

GPT-5.2-Codex vs Opus 4.5
OpenAI just launched GPT-5.2-Codex, their new coding specialist model. Opus 4.5 is a generalist model that has been performing really well on coding tasks in my earlier comparison work. For this test, I asked both models to build a Tetris game from the same PRD and compared the output.
If you want broader context on how these families stack up across tasks, see this cross-model head-to-head of GLM 4.7, Opus 4.5, and GPT-5.2. That background helps frame where specialist and generalist models have been strong. This Tetris build provides a focused, identical-spec test.
GPT-5.2-Codex vs Opus 4.5
Both models received the exact same PRD. The core features included all seven standard Tetris shapes with their correct colors and a seven-bag randomizer for fair piece distribution. The PRD also required a ghost piece, hold piece, and next piece preview.
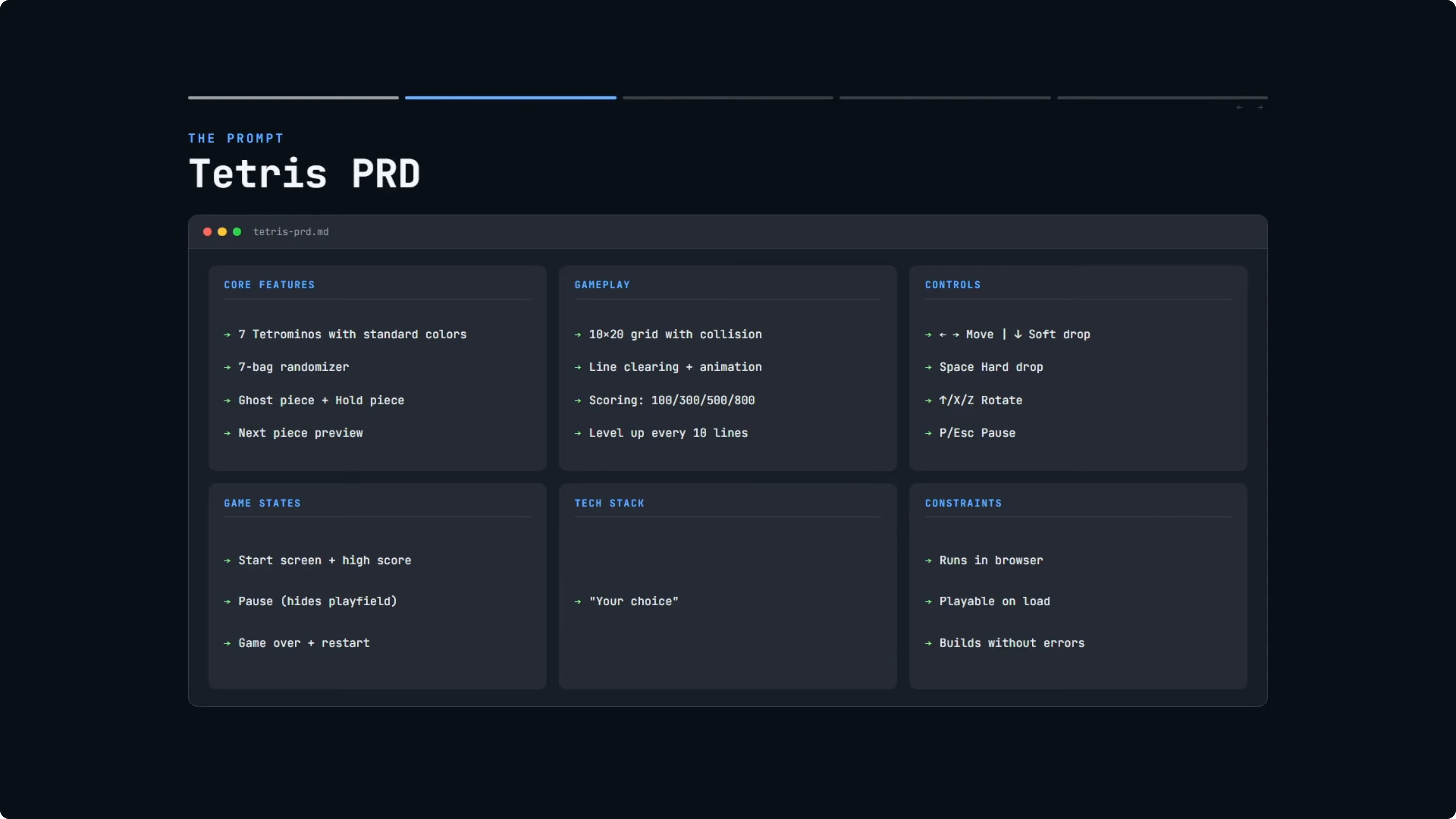
Gameplay instructions covered the standard grid with collision detection, line clearing with a visual animation, and standard Tetris scoring. Controls had to match the standard Tetris set. Game states had to include a start screen, a pause screen that hides the play field, and a game over screen with the option to restart.
