
Table Of Content
- DeepSeek V4 Pro vs Claude Opus 4.7 vs Qwen3.6 Max: Which AI Leads? Methodology and Setup
- Coding Challenge: Full Working Finance Tracker
- What I asked them to build
- Commands and run targets
- Results overview
- DeepSeek V4 Pro: App outcome
- Claude Opus 4.7: App outcome
- Qwen 3.6 Max Preview: App outcome
- Verdict for the app build
- High Pressure Reasoning: Dhaka to Lisbon Survival Plan
- The constraint driven prompt
- DeepSeek V4 Pro: Survival plan
- Qwen 3.6 Max Preview: Survival plan
- Claude Opus 4.7: Survival plan
- Verdict for the survival test
- Features Breakdown: DeepSeek V4 Pro vs Claude Opus 4.7 vs Qwen3.6 Max: Which AI Leads?
- DeepSeek V4 Pro
- Claude Opus 4.7
- Qwen 3.6 Max Preview
- Pros and Cons: DeepSeek V4 Pro vs Claude Opus 4.7 vs Qwen3.6 Max: Which AI Leads?
- DeepSeek V4 Pro
- Claude Opus 4.7
- Qwen 3.6 Max Preview
- Use Cases and When Each Model Excels
- DeepSeek V4 Pro
- Claude Opus 4.7
- Qwen 3.6 Max Preview
- Final Conclusion: DeepSeek V4 Pro vs Claude Opus 4.7 vs Qwen3.6 Max: Which AI Leads?

DeepSeek V4 Pro vs Claude Opus 4.7 vs Qwen3.6 Max: Which AI Leads?
Qwen Model Recommender
Not sure which Qwen model fits your GPU? Pick your VRAM, use case, and task type — get matched to the right model instantly. Covers Qwen3, QwQ, QVQ, Qwen2.5-VL, Qwen3-Coder, Qwen3-TTS, and 80+ models.
Table Of Content
- DeepSeek V4 Pro vs Claude Opus 4.7 vs Qwen3.6 Max: Which AI Leads? Methodology and Setup
- Coding Challenge: Full Working Finance Tracker
- What I asked them to build
- Commands and run targets
- Results overview
- DeepSeek V4 Pro: App outcome
- Claude Opus 4.7: App outcome
- Qwen 3.6 Max Preview: App outcome
- Verdict for the app build
- High Pressure Reasoning: Dhaka to Lisbon Survival Plan
- The constraint driven prompt
- DeepSeek V4 Pro: Survival plan
- Qwen 3.6 Max Preview: Survival plan
- Claude Opus 4.7: Survival plan
- Verdict for the survival test
- Features Breakdown: DeepSeek V4 Pro vs Claude Opus 4.7 vs Qwen3.6 Max: Which AI Leads?
- DeepSeek V4 Pro
- Claude Opus 4.7
- Qwen 3.6 Max Preview
- Pros and Cons: DeepSeek V4 Pro vs Claude Opus 4.7 vs Qwen3.6 Max: Which AI Leads?
- DeepSeek V4 Pro
- Claude Opus 4.7
- Qwen 3.6 Max Preview
- Use Cases and When Each Model Excels
- DeepSeek V4 Pro
- Claude Opus 4.7
- Qwen 3.6 Max Preview
- Final Conclusion: DeepSeek V4 Pro vs Claude Opus 4.7 vs Qwen3.6 Max: Which AI Leads?
Three of the most powerful AI models on the planet were pushed at maximum reasoning effort on the same prompts. No cherry picking, no retries. The goal was hands on Claude versus DeepSeek versus Qwen, with equal conditions and real constraints.
I used Claude Opus 4.7 in adaptive mode, DeepSeek V4 Pro with DeepThink plus Expert Mode, and Qwen 3.6 Max Preview with thinking mode. Same prompt, same moment, no advantages. For broader context on Opus iterations and performance shifts, see this focused overview of feature changes in Opus 4.6.
