

Deepseek Engram Explained: Conditional Memory via Scalable Lookup
Deepseek has released Engram, which adds a tiny built-in memory to a transformer so the model can fetch short repeatable phrases instead of rebuilding them in its early layers every time. I unpack Engram in very simple words without expecting you to be a machine learning engineer.
Think of repeated bits like names or stock expressions. Classic transformers keep recomputing those. Engram adds a constant time lookup that returns a ready-made vector or numerical representation for the short phrase and blends it into the model state. This idea complements mixture of expert which adds conditional compute. Engram adds conditional memory which is fast lookups for stable patterns. They also designed it so that the big memory tables can live in host RAM and be prefetched, keeping GPU overhead as small as possible.
Deepseek Engram Explained: Conditional Memory via Scalable Lookup
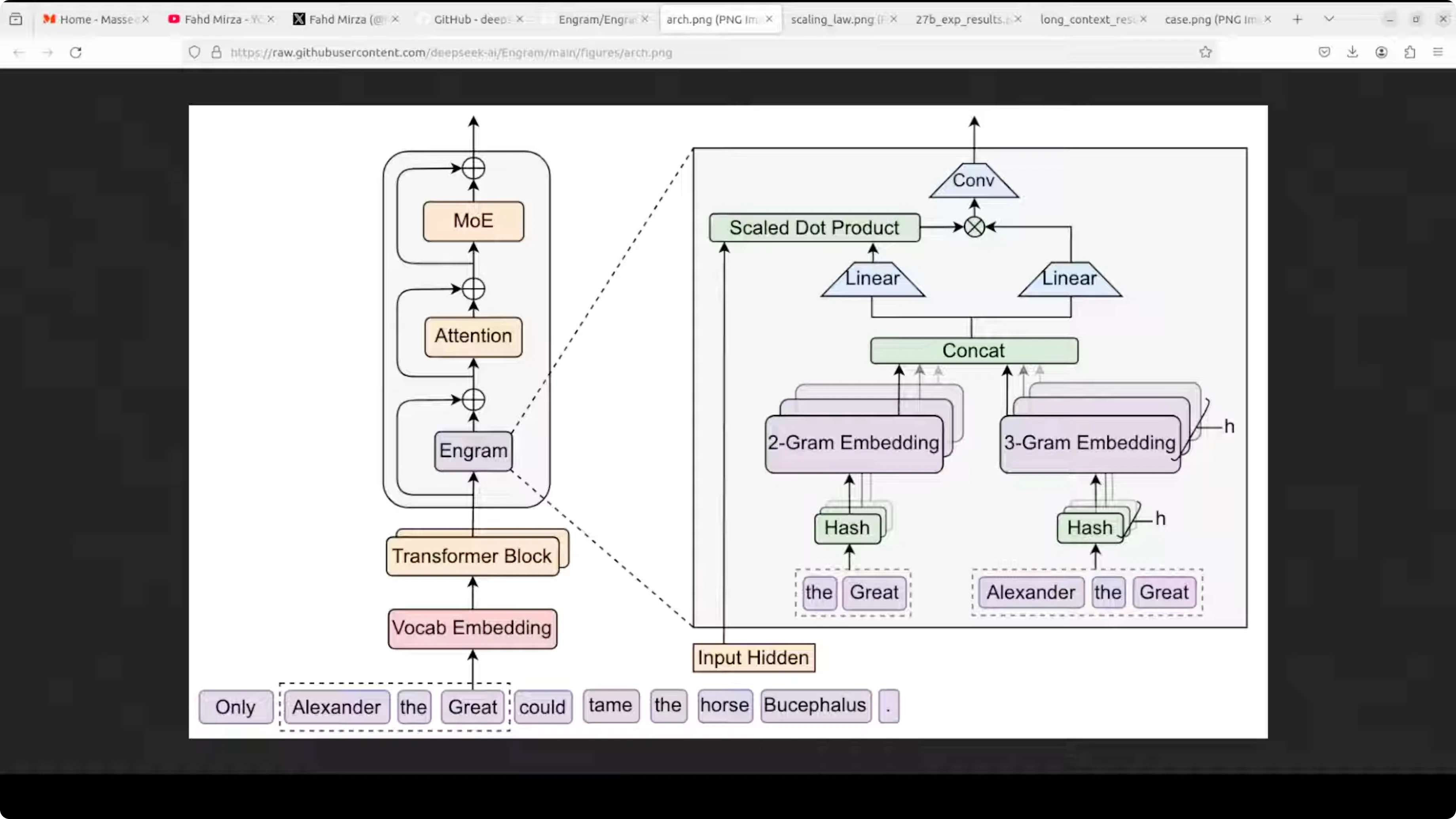
How Engram works
- Text is split into tokens, little pieces, words or subwords.
