

DeepGen 1.0: Explore Unified Image Generation and Editing
Today we're looking at a paper from the Hugging Face trending list published on February 12th, 2026. It presents a compact 5 billion parameter model that surprisingly outperforms the massive 80 billion parameter hunuan image by 28% on the wise benchmark. The paper is titled DeepGen 1.0, a lightweight unified multimodal model for advancing image generation and editing.
The fact that such a lightweight model can achieve these results using only 50 million training samples has significant implications for efficient AI development. For those interested in the implementation, the authors have shared their code on GitHub. On Hugging Face, you can grab the 5 billion parameter deepen weights.
DeepGen 1.0: Explore Unified Image Generation and Editing
Qualitative Results
To see what this model actually produces, Figure 1 displays a gallery of its outputs across distinct categories. The top rows show general generation and text rendering where it handles complex lighting and accurate text placement on signs.

Moving down, the reasoning generation section proves the model grasps physical concepts like the weight difference between an elephant and a rabbit on a seesaw. Finally, the bottom rows cover editing tasks where the model alters specific details like solving a visual maze or changing a logo without breaking the original image's structure.

Quantitative Benchmarks
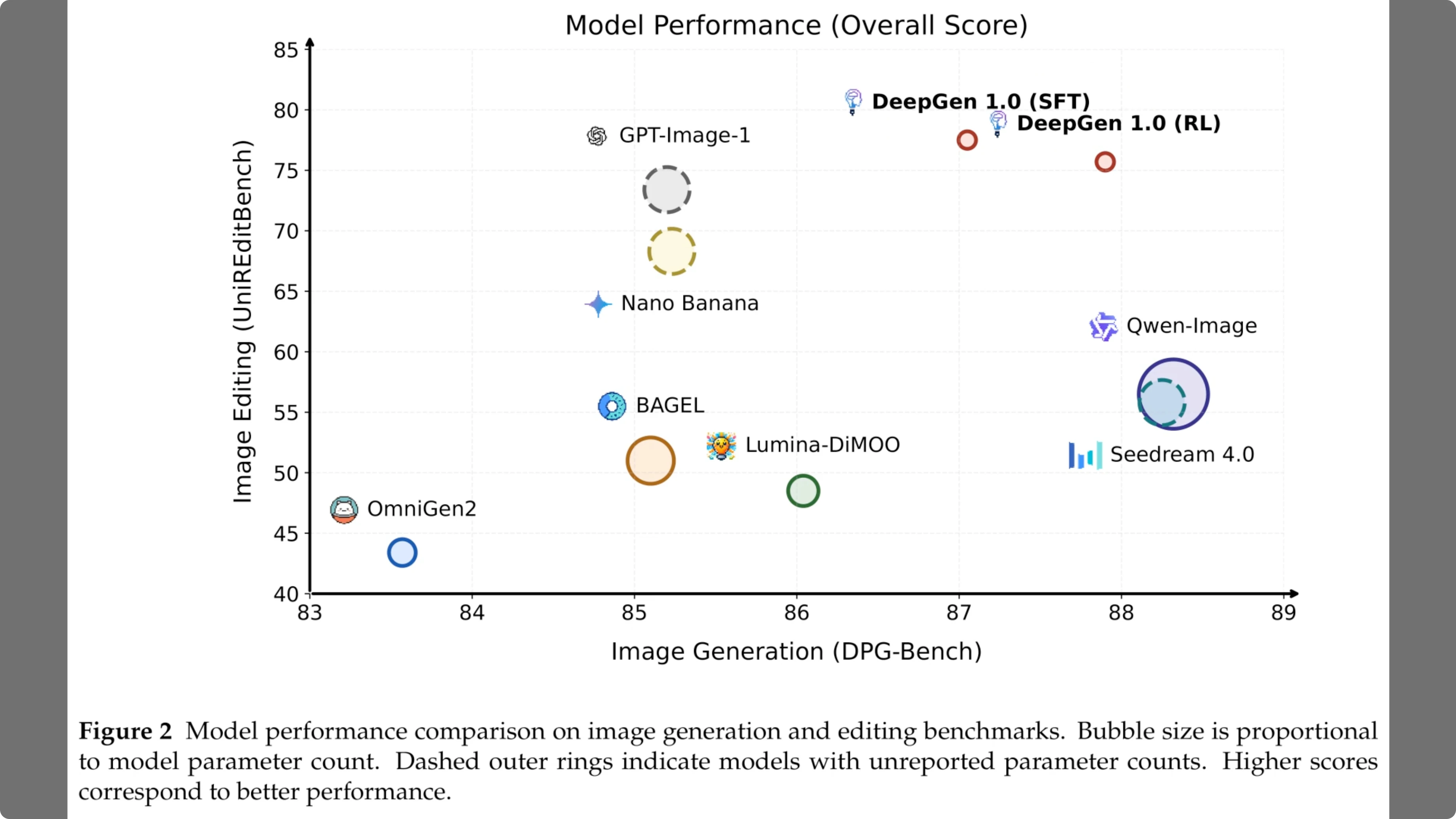
Figure 2 compares model performance across generation and editing benchmarks. The horizontal axis tracks image generation quality on DPGbench, while the vertical axis measures editing capabilities on UNIR edit bench.