| Category | DeepSeek V4 Pro | Claude Opus 4.7 | Qwen 3.6 Max Preview |
|---|---|---|---|
| Model posture | 1.6 trillion parameter open source you can download and run | Most capable general access model from Anthropic focused on professional work and software engineering | Alibaba’s next flagship still in preview |
| Reasoning mode used | DeepThink plus Expert Mode | Adaptive mode | Thinking mode |
| App build test | Built a complete finance tracker with auth, CRUD, charts | Built a complete finance tracker with polished charts and clean flows | Built a complete finance tracker with solid CRUD and metrics |
| App UX notes | Nuanced graphs, minor UI lag in category dropdown | Best charts and quick packaging to download all files at once | Needed to add transactions from a dedicated form, graphs OK |
| Packaging convenience | Manual file copy from hosted view | All files downloadable in one go | Manual file copy from hosted view |
| Coding benchmark note | Codeforces rating 3206 that outpaces most competitive programmers | Strongest on real world software delivery among Anthropic’s public models | Leading on agentic coding across six major benchmarks in internal and public tests |
| Survival plan test | Clean, specific addresses and phone numbers, Bengali phrases, Western Union test question trick, slightly lighter on contingencies | Most honest about ETD timing, creative Delhi detour, strong family contact tactic, but too verbose and analysis heavy | Most operationally tight, starts with battery triage, correct EU directive citation, EU Delegation fallback, consular guarantee letter and repatriation ticket tactic |
| Tool use in tests | Web search enabled | Web search enabled | Web search enabled |
| Interface note | Hosted build worked as expected | Fast file bundling for app export | Needed a redo because the interface auto switched to an older model |
| Overall snapshot | Close second in both tasks, very actionable outputs | Slight edge on the app build with the cleanest packaging | Edge on the survival test with tight, actionable sequencing |
DeepSeek V4 Pro vs Claude Opus 4.7 vs Qwen3.6 Max: Which AI Leads? Methodology and Setup
All three models ran at maximum reasoning effort on identical prompts. Web search and tools were enabled for the decision making test. I ran hosted versions to keep environments consistent.
The app prompt was a real world application request, not a toy snippet. Each model produced a working application that I installed and ran locally. For a step by step view of how Opus families differ across releases, see this side by side comparison of Opus 4.6 vs 4.5.
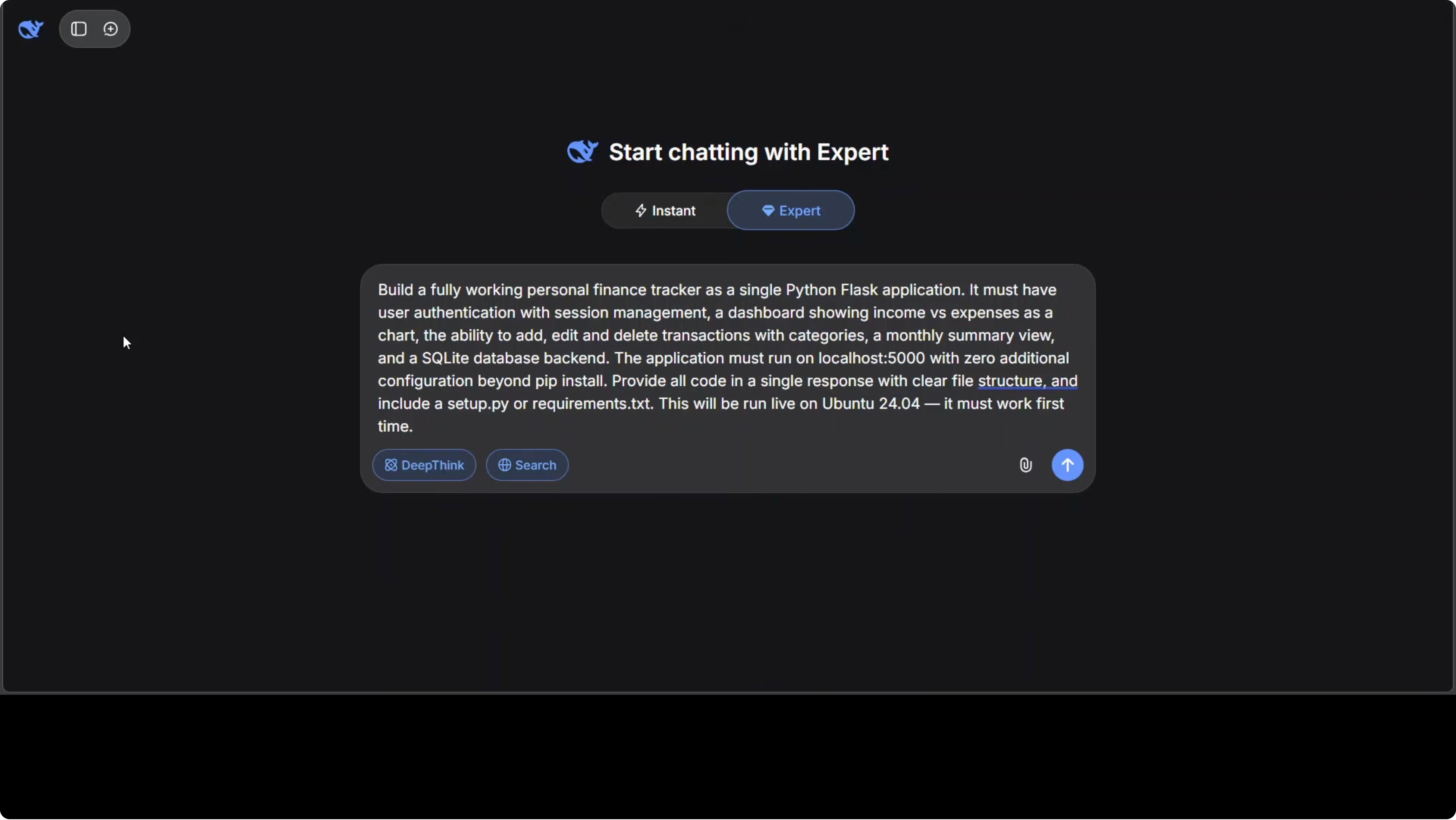
Coding Challenge: Full Working Finance Tracker
What I asked them to build
A complete working app with registration, login, a dashboard, transactions, a monthly summary, and full CRUD. I did not ask for a toy script or a partial code sample. The goal was install, run, and verify.
