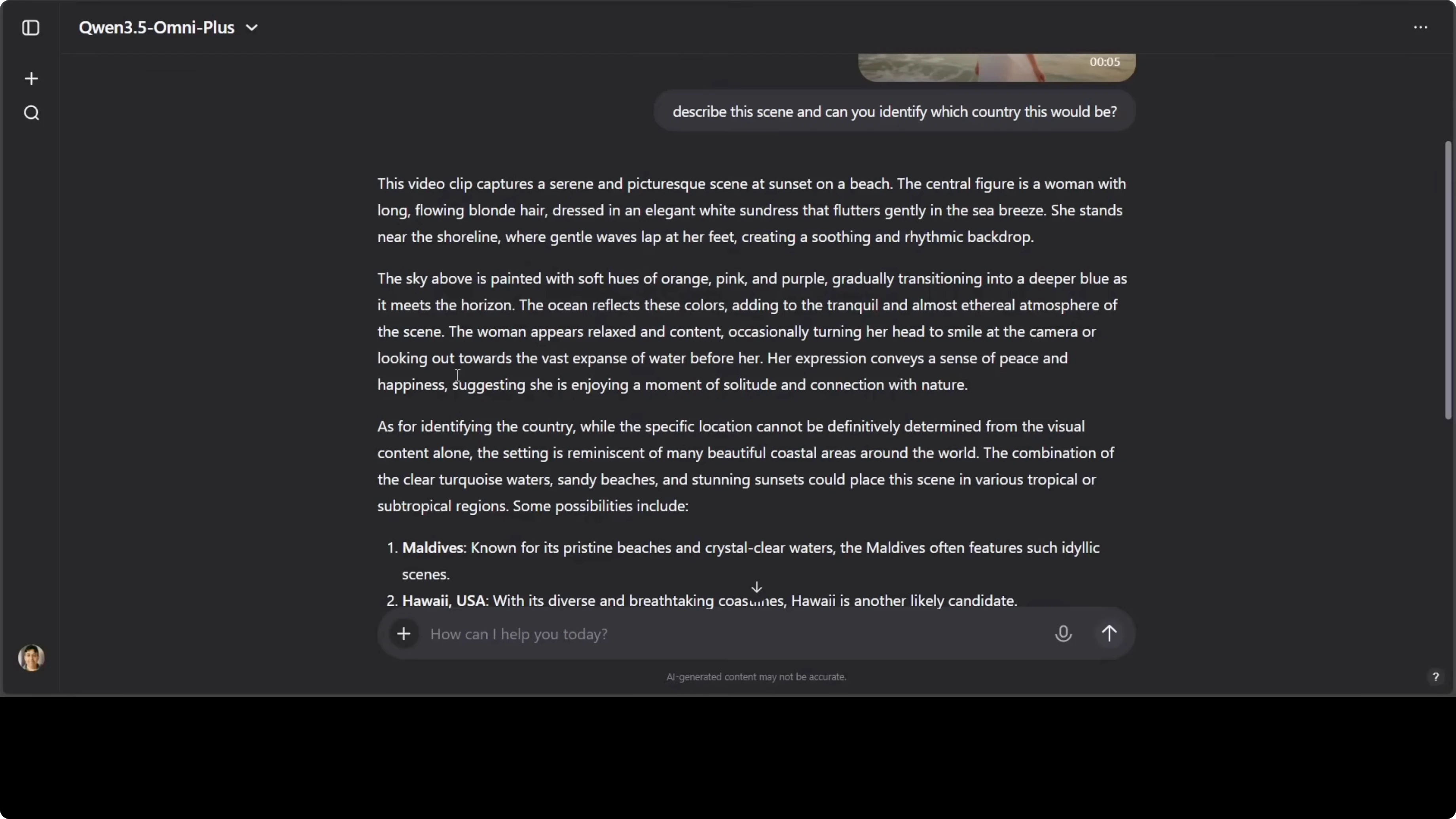
I tested an AI-generated beach scene and asked for a description and potential country identification. The model delivered a coherent, grounded narrative with details like the central figure, lapping waves, and hues of orange, pink, and purple in the sky. It suggested likely coastal regions such as the Maldives, Hawaii, the Caribbean, and Australia’s Gold Coast.
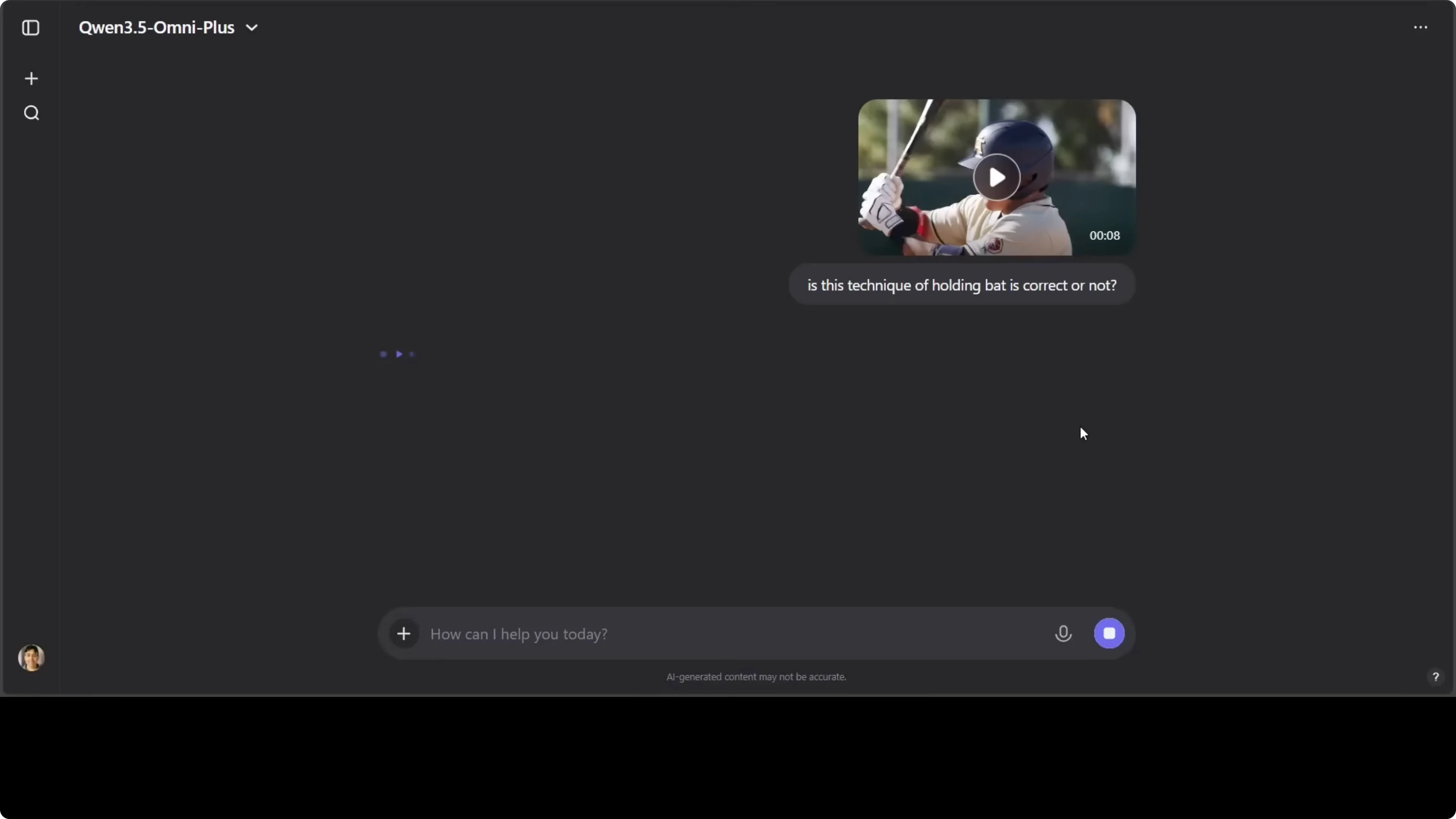
I also tested a clip of a batter holding a baseball bat to check if the grip technique was correct without naming the sport. The model identified it as baseball, described grip, stance, elbow position, and focus, and called it a technically sound approach to batting. The analysis reads like practical coaching notes.
Use cases
Rapid prototyping from screenshots into working HTML files is a quick way to test mechanics and iterate on UI or small games. Teams can take a UI mock or game frame and get a runnable baseline in minutes.
Detailed audio notes with timestamps, speaker traits, and tone are useful for research interviews, editorial workflows, and compliance logs. This level of structure saves time on review, cataloging, and search.
Multilingual voice-to-text and translation lets support teams, educators, and product teams localize short prompts or FAQs quickly. It is also a fast check on phrasings across languages.
Structured OCR on scanned pages helps with archives, newsroom research, and content audits. Extracted sections, captions, and summaries reduce manual sorting and tagging.
Video scene understanding can support coaching review, content tagging, and quick creative briefs. Descriptions with plausible locations and technique checks are helpful for first-pass analysis.
Final thoughts
Qwen 3.5 Omni Plus handled image-to-HTML coding, long-form audio with rich metadata, multilingual translation, OCR on difficult scans, handwritten text extraction, and video scene reasoning with strong results. Speed is improved over earlier releases in the family, and the outputs feel accurate and practically useful. If you want a closer look at prior versions and how they compare, here is a focused write-up on Qwen 3.5 Plus and a broader multimodal explainer for the series at Qwen 3.5 for AI video, image, code, and text.
Subscribe to our newsletter
Get the latest updates and articles directly in your inbox.

Related Posts

8 Best Claude Code Plugins in 2026 (You Need to Know)
8 Best Claude Code Plugins in 2026 (You Need to Know)

7 Best Claude Code Skills (You Need to Know)
7 Best Claude Code Skills (You Need to Know)

Claude Code Desktop IDE Features (You Need to Know)
Claude Code Desktop IDE Features (You Need to Know)