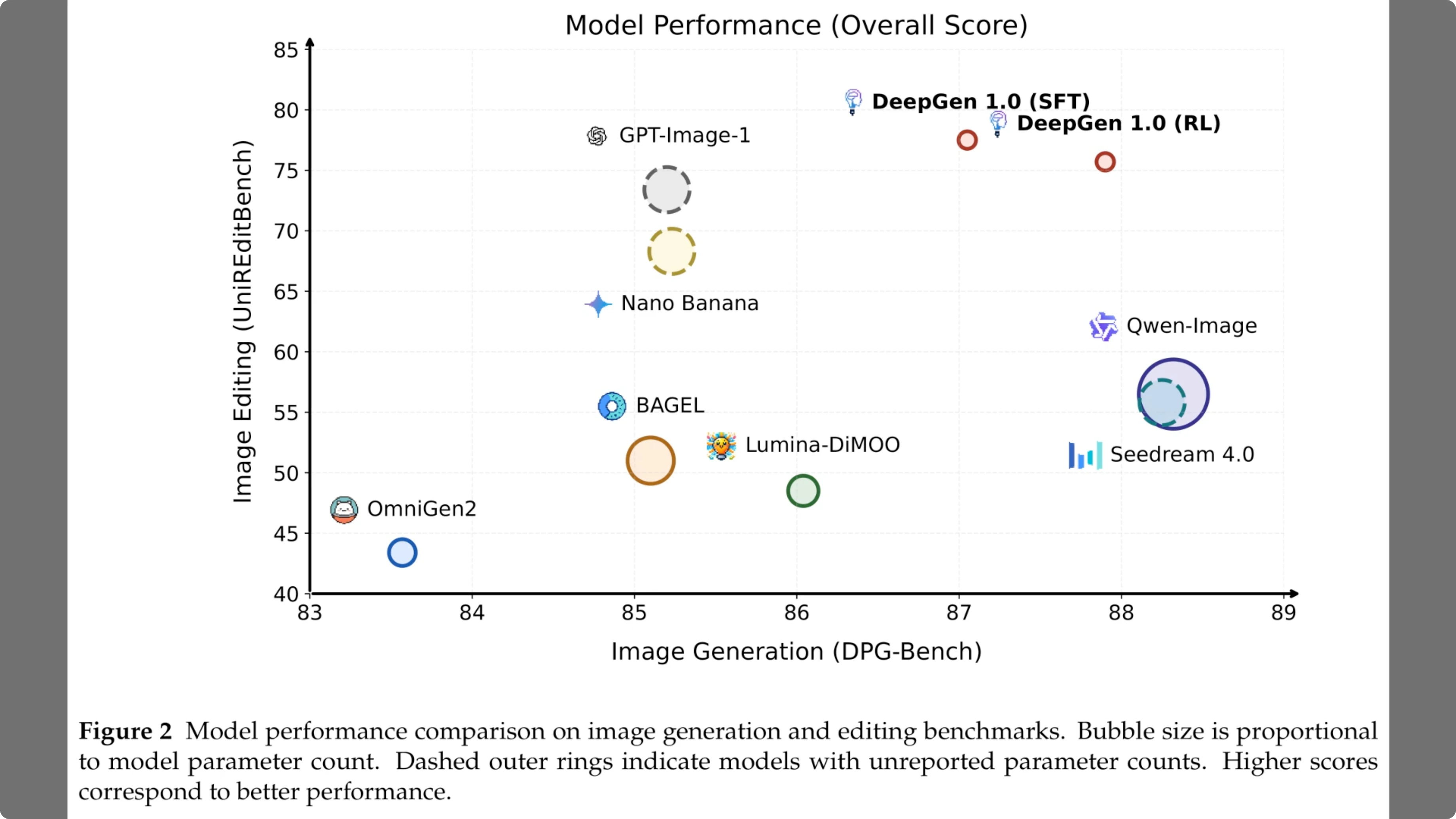
In this plot, bubble size corresponds to parameter count, meaning larger circles represent more expensive models. Strikingly, deep gen 1.0 appears in the top right corner with a relatively small footprint. It outperforms massive baselines like QN image and Cream 4.0, which appear as much larger bubbles lower down, demonstrating that efficient design can beat raw scale.
