

Qwen3.5 Plus: The New Native Vision-Language Model
Qwen Model Recommender
Not sure which Qwen model fits your GPU? Pick your VRAM, use case, and task type — get matched to the right model instantly. Covers Qwen3, QwQ, QVQ, Qwen2.5-VL, Qwen3-Coder, Qwen3-TTS, and 80+ models.
On the eve of Chinese New Year, team Qwen has given this immense gift of Qwen 3.5 plus. This model is a vision language model built on a hybrid architecture that integrates a linear attention mechanism with a sparse mixture of experts. The key feature is that it achieves higher inference efficiency across a variety of task evaluations.
This new 3.5 series was just released. It has consistently demonstrated performance on par with leading models. It shows a leap forward in both pure text and multimodal capabilities.
Model overview
At the moment this model is only available on Model Studio. It will be available on Hugging Face. You can also use it from the API, and the great thing is that it is OpenAI compatible, so it could be a drop in replacement.
The cost is very low if you check Model Studio from Alibaba. Pricing shows input and output. In my humble opinion it is a steal, but of course up to you.
It supports function calling, structured output, and tool use. Fine-tuning is not available yet but you can certainly do it. You can use it in partial mode through the API, and inputs are multimodal while output is only text at the moment.
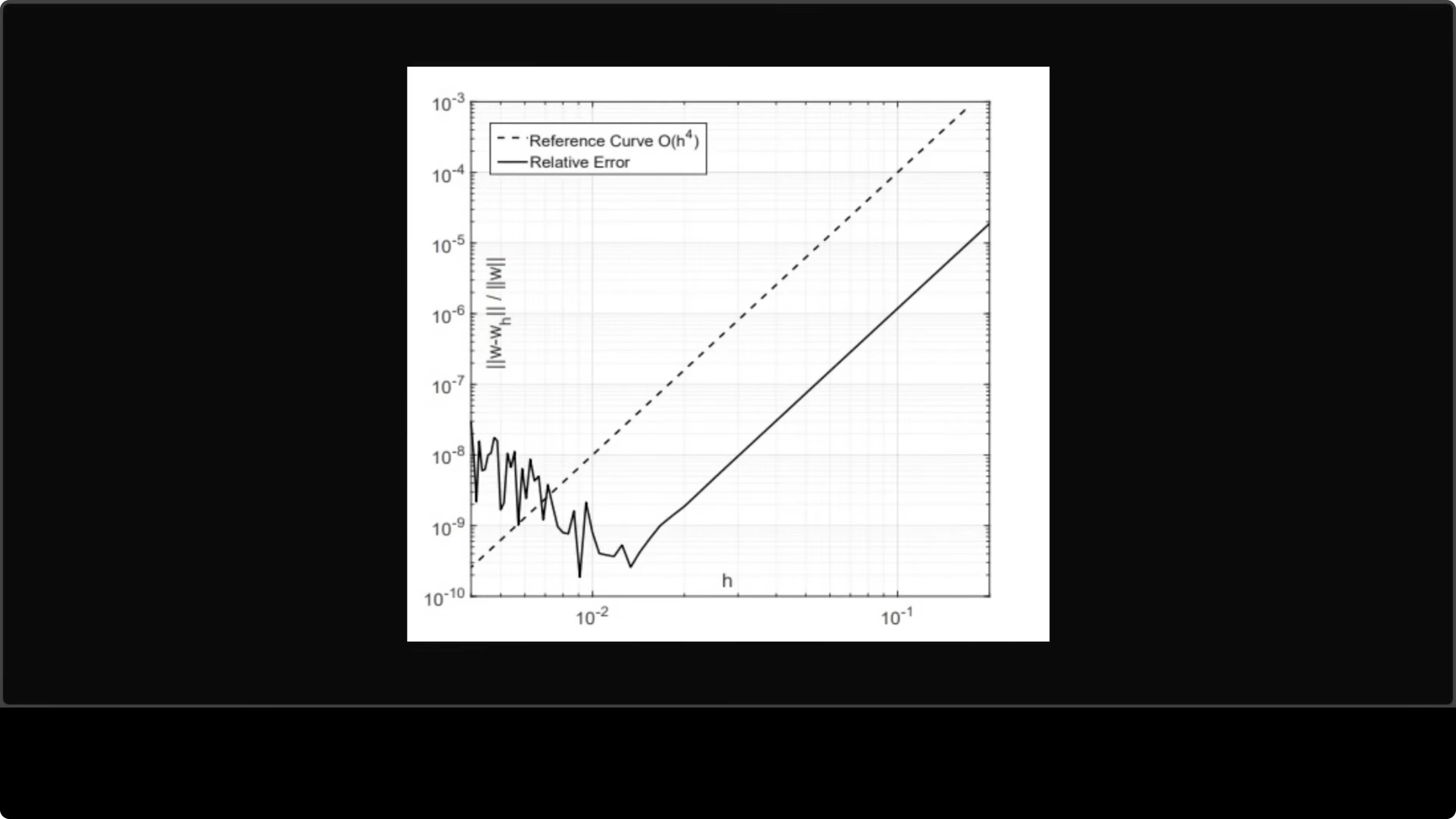
Image reasoning
I uploaded a graph and asked the model to explain it in simple words. The answer was very targeted and the quality of the model oozes through. The explanation in my humble opinion is a masterclass in making complex numerical analysis genuinely accessible.
