
Table Of Content
- Benchmark setup for GPT-5.3 Codex vs Opus 4.6 vs Kimi K2.5 vs Qwen 3.5 & More
- Tasks overview
- Scoring and efficiency
- Tier three results
- Tier two results
- Tier one results
- Version-to-version changes
- Format compliance example
- How to reproduce the test
- Comparison overview
- Use cases and trade-offs
- GPT-5.3 Codex
- Gemini 3.1 Pro
- Kimi K2.5
- GLM5
- Opus 4.6
- Qwen 3.5 Plus
- DeepSeek V3.2
- MiniMax M2.5
- Final thoughts

GPT-5.3 Codex vs Opus 4.6 vs Kimi K2.5 vs Qwen 3.5 & More
Qwen Model Recommender
Not sure which Qwen model fits your GPU? Pick your VRAM, use case, and task type — get matched to the right model instantly. Covers Qwen3, QwQ, QVQ, Qwen2.5-VL, Qwen3-Coder, Qwen3-TTS, and 80+ models.
Table Of Content
- Benchmark setup for GPT-5.3 Codex vs Opus 4.6 vs Kimi K2.5 vs Qwen 3.5 & More
- Tasks overview
- Scoring and efficiency
- Tier three results
- Tier two results
- Tier one results
- Version-to-version changes
- Format compliance example
- How to reproduce the test
- Comparison overview
- Use cases and trade-offs
- GPT-5.3 Codex
- Gemini 3.1 Pro
- Kimi K2.5
- GLM5
- Opus 4.6
- Qwen 3.5 Plus
- DeepSeek V3.2
- MiniMax M2.5
- Final thoughts
Several new coding models dropped over the past few weeks. I put eight of the most popular options through my coding benchmark to see which one performs best. The suite tests each model on a bug fix, a refactor, and a migration using real code bases with real unit tests.
Each task evaluates code comprehension and instruction following under strict constraints. Every model gets about 25,000 tokens of full project context and must return code edits that pass tests. The output must be code only with no explanatory text outside fenced blocks, edits are limited to the source directory, and each model gets a single repair turn using the test failure output.
Benchmark setup for GPT-5.3 Codex vs Opus 4.6 vs Kimi K2.5 vs Qwen 3.5 & More
The benchmark checks whether a model can read and reason about an existing multifile codebase and apply targeted changes. The constraints simulate agent workflows that often require strict format adherence. Some models fail purely on format compliance rather than implementation.
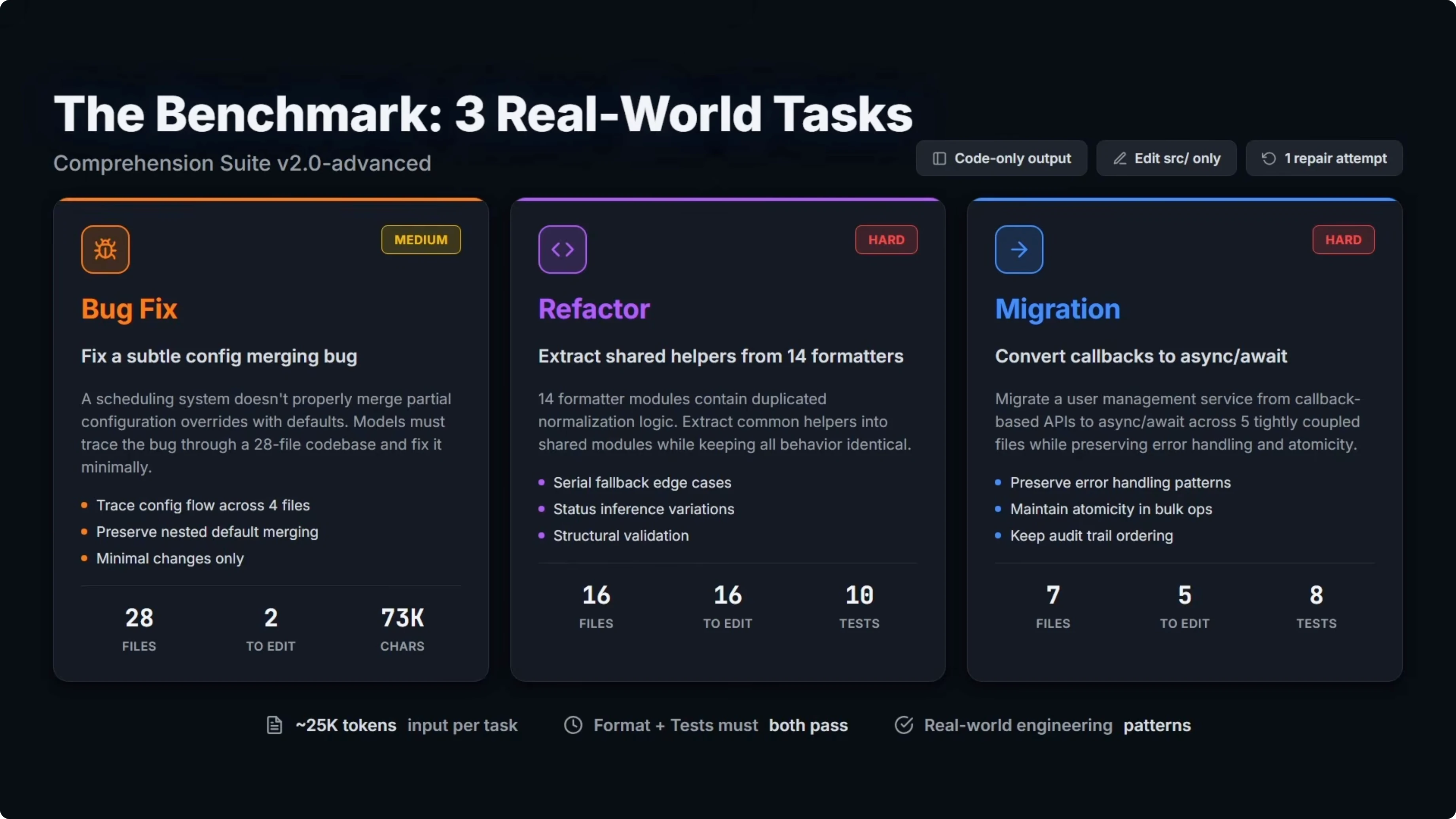
Tasks overview
Bug fix
The model must find and fix a subtle bug across a 28 file codebase with minimal changes. This task is rated medium difficulty.
