
Table Of Content
- Why DeepSeek V4 Pro and Flash Redefine GPU Clusters?
- Think modes in Why DeepSeek V4 Pro and Flash Redefine GPU Clusters?
- Benchmarks and coding edge
- Slime mold simulation test
- Scheduling puzzle test
- Multilingual translation test
- Expert mode physics test
- CSA, HCA, MHC, optimizer, OPD, and FP4 Q80 explained
- Use cases that fit Why DeepSeek V4 Pro and Flash Redefine GPU Clusters?
- Final thoughts on Why DeepSeek V4 Pro and Flash Redefine GPU Clusters?

Why DeepSeek V4 Pro and Flash Redefine GPU Clusters?
Table Of Content
- Why DeepSeek V4 Pro and Flash Redefine GPU Clusters?
- Think modes in Why DeepSeek V4 Pro and Flash Redefine GPU Clusters?
- Benchmarks and coding edge
- Slime mold simulation test
- Scheduling puzzle test
- Multilingual translation test
- Expert mode physics test
- CSA, HCA, MHC, optimizer, OPD, and FP4 Q80 explained
- Use cases that fit Why DeepSeek V4 Pro and Flash Redefine GPU Clusters?
- Final thoughts on Why DeepSeek V4 Pro and Flash Redefine GPU Clusters?
DeepSeek has just dropped V4, a model that might make every GPU cluster on the planet obsolete, a 1.6 trillion parameter beast that runs million token context at 27 percent of the compute cost. This is not a drill. I started testing it right away with hard prompts that force deep reasoning and real code synthesis.
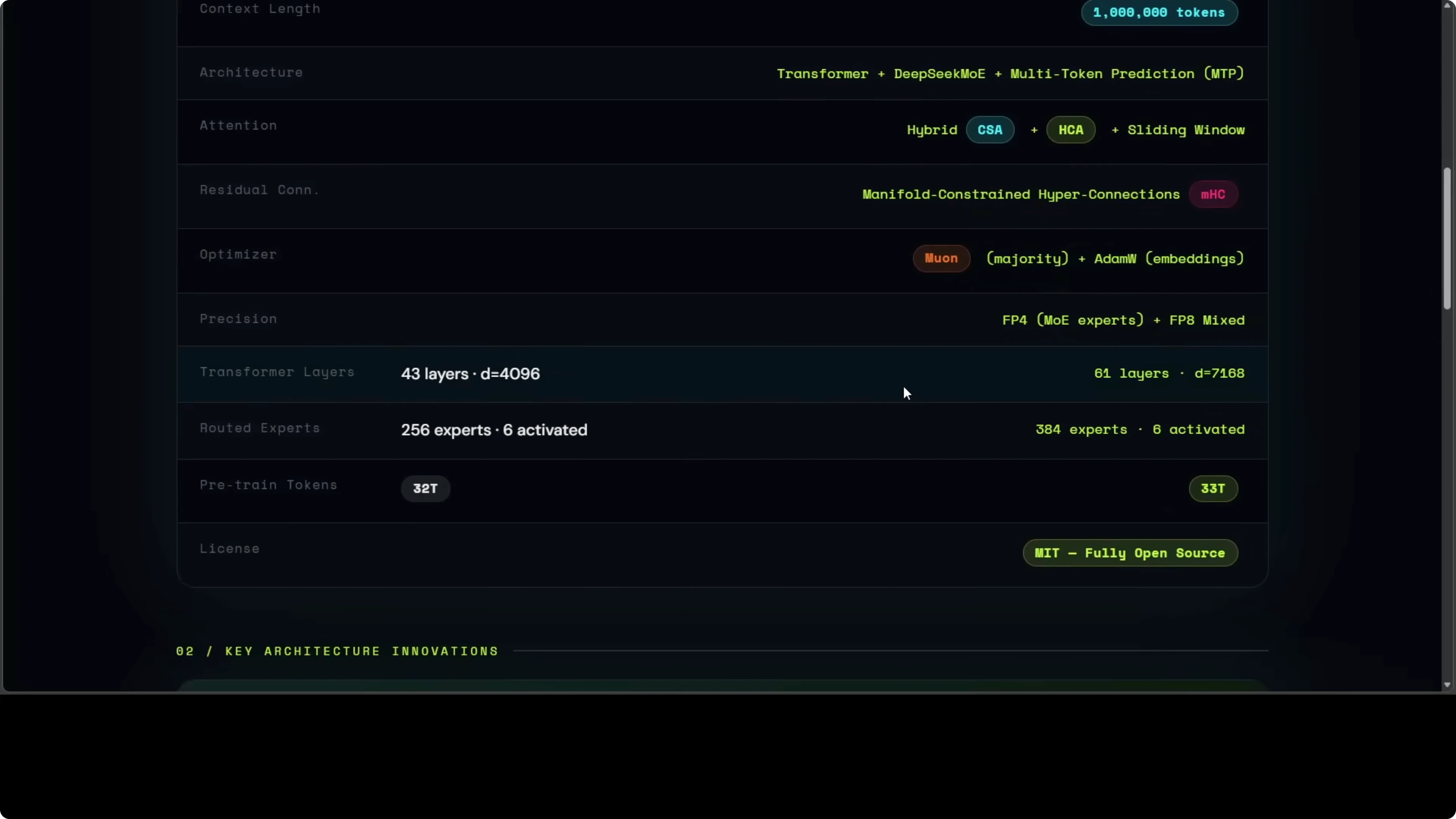
DeepSeek V4 is not one model. It is a whole new architectural philosophy that rethinks how attention works under long context. The result is hybrid CSA and HCA that can hold an entire code base or hours of conversation in context while using a fraction of memory and compute compared to six months ago.