Architecture
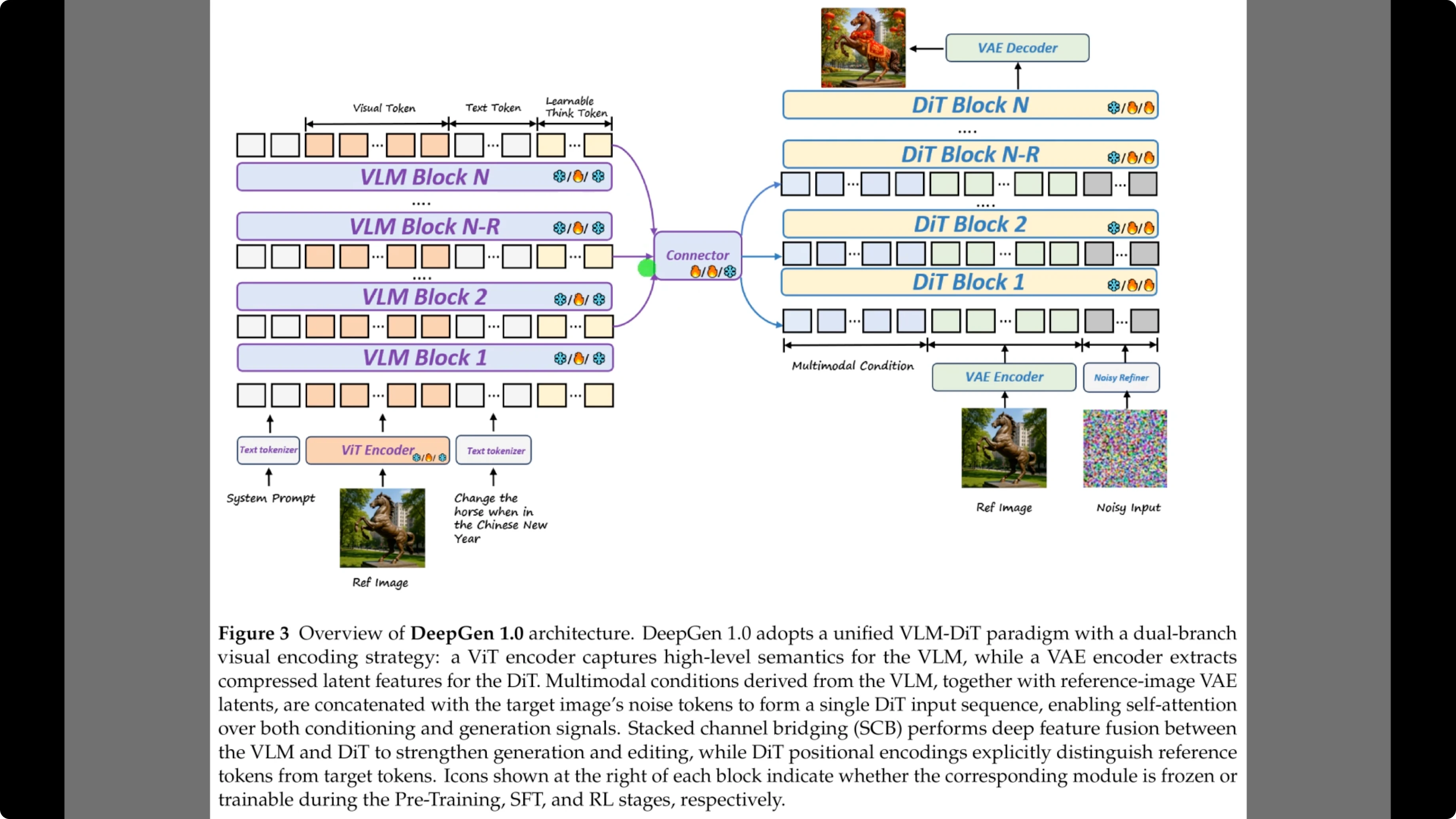
Figure 3 breaks down the architecture that makes it possible. On the left, the diagram shows the vision language model backbone, which processes both the text prompt and the reference image.