Refactor
The model must extract duplicated logic into shared modules across 16 files while preserving identical behavior. This is the hardest task in the suite.
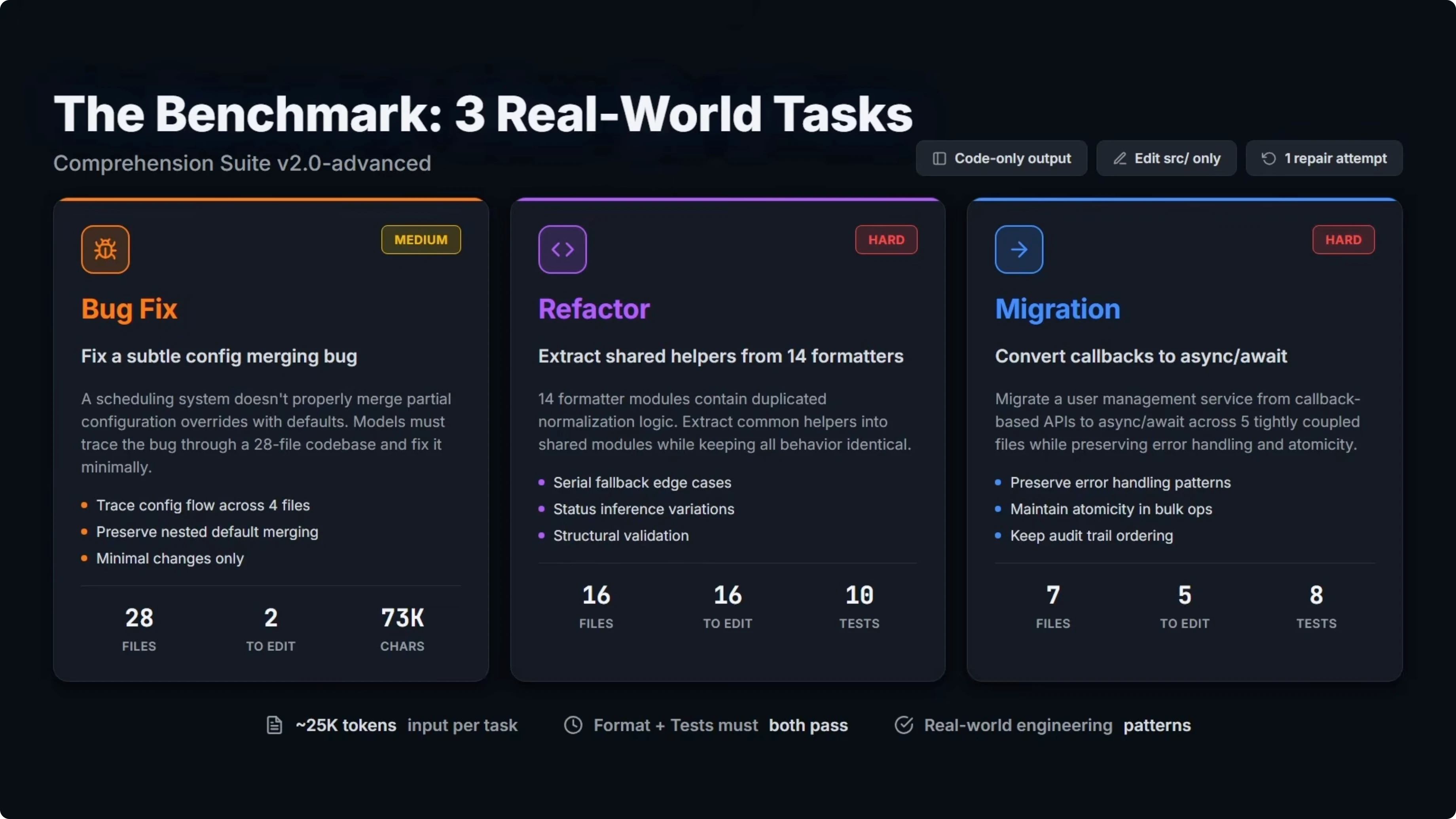
Migration
The model must convert a service from one API pattern to another across five tightly coupled files without breaking anything. This task is rated hard.
Scoring and efficiency
Hard pass scores 1. The model follows the required output format correctly and all unit tests pass.
Soft pass scores 0.85. The implementation is correct and all tests pass, but the model violates the format instructions, usually by adding text outside the fenced code blocks.
Hard fail scores 0. Either the code is incorrect or the tests fail outright.
On top of pass rates, I calculate an efficiency score. The weighting is 60 percent output tokens and 40 percent wall-clock time, both measured relative to the best result in the test.
This separates models that land the same pass rate but with very different token and time profiles. Token count matters most for cost, and time captures latency.