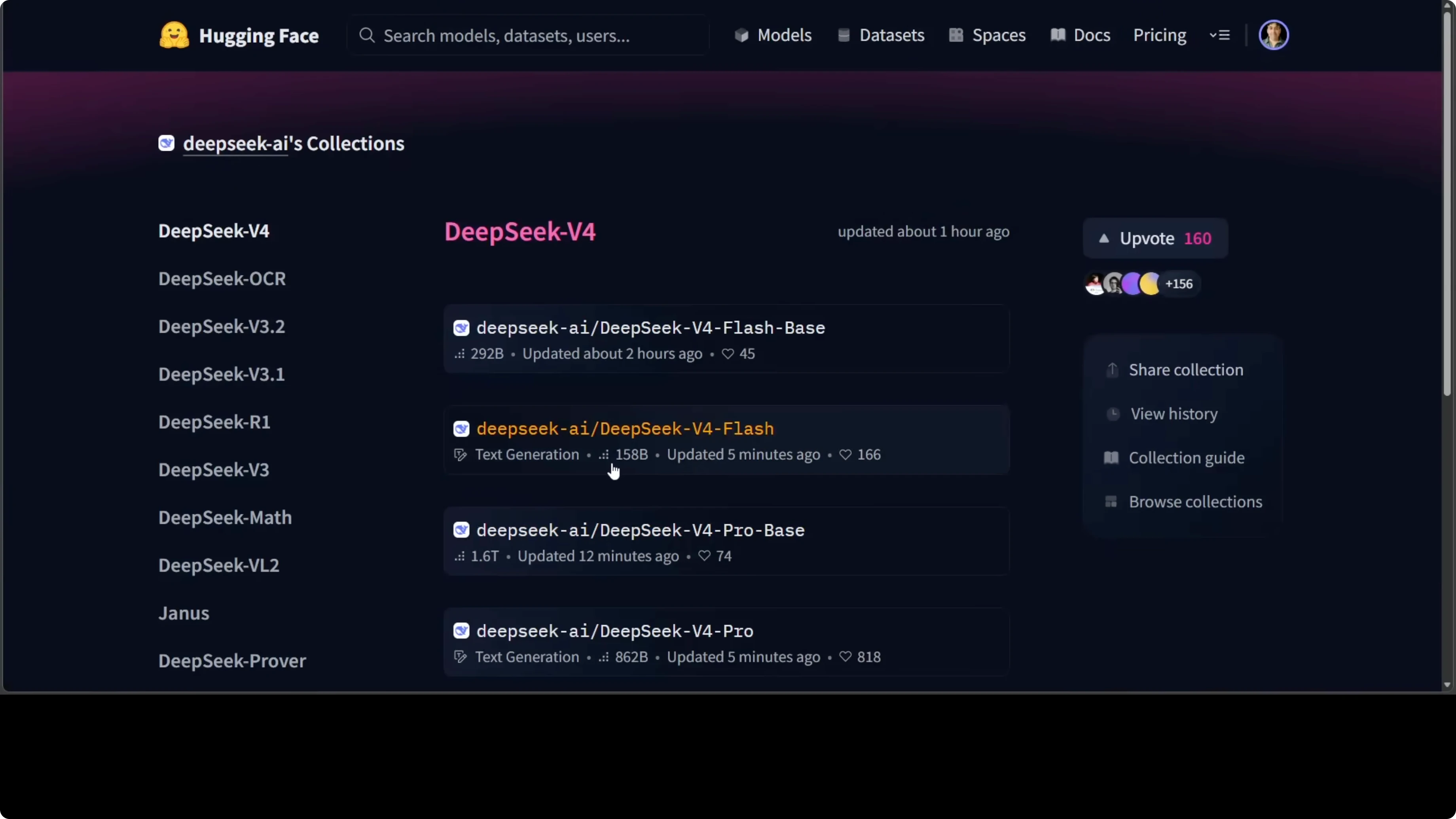
The Flash variant at 284 billion parameters is a mixture of experts with only 13 billion firing at once and it already beats DeepSeek 3.2 across most benchmarks while being far cheaper to run. The Pro variant at 1.6 trillion total parameters is currently the strongest open source model on the planet across multiple measures. Training also brought a new optimizer, a new residual connection system, and a post training pipeline that breeds specialist experts then distills them into one unified brain.
I do not use the word lightly. This feels like a generational leap in reasoning and coding, and I wanted to see if it lives up to that.
Why DeepSeek V4 Pro and Flash Redefine GPU Clusters?
They did not just scale parameters. They redesigned attention with Compressed Sparse Attention (CSA) and Hierarchical Compressed Attention (HCA) to make long range reading efficient. In practice, CSA caches by a factor of m equals 4, which keeps memory modest during million token traces.
Flash is tuned for speed and cost. Pro is tuned for maximum capability and deep chain of thought. Coding quality stands out already, and the model sustains long multi step reasoning across messy prompts.
If you want a conceptual tour of long memory ideas and memory tools from the same ecosystem, see this Engram explainer.
Think modes in Why DeepSeek V4 Pro and Flash Redefine GPU Clusters?
There are three modes here: Non think, Think high, and Think max. Non think is instant and minimal, Think high adds more internal steps, and Think max goes deepest. For cost sensitive flows, Flash with Non think hits a sweet spot, and for deep reasoning, Pro with Think max is where it shines.
Benchmarks and coding edge
Benchmarks are strong without pretending to top every chart. GPT still beats it in some tests, but coding is excellent and the long context keeps chains coherent for very long programs. For a head to head perspective across current flagships, see this comparison of DeepSeek V4 Pro vs Claude Opus vs Qwen3.6 Max.
If you focus on agentic software work, also see this walkthrough on agentic coding with OpenClaw and DeepSeek V4 Pro.
