
Table Of Content
- The product brief
- Test setup and rubric
- GLM-4.7 vs Opus 4.5 vs GPT-5.2 results
- Stack choices
- Reviewer feedback by model
- Reviewer behavior
- Build times and cost
- Dev runs and what actually worked
- GLM 4.7
- Opus 4.5
- GPT 5.2
- How to replicate this one-shot build test
- Use cases and trade-offs
- GLM 4.7
- Opus 4.5
- GPT 5.2
- Final thoughts

GLM-4.7 vs Opus 4.5 vs GPT-5.2
Table Of Content
- The product brief
- Test setup and rubric
- GLM-4.7 vs Opus 4.5 vs GPT-5.2 results
- Stack choices
- Reviewer feedback by model
- Reviewer behavior
- Build times and cost
- Dev runs and what actually worked
- GLM 4.7
- Opus 4.5
- GPT 5.2
- How to replicate this one-shot build test
- Use cases and trade-offs
- GLM 4.7
- Opus 4.5
- GPT 5.2
- Final thoughts
I recently ran a one-turn build test to see how GLM 4.7, Opus 4.5, and GPT 5.2 handle a serious app brief without follow-ups or human edits. Each model got the exact same PRD in an isolated environment. The goal was a single-pass F1 Command Center that pulls real data and renders a multi-section dashboard.
It was a clean head-to-head with blind reviews. Opus 4.5 and GPT 5.2 reviewed all three repos without knowing who built what. The interesting part is how each model judges quality.
The product brief
