
Table Of Content
- Setup - GPT-5 Codex vs Claude Sonnet 4.5
- The planning prompt
- Models and modes - GPT-5 Codex vs Claude Sonnet 4.5
- Planning outputs - GPT-5 Codex vs Claude Sonnet 4.5
- Comparison table - GPT-5 Codex vs Claude Sonnet 4.5
- Use cases - GPT-5 Codex vs Claude Sonnet 4.5
- Pros and cons - GPT-5 Codex
- Pros and cons - Claude Sonnet 4.5
- Step-by-step guide to reproduce this test
- Final thoughts

GPT-5 Codex vs Claude Sonnet 4.5
Table Of Content
- Setup - GPT-5 Codex vs Claude Sonnet 4.5
- The planning prompt
- Models and modes - GPT-5 Codex vs Claude Sonnet 4.5
- Planning outputs - GPT-5 Codex vs Claude Sonnet 4.5
- Comparison table - GPT-5 Codex vs Claude Sonnet 4.5
- Use cases - GPT-5 Codex vs Claude Sonnet 4.5
- Pros and cons - GPT-5 Codex
- Pros and cons - Claude Sonnet 4.5
- Step-by-step guide to reproduce this test
- Final thoughts
I put GPT-5 Codex and Claude Sonnet 4.5 head to head by setting up identical work environments and feeding them the same brief. I wanted to see which one planned and built a small app more effectively, not by rushing into code but by laying out a clear architecture first.
I created two identical Next.js TypeScript Tailwind skeleton projects. One lived in a Codex test project directory and the other in a Claude Code test project directory. Both were clean starts with their respective coding extensions initialized in Cursor.
I had a specific app in mind: a PRD Generator Template Wizard. The idea came from my Snapper AI PRD templates page, which people currently use by copy-pasting prompt templates into ChatGPT and Claude. I wanted a simple form-based app that takes structured inputs and outputs a fully formatted PRD, removing all the manual copy-paste work.
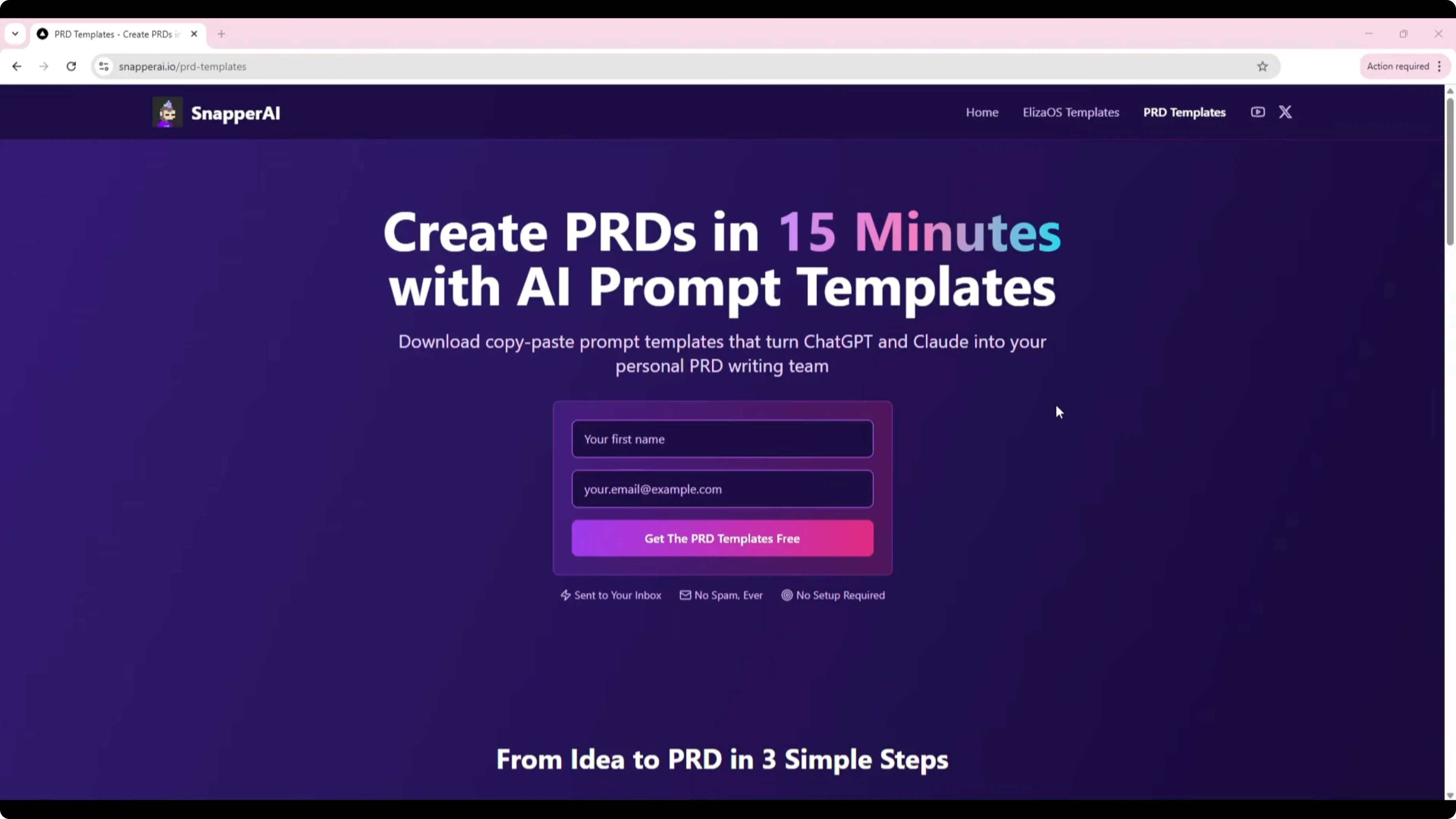
To make it easier for the models, I prepared a shared directory with the existing prompt templates. I named it "PRD generator shared" on my system and pointed both tools to that path for reference. The output target was clear too: a clean PRD structure produced instantly once the user submits the form.

For a quick speed context across popular models used in code workflows, see this separate comparison of completion latency: speed test for GPT-5 Codex, Claude Sonnet, Grok, and Composer.
Setup - GPT-5 Codex vs Claude Sonnet 4.5
I started both tools in planning mode, not implementation. The goal was to force a thoughtful design pass before writing any code.