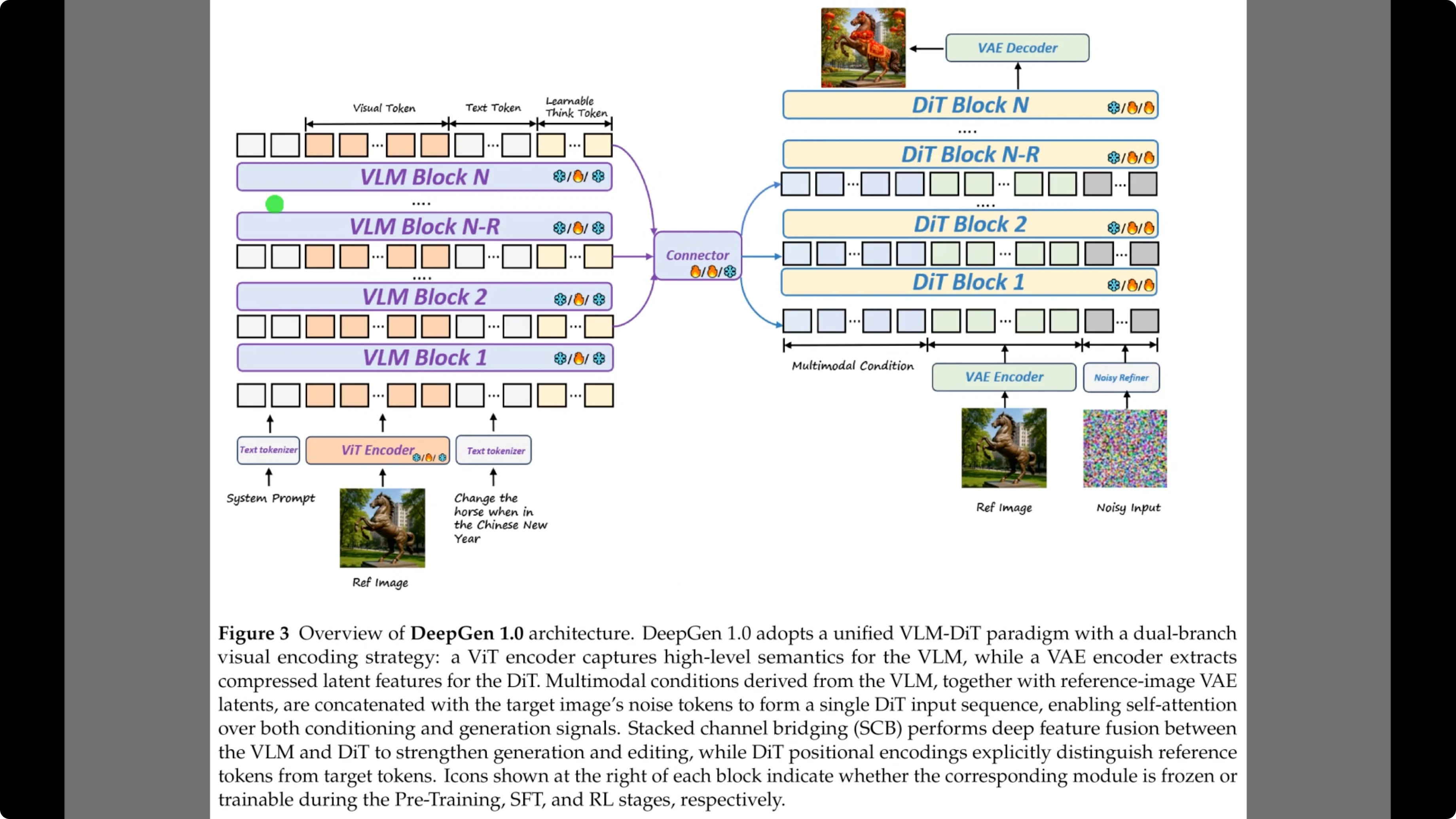
Crucially, the sequence includes what the authors call learnable think tokens shown here in the input sequence, which help the model reason before generating. These signals do not just come from the final layer.