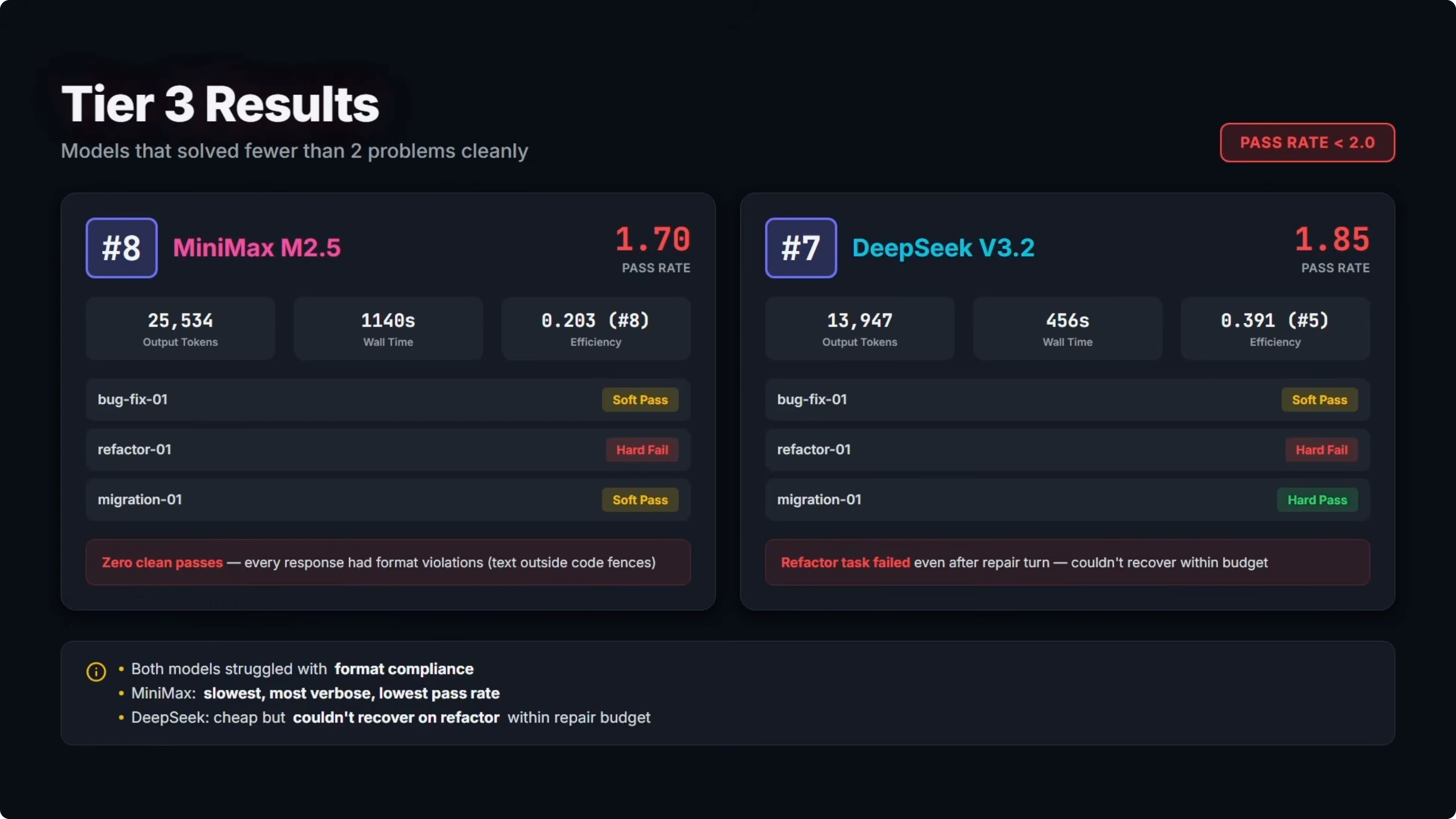
Tier three results
Two models solved fewer than two of the three problems cleanly.
MiniMax M2.5 landed in eighth. Pass rate was 1.7 and it ranked eighth on efficiency. It did not get a single clean pass and every response had format violations, though the bug fix and migration code worked for soft passes, and the refactor failed outright.
It produced about 25,000 output tokens and took roughly 19 minutes total. That made it the slowest and least accurate model in the benchmark. The refactor exposed errors beyond formatting into actual code logic.
DeepSeek V3.2 came in seventh overall. Pass rate was 1.85 and it ranked fifth on efficiency with a relative score of 0.39.
It got one clean pass on the migration and a soft pass on the bug fix. The refactor hard failed due to a missing import on the first attempt and a new bug introduced on the repair turn that missed an empty string fallback edge case.
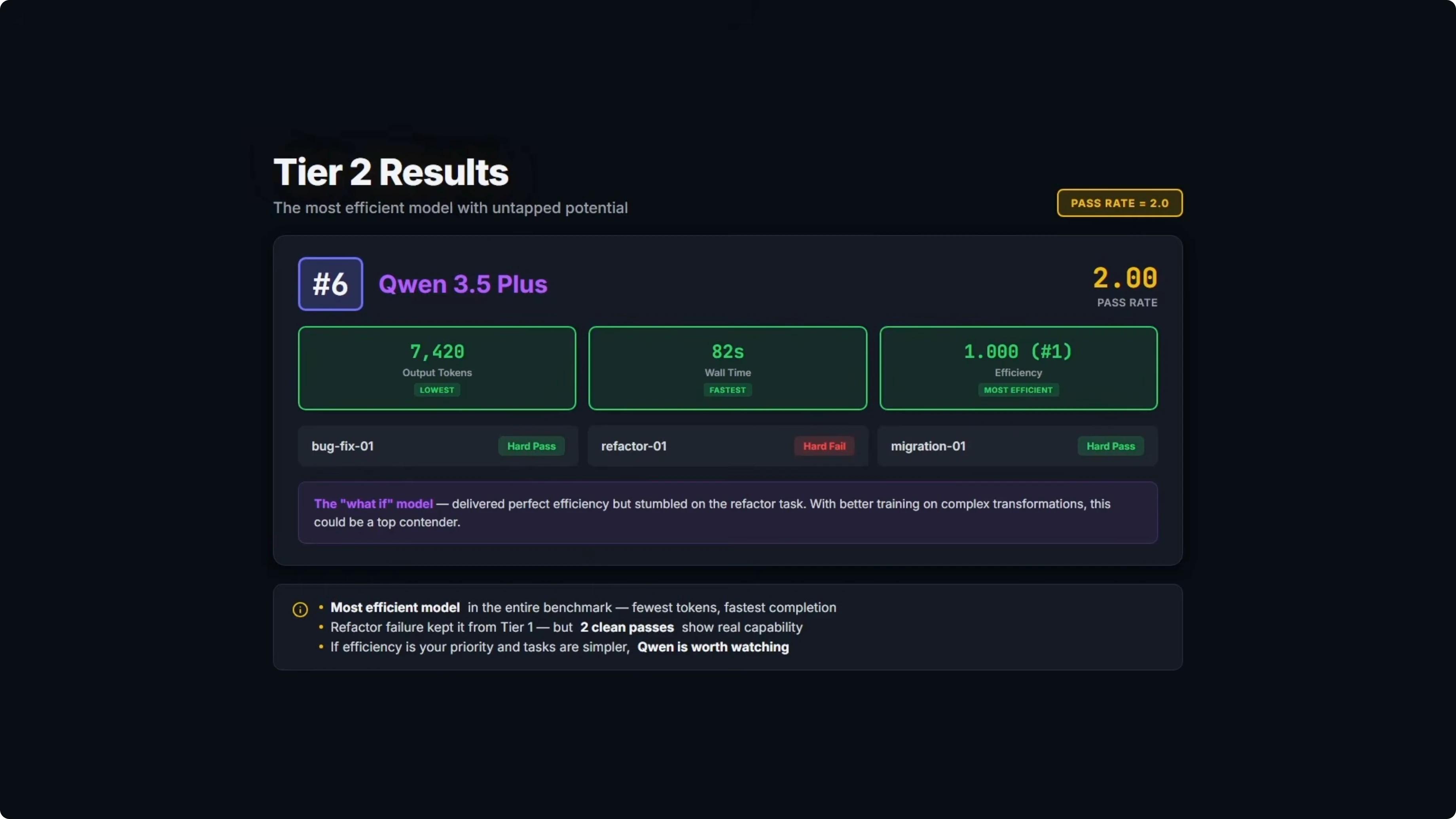
Tier two results
One model solved two out of three problems.
