
Table Of Content
- Dashboard build - Gemini 3.1 Pro vs Opus 4.6 vs GPT-5.3 Codex: Which Tops Coding Benchmarks?
- How I ran the dashboard build test
- Visual comprehension - Gemini 3.1 Pro vs Opus 4.6 vs GPT-5.3 Codex: Which Tops Coding Benchmarks?
- How I ran the visual comprehension test
- Comprehension suite - Gemini 3.1 Pro vs Opus 4.6 vs GPT-5.3 Codex: Which Tops Coding Benchmarks?
- Strict output rules - code example
- How I ran the comprehension suite
- Model upgrades in focus - Gemini 3.1 Pro vs Opus 4.6 vs GPT-5.3 Codex: Which Tops Coding Benchmarks?
- Comparison overview - Gemini 3.1 Pro vs Opus 4.6 vs GPT-5.3 Codex: Which Tops Coding Benchmarks?
- Use cases, pros and cons - Gemini 3.1 Pro vs Opus 4.6 vs GPT-5.3 Codex: Which Tops Coding Benchmarks?
- GPT-5.3 Codex
- Opus 4.6
- Gemini 3.1 Pro
- Step by step - reproduce the three tests
- Final thoughts - Gemini 3.1 Pro vs Opus 4.6 vs GPT-5.3 Codex: Which Tops Coding Benchmarks?
Gemini 3.1 Pro vs Opus 4.6 vs GPT-5.3 Codex: Which Tops Coding Benchmarks?
Gemini API Pricing Calculator
Dynamically estimate your Google Gemini API costs for text, audio, images, and context caching. Covers new 3.1 Pro, Flash, and 2.5 models.
Table Of Content
- Dashboard build - Gemini 3.1 Pro vs Opus 4.6 vs GPT-5.3 Codex: Which Tops Coding Benchmarks?
- How I ran the dashboard build test
- Visual comprehension - Gemini 3.1 Pro vs Opus 4.6 vs GPT-5.3 Codex: Which Tops Coding Benchmarks?
- How I ran the visual comprehension test
- Comprehension suite - Gemini 3.1 Pro vs Opus 4.6 vs GPT-5.3 Codex: Which Tops Coding Benchmarks?
- Strict output rules - code example
- How I ran the comprehension suite
- Model upgrades in focus - Gemini 3.1 Pro vs Opus 4.6 vs GPT-5.3 Codex: Which Tops Coding Benchmarks?
- Comparison overview - Gemini 3.1 Pro vs Opus 4.6 vs GPT-5.3 Codex: Which Tops Coding Benchmarks?
- Use cases, pros and cons - Gemini 3.1 Pro vs Opus 4.6 vs GPT-5.3 Codex: Which Tops Coding Benchmarks?
- GPT-5.3 Codex
- Opus 4.6
- Gemini 3.1 Pro
- Step by step - reproduce the three tests
- Final thoughts - Gemini 3.1 Pro vs Opus 4.6 vs GPT-5.3 Codex: Which Tops Coding Benchmarks?
Google just released Gemini 3.1 Pro, and on coding benchmarks, it beats GPT-5.3 Codex and comes close to Opus 4.6. I ran three real coding tests and compared it against both models to see if the benchmarks hold up. On one of those tests, Gemini did something no other model has managed to do so far.
In my latest run, Codex excelled at coding tasks. It one-shot an API integrated earthquake monitor dashboard and did it three times faster than Opus 4.6. But when it came to visual comprehension, Opus clearly outperformed Codex.
I put Gemini 3.1 Pro through both of those tests. I also ran it through my comprehension benchmark suite, which tests bug fixes, migrations, and refactors on a real code base. By the end, it was clear where Gemini 3.1 Pro sits against Codex and Opus across all three tests.
For more background on Codex against multiple peers, see this comparison: GPT-5.3 Codex versus top rivals.
Dashboard build - Gemini 3.1 Pro vs Opus 4.6 vs GPT-5.3 Codex: Which Tops Coding Benchmarks?
Quick recap. Quake Watch is a real-time earthquake monitoring dashboard built from a detailed PRD. It pulls live data from the USGS API and displays it across an interactive map, a filterable event feed, stat cards, and charts.
I gave all models the full PRD with no additional guidance, and they had to build from that. This is the Codex build. The map renders correctly, the event feed scrolls properly, and the stats and charts are all there.
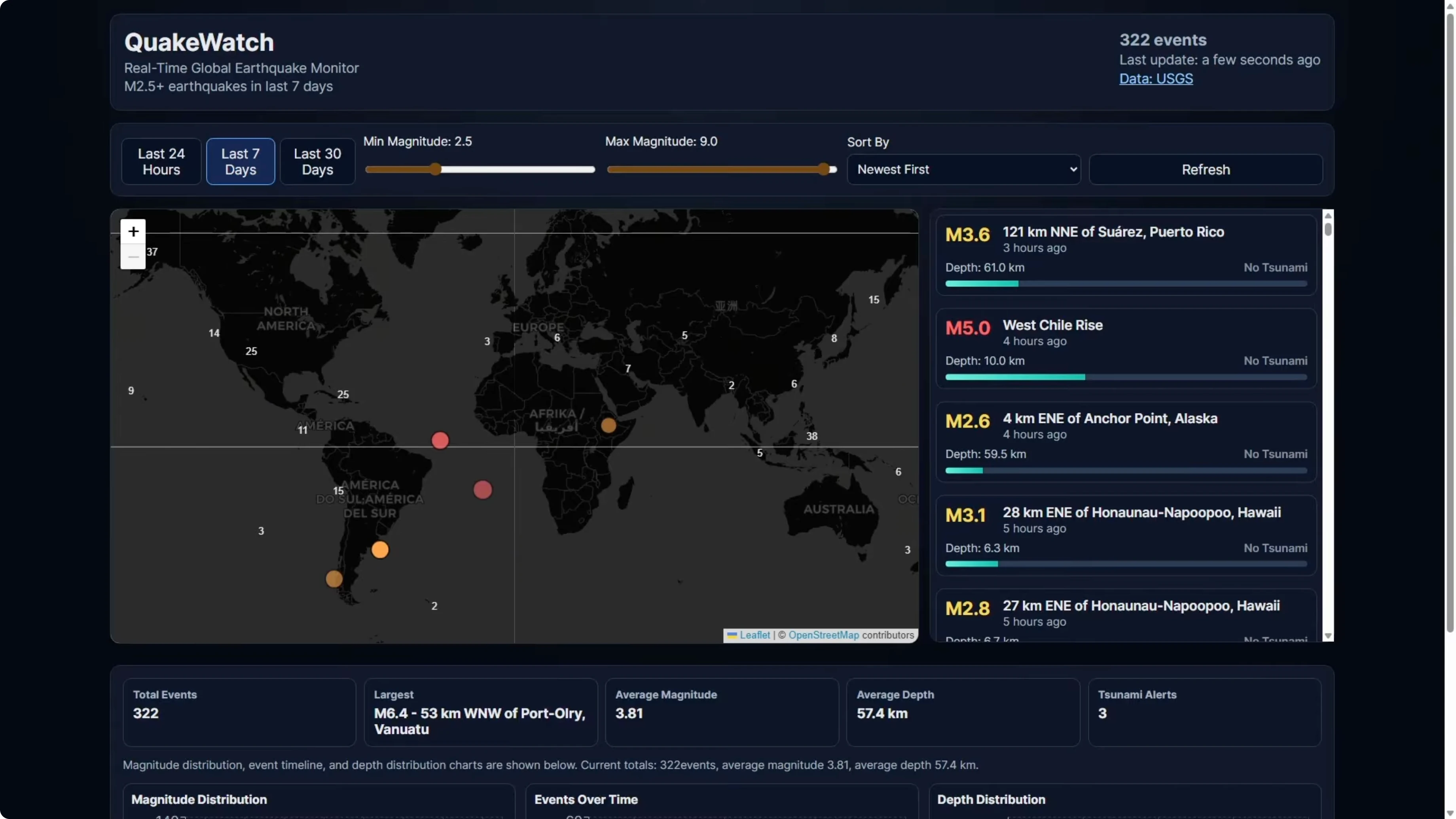
Codex built this in 7 minutes as a clean one-shot build with no repair turns needed. This is the benchmark that all models are trying to reach. Now, here is the Gemini 3.1 Pro version.