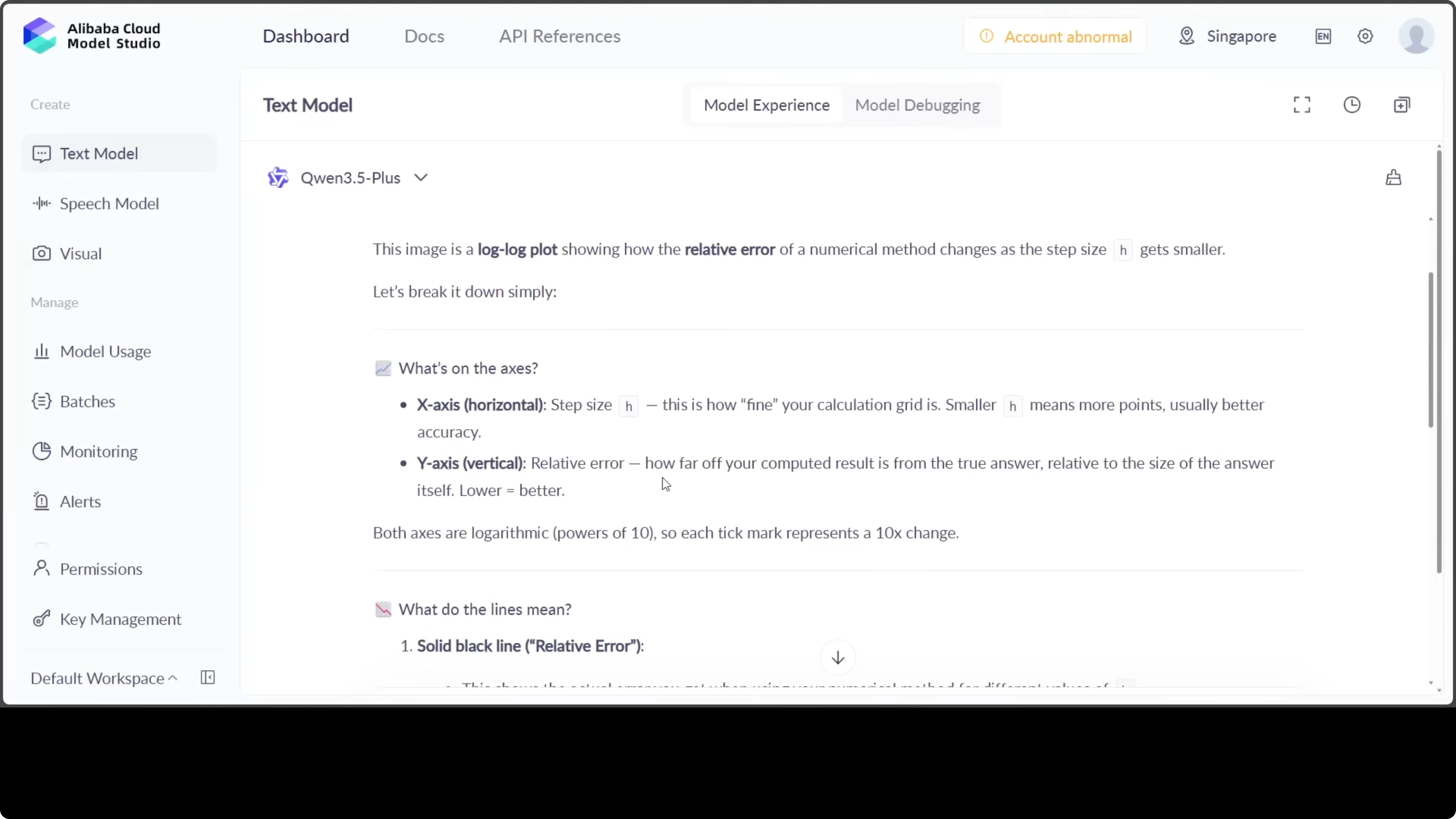
The layered breakdown from axes to curves to takeaway guides any reader with impressive clarity. The use of concrete examples like half h error drop 16 times transforms abstract math into intuitive insight. The closing sweet spot makes the key point land.