- At each step, Engram looks at the last two or three tokens you just read and that tiny window is Engram.
- It runs that window through a few small hash functions to get table positions.
- It pulls the corresponding vectors from those positions and then stitches them together into one memory vector.
- A small gate decides how much of that memory to keep. If the memory fits the current context, the gate opens. If it does not, the gate stays small and the memory is ignored.
- The gated memory is added back to the model's running representation, so the network can move on without wasting layers rebuilding the same phrase.
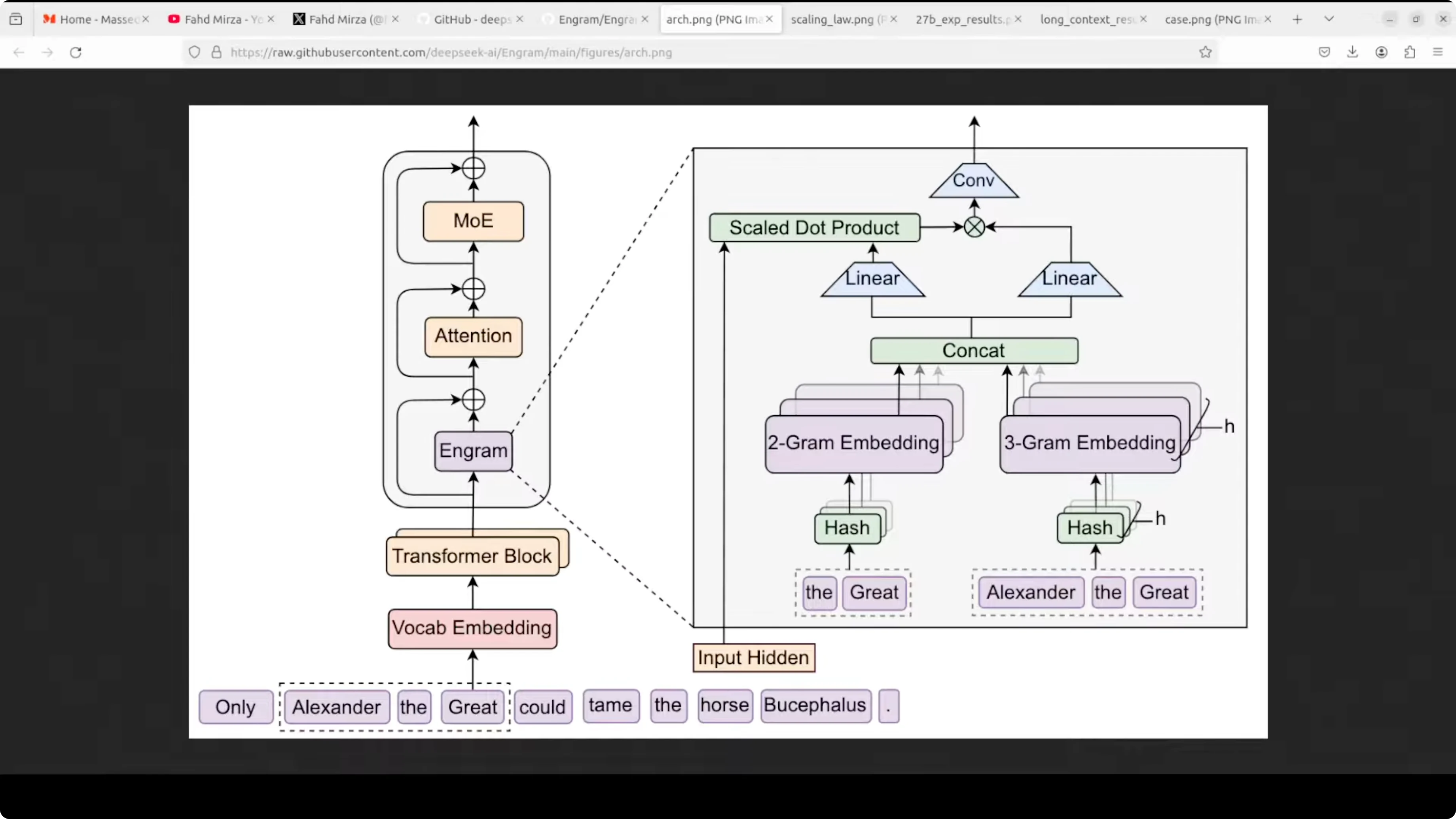
Placement and prefetching
- Engram modules are only placed in a few layers, often early and mid, which is enough to offload the repetitive stuff.
