
Table Of Content
- How Claude Opus 4.6 Built a Web App Live? The Project
- Prompt and Output
- How Claude Opus 4.6 Built a Web App Live? Setup and Run
- Environment and Dependencies
- Step-by-step setup
- How Claude Opus 4.6 Built a Web App Live? The Running App
- Map and environmental data
- Login and exploration
- Collection and sharing
- Benchmarks and Capabilities Behind How Claude Opus 4.6 Built a Web App Live?
- Pricing, Limits, and Practical Notes
- Final Thoughts on How Claude Opus 4.6 Built a Web App Live?

How Claude Opus 4.6 Built a Web App Live?
Table Of Content
- How Claude Opus 4.6 Built a Web App Live? The Project
- Prompt and Output
- How Claude Opus 4.6 Built a Web App Live? Setup and Run
- Environment and Dependencies
- Step-by-step setup
- How Claude Opus 4.6 Built a Web App Live? The Running App
- Map and environmental data
- Login and exploration
- Collection and sharing
- Benchmarks and Capabilities Behind How Claude Opus 4.6 Built a Web App Live?
- Pricing, Limits, and Practical Notes
- Final Thoughts on How Claude Opus 4.6 Built a Web App Live?
Opus 4.6 is here. Anthropic is calling it a practical high stakes AI. It comes at the point where OpenAI and Chinese labs are releasing their most powerful models. This one is the biggest leap yet in Anthropic's life. If you have been waiting for an AI that doesn't flake on big projects, this might be it.
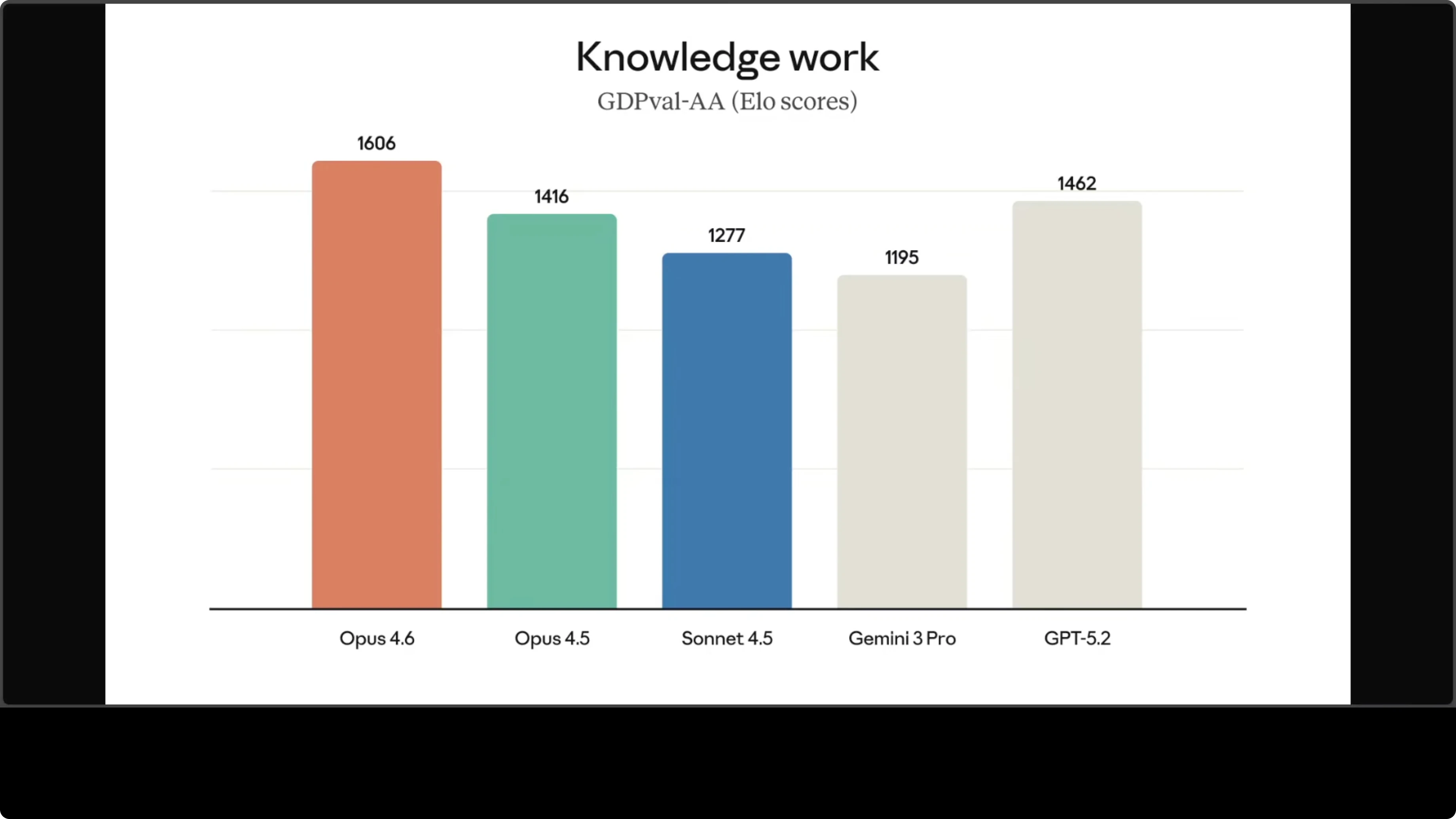
As per Anthropic, if you go through a lot of benchmarks or figures they have shared such as an ELO rated benchmark for real economic value knowledge work like finance and legal tasks, you would see that Opus 4.6 has hit a lot of great numbers and has beaten even GPT 5.2 with a wide margin. Same goes for this benchmark where I’m not going to go into the detail but you can see most of the agentic tasks it has done pretty well when compared to OpenAI's models. Interestingly enough, I don't see any comparison with Kimi, GLM, Qwen, but I will leave it at that. That is a pretty interesting observation.