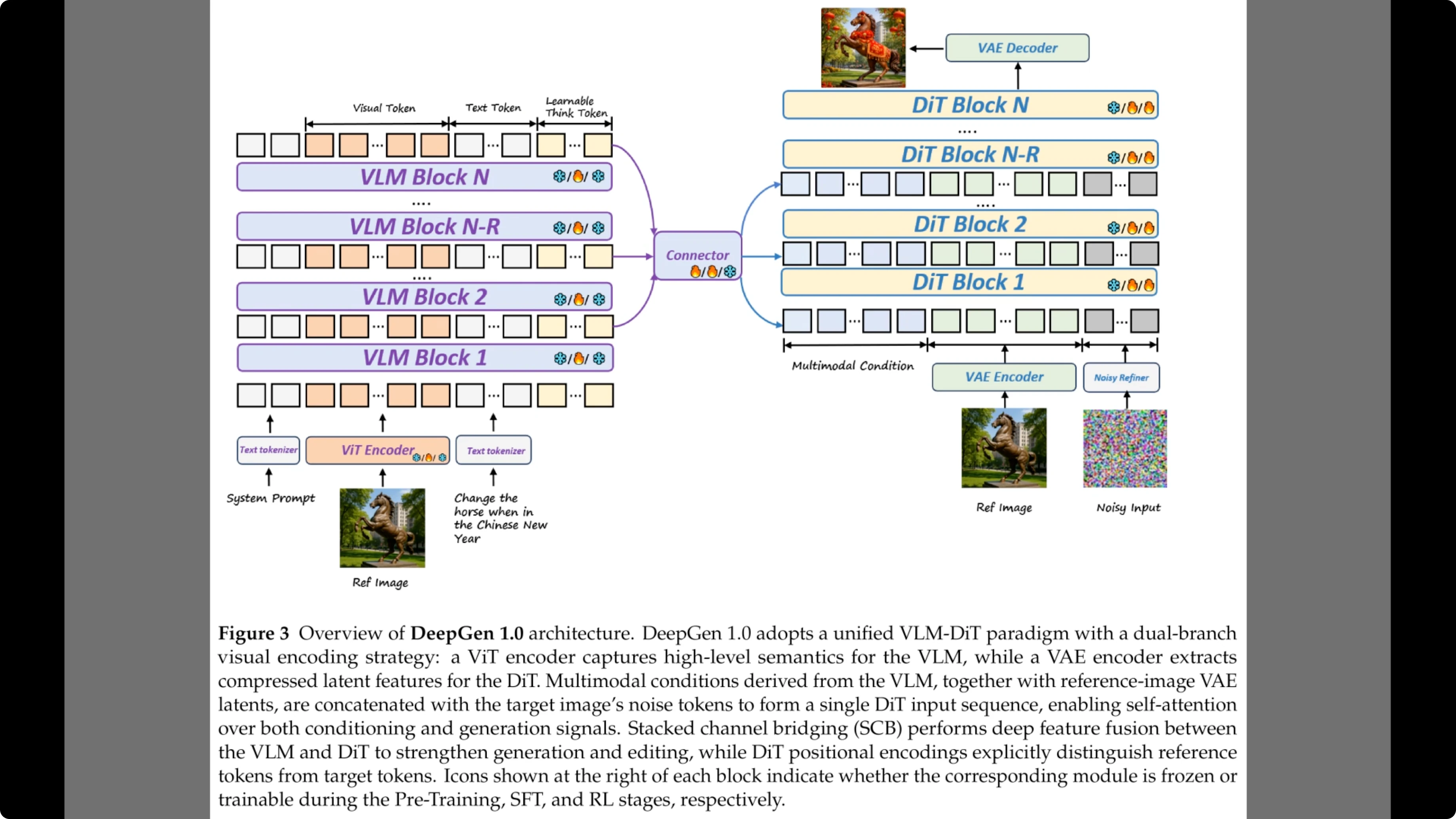
Arrows feed from multiple layers into the central purple connector. This represents the stacked channel bridging which passes detailed hierarchical features to the diffusion transformer on the right allowing it to generate the final image with precise control.
Comparisons With State of the Art
Table one provides the hard quantitative comparisons against state-of-the-art systems. The metrics cover generation tasks like general eval and dpgbench alongside editing benchmarks on the right.