Qwen 3.5 Plus took sixth overall with a pass rate of 2 and ranked first on efficiency. It was the fastest at 82 seconds of wall time and the leanest at 7,420 output tokens.
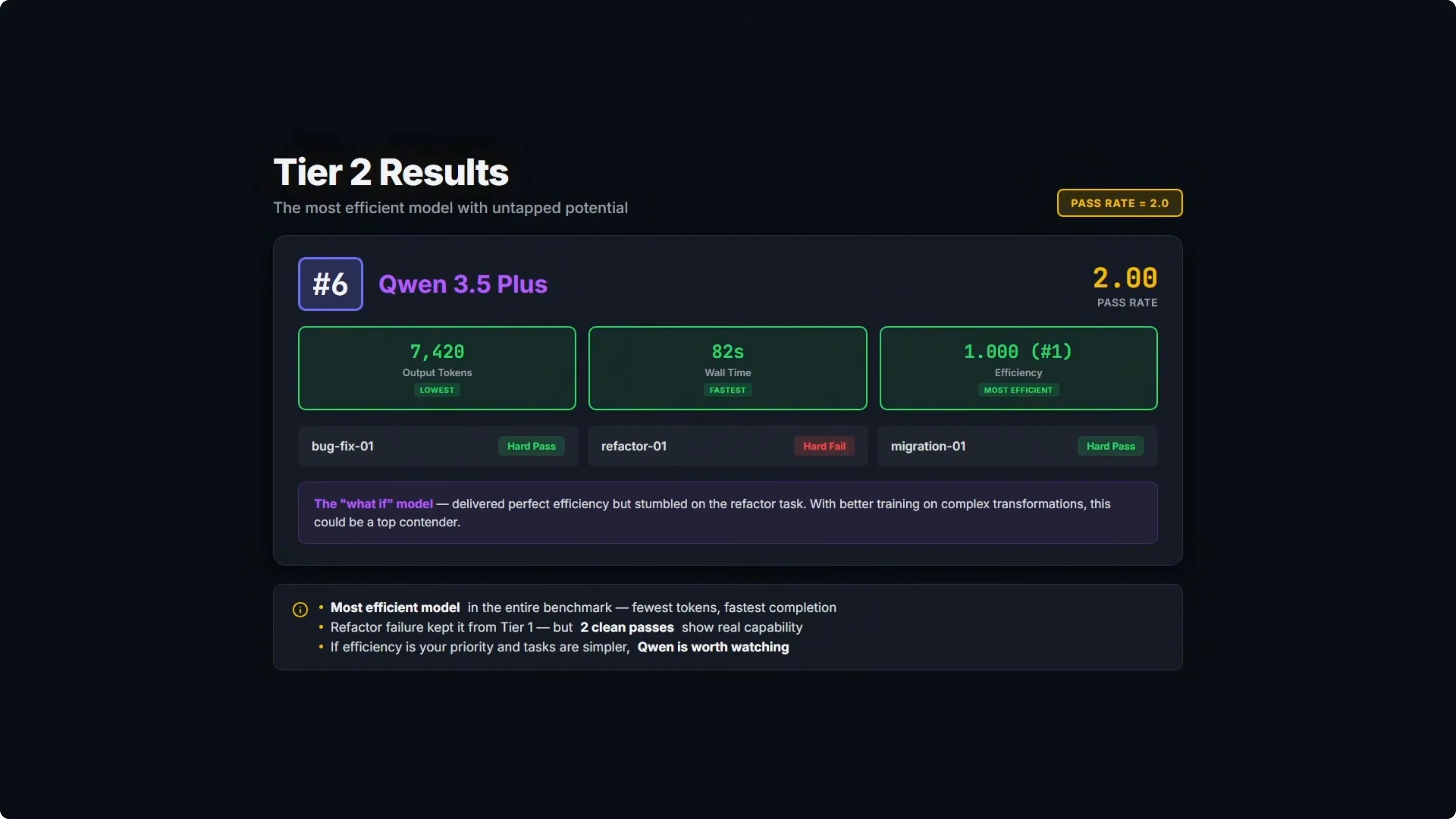
It failed on the same empty string fallback case that tripped DeepSeek and MiniMax. When an asset serial field is an empty string, the code should fall back to the asset ID, but the model used an operator that only checks null and undefined, not empty strings.
Here is a minimal illustration of that bug and fix.