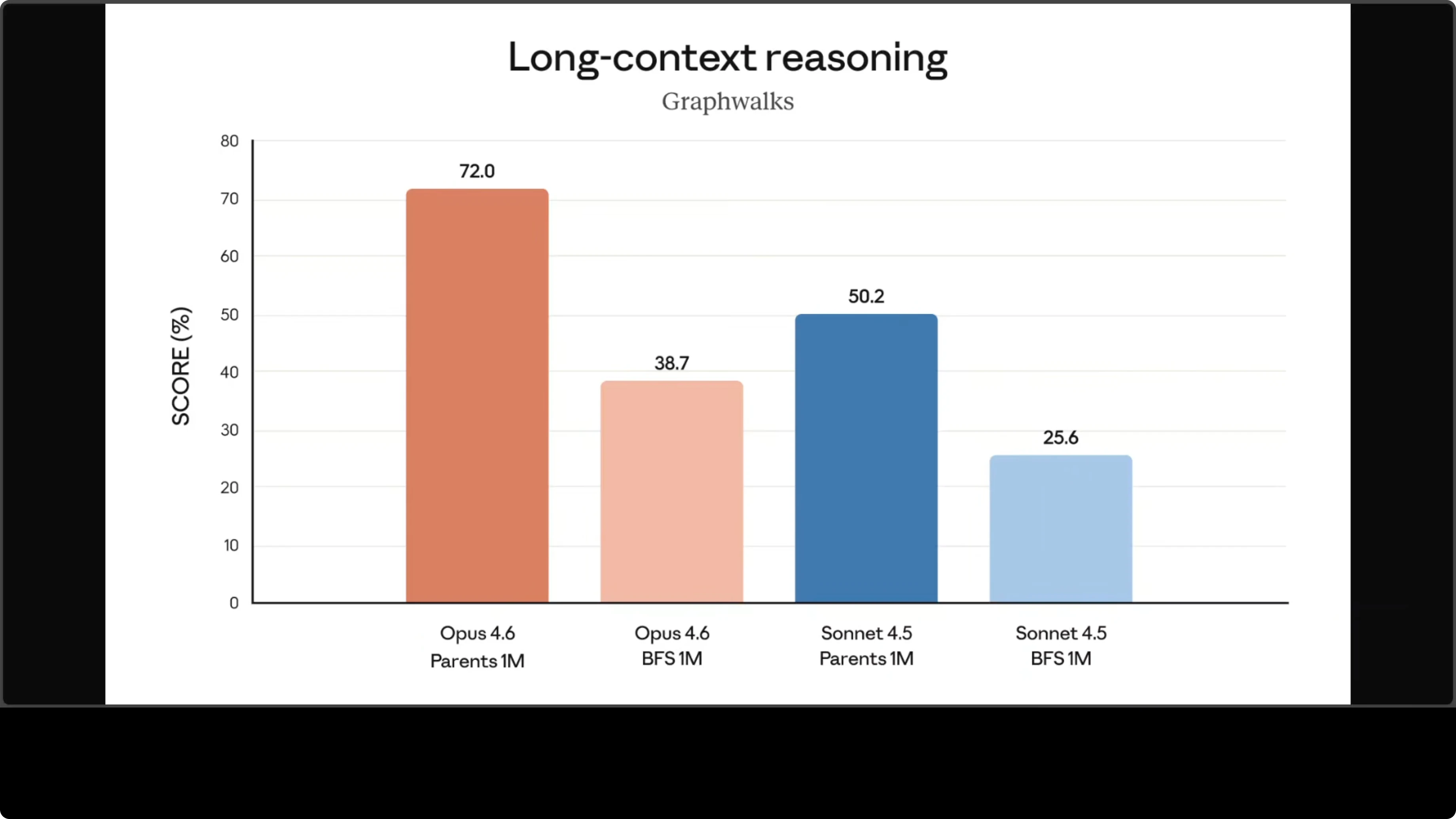
For long context reasoning and retrieval it has performed very well. First key takeaway: this is the first Opus class model with a 1 million token context window, still in beta, which allows processing of around 750,000 words at once with dramatically better long context retrieval and reasoning. Improved planning, longer autonomous task endurance, reliable handling of large code bases, and TerminalBench shows big gains in computer use too. Tool use, multi-step workflows, everything looks state-of-the-art. Knowledge work and reasoning are improved. If you're looking for an enterprise use case, I think this is where they are targeting for financial analysis, research, document presentation, creation with closer to production ready quality. Pricing is high. There is a lot of rate limiting.