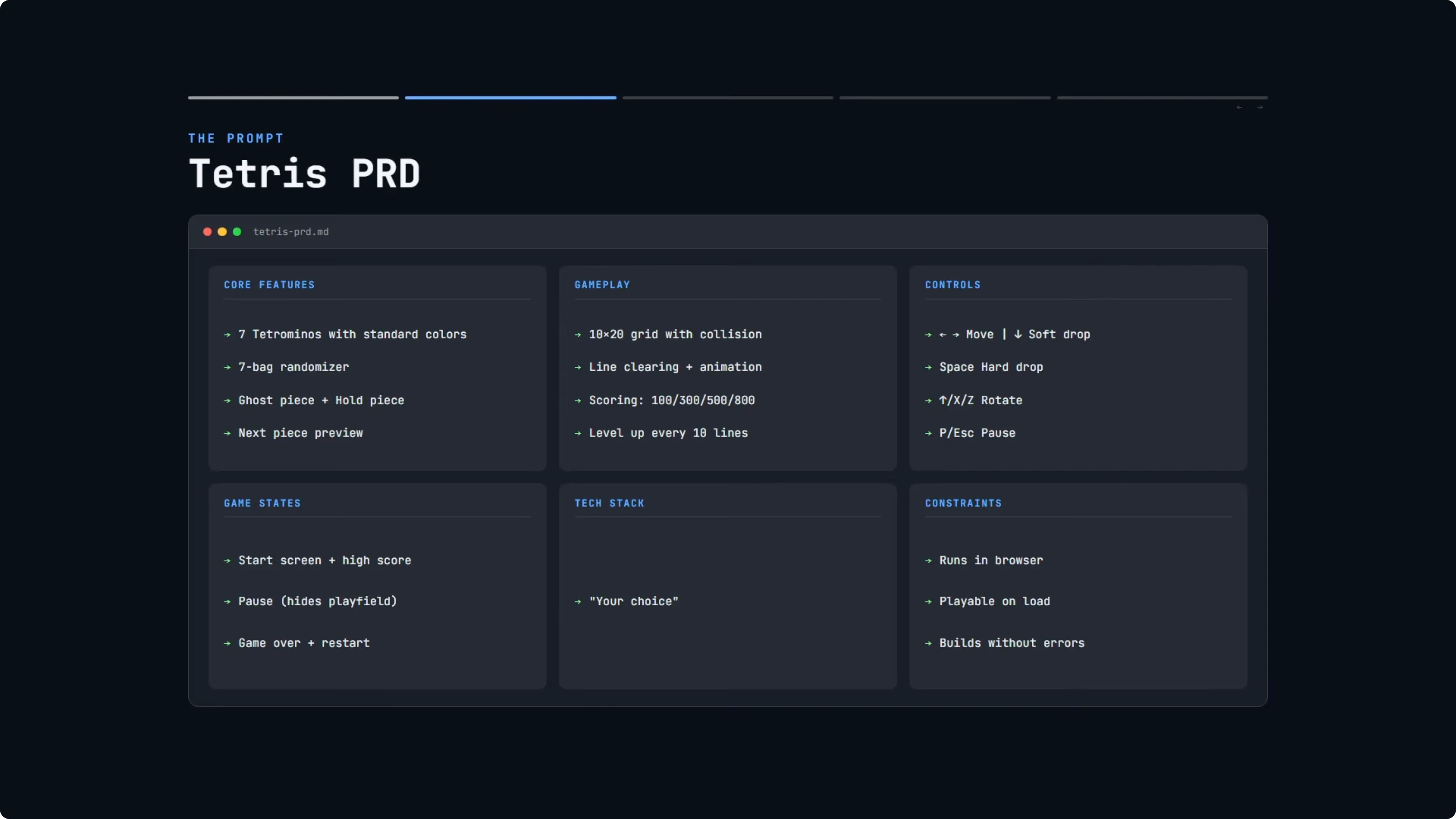
Constraints were minimal. The game needed to run in a browser, be playable immediately on load, and build without errors. There was full freedom to choose the tech stack.
How I ran GPT-5.2-Codex vs Opus 4.5
I provided both models with the same PRD prompt. GPT-5.2-Codex was run through the Codex CLI. Opus 4.5 was run in Cursor chat with Extra High Reasoning enabled.