Incorrect nullish coalescing that misses empty strings:
// Fails to fall back for '' because ?? only checks null or undefined
const serial = asset.serial ?? asset.id;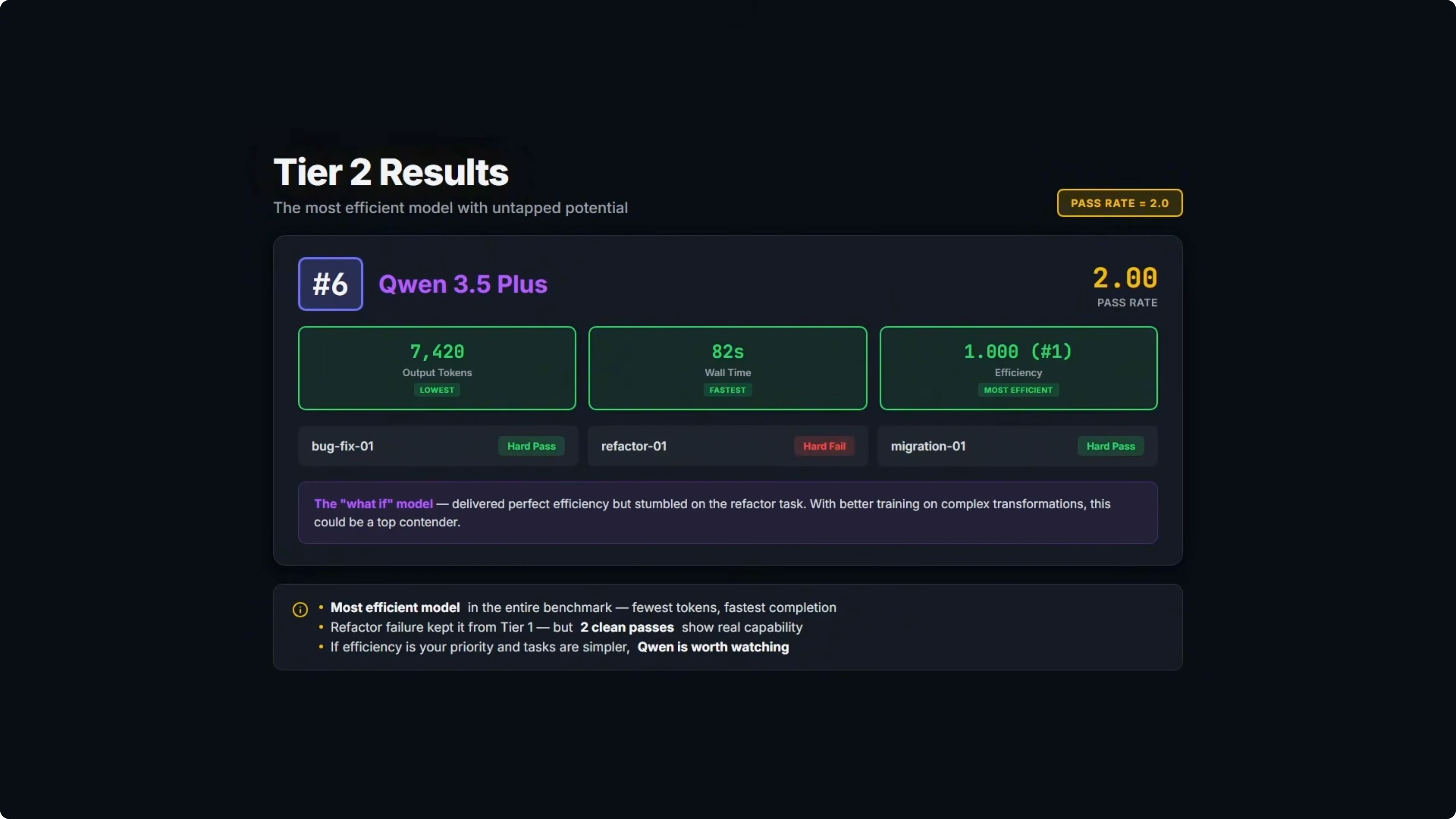
Correct fallback that handles empty strings and nullish values:
const serial = asset.serial === '' || asset.serial == null ? asset.id : asset.serial;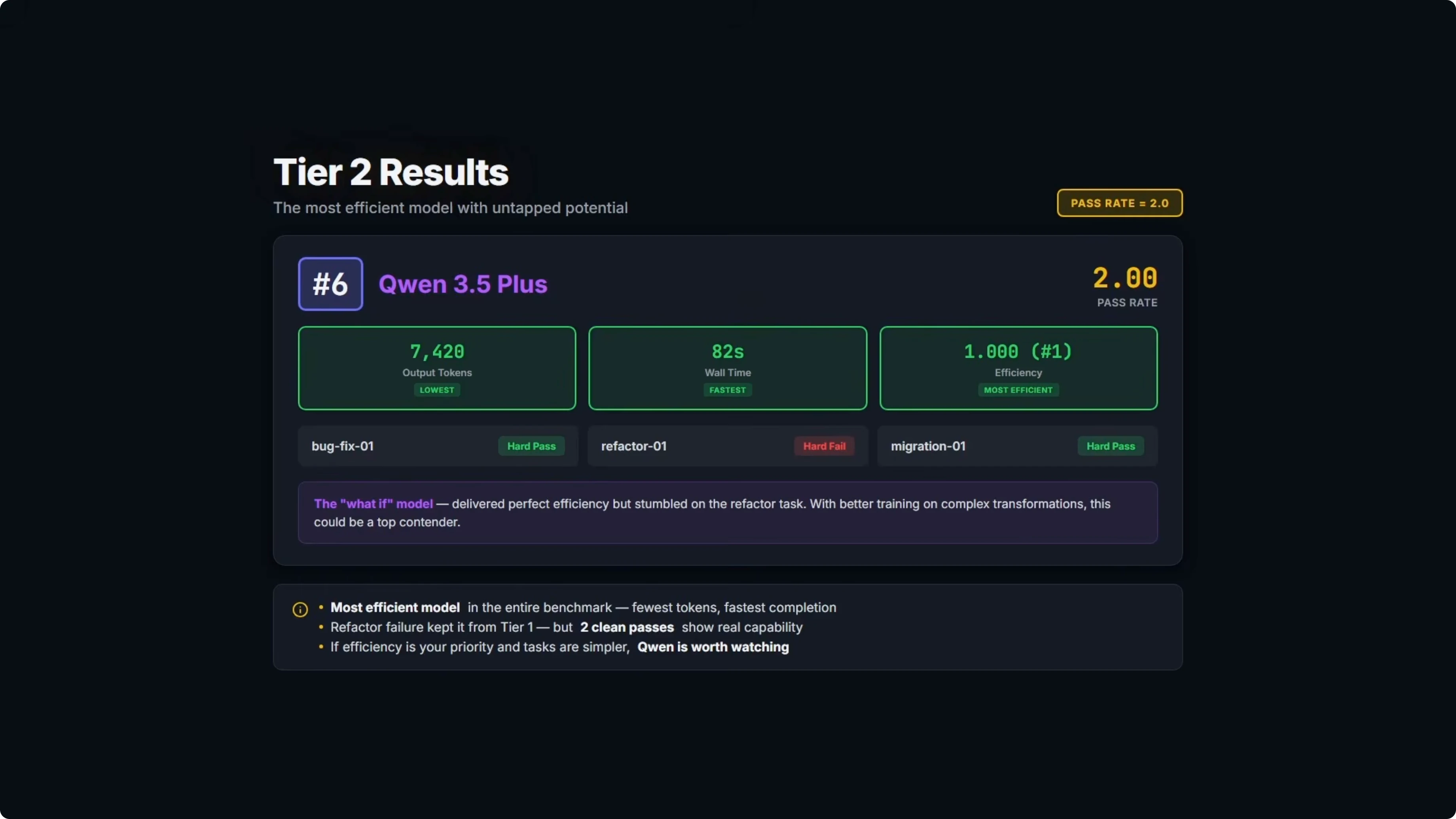
It got 9 out of 10 tests on the first attempt, saw the failure on the repair turn, but still missed the fix and stayed at 9 out of 10. If it had landed that third task, it would be competing for the top spot given its efficiency. For more context on this family, see analysis of Qwen 3.5 Plus.