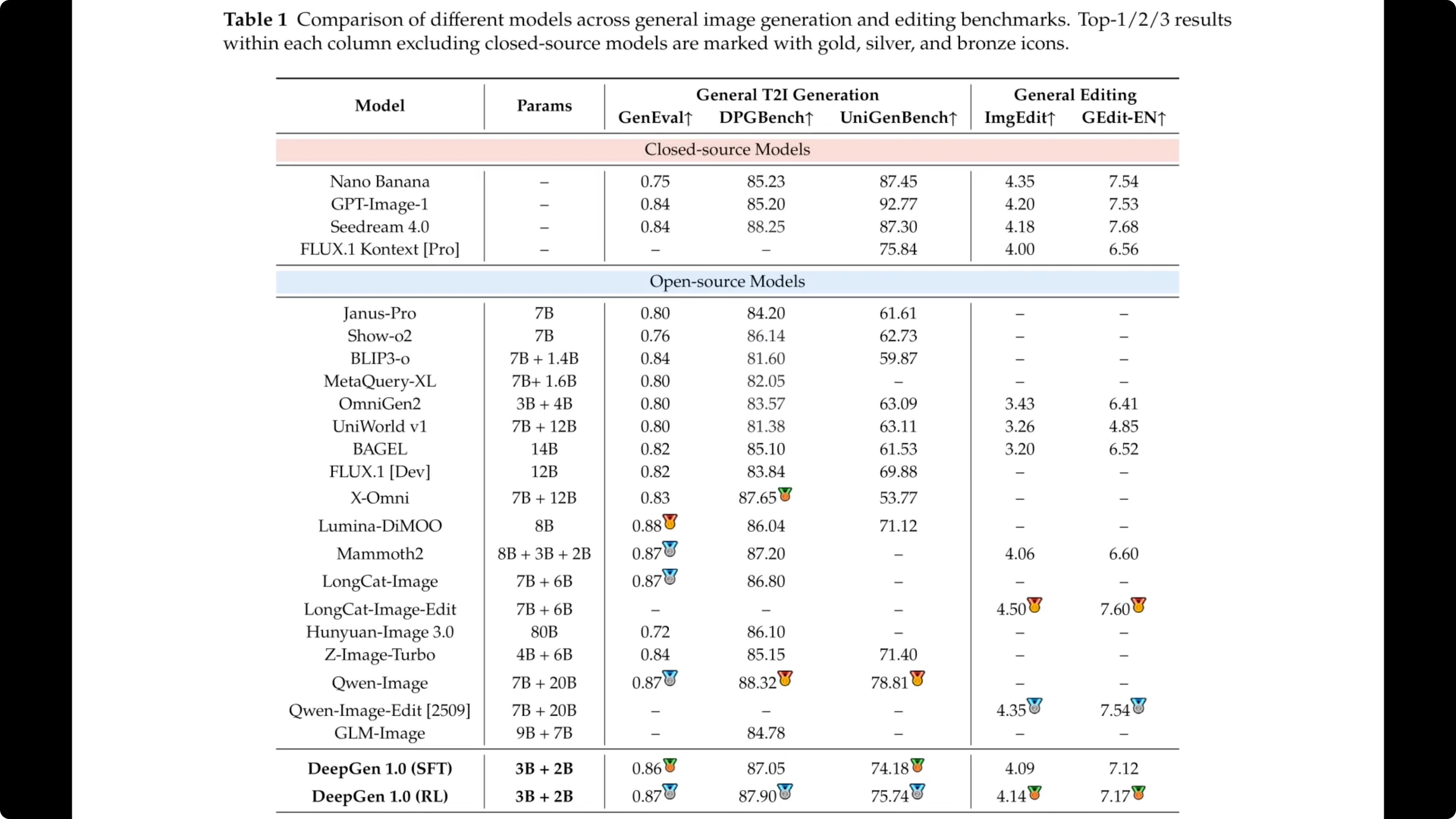
Focusing on the open source section, notice how deep gen 1.0 at the very bottom competes with significantly larger models. For instance, on DPG bench, the reinforcement learning version scores 87.90, which actually outperforms the 80 billion parameter Huan image 3.0 listed a few rows above. This validates the author's claim that a smaller well-trained model can punch far above its weight class.
Reasoning-Based Editing Benchmarks
Table 4 focuses on reasoning based editing. This tests if the model understands concepts like time, causality or logic split into the rise and uni redit benchmetrics.