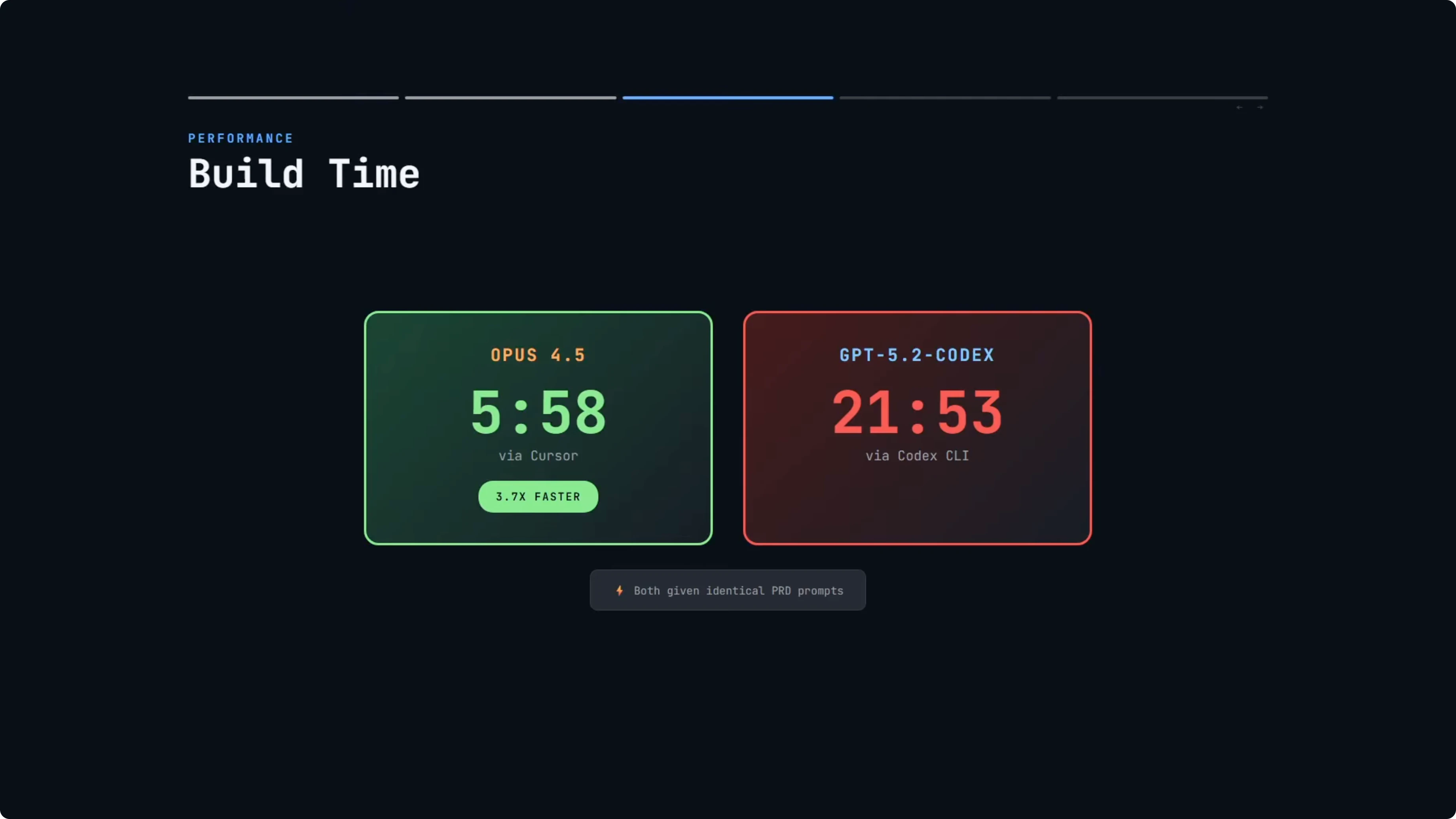
I compared build times and build approach once both completed. Opus 4.5 finished in 5 minutes and 58 seconds. GPT-5.2-Codex with Extra High Reasoning finished in 21 minutes and 53 seconds.
If you want to see another tight comparison inside the Opus family, I also published a focused look at Opus 4.6 vs Opus 4.5. That context is useful for reading Opus 4.5’s behavior here.
Build times and reasoning
Opus 4.5 was almost four times faster. It is expected that GPT-5.2-Codex would take longer with Extra High Reasoning, since it spends more time thinking and reasoning. But nearly 22 minutes is a long time for a single-file game.
When I asked GPT-5.2-Codex what took the most time, it pointed to the game logic and rendering loop. It specifically called out lock delay, SRS wall kicks, the line clear animation, and input handling with DAS. Those are genuinely the complex parts.
Opus handled all of that in under six minutes. That result highlights a meaningful delta in wall-clock speed. Output quality still needed a side-by-side check.
For more Codex-focused matchups beyond this build, see my broader comparison of GPT-5.3 Codex vs Opus, Kimi, and Qwen. It gives a wider lens on how Codex families behave across tasks.
Tech stack choices
Opus 4.5 went with vanilla JavaScript. No frameworks, just plain HTML, CSS, and JavaScript across three files and roughly 1,500 lines of code. You open the HTML file in a browser, and it works.
When I asked Opus why it did it this way, it said for a real-time game like Tetris, Vanilla JS is actually the optimal choice. Zero overhead, no virtual DOM diffing eating into your frame budget, direct canvas control with immediate mode rendering at 60 fps, tiny footprint, instant load. React’s reconciliation system does not help when you are redrawing a canvas 60 times per second.