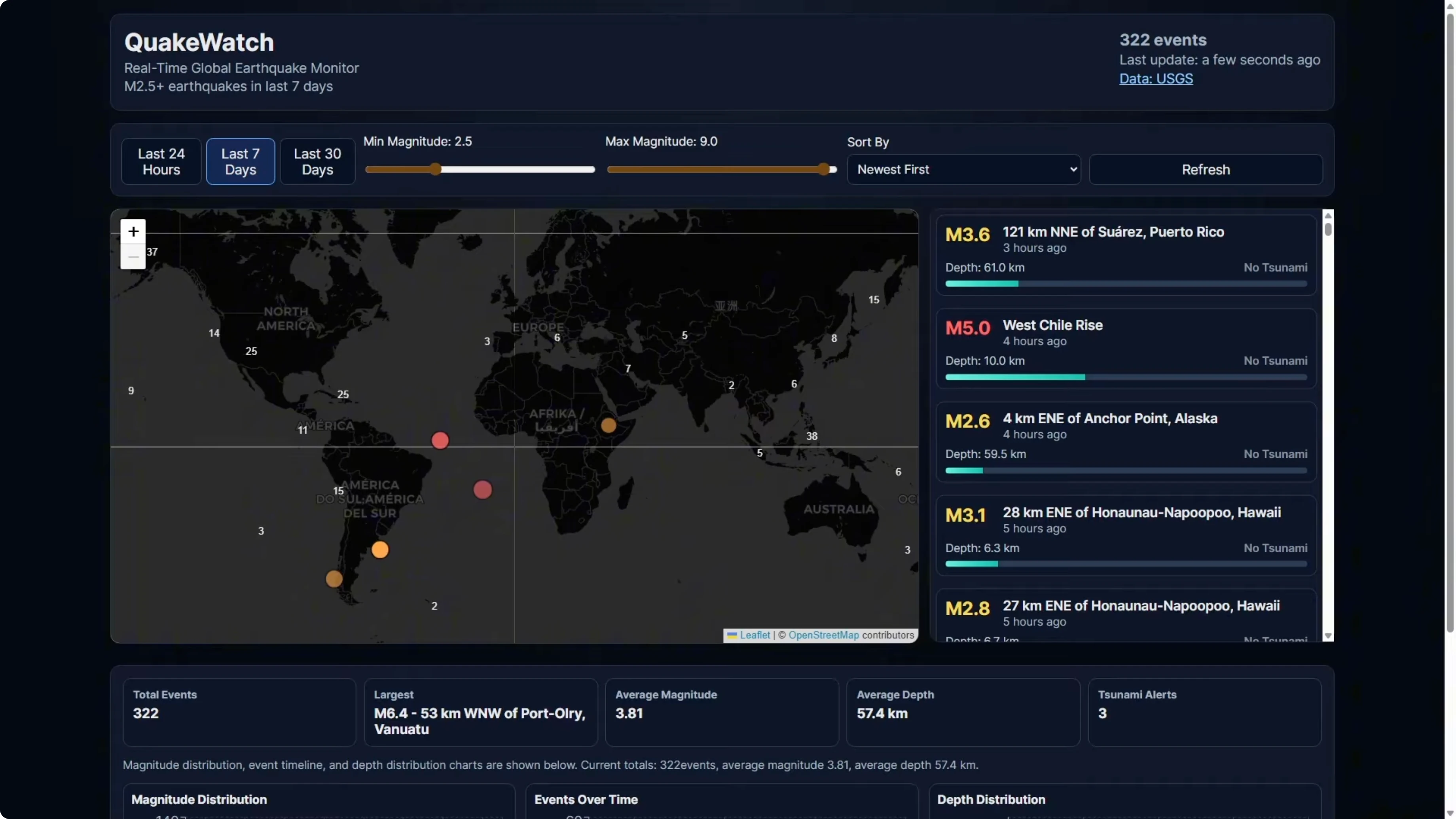
The build time came in at 6 minutes and 32 seconds. It was actually faster than Codex on the first attempt. It used a very similar tech stack to Codex and Opus: React, TypeScript, Tailwind, Recharts, and React Leaflet for the map.