Slime mold simulation test
I asked the model to write a single self contained HTML file that simulates a slime mold style agent system. The spec was to produce thousands of microscopic agents that leave chemical trails, sense each other, and self organize into a living network with no procedural hints beyond the spec. It got the simulation right and the behavior looked genuinely alive.
This is a real biological style simulation of Physarum, a single celled organism that builds networks mirroring structures like the Tokyo rail system. I adjusted parameters live such as decay rate, sensor angle, and turn speed, and every control worked. Palettes like inferno, void, point, random, and circle all responded as expected and the network grew more granular as I increased agents.

Here is the exact style of prompt I used to force a fully self contained artifact.
Create a single HTML file with no external assets.
Use a full screen canvas and implement a Physarum-inspired agent simulation.
Each agent samples three sensors ahead and to the sides, turns toward the strongest local trail, moves, and deposits trail.
Implement trail diffusion and decay on a float buffer texture.
Expose UI sliders for agent count, step size, turn speed, sensor distance, sensor angle, deposit amount, diffusion rate, and decay rate.
Add color palettes named inferno, void, point, random, and circle that map trail intensity to color.
Ensure animation starts on load and runs at 60 fps.
No external libraries. Everything in one file.If you want to try similar long context code tasks on your machine, you can run DeepSeek V4 Flash locally and iterate quickly on HTML and JS artifacts.
Scheduling puzzle test
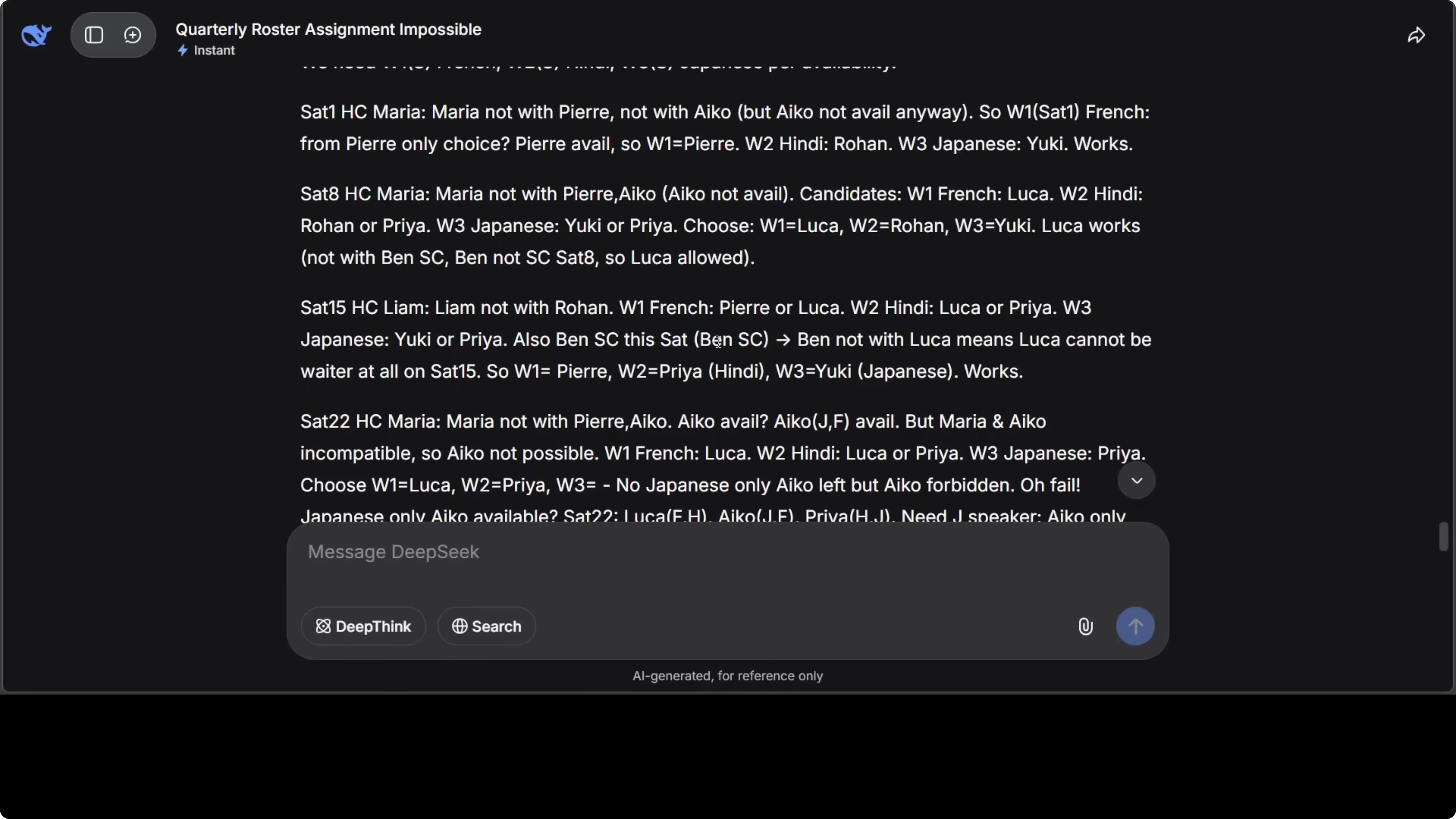
I turned off deep think and used a hardened prompt that defines a roster with hard constraints. The problem includes staff availability, language requirements, incompatibility rules, consecutive shift limits, and conditional dependencies stacked together. It is tough because you cannot solve a single constraint in isolation.