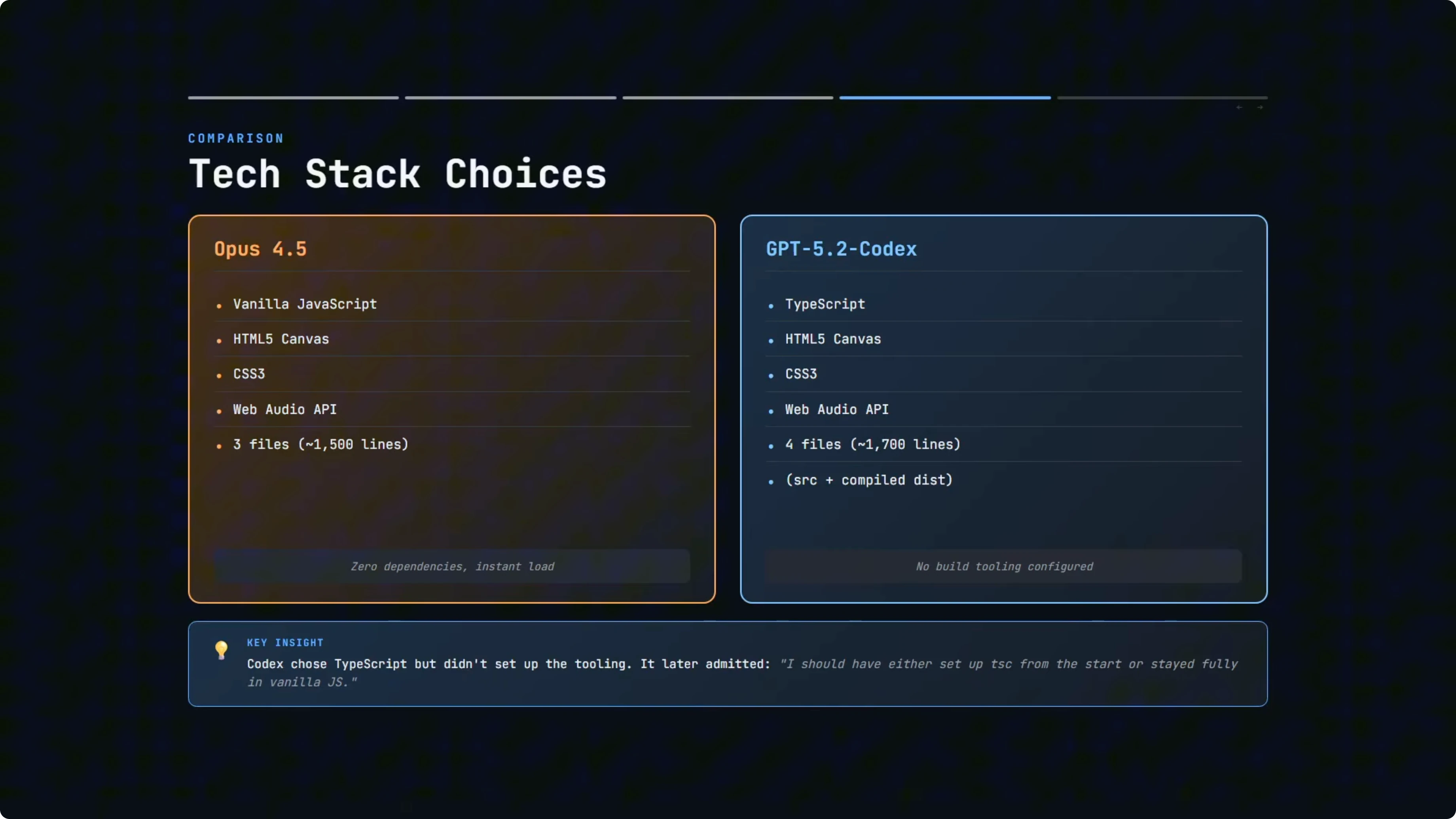
GPT-5.2-Codex chose TypeScript, which is arguably the more professional choice for larger codebases. You get type safety, better IDE support, and bugs get caught at compile time rather than runtime. The project was about 1,700 lines of code in total.
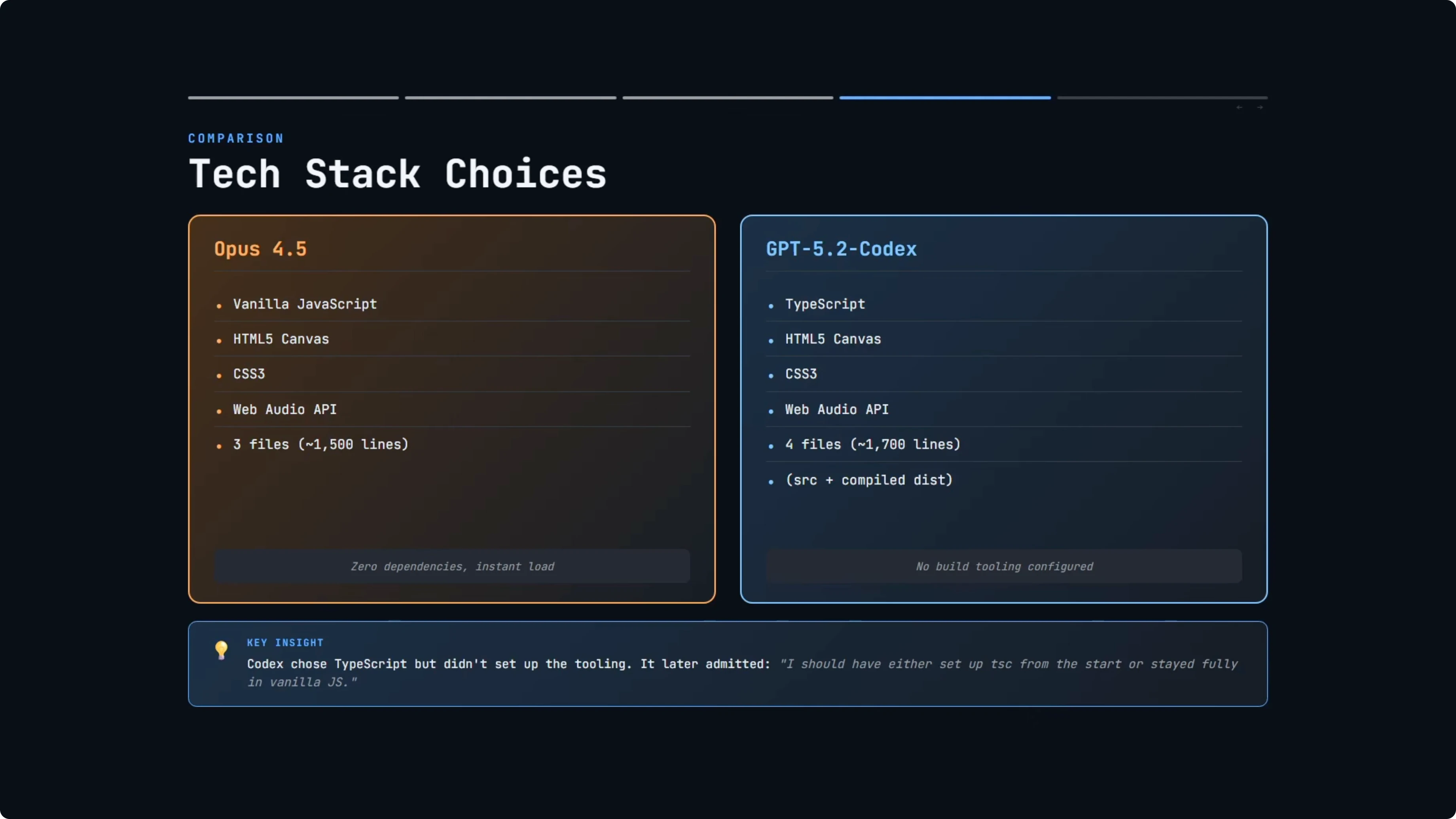
Here is where it got odd. GPT-5.2-Codex wrote TypeScript but did not set up any build tooling. It manually compiled the TypeScript to JavaScript, so you ended up with both a source file and a compiled dist file, essentially the same code twice.
It even suggested adding a TypeScript build step as a future improvement. When I asked why it did it this way, it said it skipped toolchain setup to keep it runnable immediately with zero installs. It acknowledged that it should have either set up TSC from the start or stayed fully in vanilla JS to avoid the mismatch.
If you are comparing multi-model stacks that include Codex and frontier models across web builds, you might also find this look at Gemini 3.1 Pro vs Opus 4.6 vs GPT-5.3 Codex useful. It complements the observations here on stack choices and runtime behavior.
Play test results
Opus 4.5’s Tetris starts with Enter. Audio is present and the core loop feels responsive. Ghost piece rendering is clear, and you can press Down to speed the piece, which also awards points.
Rotation works smoothly, lines clear with animation, and the score updates. Losing the game brings up a game over screen with a final score and Enter to play again. The visual style includes 3D gradient blocks and styled control icons that contribute to a more polished feel.
GPT-5.2-Codex’s version also starts with Enter. Audio is present, including movement sounds on horizontal input. The ghost piece is rendered in a way that is quite close in color to the active piece, so it reads less like a ghost and more like a variant.

Soft drop does not award points in this version. Clearing lines works correctly, and the score increments on line clears. The game over screen appears as expected with a prompt to press Enter to retry.

For a broader spread that pits GLM, Opus, and Codex models in the same ring, I also ran a larger face-off in GLM 5 vs Opus 4.6 vs GPT-5.3 Codex. Pair that with this Tetris test to see patterns that hold across projects.