How Claude Opus 4.6 Built a Web App Live? The Project
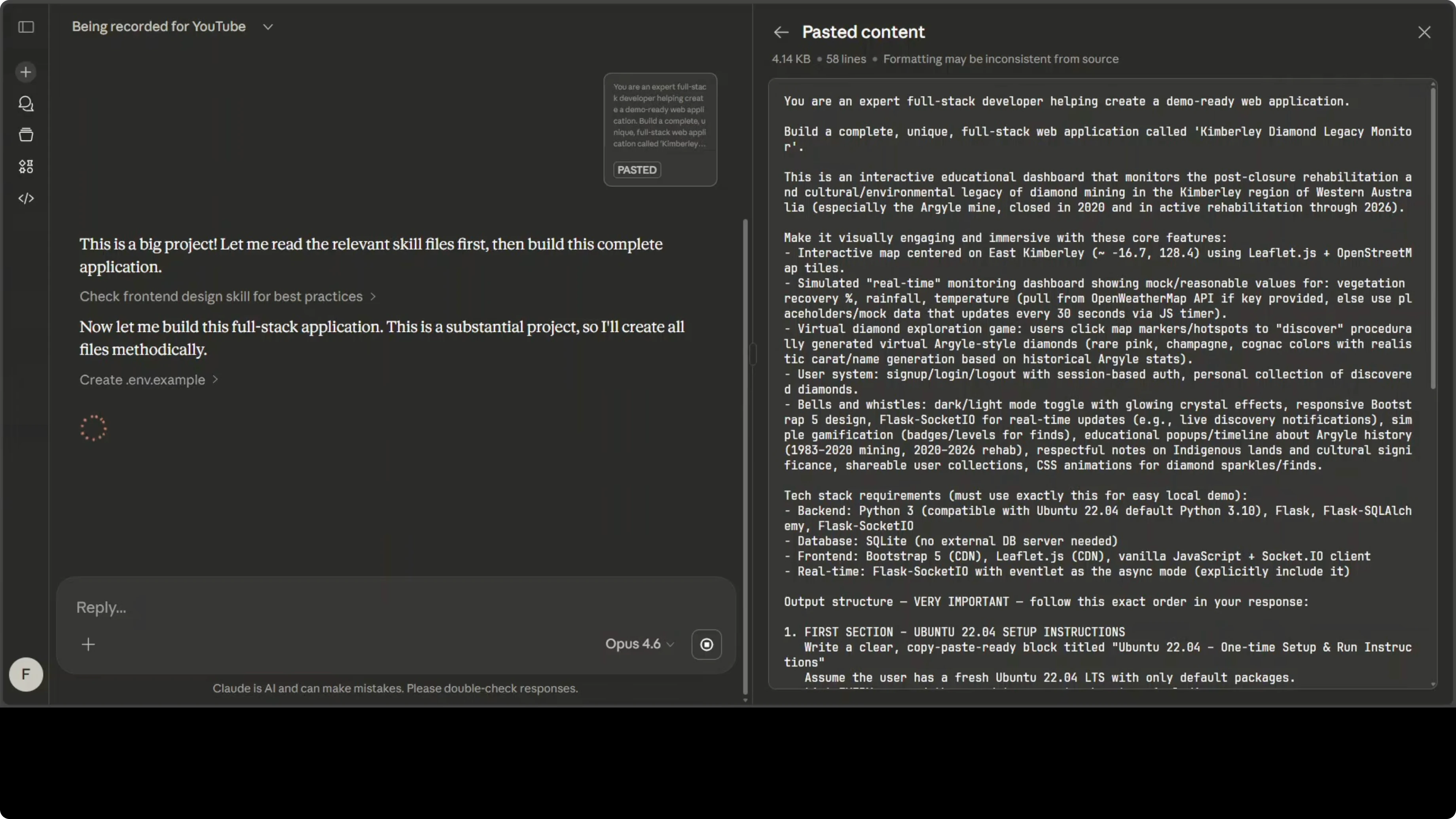
I asked Opus 4.6 to build me a full stack web application. This was an ultimate test: create the Kimberly Diamond Legacy Monitor, a cool interactive dashboard that explores the history and ongoing rehab of Australia's famous Argyle diamond mine in the Kimberly region. Everything should be runnable on my Ubuntu system. I also asked it to tell me what I need to install and what I need to do. I wanted to see if Opus 4.6 M6 delivers a production ready demo app without me fixing a single line of code. That was the ultimate test.
Planned features:
- Live map
- Virtual diamond hunting
- User login
- Real-time updates
- Dark mode and animations
- Local runnable setup with clear install instructions
Prompt and Output
I gave it a huge prompt defining the app scope and requirements. It generated the code, packaged it, and provided instructions. The archive included:
- Templates and static files in CSS and JS
- Environment files
- app.py and requirements.txt
- A README with setup steps
How Claude Opus 4.6 Built a Web App Live? Setup and Run
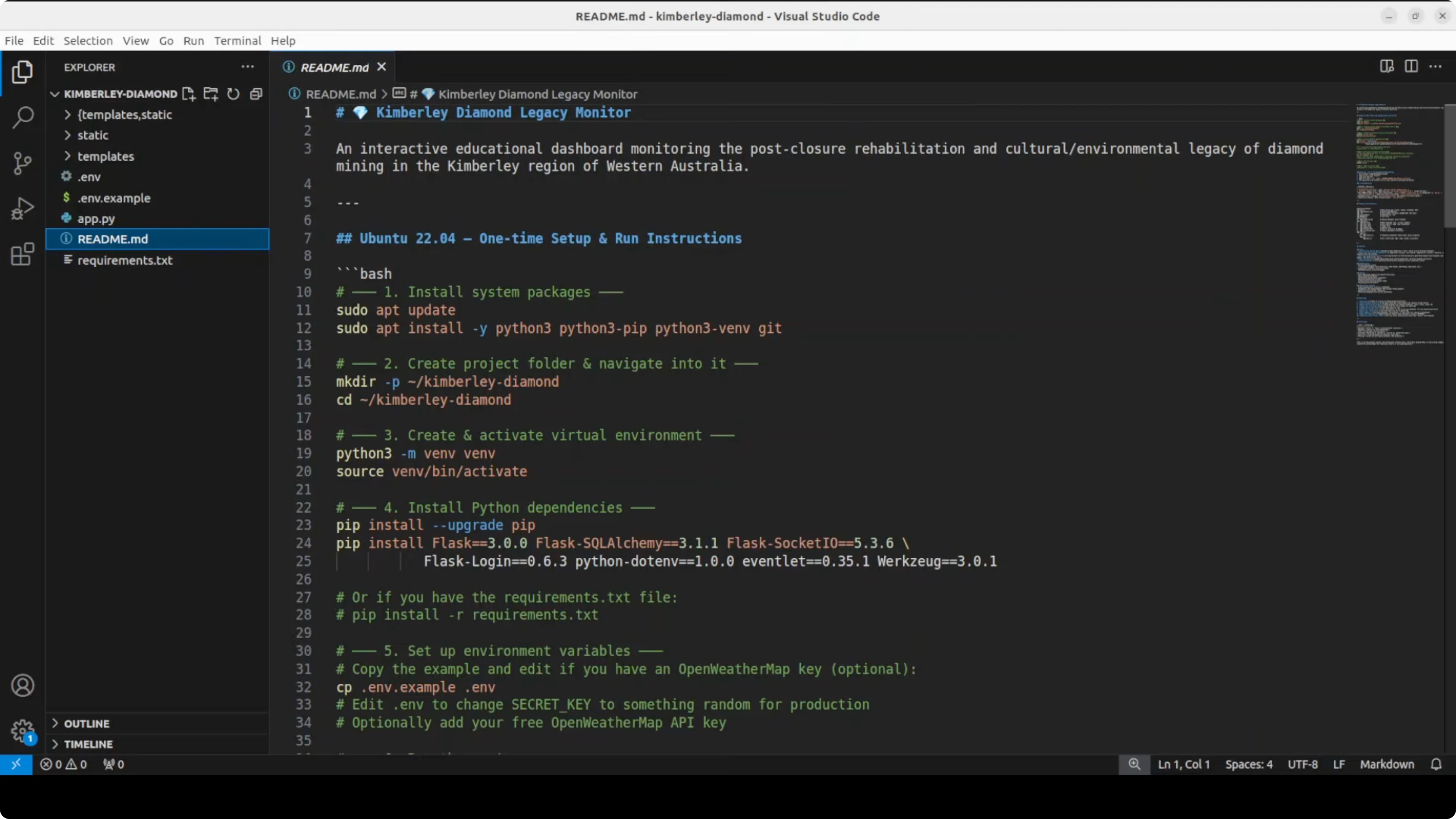
I copied the generated archive to my Ubuntu machine and unzipped it. Here is how the setup went.