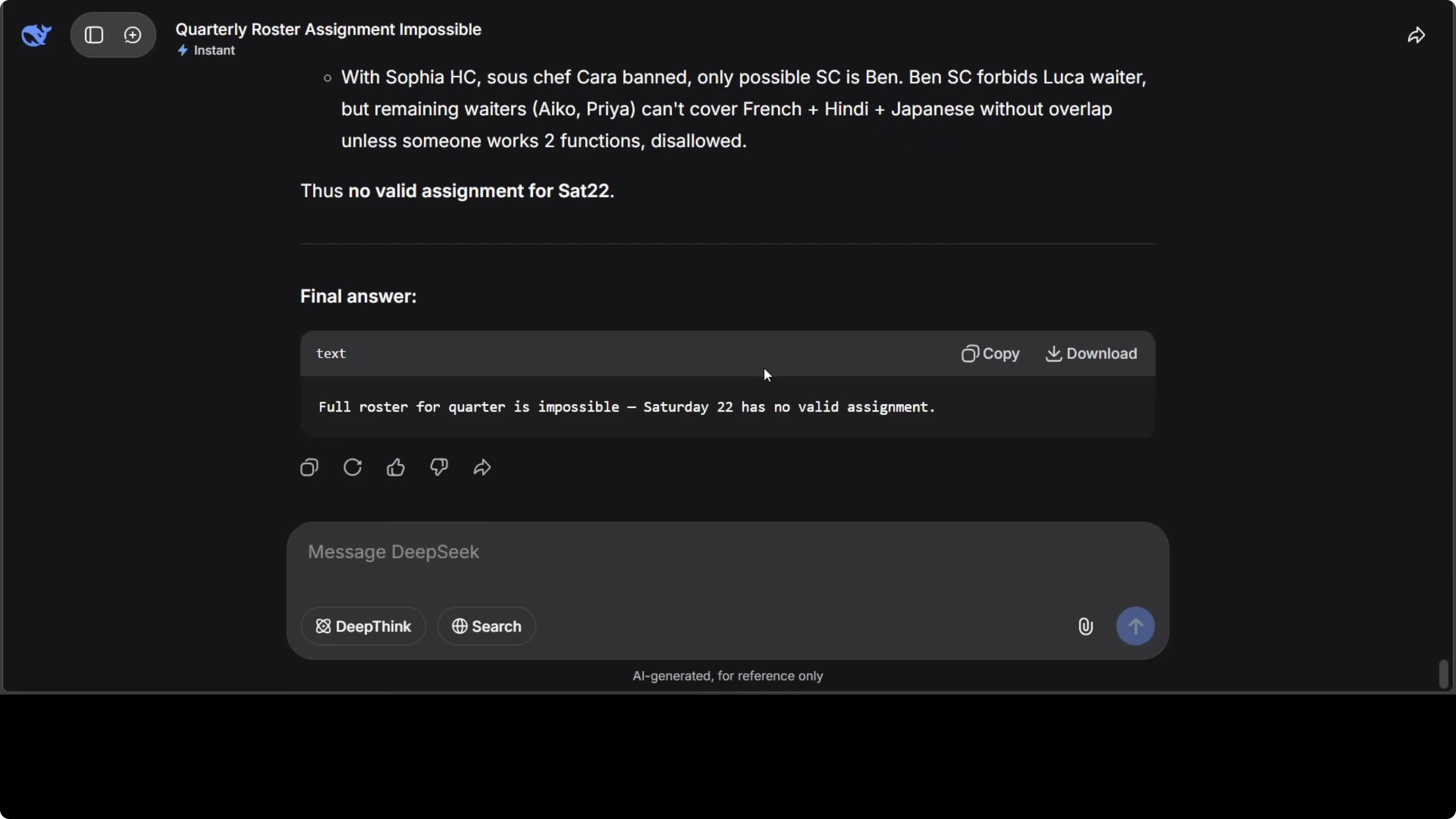
Functions included a French embassy event needing French speaking staff, several cultural association events including Japanese and Indian, and a Japanese tea ceremony. Some staff do not get along, some are not available, and the model had to schedule across multiple Saturdays. The model correctly identified that Saturday 22 is impossible and showed reasoning step by step.
It solved all dependencies and produced a clean roster for all solvable Saturdays, then documented the dead end for the unsatisfiable date. Here is the prompt template that captures the constraint logic.
You are a constraint solver. Build a weekend roster that satisfies all constraints or prove unsatisfiable.
Constraints:
1) Each function requires a fixed number of staff with listed languages.
2) Staff have availability by date and shift.
3) Incompatibility pairs cannot share a function or overlapping shift.
4) No staff may work more than one function per day or exceed consecutive shift limits.
5) Some functions require at least one senior.
Output:
- A feasibility assessment per date.
- A final schedule per solvable date with assignments and justification.