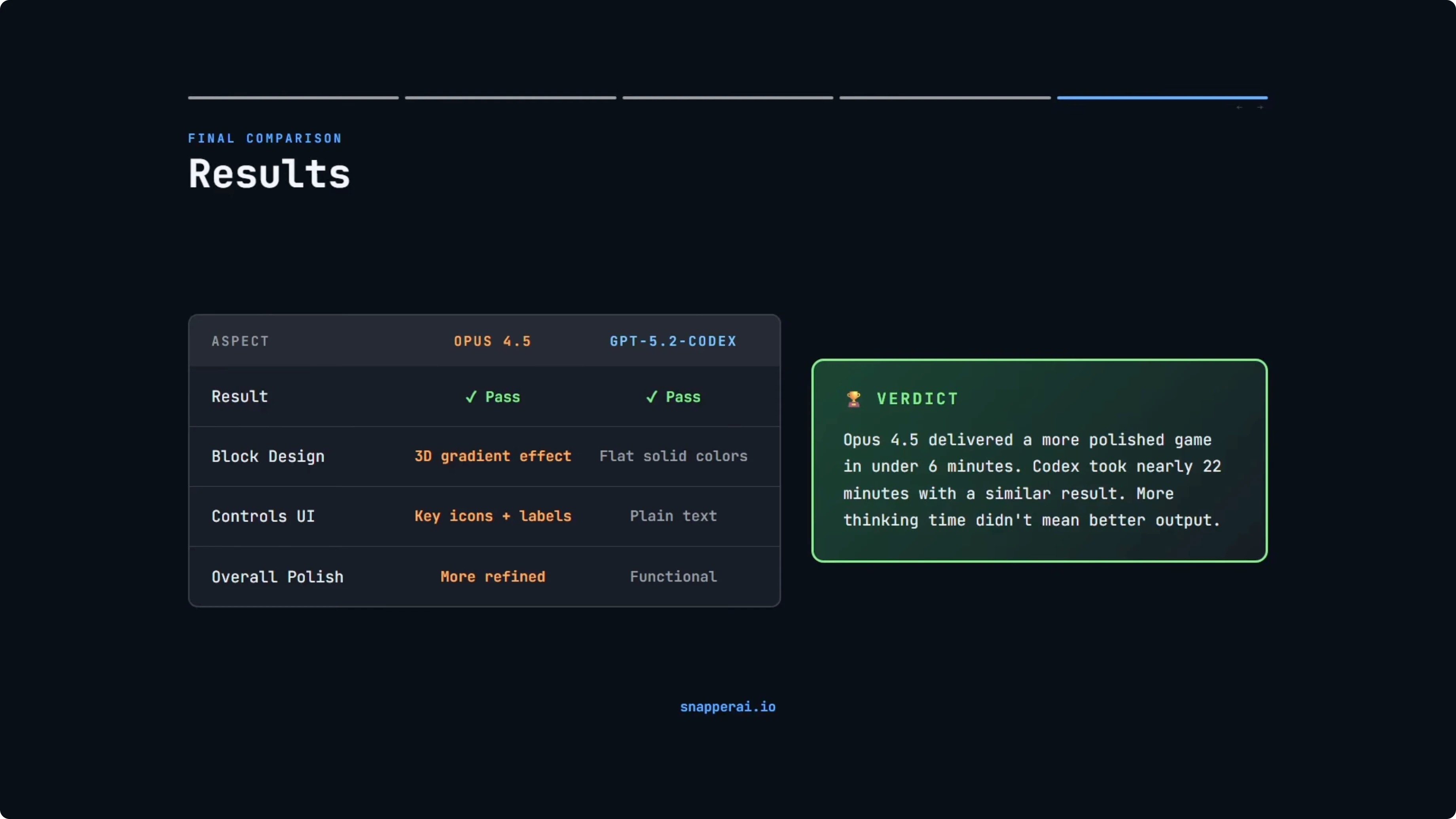
Results summary for GPT-5.2-Codex vs Opus 4.5
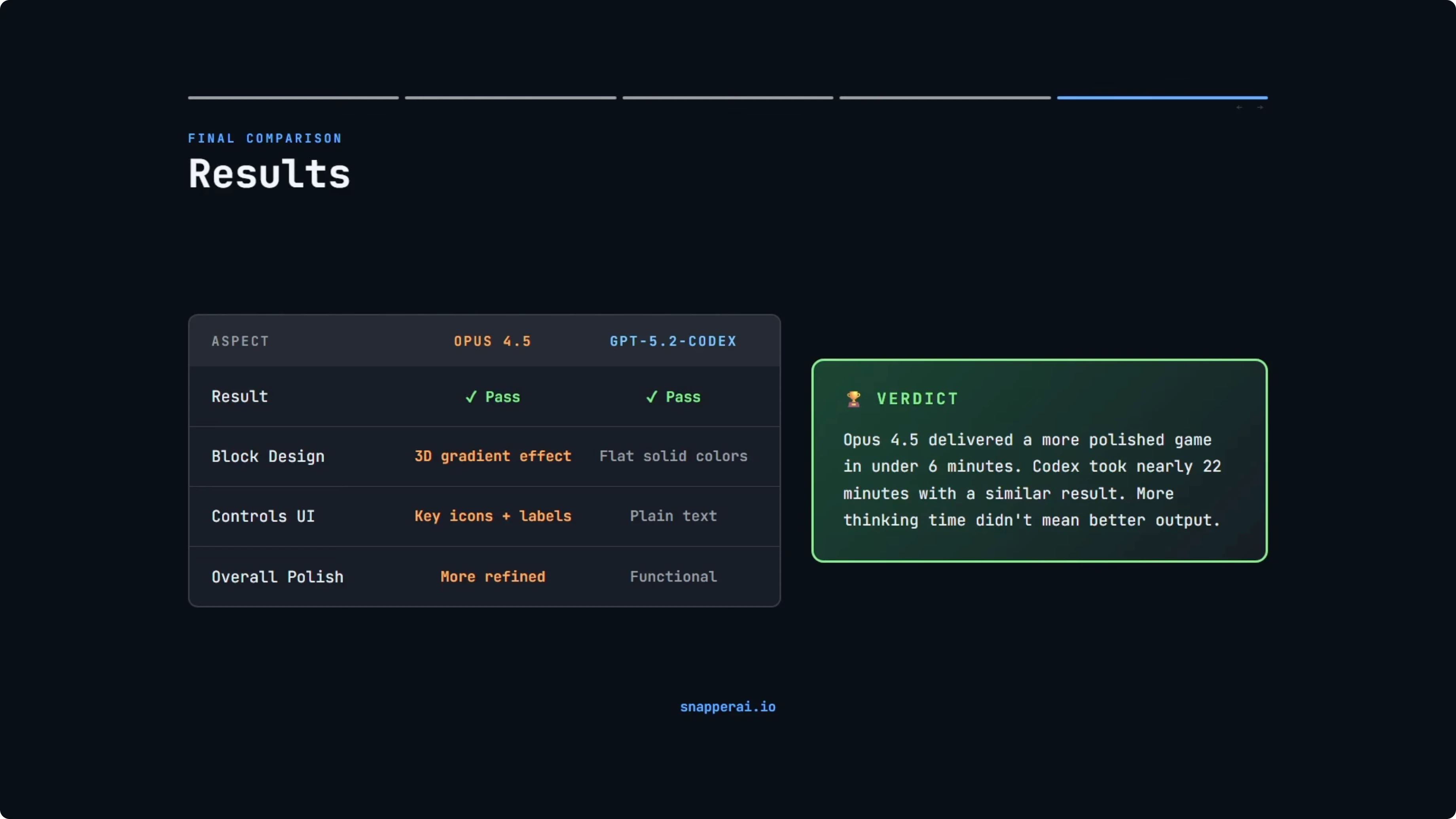
Both models passed. Both produced fully playable Tetris games with all the core mechanics working correctly. No bugs and no crashes.
Build time was the biggest spread. Opus 4.5 finished just under six minutes, and