On the Codex side, I chose GPT-5 Codex High because it prioritizes quality over speed. In Cursor, I kept it in Chat or Plan mode to align with the planning-first approach.
On the Claude Code side, I selected the default recommended model, Sonnet 4.5. If I wanted to bias toward heavier reasoning I could have used Opus 4.1, but Sonnet 4.5 is the newest recommended option and that’s what I tested.
If you need a deeper model-versus-model planning comparison outside this matchup, this breakdown is useful: how GPT-5.2 Codex compares to Opus 4.5 in structured tasks.
The planning prompt
I prompted both to operate inside a blank Next.js TypeScript Tailwind project. I told them to plan a small web app called PRD Generator Template Wizard that turns structured user inputs into a fully formatted PRD using Snapper AI’s existing PRD template system. The prompt made it explicit that this phase was planning only with no code yet.
Here is the starting snippet I provided to both:
You are working inside a blank Next.js TypeScript Tailwind project.
Your goal is to plan - not build yet - a small web app called "PRD Generator Template Wizard" that turns structured user inputs into a fully formatted PRD using Snapper AI's existing PRD template system.
In this phase:
- Analyze requirements and design the architecture.
- Define file structure, types, and component hierarchy.
- Plan the PRD generation logic.
- Identify edge cases and validation needs.
- Ask clarifying questions before implementation.
- Do not write any code.I included context about the old 3-step workflow that the app should replace. ChatGPT created the scaffold, Claude expanded to a full PRD, and ChatGPT reviewed. The new flow is much simpler: the user fills out a form and the app generates the complete PRD instantly.
I supplied the expected PRD output structure, input schema, theme and UI guidelines, technical requirements, client-side constraints, and baseline TypeScript types. I also flagged planning deliverables, UX flow, edge cases, and an optional phase 2 list.
I closed with clear guardrails: this is an MVP, focus on core functionality, clean simple UX, and a solid architecture that actually works. I asked for clarifying questions and invited improvements if they saw clear wins beyond my initial plan.
If you want to cross-reference how planning rigor correlates with coding accuracy across other stacks, see this benchmark-style review: coding test comparisons for GPT-5 Codex vs GLM 4.6.