- If any date is impossible, show the minimal conflicting set that causes the dead end.Multilingual translation test
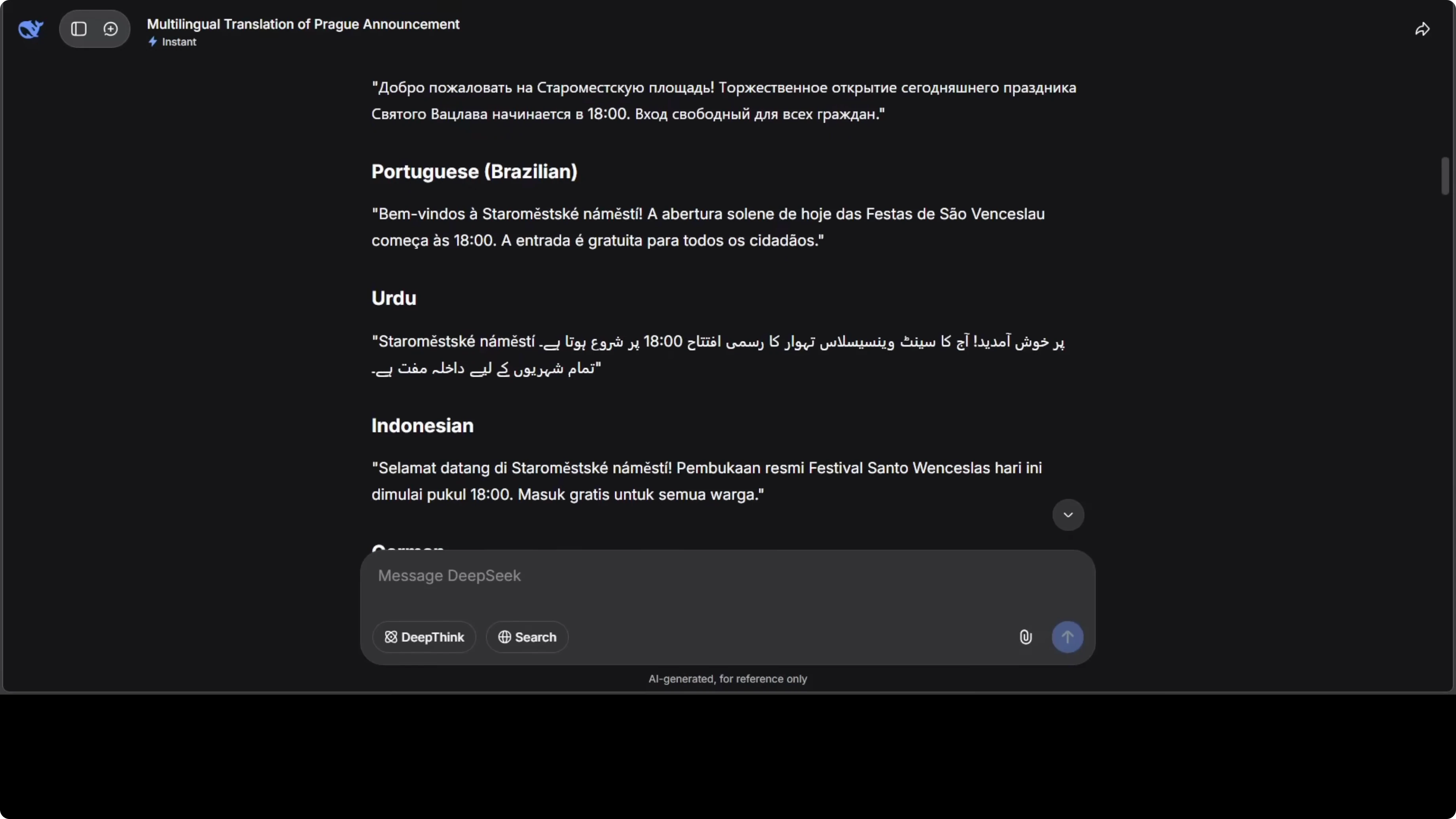
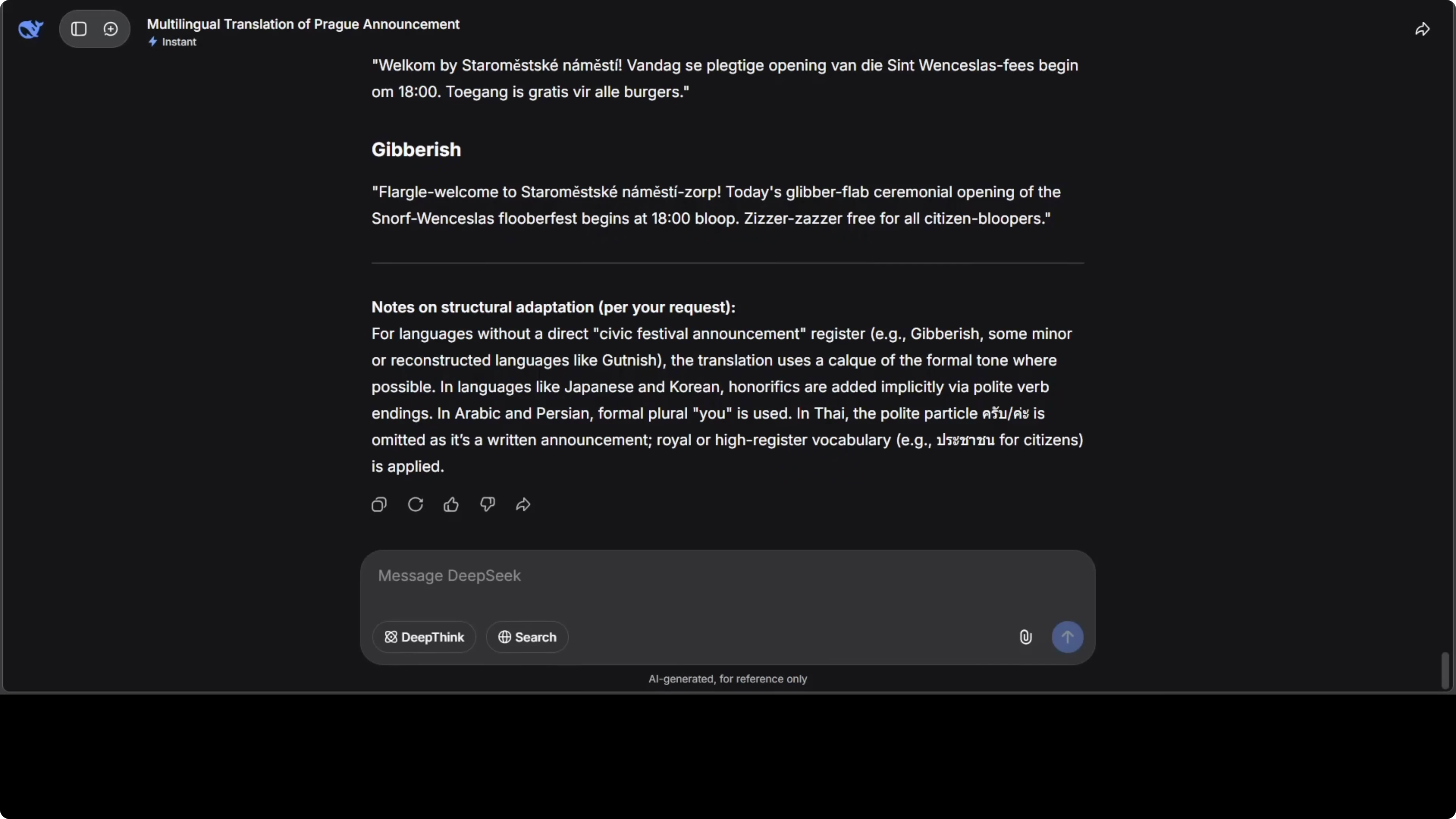
I asked for a multilingual translation of an official city announcement with formal tone and accurate diacritics. The source text started with this line: “Welcome to Old Town Square for today’s ceremonial opening of the Saint Wenceslas Festival.” I requested translations across a wide range of languages.