GPT-5.2-Codex took nearly 22 minutes with Extra High Reasoning. That is a significant difference in time.
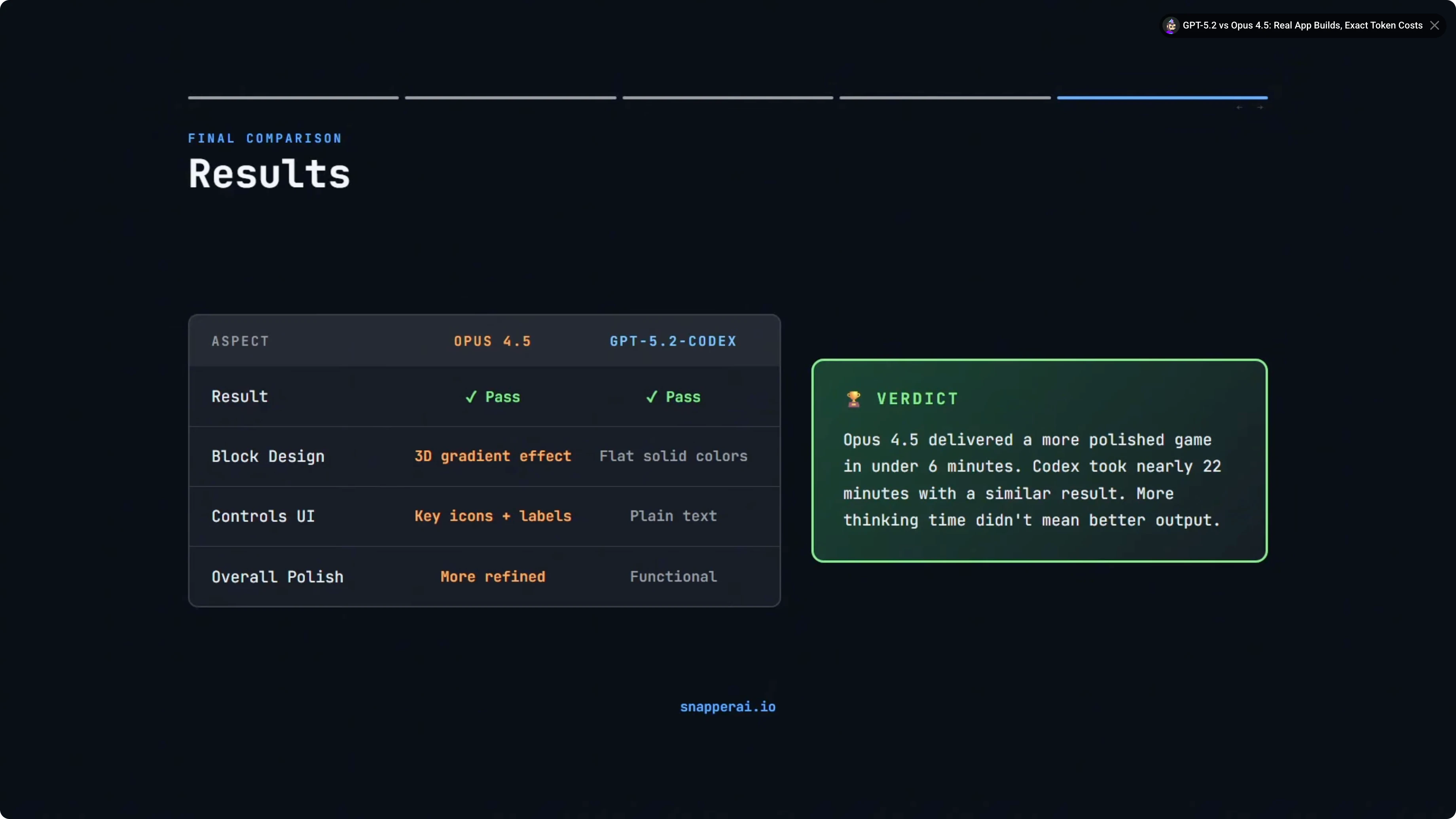
Tech stack choices diverged. Opus 4.5 chose vanilla JavaScript with zero dependencies. GPT-5.2-Codex chose TypeScript but without proper tooling, a partial commitment that it later acknowledged was not ideal.