The product is the F1 Command Center, a web dashboard that turns historical and current F1 data into a pit-wall style experience. It should run year round, including the offseason. The app needs to integrate free data sources, primarily the listed F1 API, with optional weather.
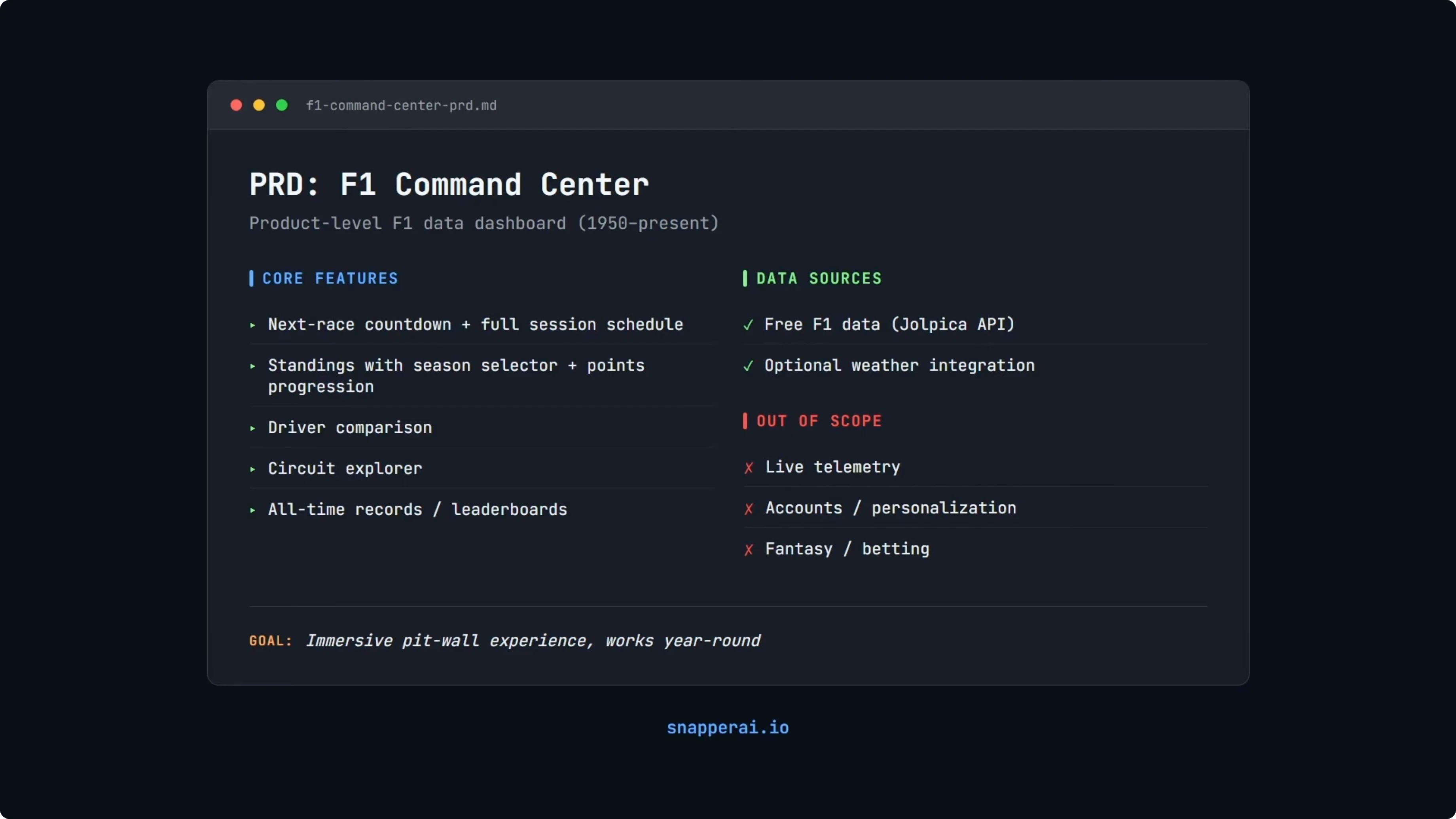
Core features include a multi-section dashboard with an X-ray countdown and a full session schedule. It also needs standings with season selection and points progression, driver comparison, a circuit explorer, and all-time records. Non-goals are live telemetry, accounts, fantasy, and betting.
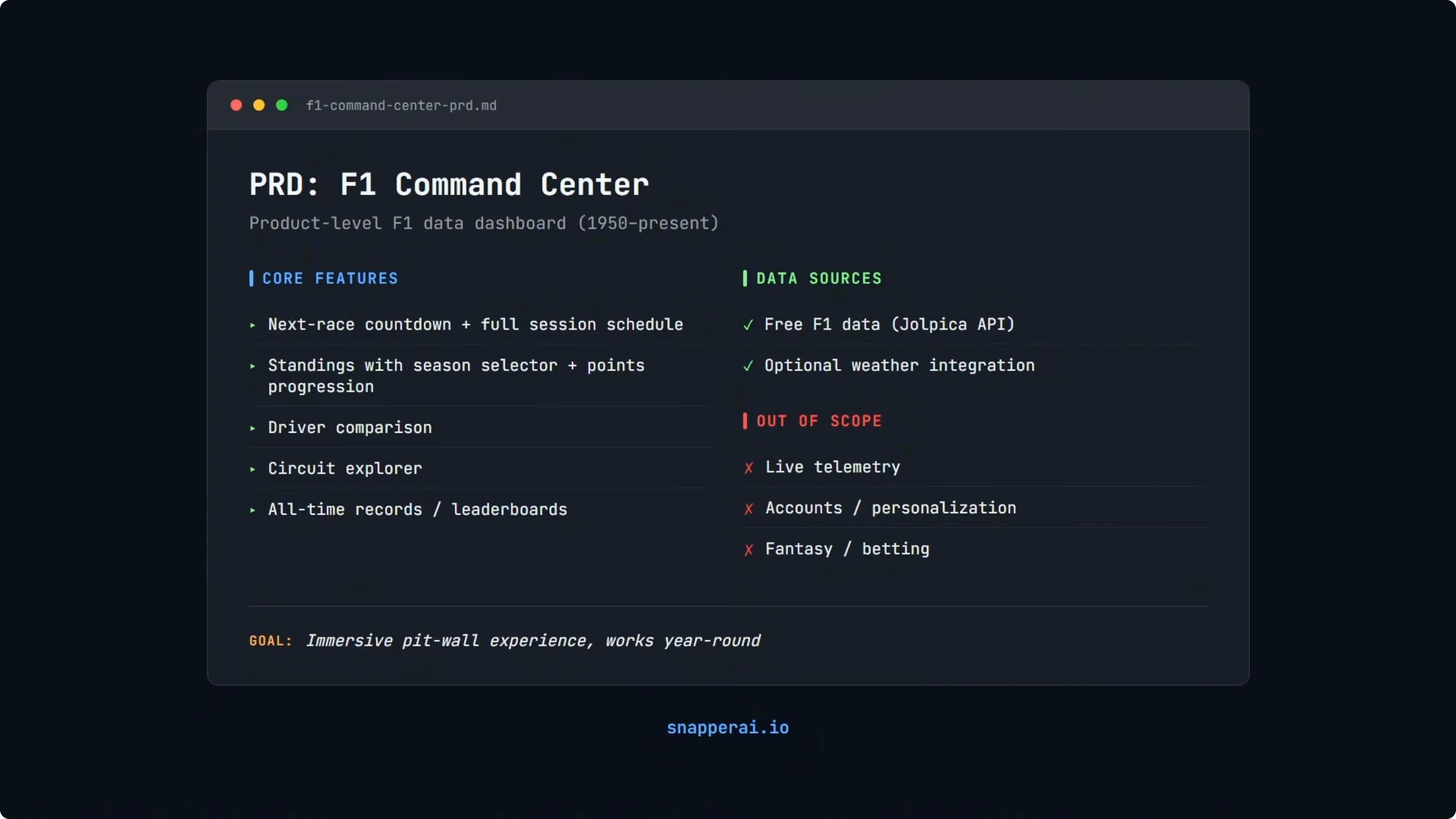
The ask is not just styling a page. The app must integrate real data across decades, handle season selection from 1950 to now, and present it cleanly. I used Opus 4.5 to write the PRD because it consistently produces detailed PRDs.
See GLM 4.7 notes and context if you want more background on the model’s positioning.
Test setup and rubric
All three models got the exact same PRD and I ran every build through Cursor Chat, so the tooling was identical. Each model built its own repo, and those repos are what the reviewers scored. Repos were pushed individually and reviewed blind.
The rubric is 100 points across build and reproducibility, feature coverage, data correctness, resilience and caching, UX and design, accessibility, and engineering quality. UX here means usability, information clarity, mobile fit, and accessibility. Scoring also checks real data, season logic, failure states, and whether the app is runnable.