Tier one results
Five models solved all three problems.
At number one is GPT-5.3 Codex with a perfect 3.0 pass rate and third on efficiency. It delivered three clean passes using about 8,400 output tokens and under 2 minutes total response time.
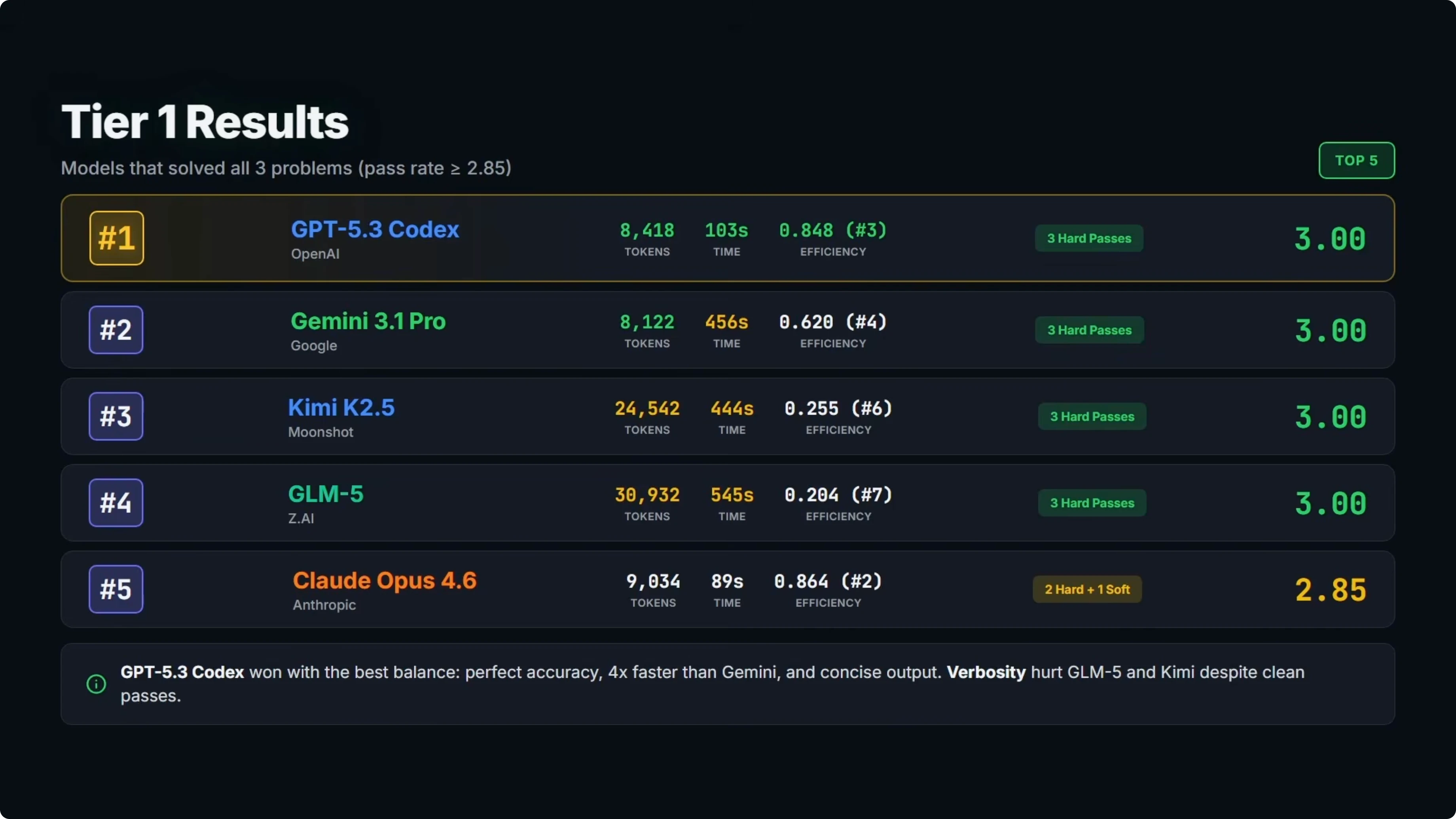
At number two is Gemini 3.1 Pro, also with a perfect 3.0 and fourth on efficiency. All three passes were clean with roughly 8,000 output tokens, slightly fewer than GPT-5.3 Codex, but the response time was about 7.5 minutes, roughly four times slower.