Environment and Dependencies
- The project included a Python backend with Flask and a requirements.txt.
- There was an environment file with a secret key and an OpenWeatherMap API key.
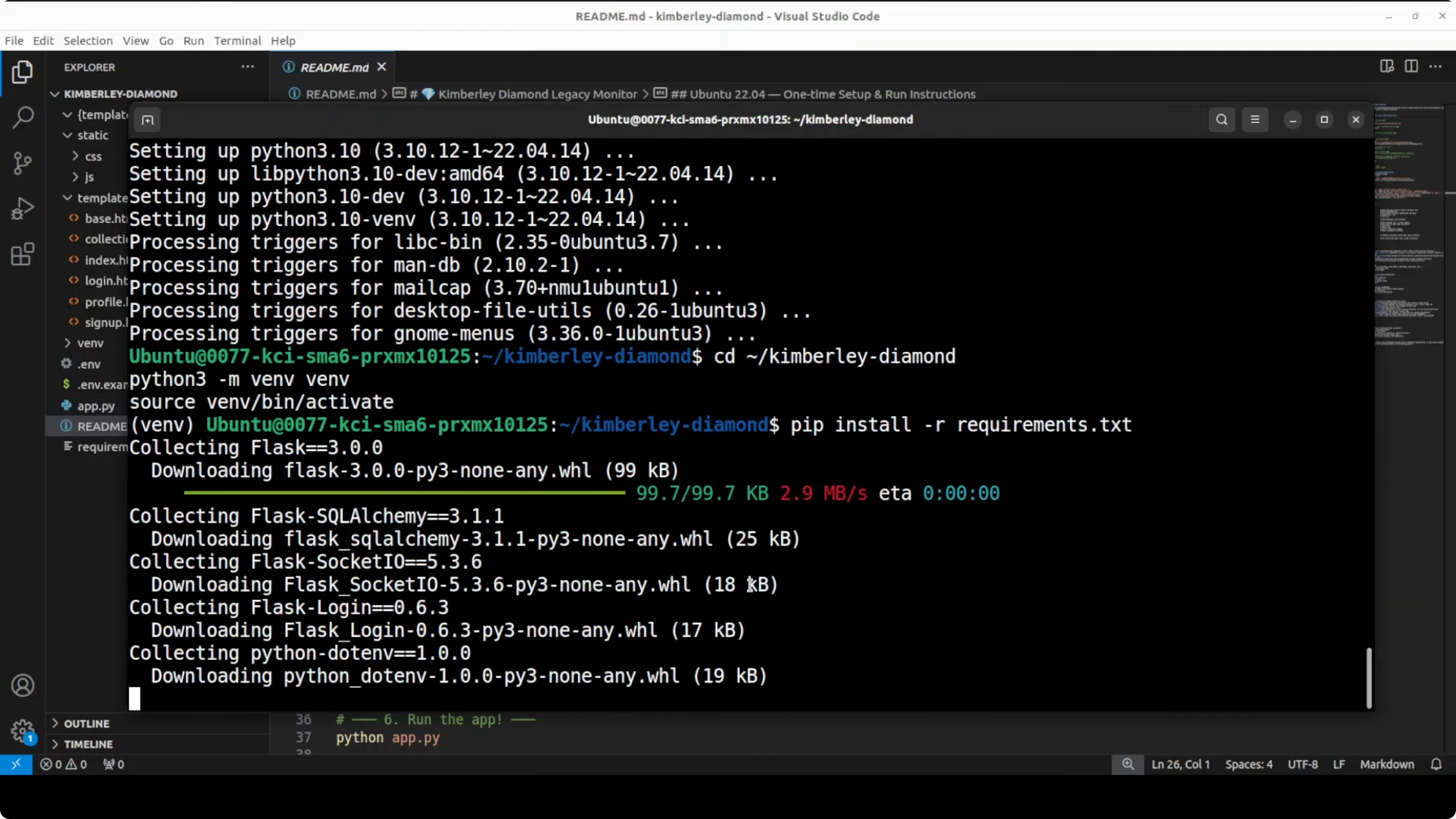
Step-by-step setup
- Unzip the project archive.
- Create and activate a Python virtual environment.
- I initially hit an issue because the venv package wasn't installed on my system.
- The model pointed out that the README mentions this step but the quick start it gave me skipped it.