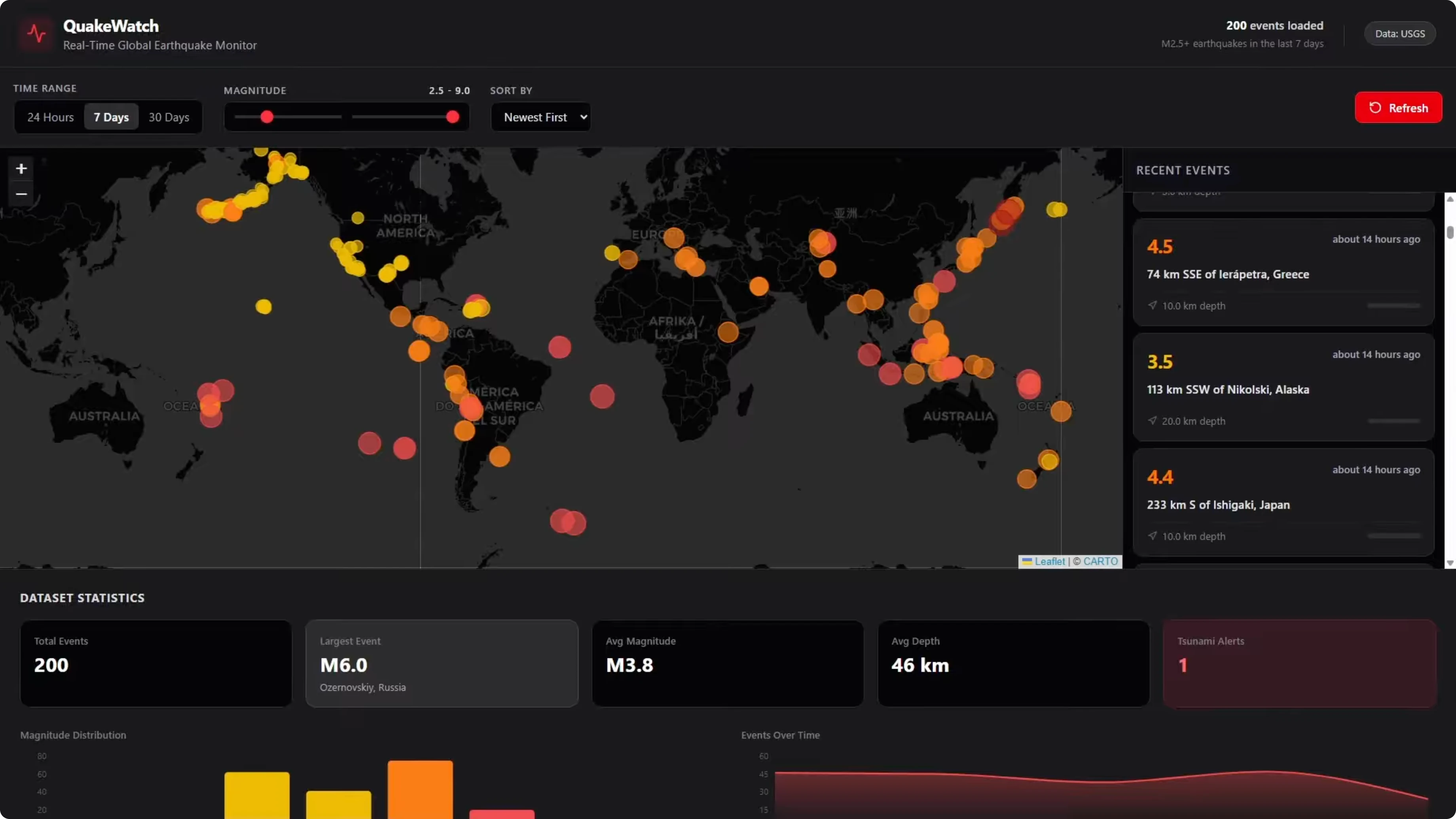
The initial build came back without any UI styling, so I gave it a repair turn to fix that. After the repair turn, the map is rendering properly, the markers are color coded by severity, the event feed is working with the scroll bar, and the stat cards and charts are all there. It is a solid looking build.
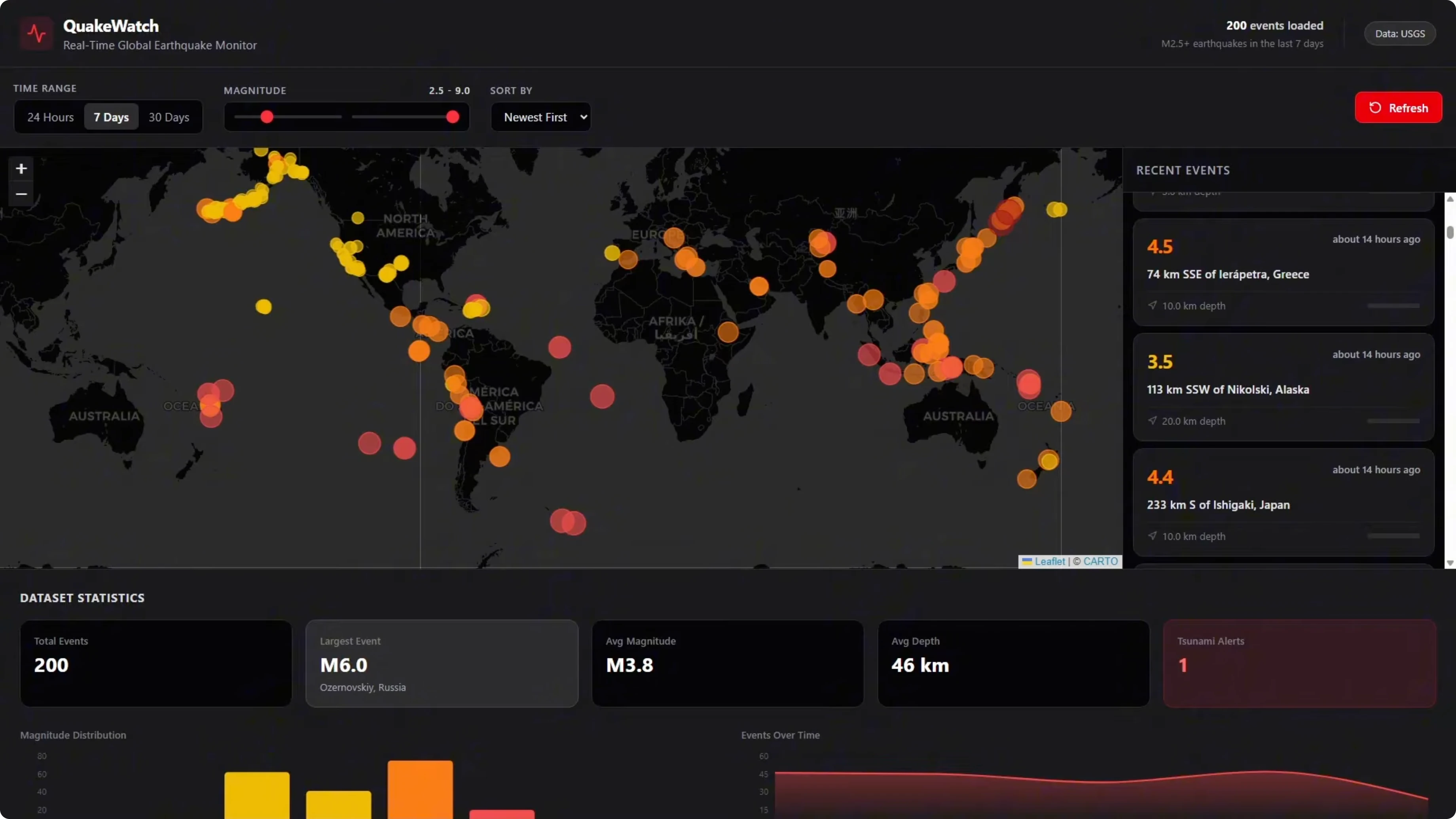
The one issue is there is no full page scroll bar, so the content below the map is cut off. I could not scroll down to see the content at the bottom. It is an okay effort, but it is not a clean build.
Codex is still the winner on this test. Even though Gemini was technically faster on build time for the first attempt, Codex shipped a fully working dashboard on one shot with no issues. Gemini needed a repair turn and still has that scroll issue.
It is worth noting that this is a much better result than GLM 5 and Opus 4.6. GLM 5 took over 38 minutes and had map layout issues even after a repair turn. Opus 4.6 took 22 minutes and also had map rendering issues after a repair turn.
For more on Opus in app builds and image tasks, see this profile: Opus 4.6 capabilities.