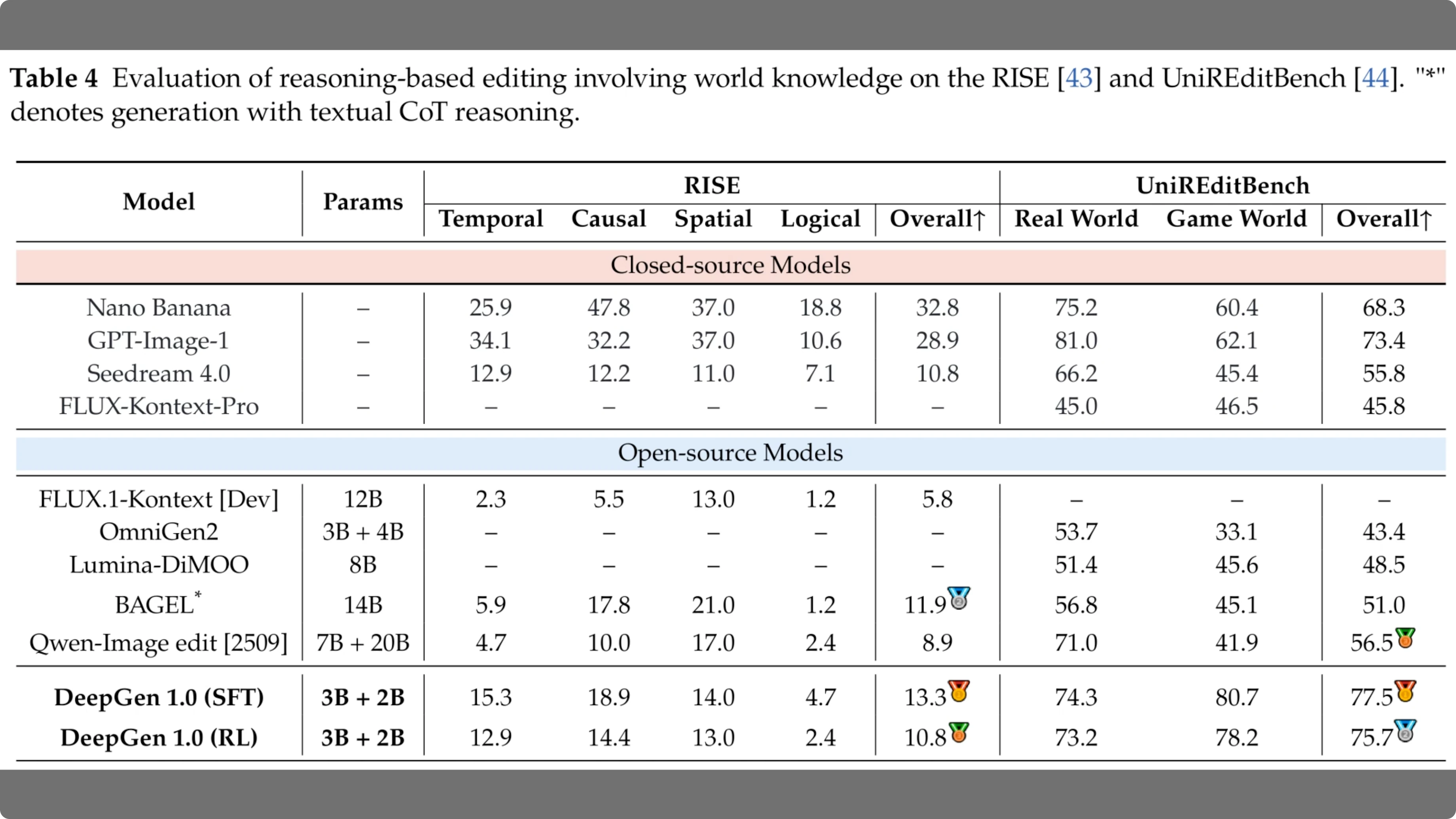
Looking at the open-source section at the bottom, the deep gen 1.0 supervised fine-tuning model takes the lead. It scores 77.5 overall on Uni Reddedit Bench, significantly beating the Quinn imageedit model at 56.5. It even outperforms the closed source GPT image one from the top section, proving its strong grasp of real world dynamics.
Ablation Study
Table 6 dissects the architecture to see which parts drive this performance. The first row establishes the full deep gen 1.0 baseline.