GLM-4.7 vs Opus 4.5 vs GPT-5.2 results
Here are the final scores from the blind reviews and a quick snapshot of choices and trade-offs.
| Model | Opus review | GPT review | Average | Stack choice | Build time | Cost note | Notable strengths | Notable issues |
|---|---|---|---|---|---|---|---|---|
| GLM 4.7 | 85 | 47 | 66 | Next.js-style React + TypeScript | 50m 14s | Lowest raw token cost | Good layout, modular structure, season switching | Runtime bug on circuit detail, trust and fallback |
| Opus 4.5 | 94 | 72 | 83 | Vite-based client-only React | 25m 07s | Highest output cost | Polished UI, broad feature coverage | Simulated data presented as real in some views |
| GPT 5.2 | 94 | 88 | 91 | Next.js App Router with server routes | 23m 20s | Moderate input, pricey output | Real per-round standings, correct propagation | Minor lint, conservative visuals, Node version gap |
Stack choices
Tech stack was open-ended in the PRD. All three used modern React and TypeScript stacks.
GPT 5.2 built a Next.js App Router application with server capabilities, which makes validation and data boundaries easier to enforce. Opus 4.5 built a Vite-based client-only React app that is fast to scaffold and tends to favor UI speed and polish. GLM 4.7 also chose a Next.js-style setup but had more wiring and runtime stability issues.