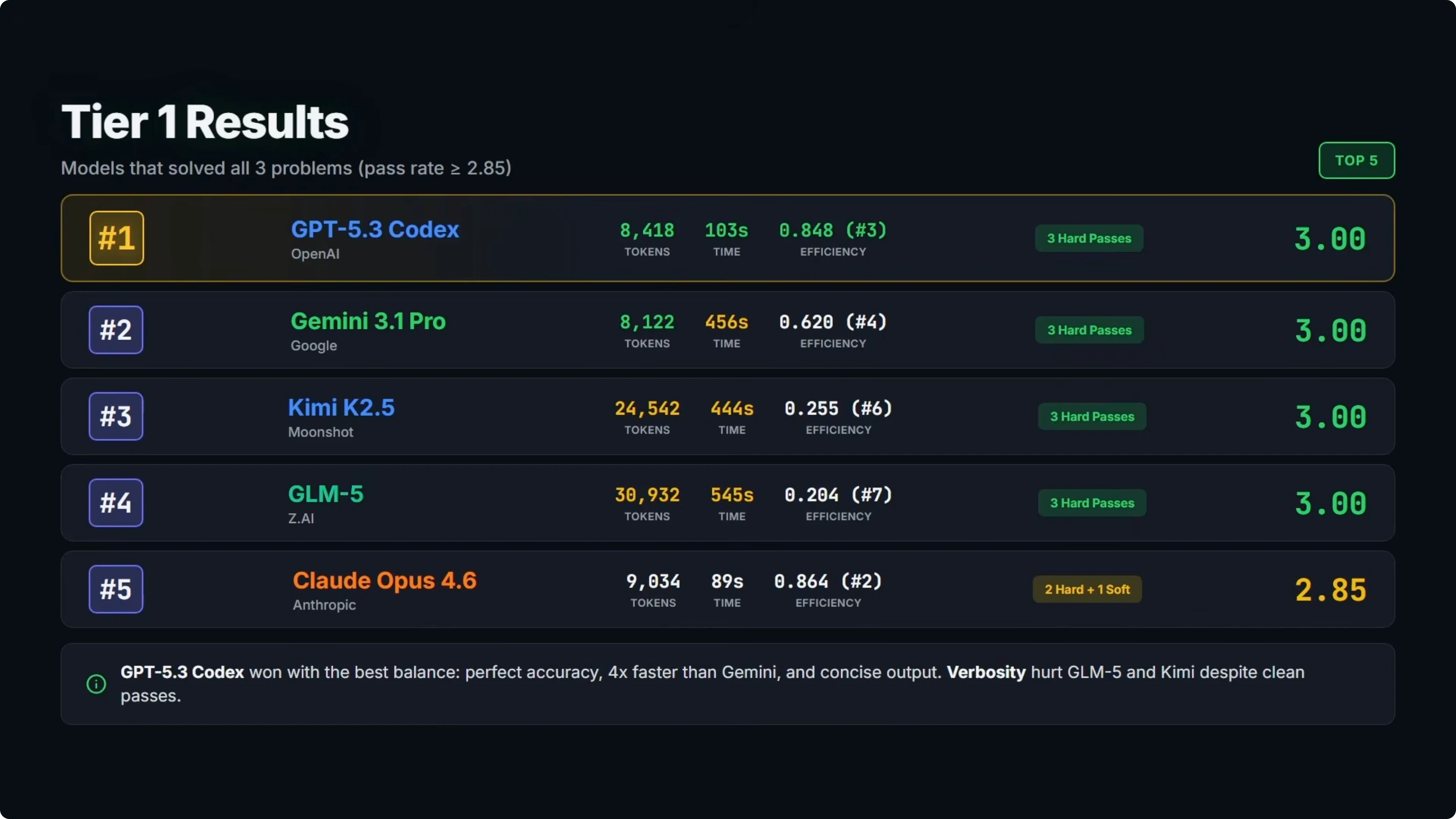
At number three is Kimi K2.5 with a perfect 3.0 and sixth on efficiency. It was a clean sweep on accuracy, but it used about 24,000 tokens and took over 7 minutes, which is far more verbose than the top two on tokens.
At number four is GLM5 with a perfect 3.0 and seventh on efficiency. It produced over 31,000 output tokens and took over 9 minutes, so perfect accuracy with a major trade-off on verbosity and time.
At number five is Opus 4.6 with a 2.85 and second on efficiency. It solved all three problems and the code was correct on all of them, but it included explanatory text outside the code fences on the bug fix, so that task scored a soft pass and dropped its overall rank. If you want a deeper look at model behavior and formatting gotchas, check the full breakdown of Opus 4.6.
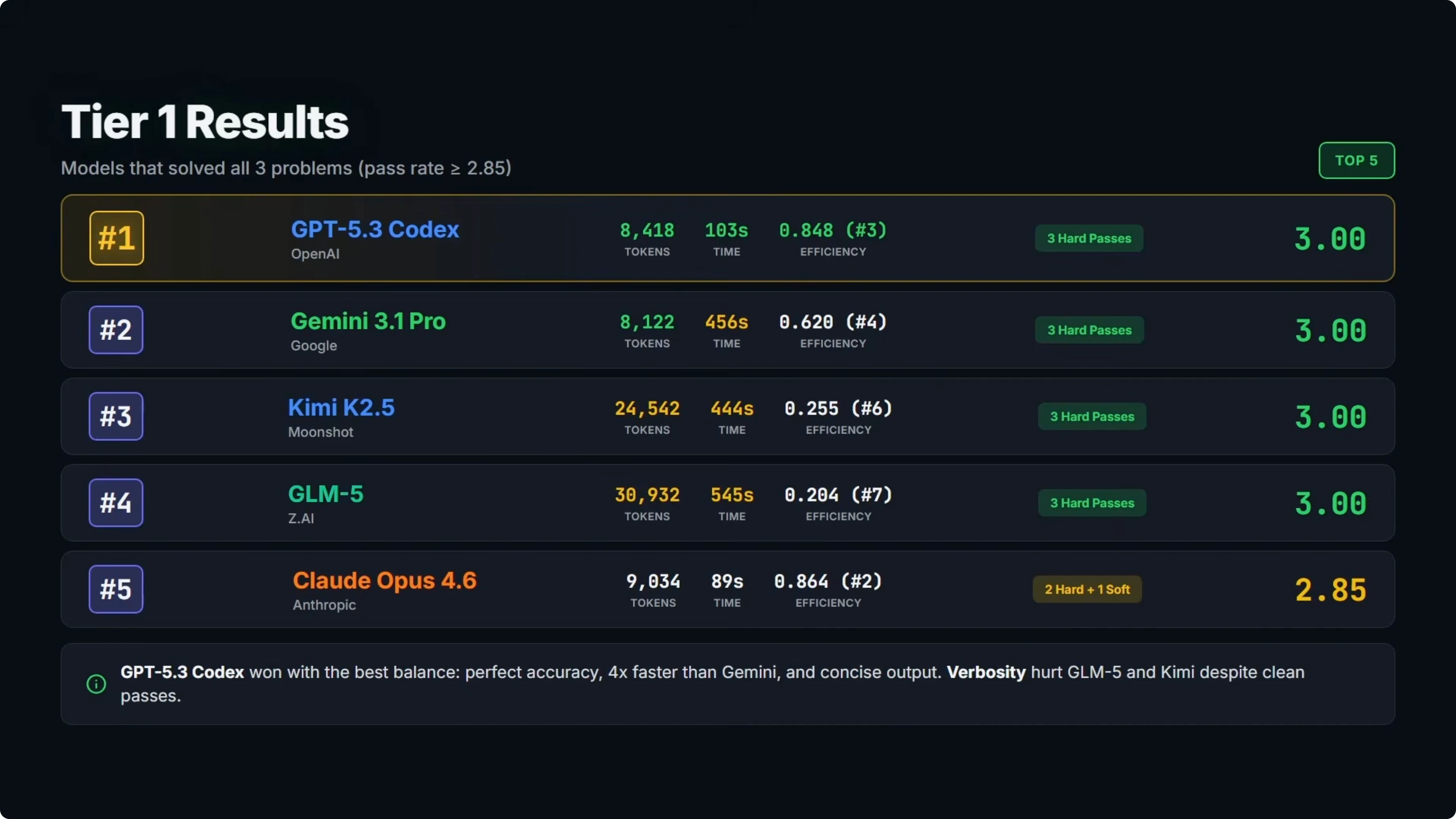
The efficiency gap within tier one is significant. GLM5 and Kimi K2.5 produced about three to four times more tokens than GPT-5.3 Codex and Gemini 3.1 Pro for the same results.