Models and modes - GPT-5 Codex vs Claude Sonnet 4.5
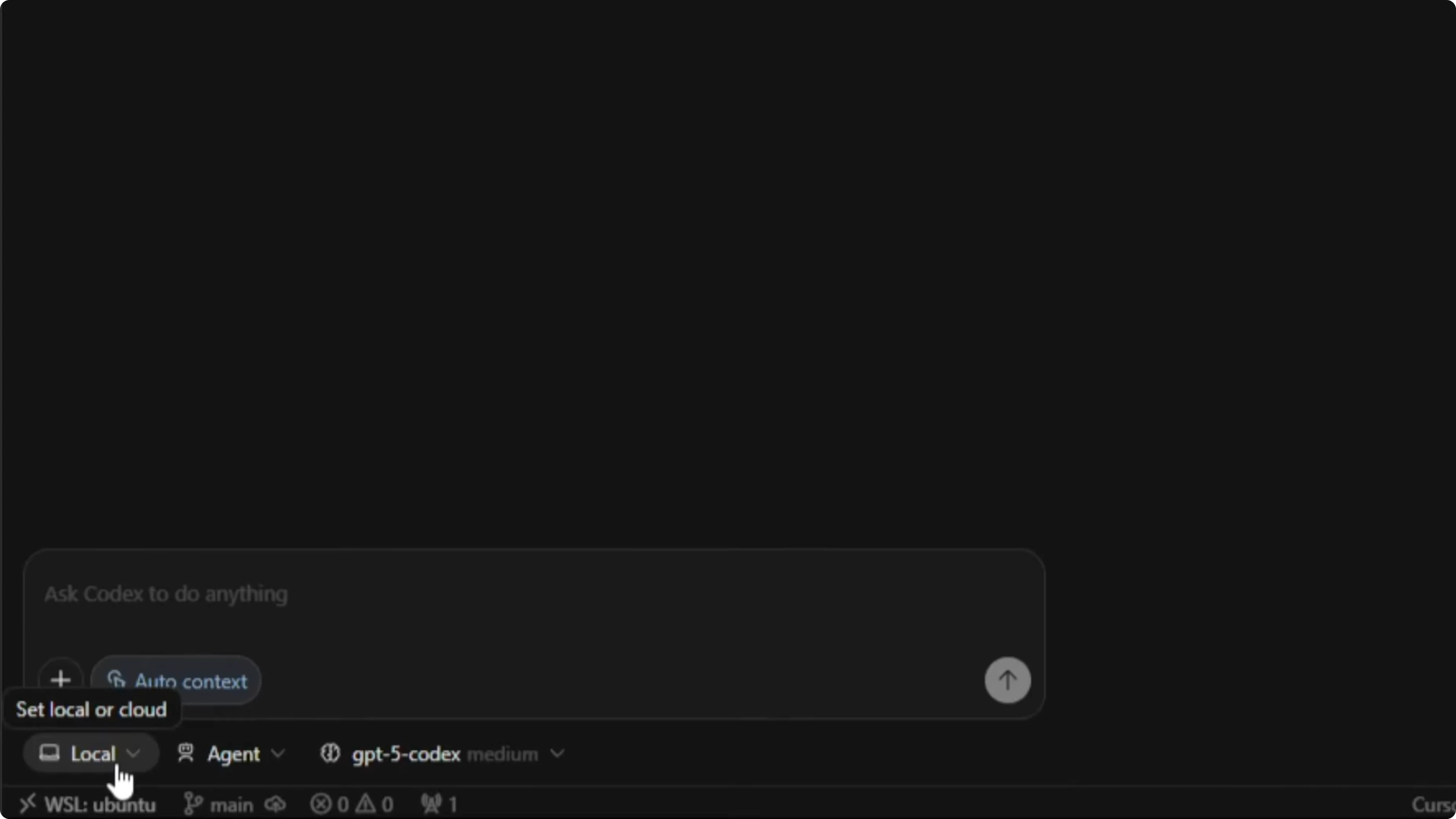
I kept Codex in Chat or Plan mode first, with GPT-5 Codex High selected. Once the plan was approved, the next step would be switching to Agent mode for implementation.
In Claude Code, I accessed settings with the /mod command and confirmed Sonnet 4.5. That matched the default recommended model and aligned with the use case here.
I also noted Opus 4.1 as a backup for especially complex tasks, but I stuck with Sonnet 4.5 for parity with the recommended default.
For broader context on Codex variants vs Opus in heavier tasks, this related analysis is helpful: Opus 4.5 compared against GPT-5.1 Codex Max.