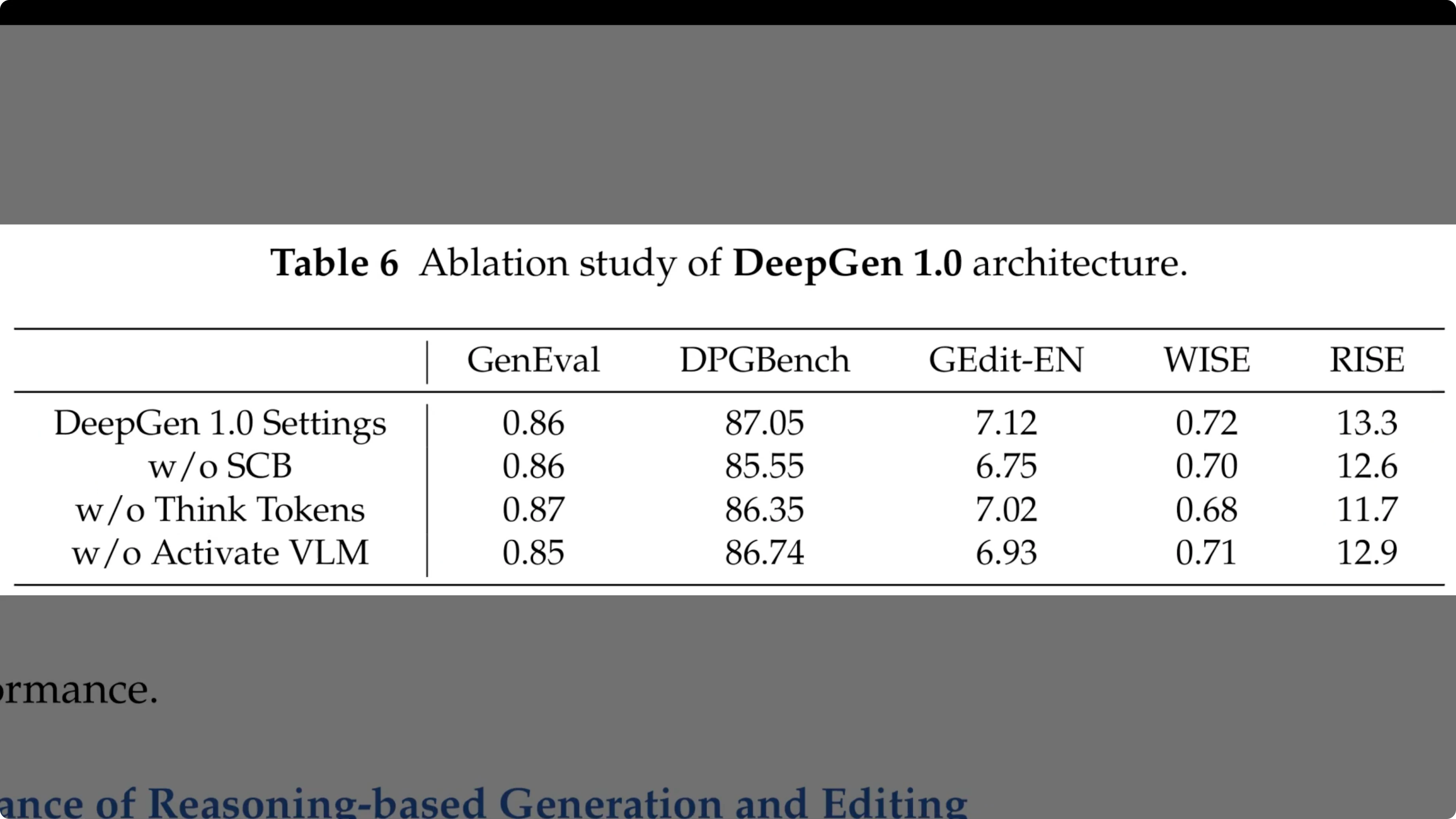
In the second row, we see that removing stacked channel bridging causes a consistent drop across all metrics. For instance, the rise score falls from 13.3 to 12.6.
The third row reveals that removing think tokens specifically hammers the reasoning benchmarks. Here, the wise score drops to 0.68 and rise plunges to 11.7, confirming that these tokens are essential for handling complex logic.
Final Thoughts
Deep gen 1.0 demonstrates that massive scale is not the only path to state-of-the-art performance. By combining a compact 5 billion parameter architecture with smart reasoning features like think tokens, it offers a powerful open-source alternative that runs on consumer hardware.
Subscribe to our newsletter
Get the latest updates and articles directly in your inbox.

Related Posts

8 Best Claude Code Plugins in 2026 (You Need to Know)
8 Best Claude Code Plugins in 2026 (You Need to Know)

7 Best Claude Code Skills (You Need to Know)
7 Best Claude Code Skills (You Need to Know)

Claude Code Desktop IDE Features (You Need to Know)
Claude Code Desktop IDE Features (You Need to Know)