- After installing the environment tooling, activation worked.
- Install dependencies with the requirements.txt.
- Set environment variables.
- SECRET_KEY can be any random string.
- OPENWEATHERMAP_API_KEY is optional for weather data. I put a random value, so that functionality was not going to work.
- Run the app and access it at the provided local port.
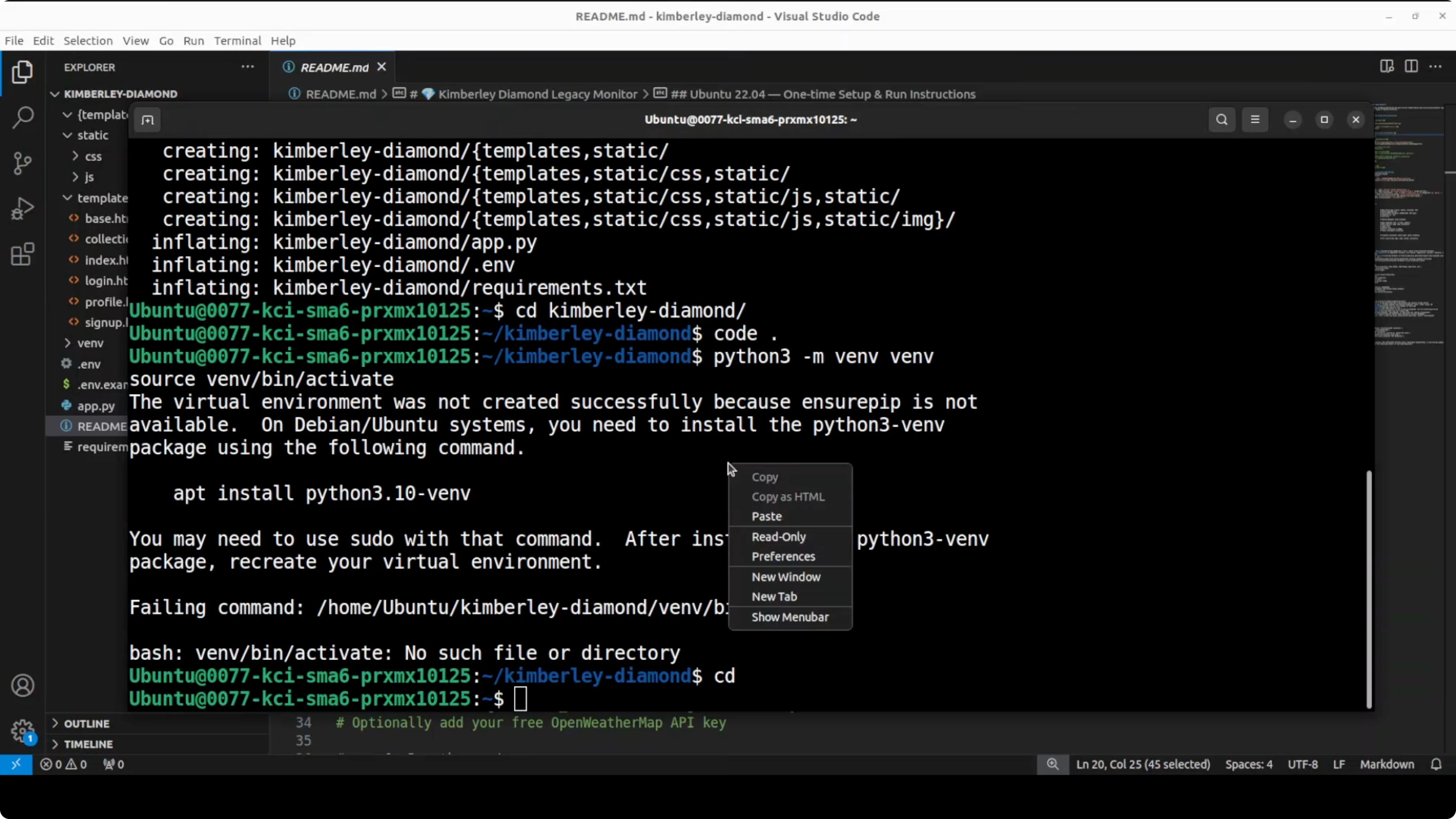
It started cleanly.