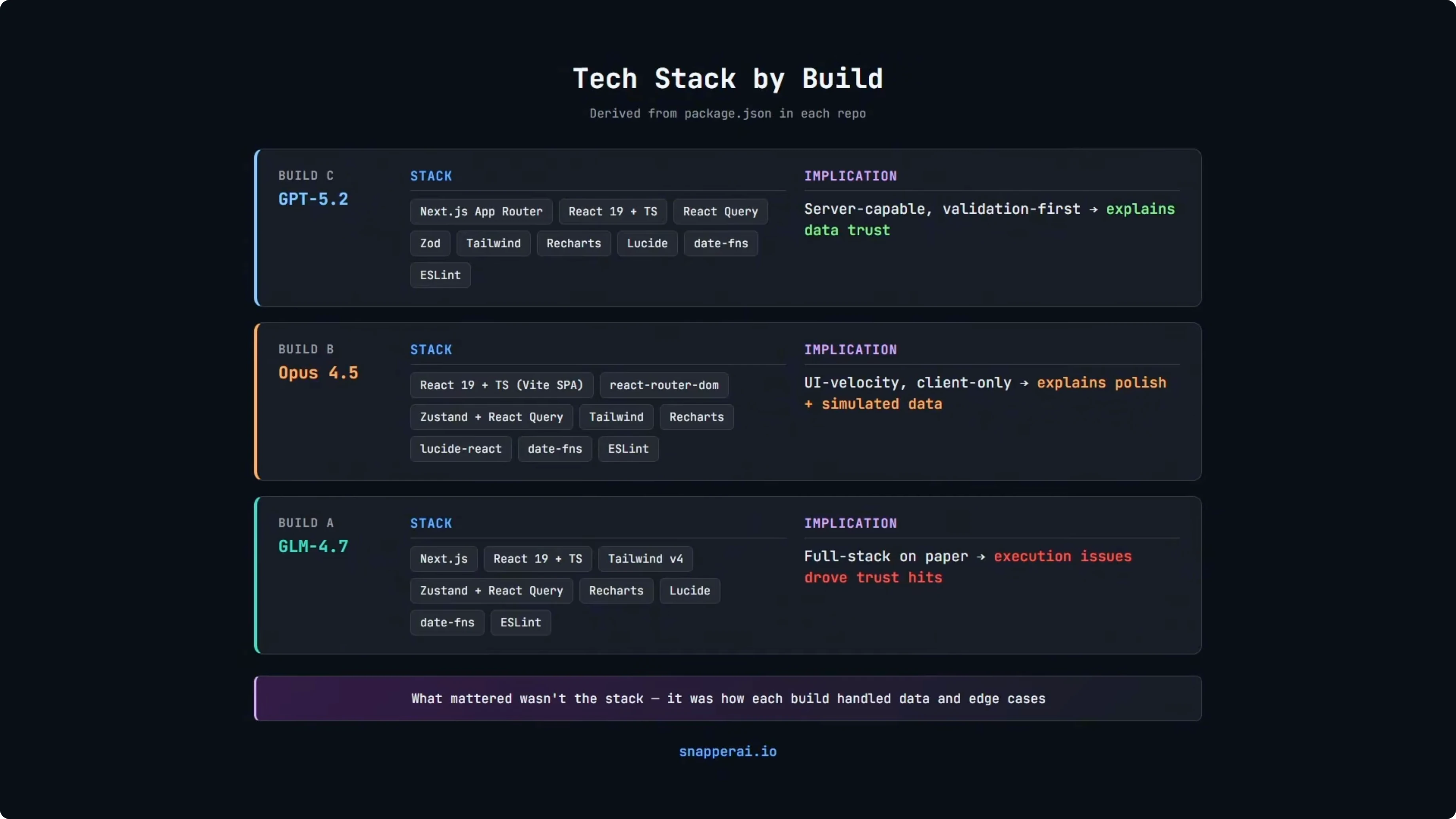
What mattered for the scores was not the stack itself. It was how well each build handled data and edge cases within that setup. Different stacks just came with different trade-offs.
Reviewer feedback by model
GLM 4.7 Opus rewarded architectural intent with a three-tier fallback hierarchy, broad route coverage across home, standings, calendar, and drivers, and a modular Next.js structure that looked production oriented. GPT penalized trust issues such as a runtime-breaking bug on a circuit detail route. It also flagged incorrect API assumptions, on-this-day data handling, and fallback snapshot data shown as authoritative without validation.
Opus 4.5 Opus praised information clarity and navigation structure, near-complete feature coverage, a clean fallback abstraction, and a strong championship progression chart. GPT penalized data integrity violations such as Math.random used to plot season standings rather than specific results. It also flagged simulated intermediate race data shown as real, hardcoded all-time records, and incorrect fallback state in the UI.