The model returned strong results across languages I can check directly. It kept proper form in Arabic and Persian and handled regional language variants from Africa and South Asia with care. It also flagged lines that needed local names preserved, which helped preserve formality.
Here is the style of prompt structure that worked.
Translate the following civic announcement into the listed languages.
Keep formal register, preserve named entities, and respect local punctuation norms.
Source:
"Welcome to Old Town Square for today’s ceremonial opening of the Saint Wenceslas Festival. The procession will begin at 10:00, followed by choral music at 11:30 and a community reception at 14:00 in the municipal hall."
Languages:
Czech, Slovak, Polish, German, French, Spanish, Italian, Portuguese, Arabic, Persian, Turkish, Hindi, Bengali, Tamil, Telugu, Kannada, Malayalam, Marathi, Gujarati, Punjabi, Urdu, Swahili, Amharic, Hausa, Zulu, Yoruba, Japanese, Korean, Mandarin Chinese, Cantonese, Vietnamese, Thai, Indonesian, Filipino, Ukrainian, Russian, Greek, Dutch, Swedish, Norwegian, Danish.
Output as labeled sections per language.Expert mode physics test
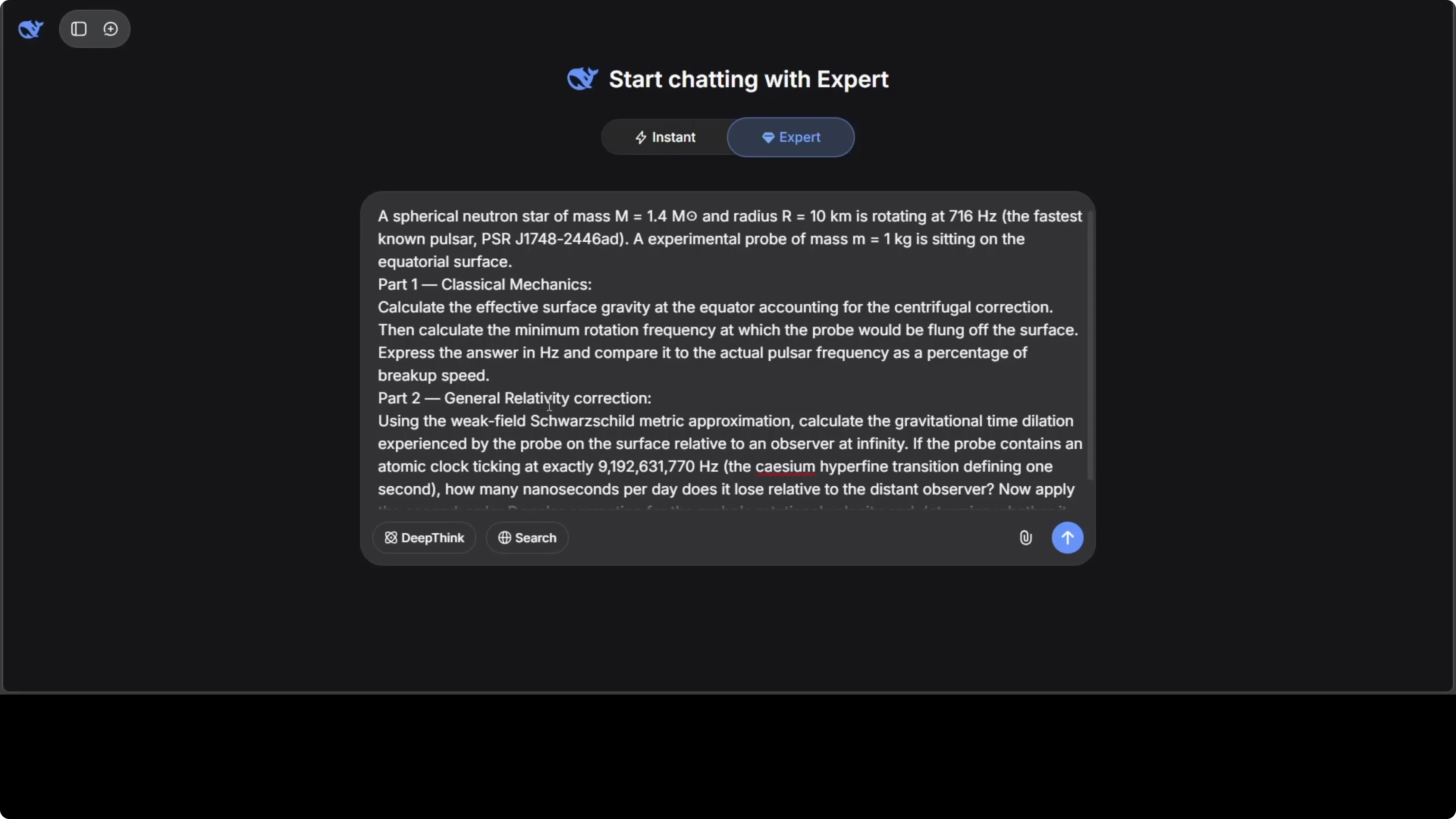
I ran an expert mode prompt with two parts. Part one covered classical mechanics and part two added a general relativity correction. The model produced a long derivation with equations and explained the physical meaning clearly.