Opus 4.6 was very close to GPT-5.3 Codex on tokens and time, just held back by a format violation on one task. For a focused overview, see this model profile of Opus 4.6.
Version-to-version changes
I compared three newer models to their immediate predecessors. The standout is GPT-5.3 Codex vs GPT-5.2 Codex.
Both achieved a perfect three pass rate, but GPT-5.3 used 28 percent fewer output tokens and was 38 percent faster. That is a 39 percent improvement in overall efficiency on this benchmark.
Opus 4.5 to 4.6 told a different story. Both scored 2.85 with a soft pass on the same bug fix case due to the same format slip, token counts were nearly identical, and 4.6 was slightly slower, dropping efficiency by roughly 2 percent. For a side-by-side comparison of that pair, see this Opus 4.6 vs 4.5 comparison.
Gemini 3 Pro to 3.1 Pro was a marginal 1.5 percent efficiency improvement, with slightly fewer tokens and similar speed. If you want release context around the latest Opus update cycle, here is a brief overview of the new Opus 4.6.
Format compliance example
This benchmark penalizes any text outside fenced code blocks. Here is a minimal example of the correct structure that models were expected to follow.
Correct code-only output:
// src/service/serial.ts
export function getSerial(asset: { serial?: string | null; id: string }) {
return asset.serial === '' || asset.serial == null ? asset.id : asset.serial;
}Incorrect output that would be downgraded to a soft pass: Here is the fix for the serial fallback.
export function getSerial(asset: { serial?: string | null; id: string }) {
return asset.serial === '' || asset.serial == null ? asset.id : asset.serial;
}How to reproduce the test
Prepare a multifile project and package its full context into a single prompt of roughly 25,000 tokens.
Constrain edits to the source directory and instruct the model to return code only inside fenced blocks.
Run three tasks in order: bug fix, refactor, and migration, each with clear acceptance tests.
After the first attempt, allow a single repair turn by feeding back only the test failure output.
Score each task as 1 for a clean pass, 0.85 for a soft pass with format violations, or 0 for a hard fail.
Compute efficiency per task relative to the best result as 60 percent weight on output tokens and 40 percent on wall-clock time.
Aggregate pass rates and efficiency to rank models tier by tier.
Comparison overview
| Model | Tier | Pass rate | Efficiency rank | Output tokens | Total time | Notes |
|---|---|---|---|---|---|---|
| GPT-5.3 Codex | 1 | 3.00 | 3 | ~8,400 | < 2 minutes | Three clean passes, best balance of accuracy and speed |
| Gemini 3.1 Pro | 1 | 3.00 | 4 | ~8,000 | ~7.5 minutes | Clean passes, slower response time |
| Kimi K2.5 | 1 | 3.00 | 6 | ~24,000 | > 7 minutes | Clean passes, high verbosity |
| GLM5 | 1 | 3.00 | 7 | > 31,000 | > 9 minutes | Perfect accuracy, most verbose |
| Opus 4.6 | 1 | 2.85 | 2 | ~9,000 | < 90 seconds | Soft pass due to a format violation on bug fix |
| Qwen 3.5 Plus | 2 | 2.00 | 1 | 7,420 | 82 seconds | Most efficient, failed one edge case on bug fix |
| DeepSeek V3.2 | 3 | 1.85 | 5 | Not stated | Not stated | One clean, one soft, one hard fail, efficiency score 0.39 |
| MiniMax M2.5 | 3 | 1.70 | 8 | ~25,000 | ~19 minutes | Format violations on all tasks, refactor failed |
Use cases and trade-offs
GPT-5.3 Codex
Best fit for end-to-end coding tasks that need high pass rates with low token spend. Pros: three clean passes with strong token and time profile. Cons: none surfaced in this run.
Gemini 3.1 Pro
Good for projects that value accuracy and can absorb longer latency. Pros: clean across all tasks with lean tokens. Cons: significantly slower than the winner.
Kimi K2.5
Works for teams that prioritize accuracy and can budget for more tokens. Pros: clean sweeps on all tasks. Cons: about three times the output tokens vs the top two and slower.
GLM5
Suitable where perfect correctness is the only goal and verbosity is acceptable. Pros: perfect accuracy across the suite. Cons: the most verbose output and the slowest in tier one.
Opus 4.6
Strong choice for speed with near top token efficiency when format is enforced strictly. Pros: correct implementations across all tasks with very fast responses. Cons: one format slip dropped the score, so guardrails on formatting are important. For more performance context and tips, see this Opus 4.6 deep dive.
Qwen 3.5 Plus
Excellent for lean, fast runs where a strict test suite can catch edge cases. Pros: most efficient model by tokens and wall time. Cons: missed an empty string fallback, so add extra checks or patterns for nullish and empty values. You can also see a focused take on this model in this Qwen 3.5 Plus review.
DeepSeek V3.2
Usable for selective tasks, but watch for refactor complexity and repair turns. Pros: can land clean passes on structured migrations. Cons: brittle on refactors and missed an empty string fallback after the repair turn.
MiniMax M2.5
Only advisable for scenarios where format compliance can be relaxed and multiple repair turns are allowed. Pros: could implement some tasks correctly when format was ignored. Cons: persistent format violations and a failed refactor.
Final thoughts
The clear winner is GPT-5.3 Codex. It delivers perfect accuracy with the best overall balance of speed and token efficiency among tier one models.
Gemini 3.1 Pro is a solid second, clean across the board but much slower. Qwen 3.5 Plus is the one to watch given it was the most efficient overall and only needs to close a single recurring edge case to climb the rankings. If you are tracking Opus iterations, here are two helpful references on the model and its update path: Opus 4.6 overview and a side-by-side with Opus 4.5.
Subscribe to our newsletter
Get the latest updates and articles directly in your inbox.

Related Posts

8 Best Claude Code Plugins in 2026 (You Need to Know)
8 Best Claude Code Plugins in 2026 (You Need to Know)

7 Best Claude Code Skills (You Need to Know)
7 Best Claude Code Skills (You Need to Know)

Claude Code Desktop IDE Features (You Need to Know)
Claude Code Desktop IDE Features (You Need to Know)