"smaller steps give better results up to a point. After that, your computer's math gets messy and makes things worse. This graph shows that sweet spot."
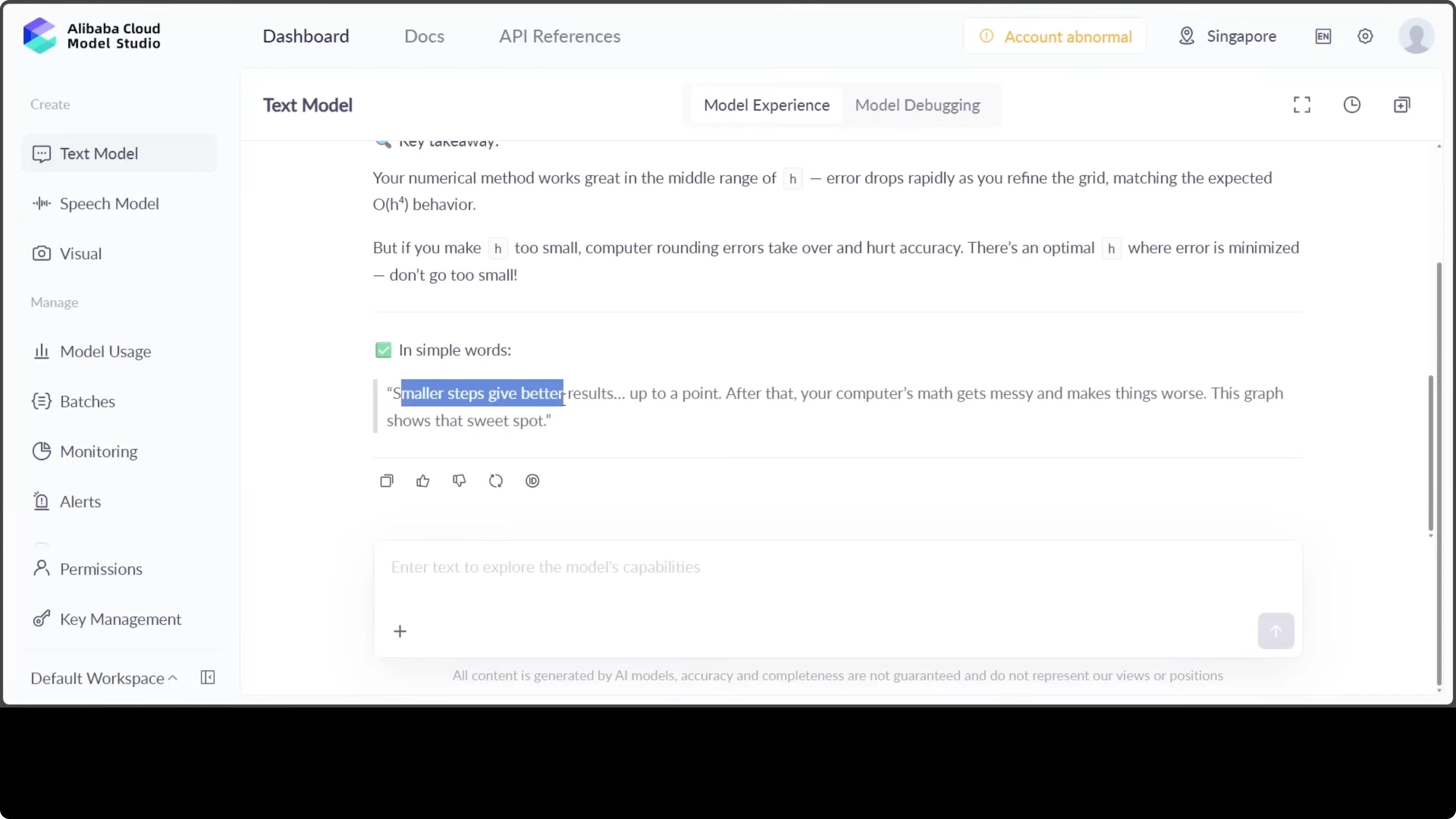
This observation about optimal step size is the kind of practical wisdom that elevates a good explanation into a great one. I love it. It reads like something you can apply right away.