Planning outputs - GPT-5 Codex vs Claude Sonnet 4.5
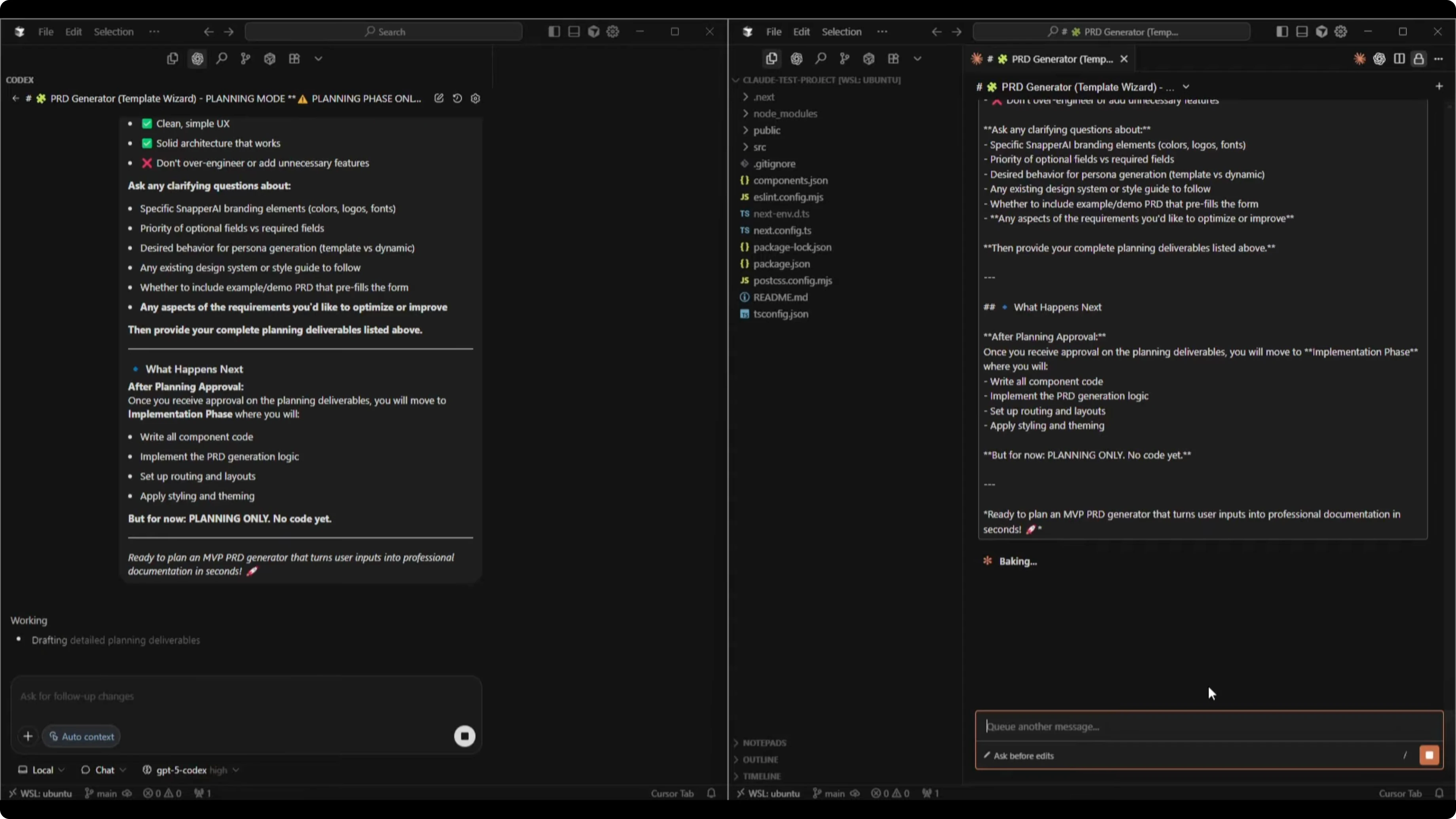
Both tools produced structured planning documents. Codex finished faster in this run and streamed its thinking more visibly, while Claude took longer to produce a single finished plan.
Codex started with a file structure and a TypeScript plan that included key PRD fields like description, problem statement, and target audience. It laid out a component hierarchy, a components implementation plan, a UI layout for desktop and mobile, an interaction flow, edge cases and validation, optimization ideas, and open questions.