It reached the correct final expressions and described the gravitational effects and breakup frequency details with precision. The treatment of the pulsar parameters and the correction order looked spot on. This scored a full mark for me in both correctness and clarity.
Here is a compact structure I used.
Problem:
A) Solve the classical mechanics system with the stated constraints and initial conditions.
B) Add the first-order general relativity correction and show its effect on the observable frequency.
Instructions:
- Derive step by step, justify approximations, and present final closed-form where possible.
- State units and constants, and verify dimensional consistency.
- Provide a concise physical interpretation of each term in the correction.CSA, HCA, MHC, optimizer, OPD, and FP4 Q80 explained
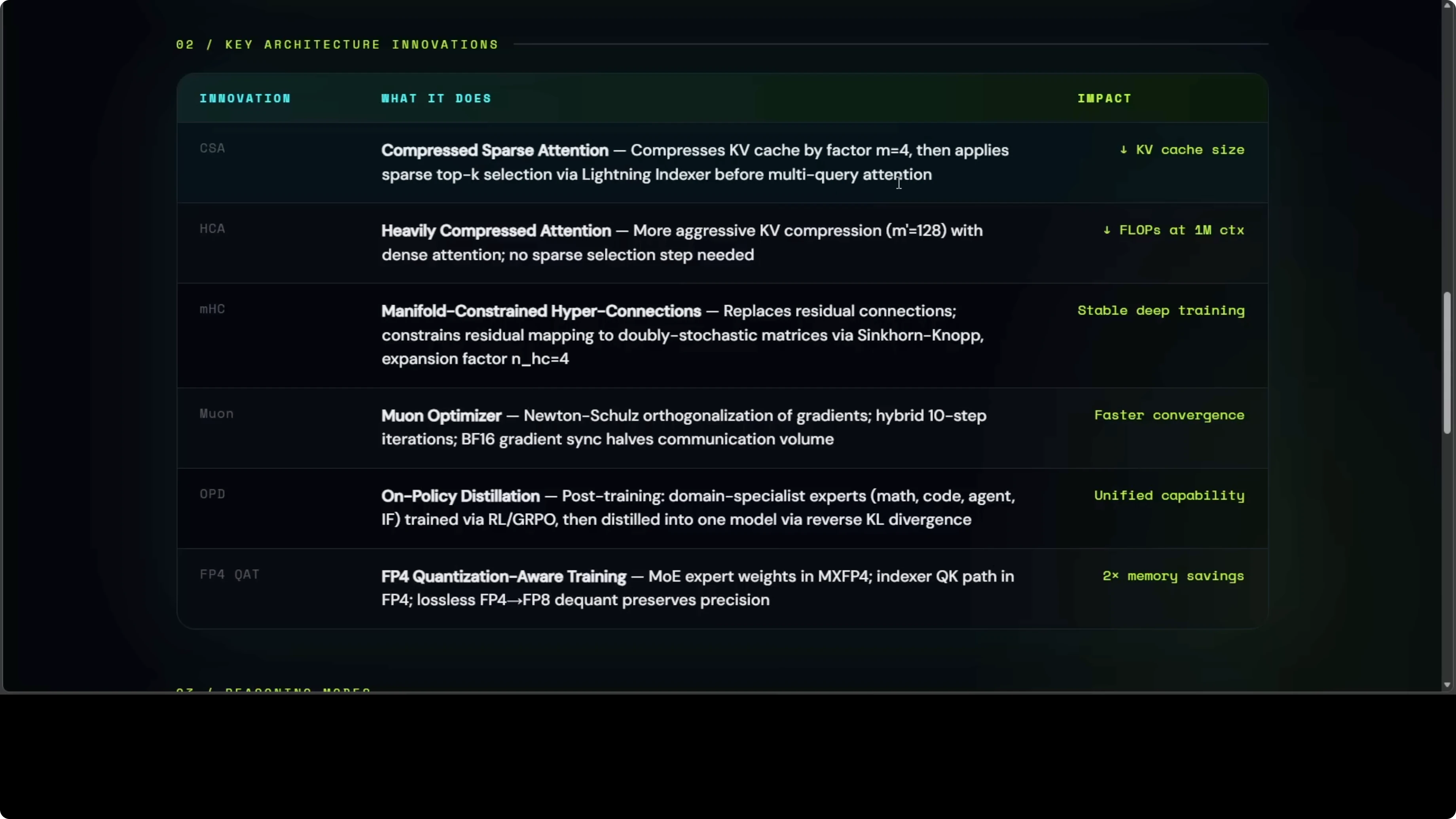
CSA means that instead of looking at every word in a million word book, the model squishes groups of words first, then reads only the most relevant squished chunks. HCA more aggressively squishes bigger groups of words into single summaries so the model barely has to read anything at long range. MHC means that rather than simply adding each layer output to the next like a stack of pancakes, it mixes them through a mathematically controlled blender.