Steps to reproduce
Open Alibaba Cloud’s Model Studio.
Click the plus sign to start a new chat or session.
Upload your image from the local system.
Use a short prompt asking for a plain-language explanation.
Review the layered reasoning and final summary.
Prompt used
Explain this in simple words.Video scene analysis
I tested an AI generated video with a savana sort of scene. There is a lion tribe, there are zebras, and a few other animals, and there are also deer which there are three of them. I asked the model to describe the scene, count the animals, identify which animals, and tell the location.

It answered with African savana where a group of zebras is being chased by two lions. The environment is dusty and open with sparse vegetation. The language of Qwen models has improved a lot.
It answered my question very targeted: at least six zebras, totally correct, and they are running away from lions. The language includes earthy tones and golden fur stands out. It notes hyenas running alongside zebras adding to the chaos.
It then talks about the location, and it could be Sereniti in Tanzania near Masai Maran Kenya. This is a description of the scene that has knitted together the whole context. The language is very targeted, no embellishment, no exaggeration, and it also gives a very concise summary.
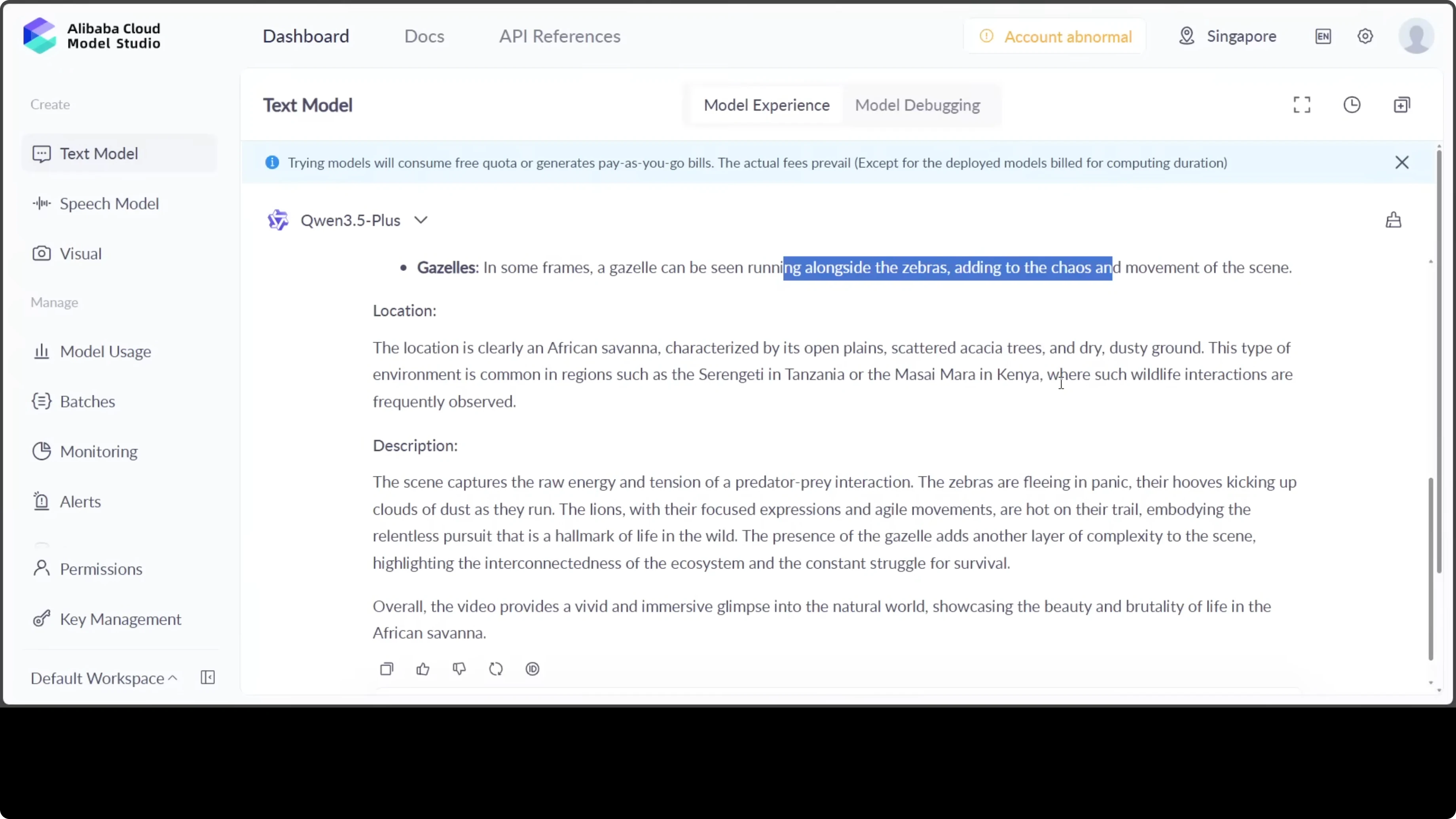
"overall the video provides a vivid and immersive glimpse into the natural world showcasing the beauty and brutality of life in the African savannah." How good is that.
Prompt used
Describe the scene. How many animals can you see, and which animals? Also, can you tell the location?Clinical reasoning test
I gave the model extra images from histopathology, dermatology, and a couple of X-rays. I told the model that I am a doctor on holidays in Chinese Inner Mongolia and a patient has sent me these images. I asked what I should say to them in simple words in an email.
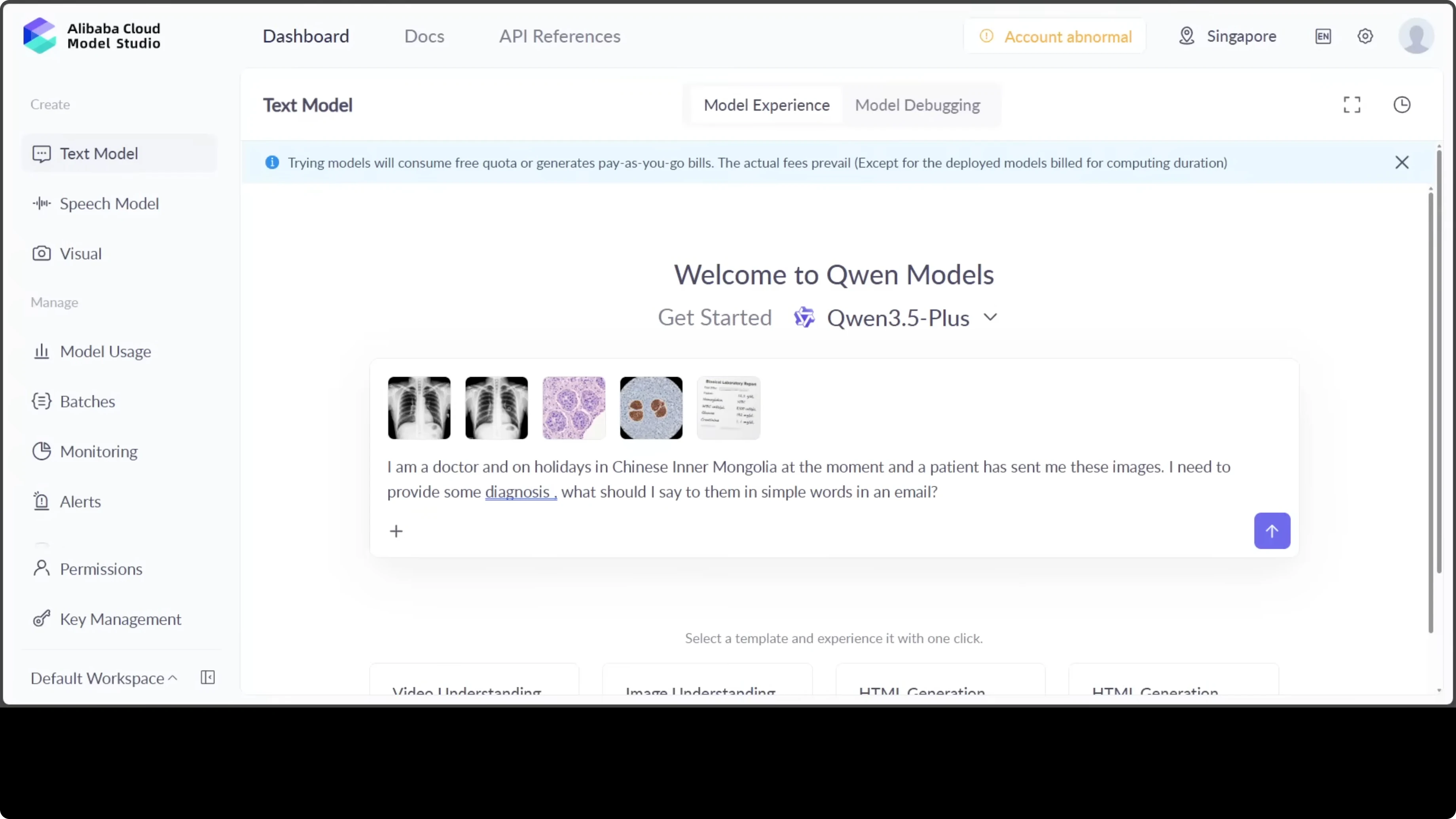
This is not medical advice and this is just for testing and education. I have no clue what exactly this means, but as far as I can tell and I have verified it from other models too, this shows exceptional clinical reasoning. It bridges radiology, histopathology, and lab interpretation into a unified coherent diagnostic picture that most AI systems struggle to achieve.
This includes a diagnosis summary for the doctor. I have no idea what that means, but it looks really cool to me, and if you are a physician or doctor, please confirm. What I really like is the draft email to the patient.
It strikes a rare balance between medical honesty and compassionate language. It ensures the patient feels informed without being overwhelmed or alarmed. You do not have to be a doctor or physician to get that vibe from this email.
The structured flow from image analysis to diagnosis to patient communication reflects a level of medical communication intelligence that is both practically useful and ethically thoughtful. It makes it immediately deployable in a clinical workflow. Look at this line.