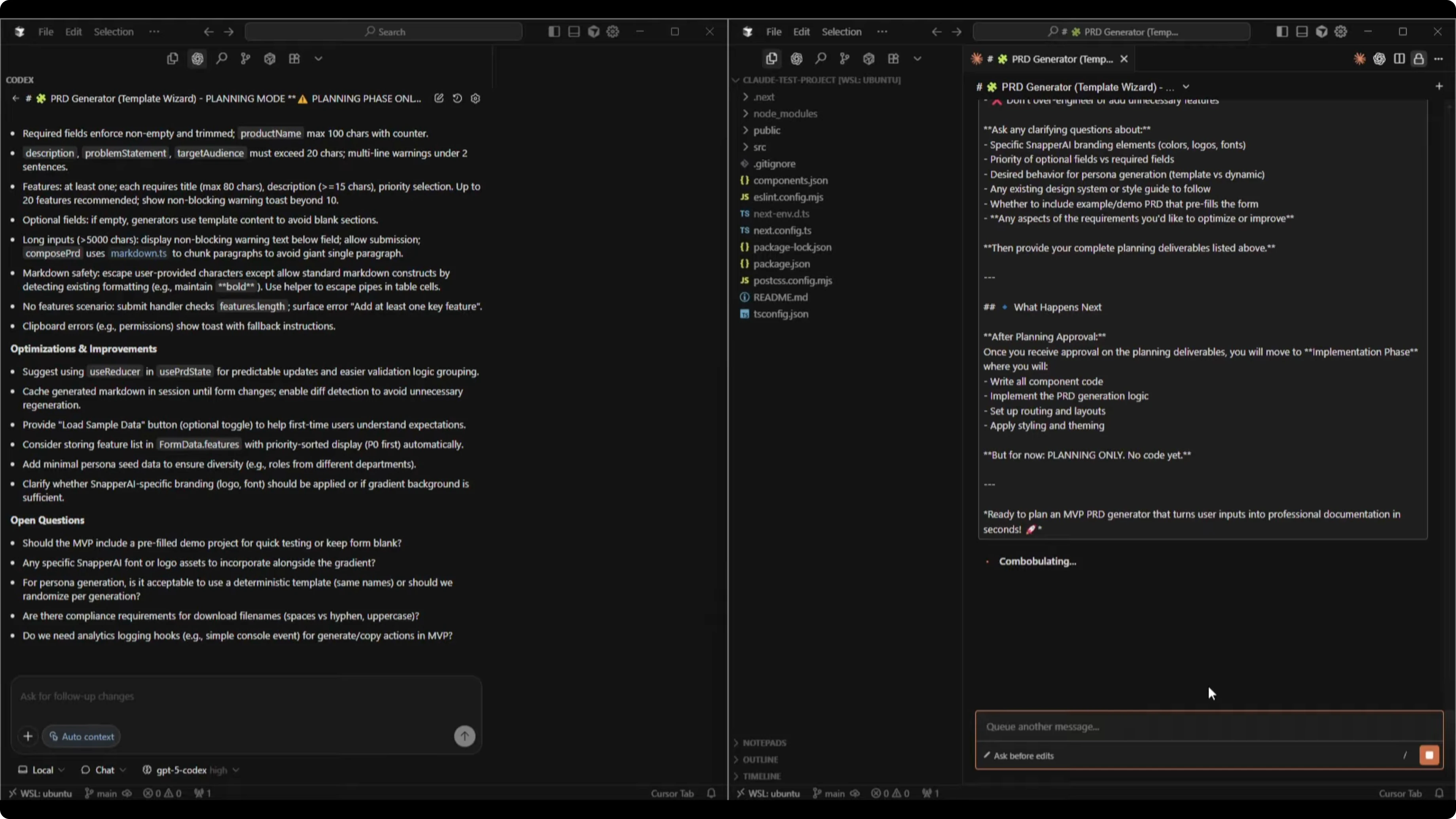
Codex’s optimization suggestions included using useReducer in a usePRState pattern for predictable updates and validation. It suggested grouping generated Markdown in a session until form changes, providing a Load Sample Data button, and adding minimal persona seed data. It asked about Snapper-specific branding, deterministic vs randomized generation, file name rules for downloads, analytics hooks, and a prefilled demo option.
Claude’s plan mirrored the structure with file structure, interfaces, component hierarchy, a components implementation plan, generation logic by PRD section, UI layout for desktop and mobile, and detailed edge cases with validation. It proposed simplifying persona generation for the MVP, using a visual badge for feature priority, setting smart defaults, and adding collapsible sections.