Visual polish favored Opus 4.5. The 3D gradient blocks and styled controls pushed it slightly ahead on fit and finish. GPT-5.2-Codex was clean and functional but simpler.
To be fair to GPT-5.2-Codex, in a larger project with multiple developers and ongoing maintenance, TypeScript would be the better choice. Type safety matters when codebases grow. For a single-file game built in one shot, Opus 4.5 probably made the better call with vanilla JavaScript.
If you are comparing families that include GLM, Opus, and GPT-5.x Codex across multiple axes, also see this expanded analysis of Codex vs Opus, Kimi, and Qwen. It adds context to the specialist vs generalist trade-offs highlighted here.
Comparison overview table
| Aspect | Opus 4.5 | GPT-5.2-Codex |
|---|---|---|
| Build time | 5m 58s | 21m 53s (Extra High Reasoning) |
| Stack | Vanilla HTML/CSS/JS | TypeScript, manual compile, no toolchain |
| Files and size | 3 files, ~1,500 LOC | ~1,700 LOC, source + dist duplicates |
| Run setup | Open HTML file and play | Play compiled JS, TS suggested with future build step |
| Scoring | Soft drop awards points, standard scoring | No soft drop points, line clear awards points |
| Visuals | 3D gradient blocks, styled controls | Flat blocks, simpler UI |
| Complex logic | SRS, lock delay, DAS handled within build time | Named lock delay, SRS wall kicks, line clear animation, DAS as time sink |
| Stability | No crashes observed | No crashes observed |
Use cases
Opus 4.5 fits quick-turn builds that need to run instantly in a browser with minimal setup. Real-time canvas rendering and tight frame budgets benefit from a no-framework path with direct control. If you need speed to a working prototype or a clean single-file deliverable, it is a strong pick.
GPT-5.2-Codex fits projects where long-term maintainability and refactoring discipline are priorities. OpenAI highlights Codex for refactors and migrations, taking existing codebases and transforming them. If the task grows in complexity, the extra thinking time may pay off in correctness on tricky logic.
For cross-vendor matchups that include GLM and GPT-5.x Codex lines, see this broader comparison of GLM 4.7 vs Opus 4.5 vs GPT-5.2. It pairs well with the task-focused results here.
Pros and cons
Opus 4.5 was much faster and delivered slightly better visual polish. The vanilla JS stack meant immediate run and a tiny footprint. The trade-off is less type safety for long-lived, multi-developer projects.
GPT-5.2-Codex approached the build with TypeScript, aiming for better safety and IDE support. It acknowledged the inconsistency of skipping proper tooling and duplicating source and dist files. Visuals were simpler, and the soft drop did not award points.
If you need another angle on how these models compare with a third competitor in the mix, check out this tri-model breakdown of GLM 5, Opus 4.6, and GPT-5.3 Codex. It complements the findings above.
Reproduce the test
Copy the PRD that specifies all seven Tetris shapes with correct colors, a seven-bag randomizer, ghost piece, hold, and next preview. Include a standard grid with collision detection, line clear animation, and standard scoring. Add start, pause that hides the play field, and game over with restart, and require immediate in-browser play with no build errors.
Run GPT-5.2-Codex through the Codex CLI with the PRD as the prompt. Allow it to complete and note build time. If it outputs TypeScript, check for manual compilation and any suggested improvements.
Run Opus 4.5 in Cursor chat with Extra High Reasoning, using the same PRD. Allow it to complete and note build time. Open each build in a browser and verify controls, ghost piece, soft drop behavior, line clear animation, scoring, and game state transitions.
Final thoughts
Both models delivered fully playable Tetris games that met the spec. Opus 4.5 was faster and edged ahead on visual polish. GPT-5.2-Codex took longer but tackled complex logic methodically and aimed for TypeScript benefits, even though it skipped tooling.
This was a greenfield build. OpenAI positions Codex strongly for refactors and migrations, which is a different skill than starting from scratch. I plan to test larger, more complex tasks and, once API access is available, track tokens and cost to see how output quality scales with complexity.
Subscribe to our newsletter
Get the latest updates and articles directly in your inbox.

Related Posts

8 Best Claude Code Plugins in 2026 (You Need to Know)
8 Best Claude Code Plugins in 2026 (You Need to Know)

7 Best Claude Code Skills (You Need to Know)
7 Best Claude Code Skills (You Need to Know)

Claude Code Desktop IDE Features (You Need to Know)
Claude Code Desktop IDE Features (You Need to Know)