Commands and run targets
I used virtual environments and installed the requirements exactly as instructed by each model. Each app launched locally on port 5000.
python app.pyOnce running, I verified registration, login, CRUD on transactions, category selection, date pickers, charts, and logout for each app.
Results overview
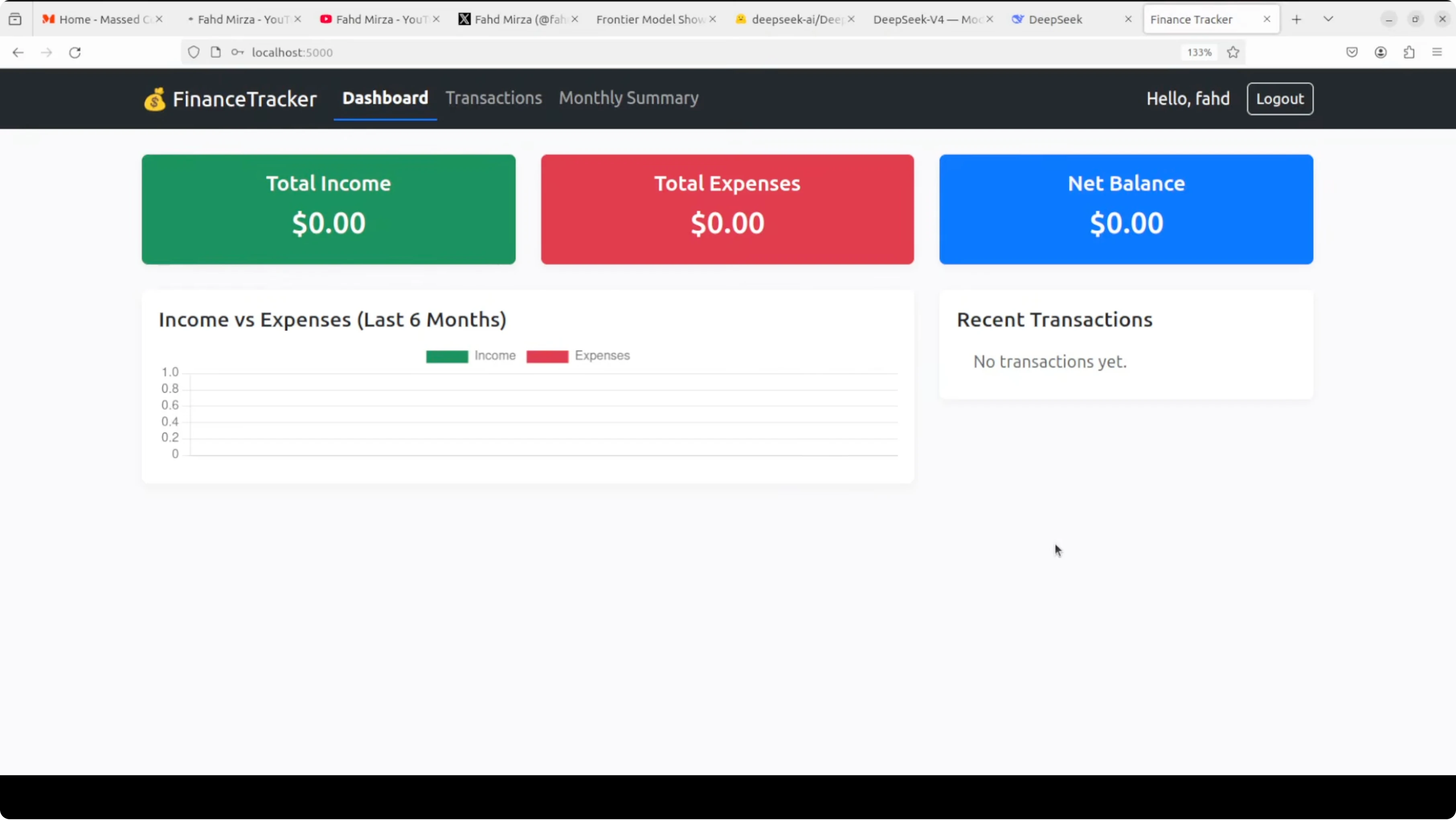
All three apps installed cleanly and launched without errors. Instruction following was good across the board. CRUD operations worked in each app and charts rendered.