GPT 5.2 Both reviewers agreed it had strong championship progression computed from real per-round standings. It included a proper internal API gateway for fallback logic, correct season propagation, and internally consistent snapshot data. Deductions were smaller lint issues, conservative visuals, a Node version mismatch, and error states that render as no data.

Reviewer behavior
Even with the same rubric and the same prompt, the models judged differently. Opus tends to reward architectural completeness and overall structure.
It treats most issues as fixable and scores like a senior design review. GPT 5.2 is far stricter on data integrity and release blockers and penalizes hard if the data is questionable or the build is unstable. That explains the score gaps as two different review philosophies.
For more nuance on how Opus variants shape product trade-offs, see this Opus 4.6 vs 4.5 comparison. It aligns with what surfaced here in terms of structure and presentation.
Build times and cost
Build time here is observational only and not part of scoring. Faster does not automatically mean better.
In this run, GPT 5.2 finished in 23 minutes 20 seconds, Opus 4.5 in 25 minutes 7 seconds, and GLM 4.7 in 50 minutes 14 seconds. I did not track exact token usage, so cost is theoretical based on published pricing. From a raw token perspective, GLM 4.7 is the cheapest, GPT 5.2 has moderate input cost but higher output, and Opus 4.5 is the most expensive on output.
I am building an API test rig that will benchmark tasks and track exact token usage and cost. Until then, the practical takeaway is cost-aware composition. Use cheaper models for repeatable background work, GPT 5.2 for correctness and critical logic, and Opus for structure and presentation when it adds real value.
For broader benchmarks across families, this GPT-5.3 Codex vs Opus and others study is a helpful comparative reference.
Dev runs and what actually worked
GLM 4.7
The UI is solid at first glance with a clean layout, sensible navigation, and working season switching across pages. Switching to 2024 and back to 2025 updated standings correctly, including Lando Norris as the winner in the 2025 view. The weaknesses are depth and stability.
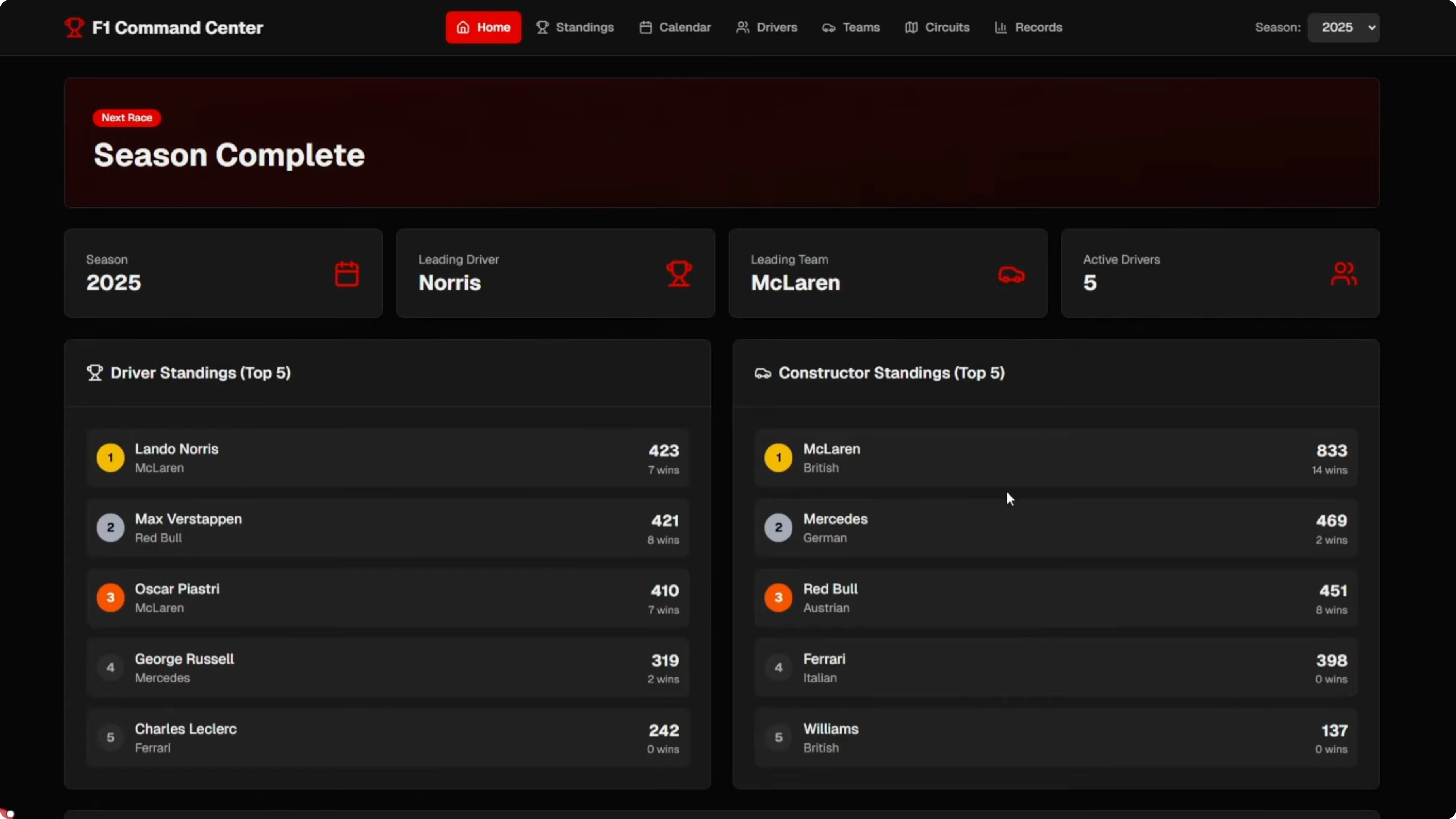