How I ran the dashboard build test
I provided the exact same PRD to each model with no additional guidance. I required a single pass build and measured time from first token to working app. I allowed one repair turn only if the initial render had clear fixable issues.
Visual comprehension - Gemini 3.1 Pro vs Opus 4.6 vs GPT-5.3 Codex: Which Tops Coding Benchmarks?
For the visual comprehension test, I took screenshots of the Stripe homepage and asked each model to recreate it based solely on the images. There was no written spec, no component list, and the model could not fetch the URL. It had to work from the screenshots only.
I ran Gemini 3.1 Pro in Cursor for these tests. It was the same conditions I used for Opus and Codex, keeping it consistent with all models using the same setup. There is a lot going on in this page, so it is a solid test of image to code performance.
Here is the Opus version. Opus won this test. It got the hero and the logo bar right.
If I scroll down, it also got the product showcase cards with detailed UI mockups inside them. This is where it really separated from Codex. Codex recreated the section but left the inner mockups blank, whereas Opus recreated all of them.
Opus created all the components that exist on the Stripe homepage and the design is very close to the screenshots I provided. Opus did a great job. This is the benchmark that Gemini is trying to reach.
Now, here is the Gemini 3.1 Pro build. There are clear differences compared to the actual Stripe homepage. The hero headline says financial infrastructure for the internet, whereas the real page says financial infrastructure to grow your revenue.
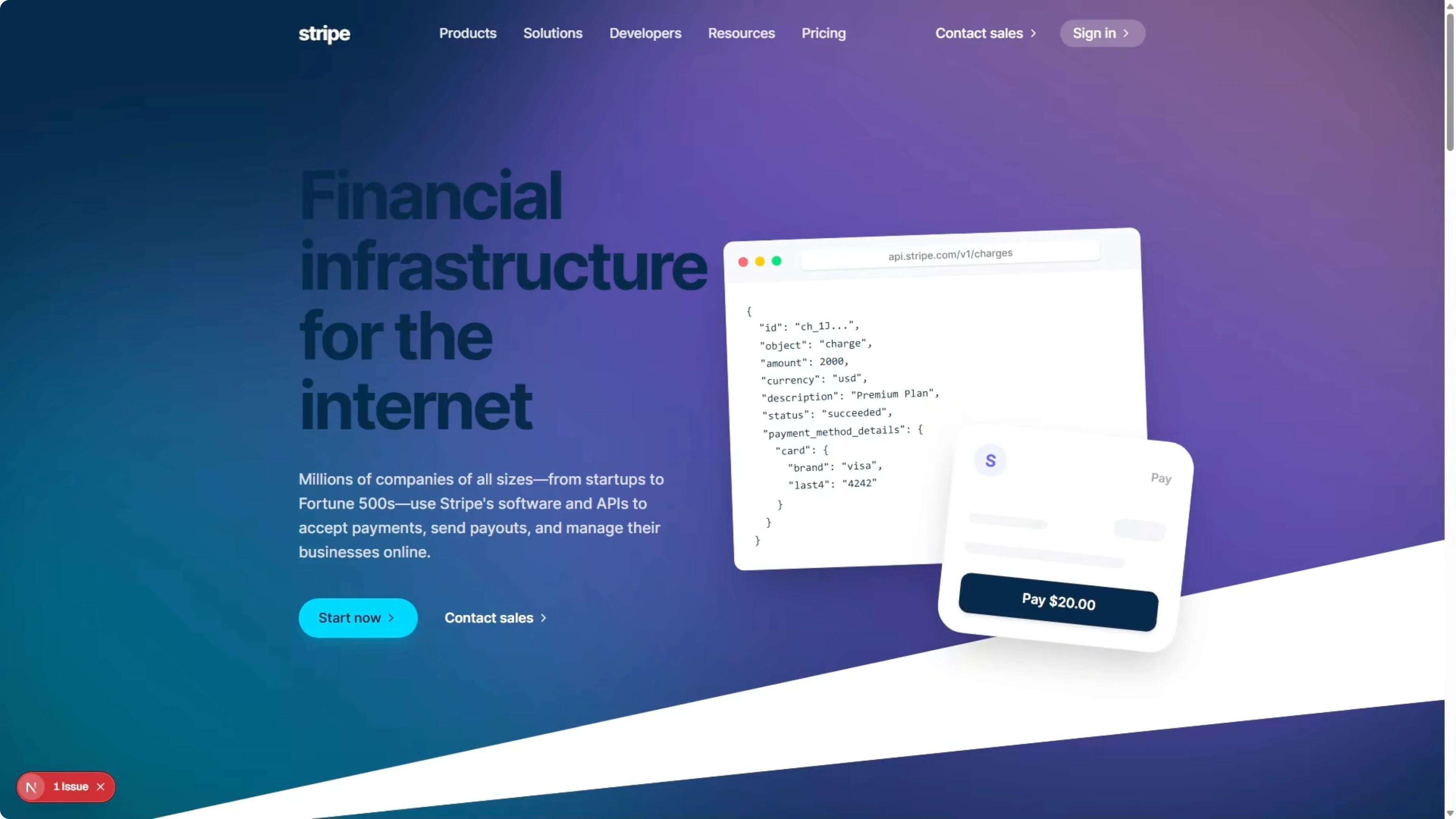
The logo bar has some of the wrong logos. It includes Deliveroo, which is not a partner in the screenshots. It invented that and put it in there.