DeepSeek V4 Pro: App outcome
The app looked solid with nuanced charts. There was a minor delay before the category dropdown appeared during entry and edit. Everything else in flows checked out as expected.
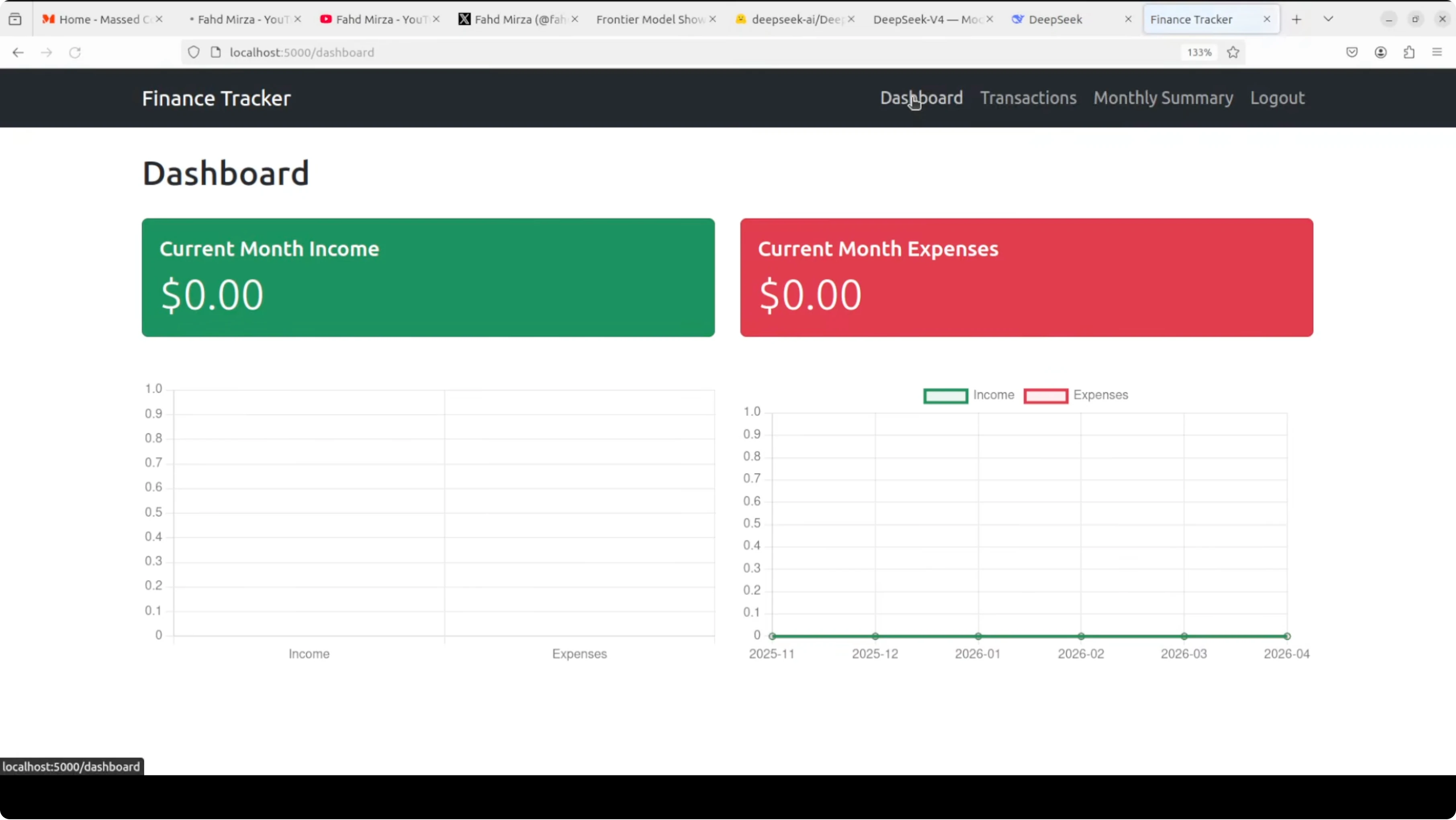
Claude Opus 4.7: App outcome
This build had the cleanest charts and the most polished flows. A practical perk was the ability to download all files in one go for quick local setup. The application was created in a single pass and worked on first run.