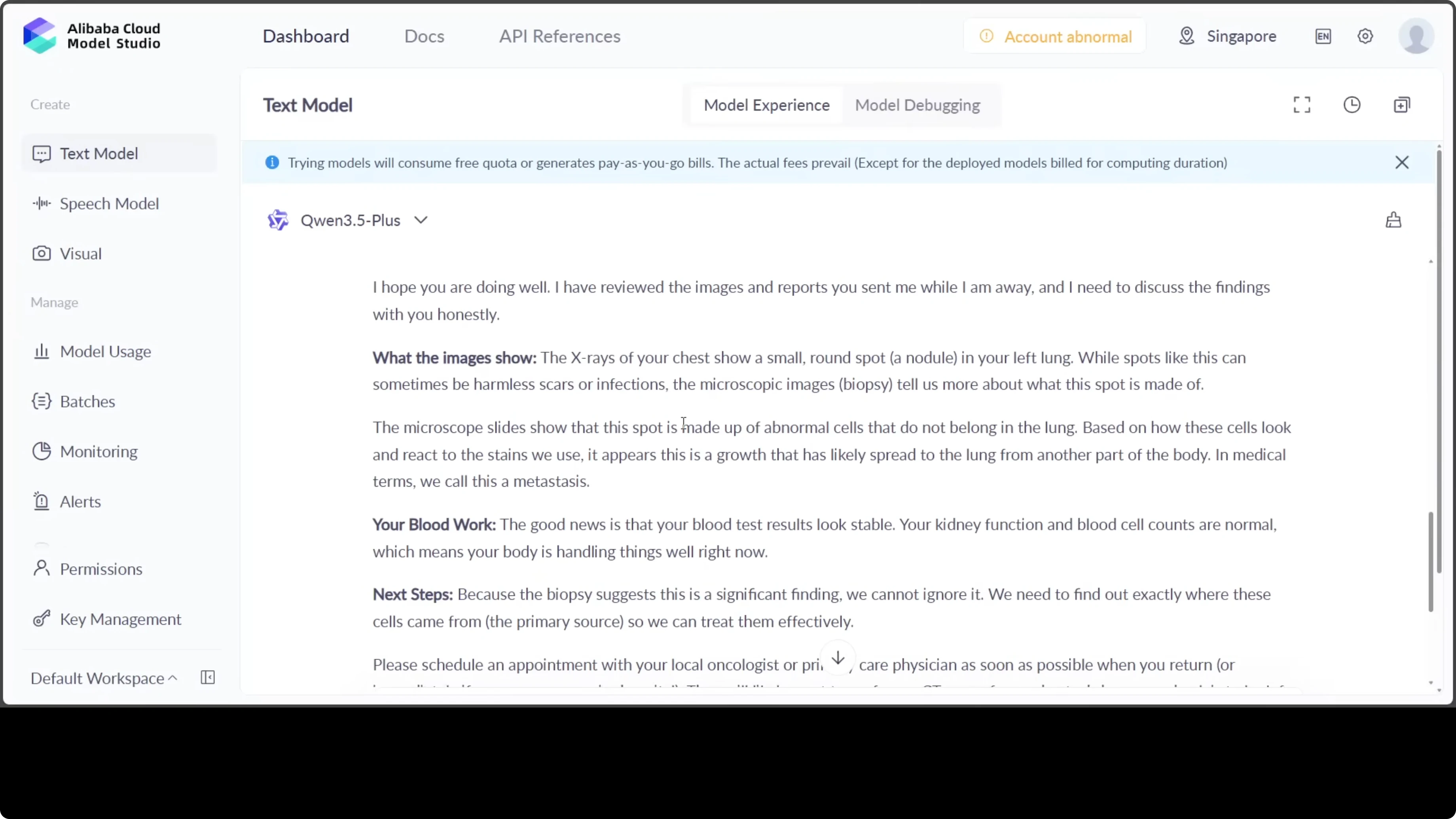
"I know this is worrying news to receive while I’m away but catching this early gives us a best chance to manage it." This is so good. Then you add your name and all that stuff.
Prompt used
I’m a doctor and on holidays in Chinese Inner Mongolia at the moment. A patient has sent me these images. I need to provide some diagnosis and write what I should say to them in simple words in an email.API notes
You can use this model from the API, and there is a complete API reference. It is OpenAI compatible, so you can swap it in with an OpenAI-style client. Inputs are multimodal and the output is text for now.
Check the published pricing for input and output. Function calling, structured output, and tool use are supported. Fine-tuning is not available yet but you can certainly do it.
Final thoughts
Qwen 3.5 plus lands with a hybrid design that boosts efficiency and strong parity with leading models. In quick trials it delivered clear, targeted explanations for images, rich scene understanding for video, and coherent clinical reasoning with a patient-safe tone. It is available in Model Studio with an OpenAI compatible API, low cost, and support for function calling, structured output, and tool use, which makes it instantly useful.
Subscribe to our newsletter
Get the latest updates and articles directly in your inbox.

Related Posts

8 Best Claude Code Plugins in 2026 (You Need to Know)
8 Best Claude Code Plugins in 2026 (You Need to Know)

7 Best Claude Code Skills (You Need to Know)
7 Best Claude Code Skills (You Need to Know)

Claude Code Desktop IDE Features (You Need to Know)
Claude Code Desktop IDE Features (You Need to Know)