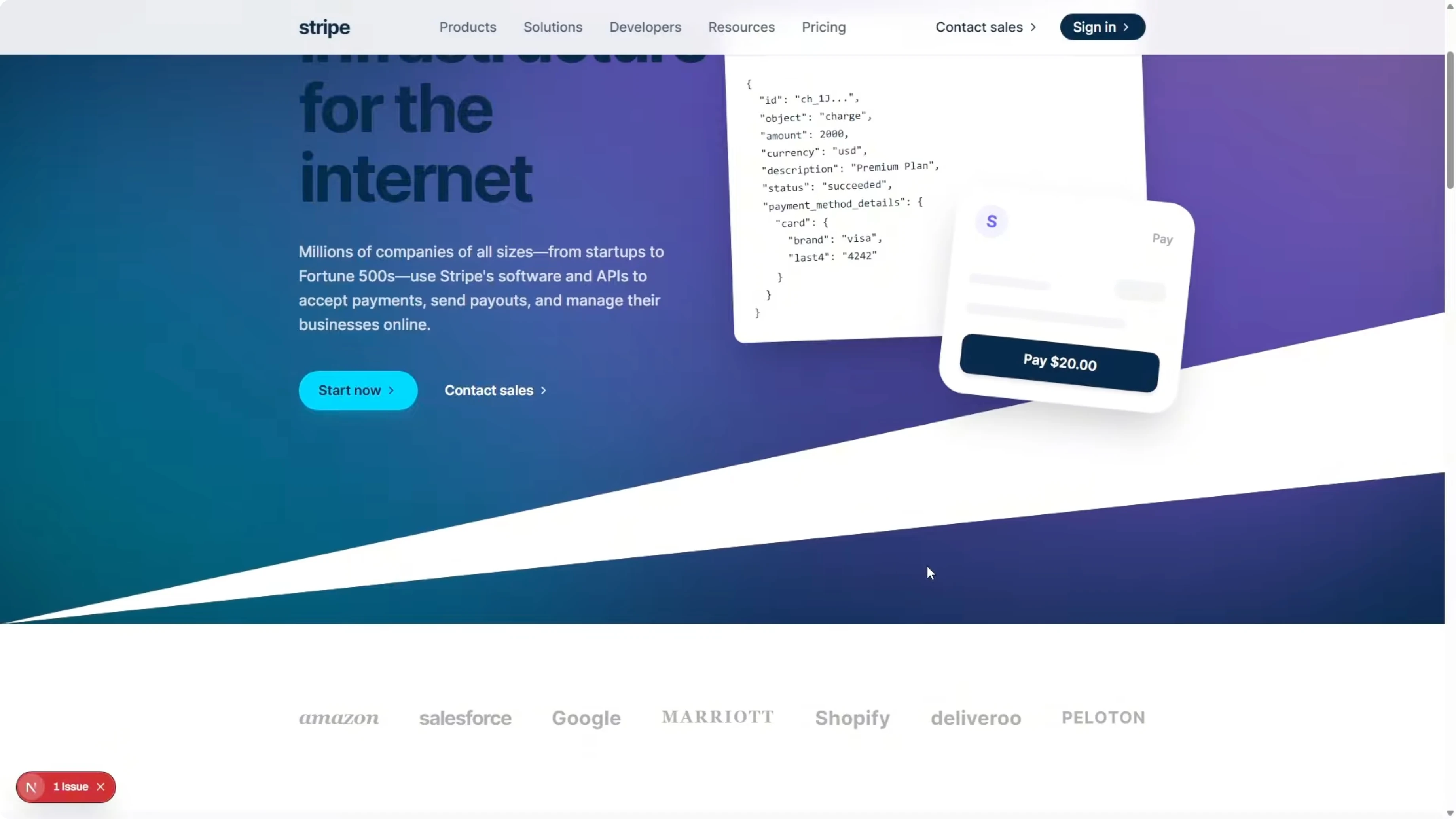
There are sections that are missing completely. The product showcase section that Opus rebuilt is not here at all. There are also sections where it made up some content and left out quite a few sections.
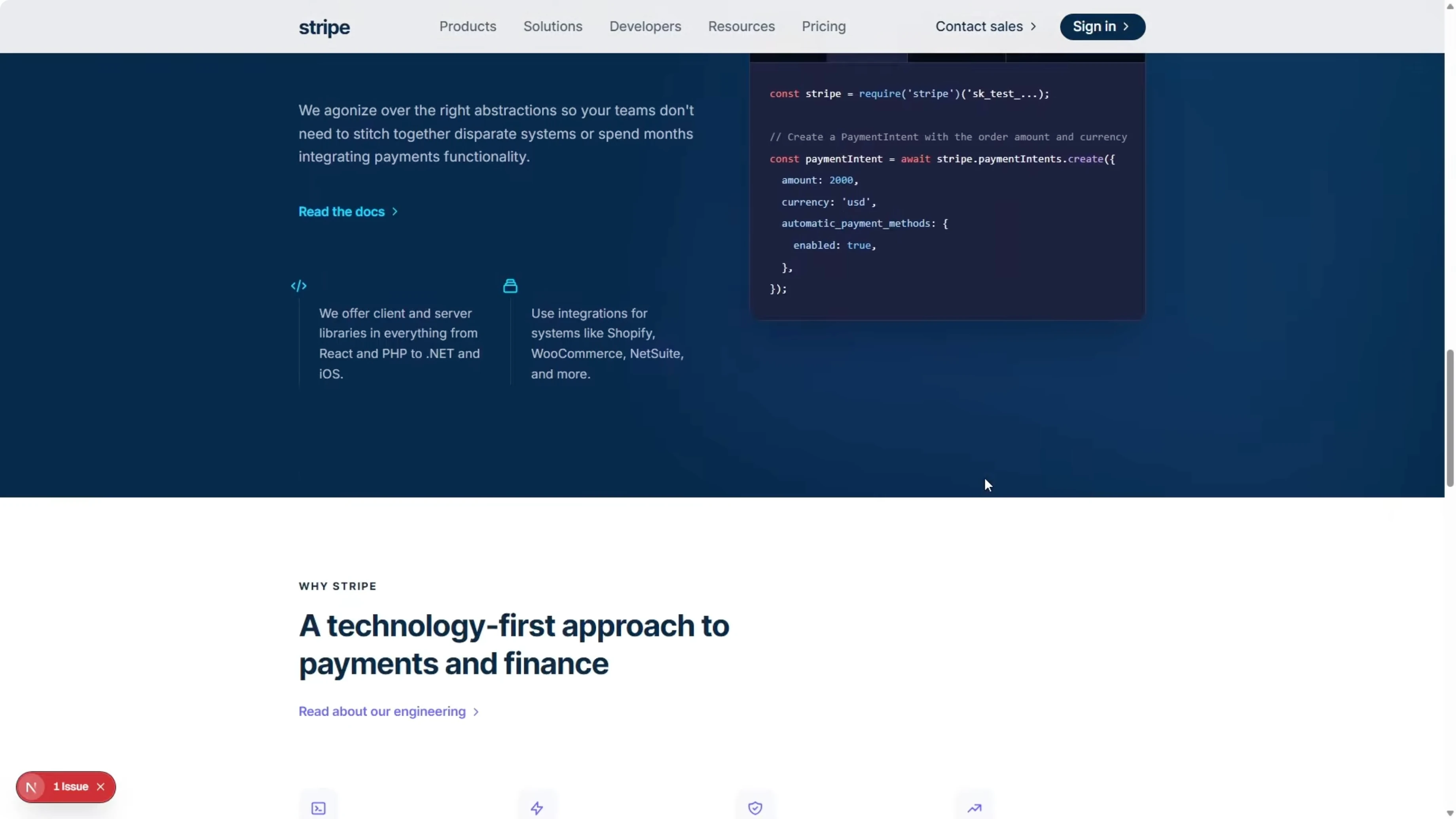
We are at the footer already, but the real page and the Opus rebuild were a lot more detailed than this. In terms of visual comprehension, this gets a fail for this task. Opus 4.6 is still the benchmark here.
If you want a deeper look at why Opus 4.6 excels at recreating complex pages from images, see this detailed writeup: full breakdown of Opus 4.6.
How I ran the visual comprehension test
I supplied only screenshots of the target page and blocked URL fetches. I asked for a faithful recreation using components inferred from images. I compared the output against the screenshots for structure, content, and fidelity.
Comprehension suite - Gemini 3.1 Pro vs Opus 4.6 vs GPT-5.3 Codex: Which Tops Coding Benchmarks?
This is my custom built benchmark that tests models on real engineering tasks: a bug fix, a refactor, and a migration. All are run against the same code base with the same prompt and constraints. It is API only, there are no agent loops, and temperature is set to zero.