How Claude Opus 4.6 Built a Web App Live? The Running App
Map and environmental data
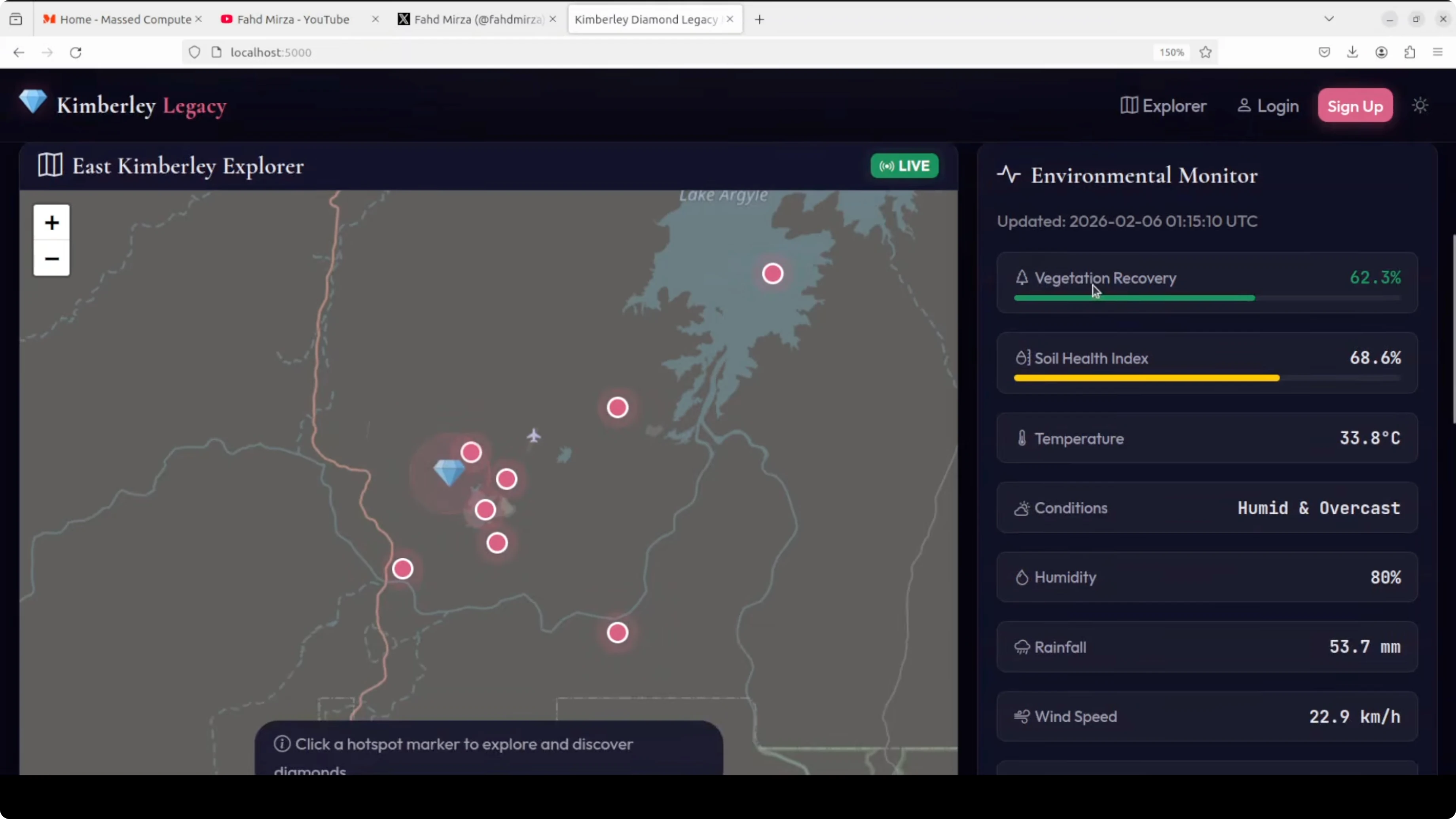
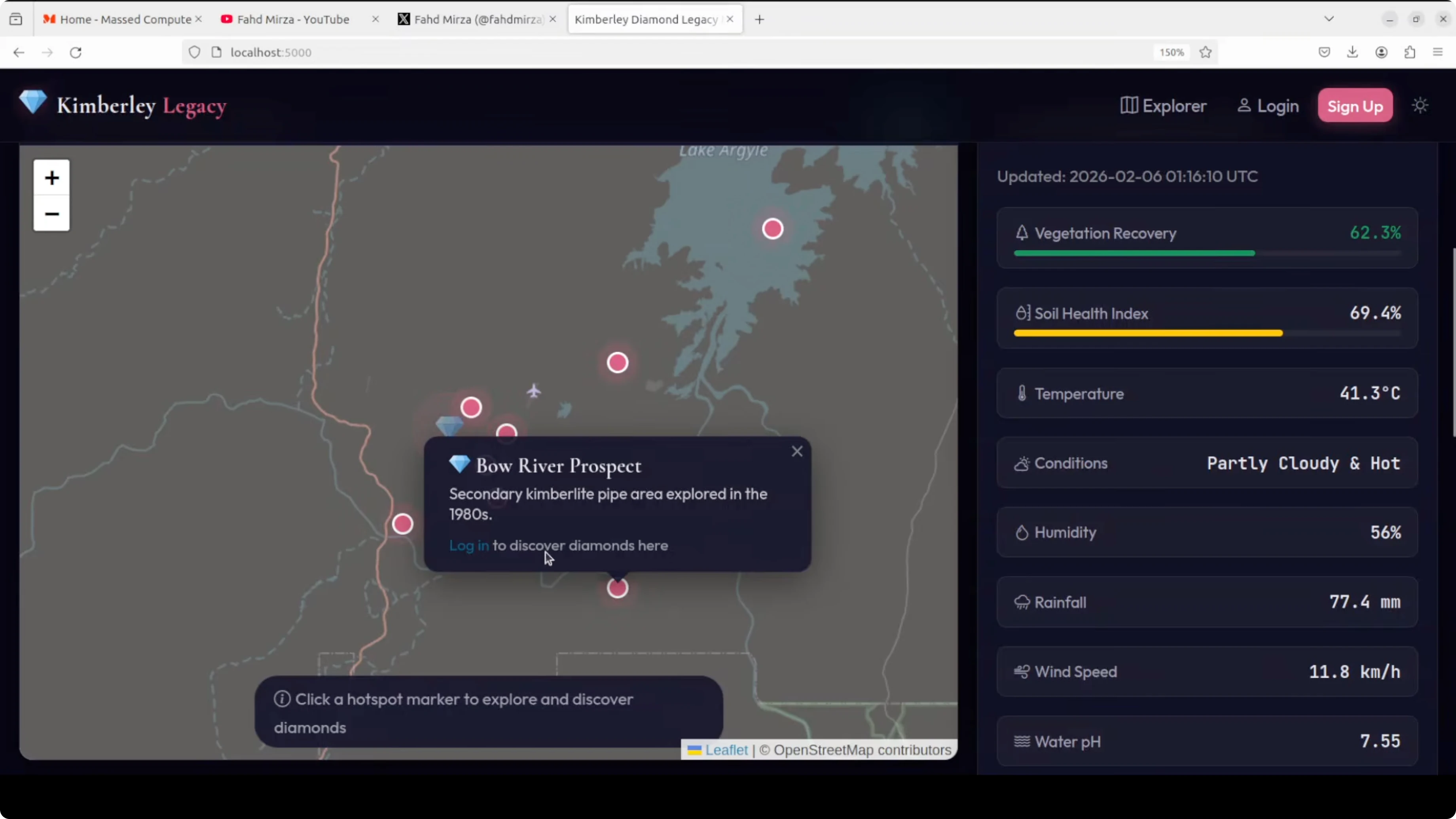
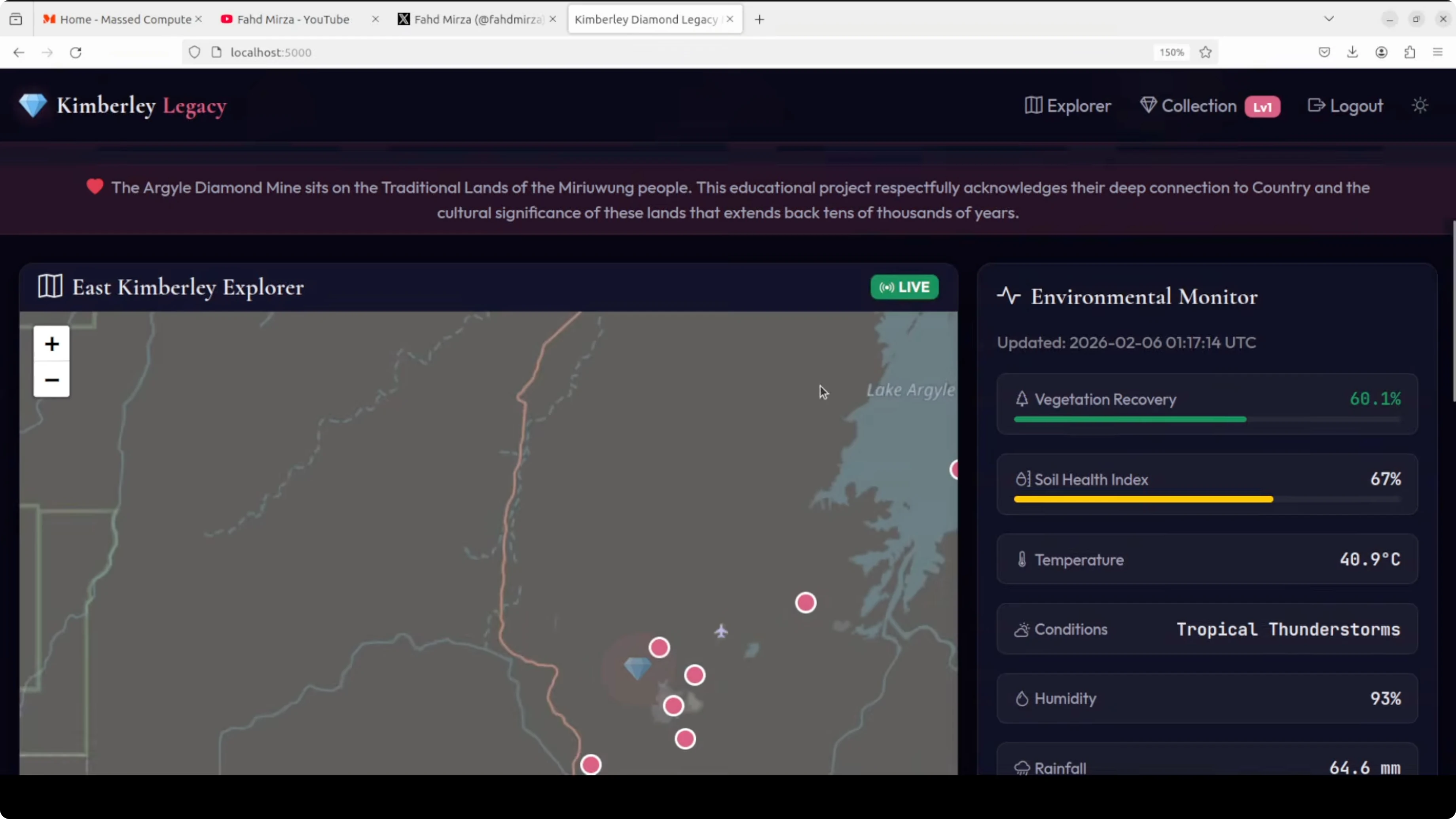
The UI was responsive. It presented a legacy monitor with an environmental monitor showing vegetation recovery and locations. The map used OpenStreetMap with legacy data, and it surfaced details about the Argyle diamond mine in Western Australia. It displayed conditions like temperature and a soil health index.
Live discovery invited me to click a hotspot on the map to start exploring. The map zoom in and zoom out functionality worked smoothly.