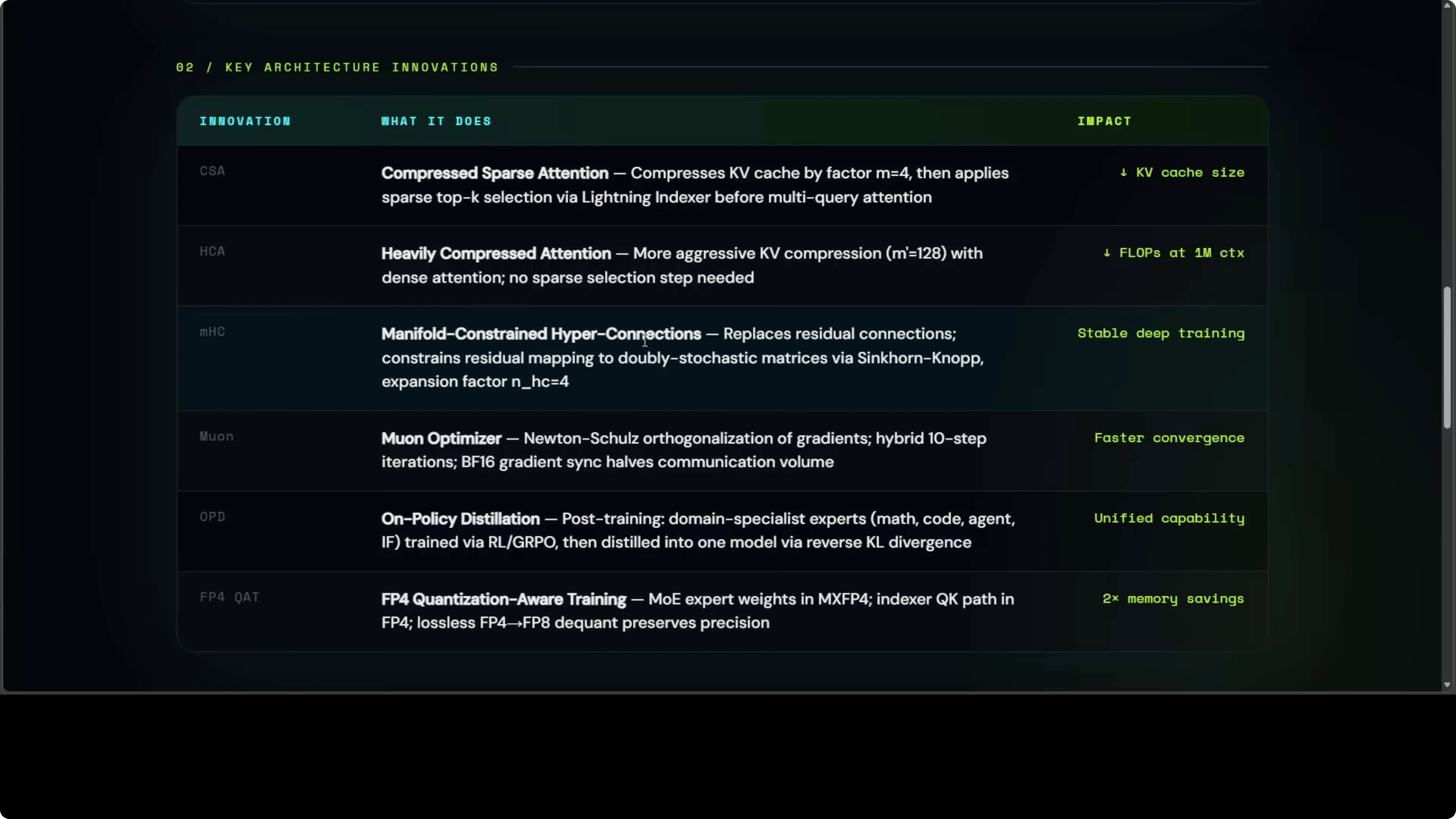
The Muon optimizer is a training optimizer that rotates gradients into more efficient updates. OPD trains separate specialist models for math, coding, and language, then distills their strengths into one model. FP4 Q80 stores model weights in a format so compressed it is basically a 4 bit number instead of 16 bit, with calibration that keeps quality high.
If you want to see how this plays out in practical agents and bug fixing flows, check this hands on walkthrough of a Telegram assistant powered by DeepSeek in this Hermes agent bug fixing guide.
Use cases that fit Why DeepSeek V4 Pro and Flash Redefine GPU Clusters?
Long codebases with multi file edits and refactors benefit from million token context. You can load entire repositories, reason across call graphs, and keep tests in context while proposing changes. Pair this with agentic tools and you can push end to end coding tasks through a single session.
Complex scheduling, routing, and allocation problems respond well to deliberate reasoning with Think high and Think max. The model can explain dead ends and propose minimal conflicting sets, which is essential for planners. Financial research that aggregates long reports and source tables sits well inside the compressed attention design.
Multilingual public communications, policy drafts, and regulator ready copy require tone control and consistent formatting across many languages. The translation test shows it can maintain formality and preserve entities. For deeper agent coding setups, see this guide on agentic coding with OpenClaw, and if you plan local experiments, you can run Flash locally with a simple workflow.
Final thoughts on Why DeepSeek V4 Pro and Flash Redefine GPU Clusters?
This release feels like a step change, with million token context and hybrid CSA and HCA making long range reasoning practical at a fraction of the cost. Flash delivers fast and cheap results, while Pro pushes depth and accuracy for hard problems. From real simulations to expert math and careful multilingual work, the results speak for themselves.
Subscribe to our newsletter
Get the latest updates and articles directly in your inbox.

Related Posts

8 Best Claude Code Plugins in 2026 (You Need to Know)
8 Best Claude Code Plugins in 2026 (You Need to Know)

7 Best Claude Code Skills (You Need to Know)
7 Best Claude Code Skills (You Need to Know)

Claude Code Desktop IDE Features (You Need to Know)
Claude Code Desktop IDE Features (You Need to Know)