The model gets one attempt, and the output has to be fenced code blocks only. No explanations and no commentary are allowed, which is specific in the prompt. If it breaks that output contract, it fails even if the code inside is correct.
GPT 5.3 and GPT 5.3 Codex are not available via API yet, so I could not include them in this suite. Once that is available, I will add it in. Here are the results.
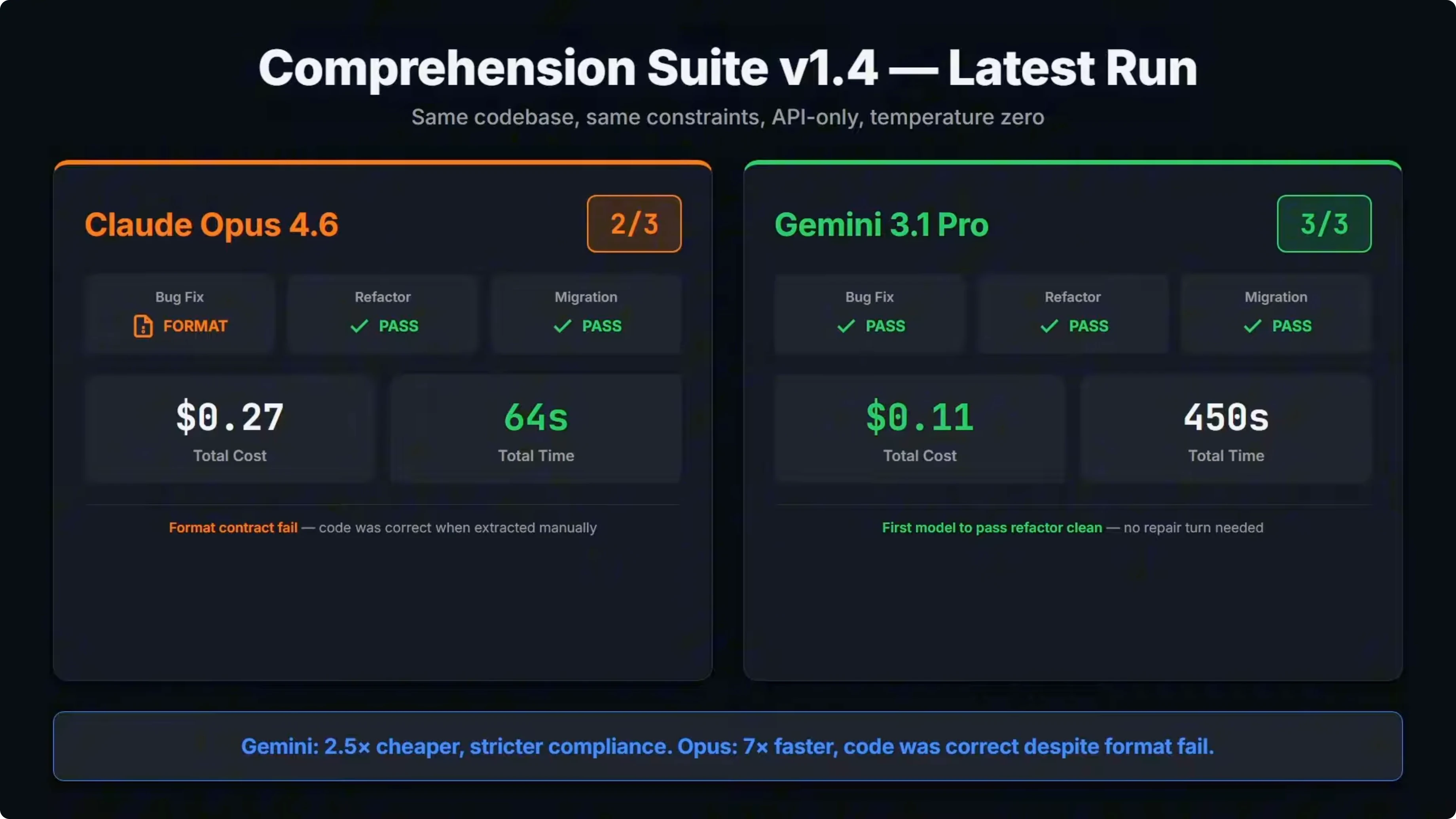
Gemini 3.1 Pro went three for three. Bug fix, refactor, and migration all passed clean on the first attempt with no repair turns needed. The total cost across all three tasks was about 11 cents, and it followed the output contract perfectly every time.
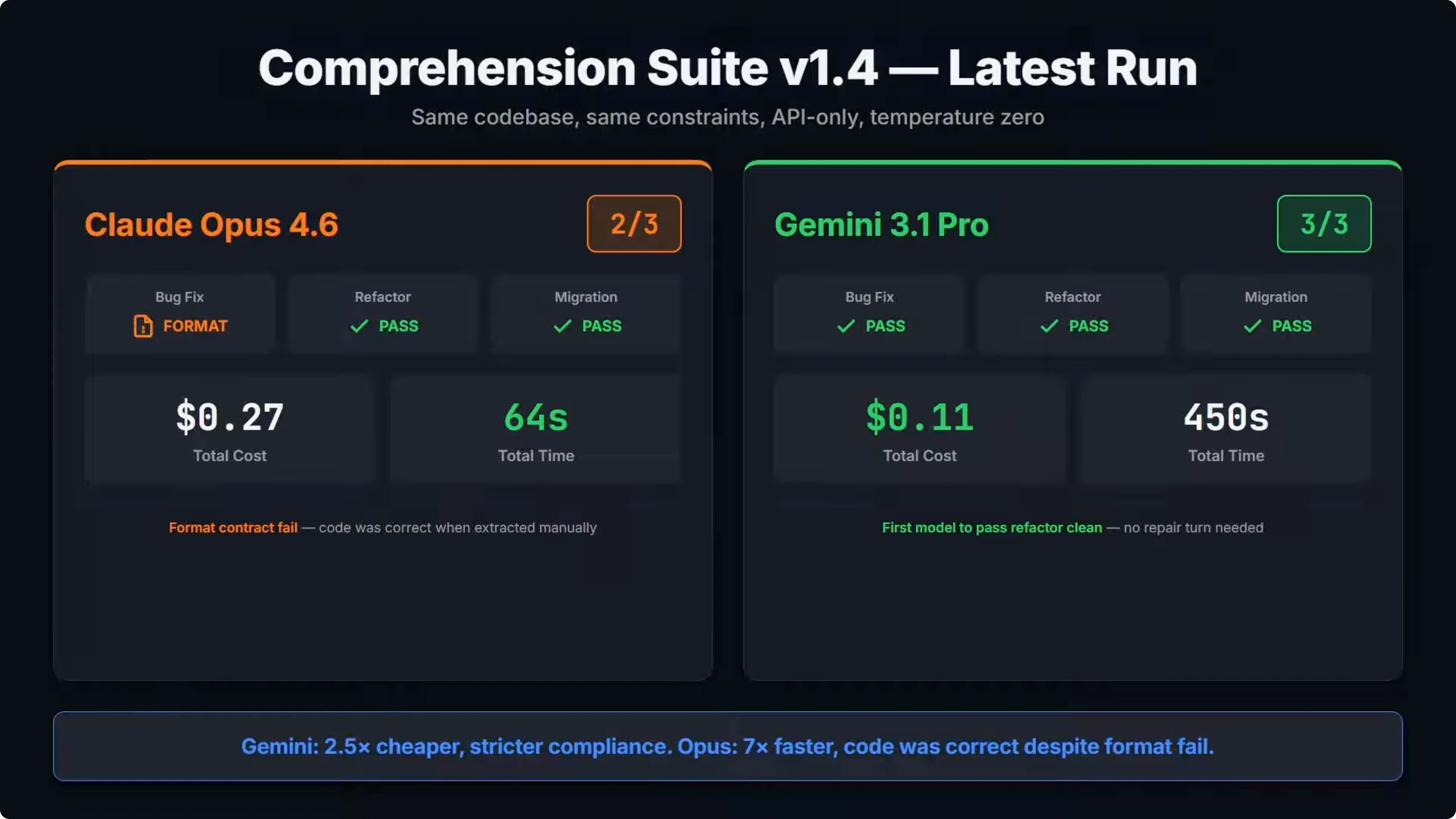
Opus 4.6 went two for three. It passed refactor and migration clean but failed the bug fix. It was not a code quality failure.