Calendar did not surface completed race results. Circuit pages were not season aware and the records page hit a runtime error. The takeaway is that GLM 4.7 can scaffold a decent UI and basic season logic, but you must validate data trust and runtime paths before shipping anything serious.
Opus 4.5
This is where UI polish and product thinking show. Navigation is clear, features are broadly implemented, and the circuit and driver detail views are well designed.

On season 2024, the driver standings show Max Verstappen on top and the UI layout is clean. The championship battle graph is where GPT 5.2 penalized Opus, because the chart used randomized data between known endpoints to arrive at the correct final result. Visuals and structure are excellent, but parts of the data were presented as real when they were not.
GPT 5.2
The UI is more conservative with less visual flair than Opus, but the underlying logic is strong. Standings, calendar results, and season propagation are computed from real data rather than using simulated intermediates. It is the most trustworthy implementation on data integrity, with smaller issues like lint, a Node version mismatch, and no-data rendering for certain errors.

How to replicate this one-shot build test
Use a single, detailed PRD that specifies product goals, data sources, non-goals, and acceptance criteria for a multi-section F1 dashboard. Keep tech stack open-ended and require real data integration, season selection from 1950 onward, and a clean UI.
Run each model in the same tool and environment. In my case it was Cursor Chat with identical settings and no follow-ups, and each model built a separate repo.
Push each repo to a neutral host and run blind reviews with the same prompt and rubric. Ask for a detailed score across build and reproducibility, feature coverage, data correctness, resilience and caching, UX and design, accessibility, and engineering quality.
Run each build locally and verify season propagation, data trust, error boundaries, and fallback behavior. Note runtime failures, incorrect API assumptions, and any simulated data presented as real.
Example: internal API gateway with validated fallbacks This pattern matches the GPT 5.2 approach with a route handler that validates external data, tags fallback state, and keeps snapshot data internally consistent.