Qwen 3.6 Max Preview: App outcome
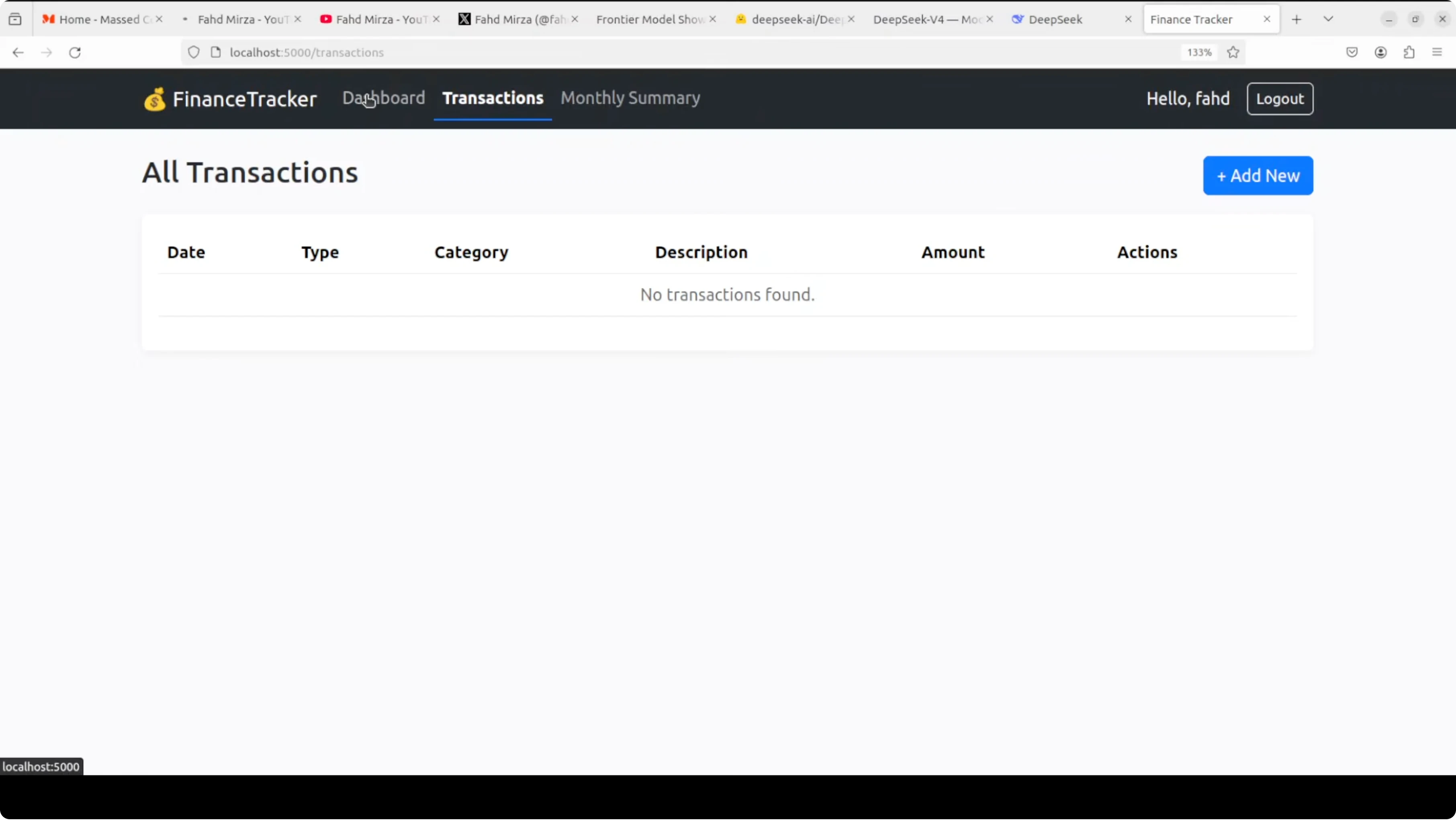
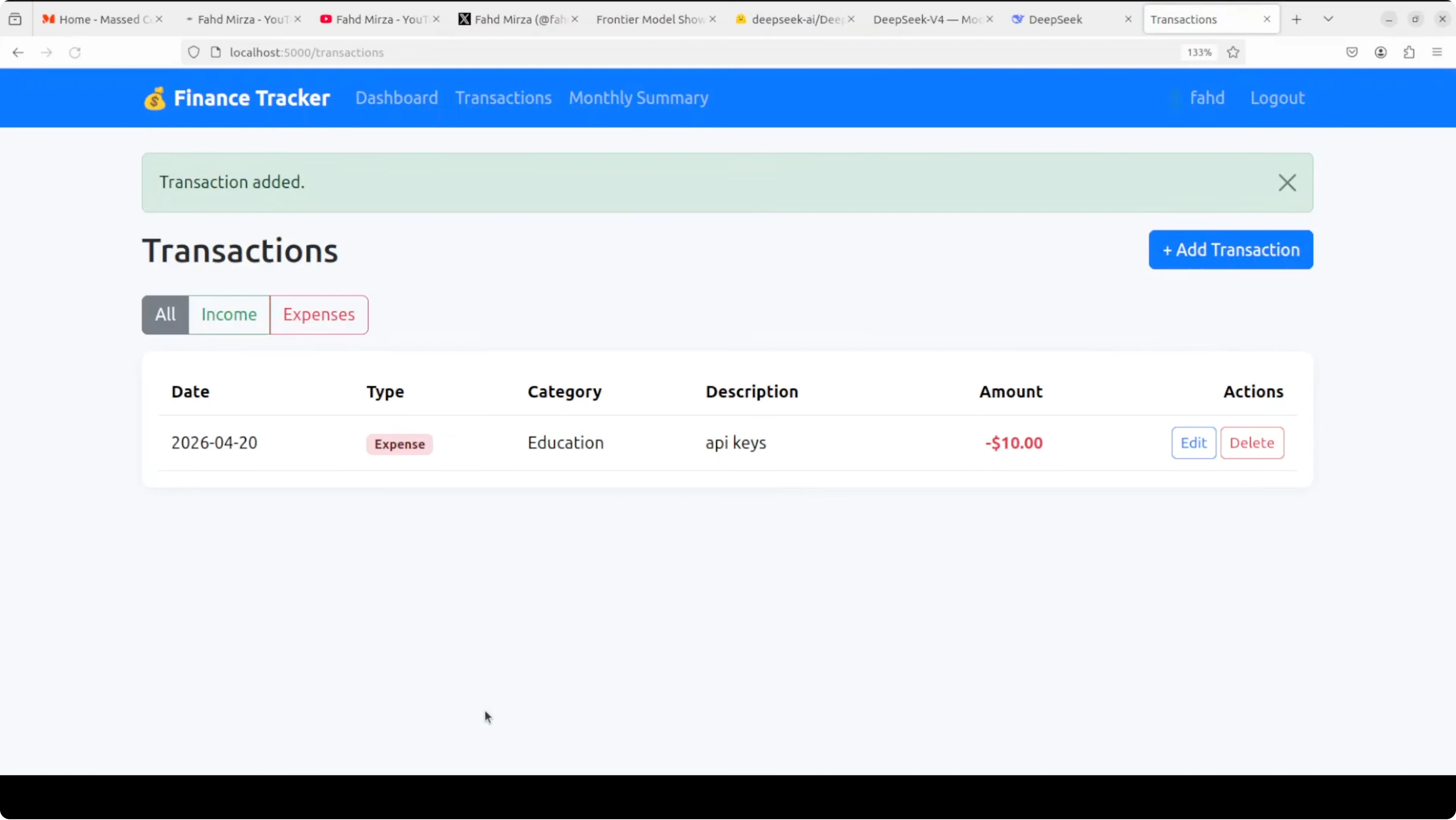
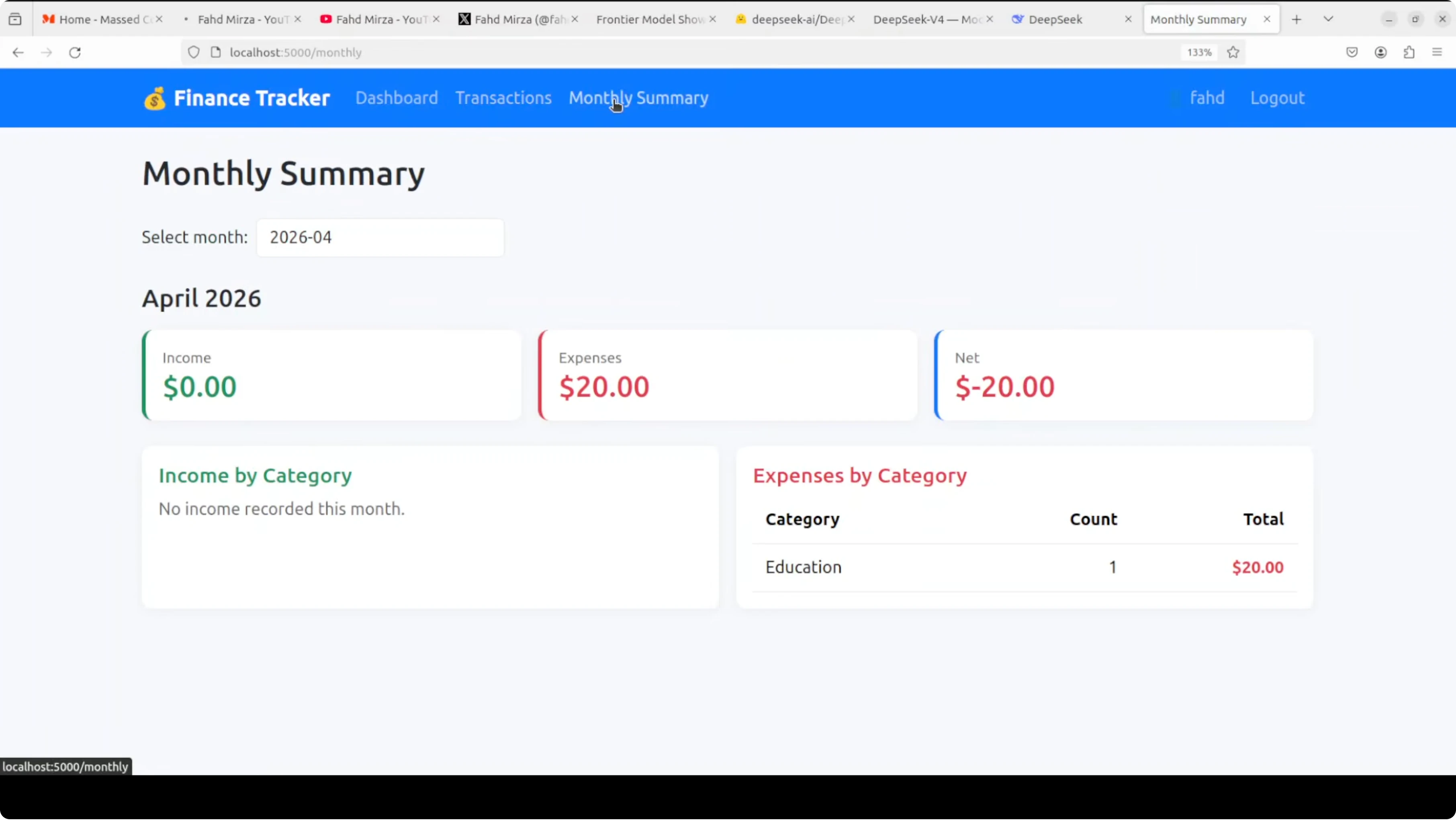
The app required using a dedicated form for adding new transactions instead of adding from the home dashboard. Graphs and net balance views were fine. CRUD worked and confirmations appeared as expected.
Verdict for the app build
In my view, Claude had a slight edge over DeepSeek, which in turn held a slight edge over Qwen. It is neck and neck, and with richer context the gap might disappear. For prior head to head notes on DeepSeek vs Opus families, see this earlier comparison of DeepSeek V3.2 vs Opus 4.5.
High Pressure Reasoning: Dhaka to Lisbon Survival Plan
The constraint driven prompt
You are stranded in Dhaka at 11 pm with 3 percent battery and no charger. You have no cash, bank cards are blocked, passport is lost, no local contacts, and you do not speak Bengali. You must reach Lisbon within 48 hours with specific locations, phone numbers, embassy addresses, costs, and concrete contingencies for each possible failure.
Tools and web search were enabled for every model. This was designed to test planning under genuine pressure with verifiable details. I evaluated each response for actionability, specificity, and operational sequence.
DeepSeek V4 Pro: Survival plan
The response was clean, well structured, and genuinely actionable with specific addresses and phone numbers. It even included Bengali phrases that could help at a police station and a Western Union test question trick for receiving funds without ID. It had slightly less depth on contingencies, but nothing was wasted.
Qwen 3.6 Max Preview: Survival plan
I had to redo the test because the interface initially switched to an older model on a new chat. The final run was comprehensive and the most operationally tight, starting with step zero battery triage which fits the scenario. It cited the correct EU directive for emergency travel and introduced the EU Delegation fallback, a consular guarantee letter to an airline, and a repatriation ticket concept that shows strong practical knowledge.