When I extracted just the fenced code blocks from the response and ran them manually, all tests passed. The issue is that Opus added text before the code fences and the test runner requires fenced output only. The format contract failed before the code ever got tested.
This is the exact same failure that Opus 4.5 had in the baseline run across two versions. The Claude models share the same issue on strict output contracts. On cost, Gemini came in at about 11 cents total, while Opus was about 27 cents.
On speed, Opus finished everything in about 64 seconds. Gemini took over seven minutes. There is a clear trade off: Gemini is cheaper and scored higher on strict compliance, but Opus is significantly faster, and the code itself was correct.
Across the baseline, seven models have now been through this benchmark. Here is how they stack up. Gemini 3.1 Pro is sitting at the top.
It went three for three, with the lowest cost at 11 cents and it is the only model to pass every task clean on the first attempt with no repair turns needed. That is a significant result. Google’s blog post for this model calls out improved core reasoning, saying it more than doubled the reasoning performance of Gemini 3 Pro.
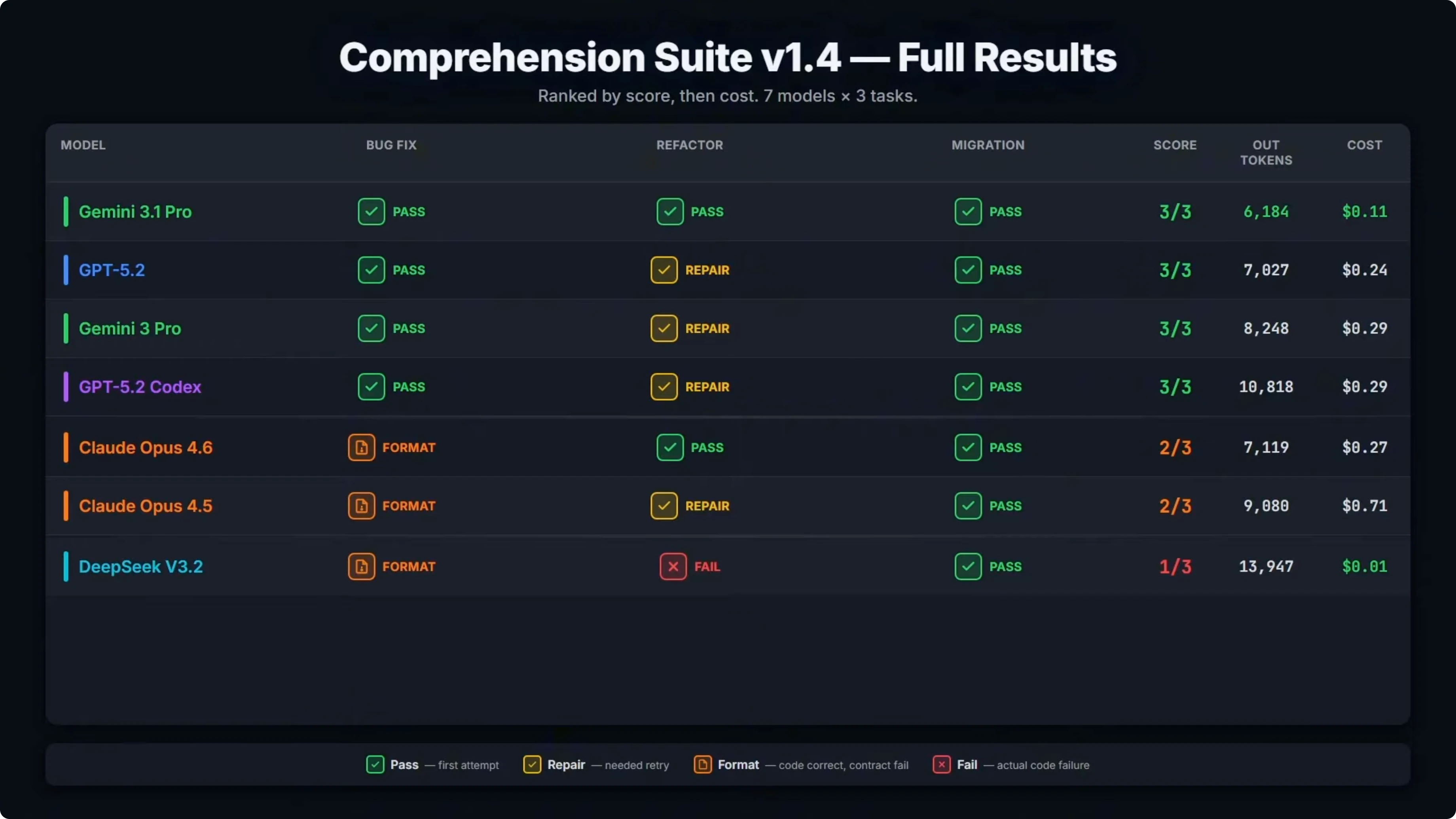
You can see that in the refactor column. The refactor is the hardest task in the suite. It requires multi step reasoning across eight files, extracting shared logic without breaking behavior.
Every other model either needed a repair turn or failed outright. Gemini 3.1 Pro is the first and only model so far to pass it clean. When Google says this is a step forward in core reasoning, the data here backs that up.

GPT 5.2, Gemini 3 Pro, and GPT 5.2 Codex also scored three from three, but all of those models needed a repair turn on the refactor task. Both Claude models are at two for three. Both failed the bug fix on the same format contract issue.
The actual code still worked. The cost difference between Opus 4.5 and 4.6 is significant. Opus 4.5 cost 71 cents and that came down to 27 cents with Opus 4.6.
Wall time is also a factor. Gemini 3.1 Pro is on top for cost and strict compliance, but it was significantly slower than Opus 4.6. That trade off matters when you care about speed to result.