// app/api/standings/route.ts
import { NextResponse } from 'next/server';
import { z } from 'zod';
import fs from 'node:fs/promises';
import path from 'node:path';
const StandingSchema = z.object({
season: z.number().int().min(1950),
rounds: z.array(z.object({
round: z.number().int(),
driverId: z.string(),
points: z.number(),
position: z.number().int()
}))
});
async function fetchFromSource(season: number) {
const res = await fetch(`${process.env.F1_API_BASE}/standings?season=${season}`, {
headers: { 'Accept': 'application/json' },
cache: 'no-store'
});
if (!res.ok) throw new Error(`Upstream error ${res.status}`);
const json = await res.json();
return StandingSchema.parse(json);
}
async function readSnapshot(season: number) {
const file = path.join(process.cwd(), 'snapshots', `standings-${season}.json`);
const raw = await fs.readFile(file, 'utf8');
const json = JSON.parse(raw);
return StandingSchema.parse(json);
}
export async function GET(req: Request) {
const { searchParams } = new URL(req.url);
const season = Number(searchParams.get('season') ?? new Date().getFullYear());
try {
const data = await fetchFromSource(season);
return NextResponse.json({ ok: true, fallback: false, data });
} catch (err) {
try {
const data = await readSnapshot(season);
return NextResponse.json({ ok: true, fallback: true, data });
} catch {
return NextResponse.json({ ok: false, error: 'No data available' }, { status: 502 });
}
}
}Example: season propagation utility Make sure the selected season flows across routes and components without desyncs.
// lib/season.ts
import { cookies } from 'next/headers';
export function getSeasonFromRequest(defaultSeason = new Date().getFullYear()) {
const cookieStore = cookies();
const raw = cookieStore.get('season')?.value;
const n = raw ? Number(raw) : defaultSeason;
return Number.isInteger(n) && n >= 1950 ? n : defaultSeason;
}
export function persistSeason(season: number) {
'use server';
// set a cookie for cross-route consistency
// @ts-ignore - Next runtime cookie API
cookies().set('season', String(season), { path: '/', httpOnly: false, maxAge: 60 * 60 * 24 * 180 });
}For a broader look at multi-model build tests and how to mix strengths, see this next-gen comparison that extends the idea across newer variants and codecs.
Use cases and trade-offs
GLM 4.7
Pros: It can scaffold a decent UI quickly with sensible navigation and it handled season switching correctly across pages. It showed architectural intent with a modular Next.js structure and a three-tier fallback idea.
Cons: Depth and runtime stability were weaker with a circuit detail bug, records page error, and trust issues around fallback data. Validate data paths and error states before shipping anything serious.
Best use cases: Iterations, smaller tasks, and basic UI builds where speed and cost matter. It is a decent option for background work and first drafts on presentation.
Opus 4.5
Pros: Strong UI polish, clear navigation, broad feature coverage, and clean fallback abstractions. Circuit and driver detail views were well designed and product thinking was evident.
Cons: Simulated data was presented as real in places, including a randomized championship progression between known endpoints. Fallback status was not always reflected correctly in the UI state.
Best use cases: Structure, completeness, and product experience where presentation adds real value. Pair it with a stricter reviewer for data integrity before release.
GPT 5.2
Pros: Real per-round standings, correct season propagation, an internal API gateway for validated fallbacks, and internally consistent snapshots. It produced the most trustworthy implementation on data correctness.
Cons: More conservative visuals, minor lint issues, a Node version mismatch, and some no-data render states. Visuals can be refined after correctness is locked.
Best use cases: Correctness gates, critical logic, and production checks on data integrity. Use it as a release blocker to prevent simulated or invalid data from shipping.
If you want to see how GLM and Opus compare against a different family as a sanity check, this Gemini vs Opus vs GPT study adds helpful context across stacks and review styles.
Final thoughts
The main takeaway is not that one model is objectively better. Each model optimizes for a different definition of quality.
GPT 5.2 prioritizes correctness, data integrity, and release safety. Opus favors structure, completeness, and product experience. GLM focuses on speed and breadth, sometimes at the expense of depth.
Everything here reflects a single-agent Cursor setup with one-shot builds and no follow-ups. In a different setup with iterative prompting, task decomposition, or a longer refinement loop, these models can behave very differently. Treat this as a snapshot of behavior under the same constrained workflow.
Subscribe to our newsletter
Get the latest updates and articles directly in your inbox.

Related Posts

8 Best Claude Code Plugins in 2026 (You Need to Know)
8 Best Claude Code Plugins in 2026 (You Need to Know)

7 Best Claude Code Skills (You Need to Know)
7 Best Claude Code Skills (You Need to Know)

Claude Code Desktop IDE Features (You Need to Know)
Claude Code Desktop IDE Features (You Need to Know)