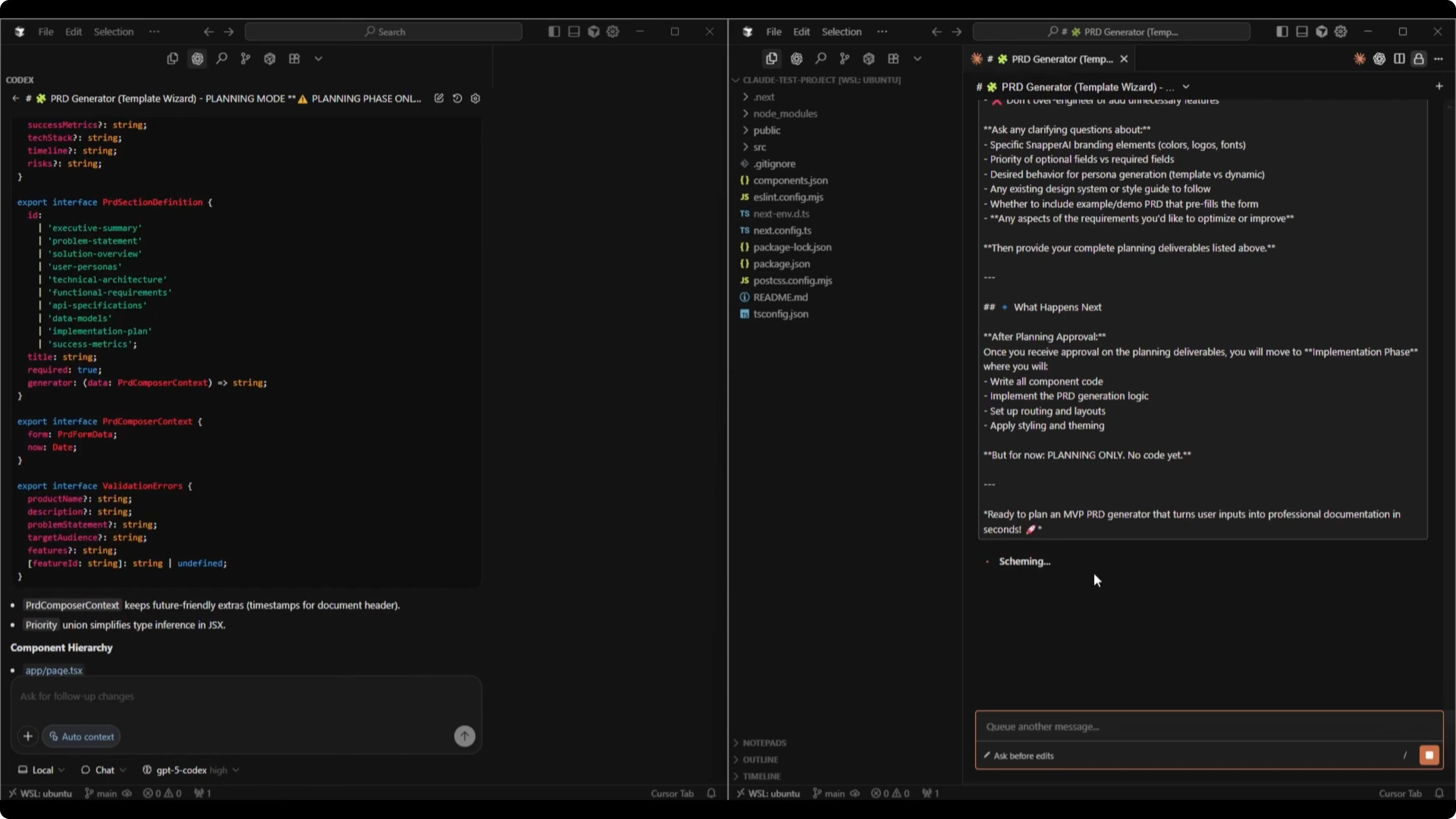
Claude also suggested including metadata comments in the download and treating live preview while typing as optional for the MVP. Its questions probed branding assets, a demo PRD example, analytics and tracking, error handling, future versions, and the tradeoff between content quality and speed.
I accepted all optimization and improvement suggestions from both. Claude presented a recommended MVP scope and flagged items to defer like live preview while typing, save and load PRDs, heavier NLP polish, and PDF exports.