For details on how Opus 4.6 compares to 4.5 in these tests, see this side by side: Opus 4.6 vs 4.5 changes.
Strict output rules - code example
The suite accepts only fenced code blocks with no text outside. Here is an example of a valid single file patch:
// src/utils/formatCurrency.ts
export function formatCurrency(amount: number, locale = "en-US", currency = "USD"): string {
return new Intl.NumberFormat(locale, { style: "currency", currency }).format(amount);
}Here is an example of a valid multi file response using separate fences. Each block must start with a clear file path comment:
// src/components/Button.tsx
import React from "react";
type Props = React.ButtonHTMLAttributes<HTMLButtonElement> & { variant?: "primary" | "secondary" };
export function Button({ variant = "primary", ...rest }: Props) {
const base = "px-4 py-2 rounded font-medium";
const color = variant === "primary" ? "bg-indigo-600 text-white" : "bg-white text-gray-900 border";
return <button className={`${base} ${color}`} {...rest} />;
}// src/components/__tests__/Button.test.tsx
import { render, screen } from "@testing-library/react";
import { Button } from "../Button";
it("renders primary by default", () => {
render(<Button>Click</Button>);
expect(screen.getByRole("button")).toHaveTextContent("Click");
});How I ran the comprehension suite
I fixed temperature at 0, set API only mode, and disabled any agent loops. I provided one attempt per task and rejected any text outside fenced code blocks. I measured cost and wall time across bug fix, refactor, and migration.
Model upgrades in focus - Gemini 3.1 Pro vs Opus 4.6 vs GPT-5.3 Codex: Which Tops Coding Benchmarks?
Here is how both upgrades compare to their predecessors. This is the first time Google has done a 0.1 update to a Gemini model. Previous updates were 0.5 jumps, so it is a smaller increment, but the improvement is clear.
Gemini 3.1 Pro no longer needs a repair turn on the refactor task. Cost dropped 62 percent and output tokens came down from over 8,000 to just over 6,000. It is doing more with less.
On the Opus side, there is a similar story on the refactor. It also no longer needs a repair turn and cost dropped 62 percent as well. But the bug fix format issue carried over unchanged.
The code was correct both times. It just did not follow the output rules. Both models improved on the hardest task in the suite, but Gemini also fixed its format compliance, which is why it moved to the top.
If you want Google’s positioning and specs for this update, here is the product page: Gemini 3.1 Pro overview.
Comparison overview - Gemini 3.1 Pro vs Opus 4.6 vs GPT-5.3 Codex: Which Tops Coding Benchmarks?
| Model | App build from PRD | Build time | Visual comprehension | Comprehension suite | Total cost | Wall time | Notes |
|---|---|---|---|---|---|---|---|
| GPT-5.3 Codex | Clean one-shot, fully working dashboard | 7 minutes | Missed inner mockups, left sections blank | API not available for this run | n/a | n/a | Benchmark for clean app build speed and completeness |
| Opus 4.6 | Had map rendering issues after a repair turn | 22 minutes | Recreated all components, close to screenshots | 2 of 3 passed, failed bug fix on format rules | ~$0.27 | ~64 seconds | Correct code, strict fenced output violated |
| Gemini 3.1 Pro | Needed repair turn for styling, scroll issue remained | 6m32s first attempt | Headline and logos incorrect, sections missing | 3 of 3 passed, first attempt, no repairs | ~$0.11 | Over 7 minutes | Only model to pass refactor clean in first attempt |
For broader context across Codex and peers, you can also scan this roundup: Codex compared with Opus, Kimi, and Qwen.
Use cases, pros and cons - Gemini 3.1 Pro vs Opus 4.6 vs GPT-5.3 Codex: Which Tops Coding Benchmarks?
GPT-5.3 Codex
Codex is best for app builds from a written spec when you want a clean one-shot result. It shipped the Quake Watch dashboard fully working in 7 minutes. For quick prototypes and spec to app flows, it sets the bar.
The main limitation shows up in image based reconstruction. On the Stripe page test, it left inner mockups blank and missed detail in key sections. If you need faithful builds from screenshots, there are better options.
Codex was not available via API for the comprehension suite in this run. Prior versions have done well on structured code changes with repair turns allowed. I will add updated numbers once the API is available.
Opus 4.6
Opus is best for visual comprehension. It recreated the full Stripe homepage from screenshots, including detailed product showcase mockups, and matched structure closely.
It is fast on structured coding tasks and produced correct code in the suite. The failure was strict formatting, where it added text before fenced blocks and tripped the output contract.
Cost improved a lot from 4.5 to 4.6, but it is still about 2.5 times more expensive than Gemini on the suite. If you need speed and image to code fidelity, Opus is strong, as long as you can relax output formatting rules.
Gemini 3.1 Pro
Gemini 3.1 Pro is best for code comprehension tasks. It passed bug fix, refactor, and migration clean on the first attempt with perfect adherence to the output rules.
It is also the first and only model in this set to pass the refactor task clean. That task requires multi step reasoning across eight files and careful extraction of shared logic without breaking behavior.
It did not win the app build or the visual test. The dashboard build needed a repair turn for styling and still had a scroll issue, and the Stripe page reconstruction missed sections and content. The trade off is clear: it is cheaper and more compliant, but slower, and weaker on image to code.
Step by step - reproduce the three tests
Provide the PRD for Quake Watch with API endpoints, required components, and acceptance criteria. Instruct the model to build from the PRD with no extra guidance and measure time to first working render. Allow a single repair turn for targeted fixes and recheck the same acceptance criteria.
Capture full page screenshots of the Stripe homepage and block all URL fetches. Ask the model to recreate the page using only the screenshots and compare structure and content. Score fidelity by checking the hero, logo bar, product showcase cards, and overall section coverage.
Prepare a repo with a failing test for bug fix, a scoped migration task, and a multi file refactor target. Set temperature to 0, one attempt only, API only, and require fenced code blocks with no text outside. Measure wall time and token cost, and evaluate success via tests and strict output contract.
Final thoughts - Gemini 3.1 Pro vs Opus 4.6 vs GPT-5.3 Codex: Which Tops Coding Benchmarks?
Across the three tests, there was a lot of variety in the results. Codex was best at the app build from a spec. Opus was best at the visual comprehension task.
Gemini 3.1 Pro was best at the code comprehension tasks at a fraction of the cost. It moved to the top of the suite by passing every task clean on the first attempt and fixing format compliance. For a 0.1 update, that is a strong improvement.
The model you choose depends on the task. I am interested to see where GPT 5.3 Codex fits once the API is available. If you want the most recent Gemini details while you test, see this reference: Gemini 3.1 Pro details.
Subscribe to our newsletter
Get the latest updates and articles directly in your inbox.

Related Posts

8 Best Claude Code Plugins in 2026 (You Need to Know)
8 Best Claude Code Plugins in 2026 (You Need to Know)

7 Best Claude Code Skills (You Need to Know)
7 Best Claude Code Skills (You Need to Know)

Claude Code Desktop IDE Features (You Need to Know)
Claude Code Desktop IDE Features (You Need to Know)