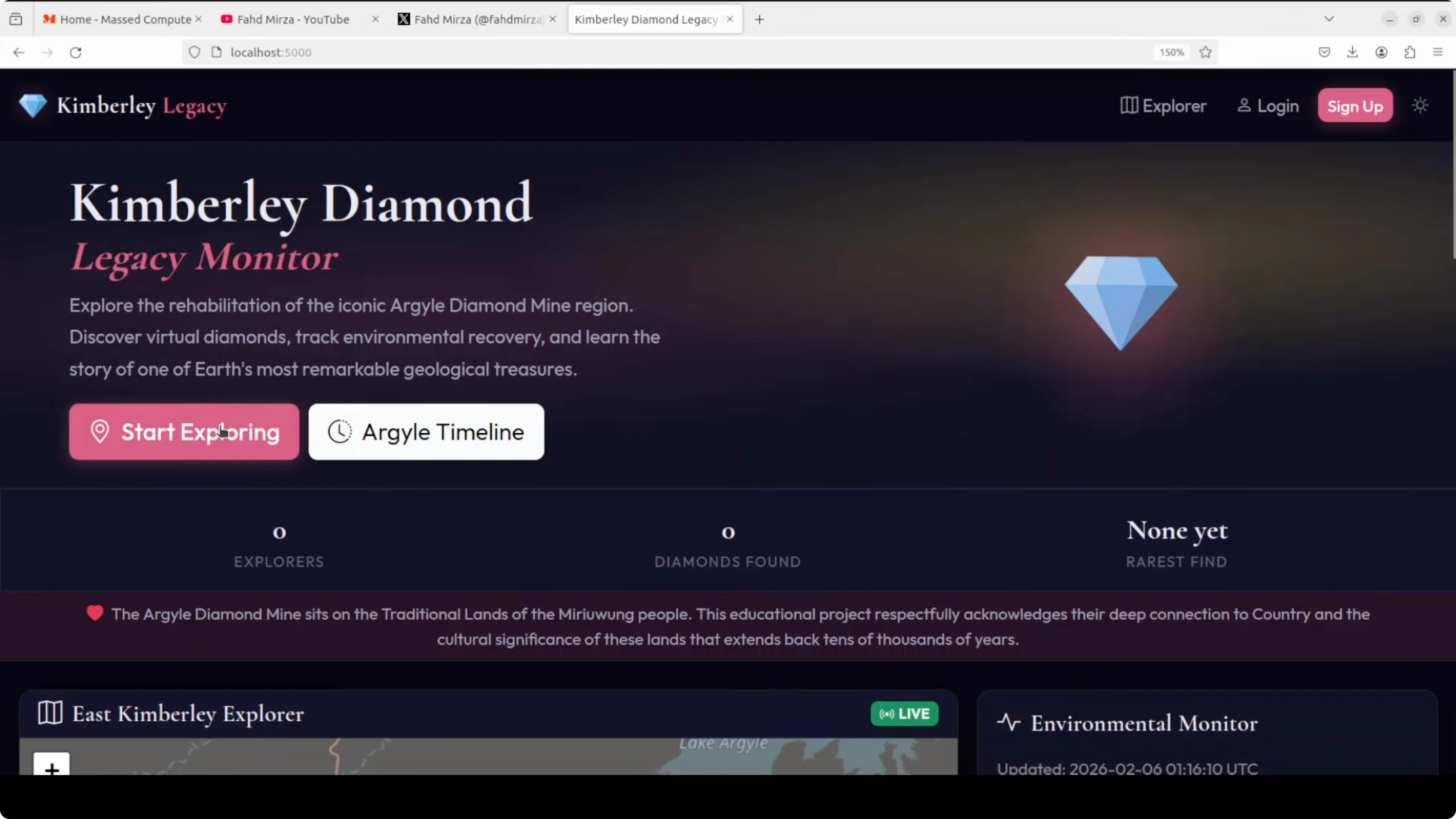
Login and exploration
Start exploring took me to a login. I didn’t have an account, so I signed up with a basic flow and logged in successfully. After login, Start exploring scrolled to the exploration section. Explore and dig produced location-based results. At the sampled locations, it returned no diamond discovered messages during my clicks, which is expected behavior for a demo logic that simulates exploration.
Collection and sharing
The Collection page showed badges I could win. Pink Sealer was one example, and the naming conventions looked good. It displayed my level and offered a Share collection view. The collection view used random data but looked quite good. Presentation on first go looked strong.
I checked the Timeline section. I didn’t see anything there yet.
I think software engineering SaaS is in real trouble. That is why we are seeing such tumbles in the stock market.
Benchmarks and Capabilities Behind How Claude Opus 4.6 Built a Web App Live?
There are five models being evaluated including Anthropic's own. No Chinese model is included in that set. The comparison spans Google and then also an open model across many practical agentic benchmarks that test how well they handle real world work like coding in terminals, using tools and computers autonomously, searching the web effectively, and doing complex multidisciplinary reasoning. Examples include tough expert level exams like humanity's last exam, financial analysis, and office tasks, with ELO-like scores for economically valuable knowledge work.
It is also checking solving completely new problems through ARC AGA2, graduate level reasoning, visual understanding, and multilingual question answering. Opus 4.6 is leading or ties for first in most categories, especially agentic terminal coding where it is achieving 65.4 percent. Tool use is up to 99.3 percent in telecom scenarios. Agentic search is quite good. Office knowledge work is also quite good, 1660, far ahead of others. New problem solving is quite good.
In short, it is strong at reliably performing long autonomous tool assisted professional tasks, while scores remain much lower on ultra hard reasoning tests like humanity's last exam where it is just 40 to 53 percent even with tools. ARC AGA2 is also not that great. This highlights that frontier models are excellent at many applied jobs but still far from human expert or truly general intelligence on the toughest abstract challenges. This is my neutral take on these benchmarks.
Pricing, Limits, and Practical Notes
Pricing is high. Rate limiting can kick in. My generation ran fine, but throttling is possible on heavier use.
Final Thoughts on How Claude Opus 4.6 Built a Web App Live?
Opus 4.6 generated a full local web app with a working Flask backend, templates, a responsive UI, a map with environmental context, a login and signup flow, an exploration mechanic, and a collection page with shareable output. It provided installation steps, corrected a missing venv step when asked, and the app ran locally with minimal manual fixes. The long context window, improved planning, autonomous task endurance, and tool use benchmarks line up with what I saw in practice.
Scores remain lower on the hardest abstract reasoning tests, pricing is high, and rate limits exist, but for applied coding and end-to-end project scaffolding it is already quite strong. I’ll be testing this model more and getting it integrated with things like open claw or cursor or whatever you are using in the coding framework.
Subscribe to our newsletter
Get the latest updates and articles directly in your inbox.

Related Posts

8 Best Claude Code Plugins in 2026 (You Need to Know)
8 Best Claude Code Plugins in 2026 (You Need to Know)

7 Best Claude Code Skills (You Need to Know)
7 Best Claude Code Skills (You Need to Know)

Claude Code Desktop IDE Features (You Need to Know)
Claude Code Desktop IDE Features (You Need to Know)