To compare this matchup with a wider set of model face-offs, including multi-model lineups, check this round-up for additional context: Opus 4.5 vs GPT-5.1 Codex vs Gemini 3 Pro compared.
Comparison table - GPT-5 Codex vs Claude Sonnet 4.5
| Category | GPT-5 Codex | Claude Sonnet 4.5 |
|---|---|---|
| Planning detail | Strong, end-to-end plan with clear hierarchy and validation | Very detailed, especially in generation logic and edge cases |
| Speed to first plan | Faster in this run | Slower in this run |
| Transparency while thinking | Streams visible steps while composing | Opaque until the final output |
| Optimization ideas | useReducer state pattern, session-based Markdown grouping, sample data, persona seeding, analytics hooks | Simplified personas for MVP, visual priority badge, smart defaults, collapsible sections, metadata in downloads |
| Quality and UX questions | Branding assets, deterministic vs randomized output, file naming, demo PRD, analytics hooks | Branding assets, demo PRD, analytics, error handling, content quality vs speed, audience expectations |
| MVP scope clarity | Clear plan with targeted improvements | Clear plan with explicit deferrals for 1.1 features |
Use cases - GPT-5 Codex vs Claude Sonnet 4.5
GPT-5 Codex felt strong for fast iteration where you want to see the plan materialize as it thinks. I liked it for projects where streaming transparency helps me steer the plan in real time. The suggestions around predictable state and session-level grouping fit a tidy MVP.
Claude Sonnet 4.5 felt thorough in decision-heavy areas like content generation logic and guardrails. I liked it for cases where content quality, validation depth, and form UX polish matter a lot. The questions around speed vs quality and audience expectations were on point for PRD output.
Pros and cons - GPT-5 Codex
Codex produced a complete, structured plan quickly and exposed its thought process while writing. It offered practical architectural patterns like useReducer and useful developer-focused questions about compliance, analytics, and sample data. Its plan matched the MVP ethos and stayed tight.
Codex did not go quite as deep on generation logic per PRD section as Claude. In this planning pass, it asked solid questions but left a few UX niceties for later confirmation.
Pros and cons - Claude Sonnet 4.5
Claude produced a highly detailed plan with clear generation logic mapping and robust edge case coverage. It framed thoughtful tradeoffs around content quality, speed, and audience type that matter for PRD text. It also organized MVP vs 1.1 features cleanly.
Claude took longer and did not show intermediate steps while thinking. It leaned into refinement that could add time unless you explicitly keep the scope tight.
Step-by-step guide to reproduce this test
Create two identical Next.js TypeScript Tailwind projects as clean skeletons.
Initialize GPT-5 Codex in Cursor and set the model to GPT-5 Codex High in Chat or Plan mode.
Initialize Claude Code in Cursor, run /mod, and confirm Sonnet 4.5 as the selected model.
Prepare a shared directory with your PRD prompt templates and note its absolute path for both tools.
Construct a planning-only prompt that describes the app goal, inputs, PRD output structure, UI guidelines, constraints, types, and deliverables.
Add explicit MVP constraints and ask for clarifying questions and optimization suggestions.
Paste the identical prompt into both tools and wait for their planning outputs.
Review file structures, types, component hierarchy, generation logic, UI layout, validation strategy, and edge cases.
Accept or reject optimization suggestions, but keep the MVP scope focused.
Only after you approve a plan, switch each tool from planning to implementation mode to generate code.
Final thoughts
Both GPT-5 Codex and Claude Sonnet 4.5 produced strong planning documents for the PRD Generator Template Wizard. Codex was faster and practical with developer-friendly state patterns and transparent streaming, while Claude pressed deeper on generation logic, validation, and content quality tradeoffs.
I accepted all suggested improvements from both to see their distinct approaches show up in implementation. Based on planning alone, there was no single clear winner here. They were both solid, and the better choice will depend on how much you value speed and streaming transparency versus depth on content and validation.
Subscribe to our newsletter
Get the latest updates and articles directly in your inbox.

Related Posts

8 Best Claude Code Plugins in 2026 (You Need to Know)
8 Best Claude Code Plugins in 2026 (You Need to Know)

7 Best Claude Code Skills (You Need to Know)
7 Best Claude Code Skills (You Need to Know)

Claude Code Desktop IDE Features (You Need to Know)
Claude Code Desktop IDE Features (You Need to Know)