Claude Opus 4.7: Survival plan
Reasoning quality was excellent and it was the most honest about the seven working day ETD reality. It suggested a New Delhi detour and the idea of a family member calling the global emergency center in Portuguese from Portugal which is psychologically and practically sharp. It was the longest and at points uncertain, reading more like analysis than survival instructions.
Verdict for the survival test
Qwen edged this round with the tightest, most actionable sequence. DeepSeek’s response was highly usable and specific with a few smart field tricks. Claude was insightful and candid on policy timing but verbose for a time critical path. For a deeper look at Opus traits and behavior patterns across tasks, explore this focused Opus 4.6 breakdown.
Features Breakdown: DeepSeek V4 Pro vs Claude Opus 4.7 vs Qwen3.6 Max: Which AI Leads?
DeepSeek V4 Pro
- 1.6 trillion parameter open source model you can download and run yourself.
- Strong coding performance with a Codeforces rating of 3206.
- Hosted outputs required manual file copy and assembly for local runs.
Claude Opus 4.7
- Most capable general access model from Anthropic for professional work.
- Clean packaging that lets you download all files at once for quick setup.
- Strong software engineering outputs with polished structure and charts.
Qwen 3.6 Max Preview
- Alibaba’s next flagship already strong at agentic coding.
- Operationally tight planning under pressure with correct legal hooks.
- Interface needed attention since it auto switched to an older model once.
Pros and Cons: DeepSeek V4 Pro vs Claude Opus 4.7 vs Qwen3.6 Max: Which AI Leads?
DeepSeek V4 Pro
Pros
- Highly actionable outputs with specific locations and phone numbers.
- Smart tricks like a Western Union test question and Bengali phrases for field use.
- Strong coding ability backed by competitive programming metrics.
Cons
- Slightly lighter on contingency depth in crisis planning.
- Minor UI lag noticed in the app’s category dropdown.
- Manual export steps from hosted outputs took extra time.
Claude Opus 4.7
Pros
- Best charts and cleanest packaging for the app build.
- Honest about document timing and embassy realities.
- Strong structure and readability for professional tasks.
Cons
- Verbose in high pressure planning and sometimes uncertain in steps.
- Can read like analysis rather than concise instructions in a crunch.
- Did not surface some of the airline coordination tactics used by Qwen.
Qwen 3.6 Max Preview
Pros
- Most operationally tight survival plan with step zero battery triage.
- Accurate EU directive reference and EU Delegation fallback.
- Airline coordination via consular guarantee letter and repatriation ticket concept.
Cons
- Interface defaulted to an older model on a new chat and needed a redo.
- App build UX paths were less direct for quick add from the dashboard.
- Charts were acceptable but not as polished as Claude’s.
Use Cases and When Each Model Excels
DeepSeek V4 Pro
Pick it for local runs, research, and heavy coding where you want to own the stack. It is a strong choice for agent workflows that require explicit addresses, numbers, and scripts that people can act on. It is also well suited to code heavy sprints with verifiable outputs.
Claude Opus 4.7
Choose it for professional software projects, structured documents, and deliverables where polish matters. It is especially good when you want clean packaging and a working build in one pass. Use it for client ready artifacts and readable plans.
Qwen 3.6 Max Preview
Use it for crisis planning, travel logistics, and agent tasks that demand legally accurate steps and lean sequencing. It can set up correct contacts and fallbacks with minimal fluff. Reach for it when action speed and tight instructions matter more than prose.
Read More: Opus 4.6 support details and usage notes
Final Conclusion: DeepSeek V4 Pro vs Claude Opus 4.7 vs Qwen3.6 Max: Which AI Leads?
For the app build, Claude holds a slight edge with the cleanest charts and the easiest packaging. DeepSeek finished very close with nuanced outputs and strong coding chops, followed by Qwen with a solid but slightly less polished UX. All three produced working apps in one pass.
For the high pressure survival plan, Qwen led with the most operationally tight and legally accurate sequence. DeepSeek’s plan was highly actionable and specific, while Claude offered candid policy timing and creative detours but ran long for a time boxed scenario. Across both tests, differences were small and context could erase them.
If you want refined build quality and readable artifacts, pick Claude. If you want self hosting and strong code under your control, pick DeepSeek. If you want crisis ready plans and tight execution steps, pick Qwen.
Subscribe to our newsletter
Get the latest updates and articles directly in your inbox.

Related Posts

8 Best Claude Code Plugins in 2026 (You Need to Know)
8 Best Claude Code Plugins in 2026 (You Need to Know)

7 Best Claude Code Skills (You Need to Know)
7 Best Claude Code Skills (You Need to Know)

Claude Code Desktop IDE Features (You Need to Know)
Claude Code Desktop IDE Features (You Need to Know)