- Because the table addresses depend only on the input tokens, the system knows in advance which rows it will need and can prefetch them from CPU memory while the GPU is busy with prior layers.
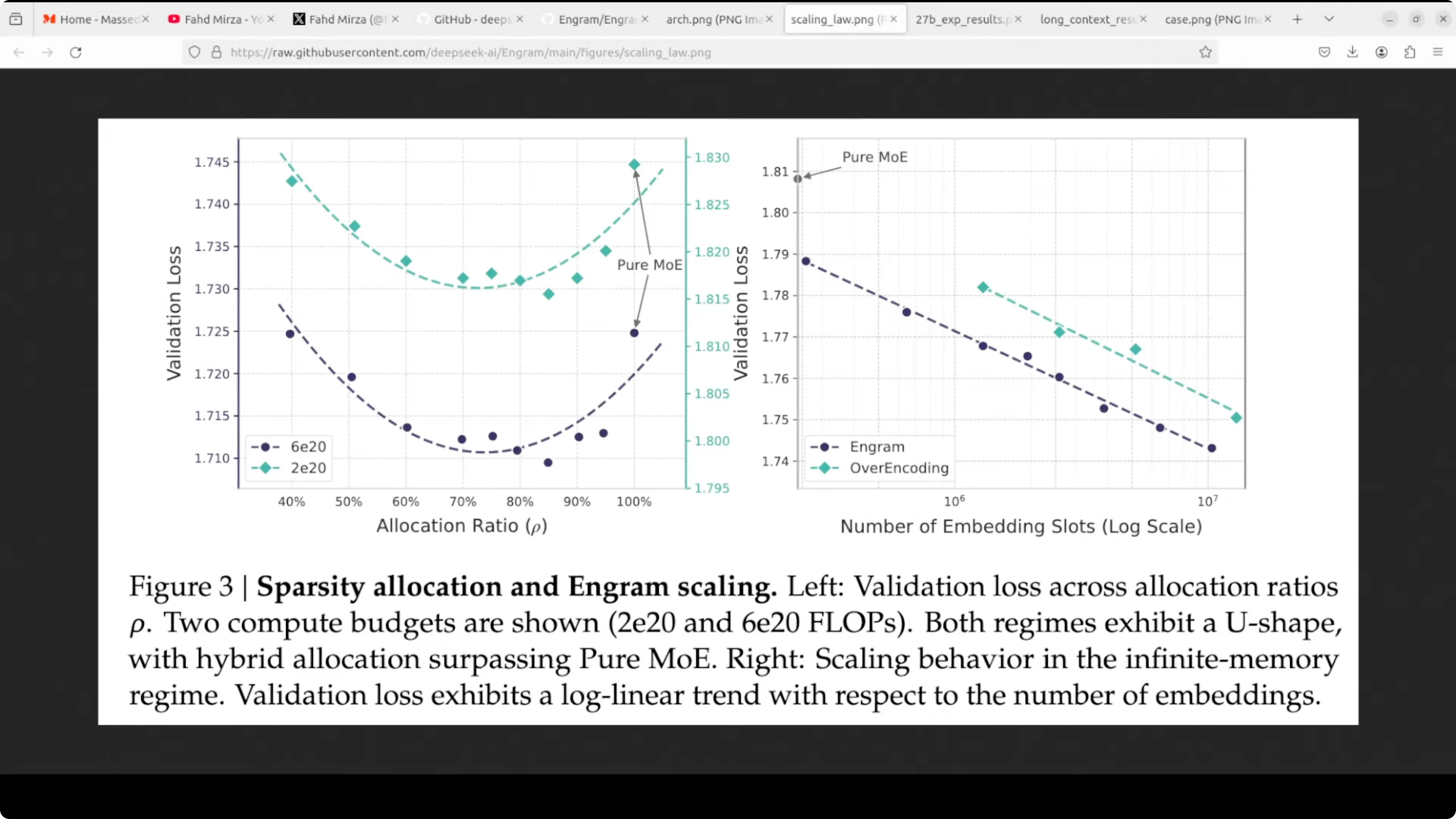
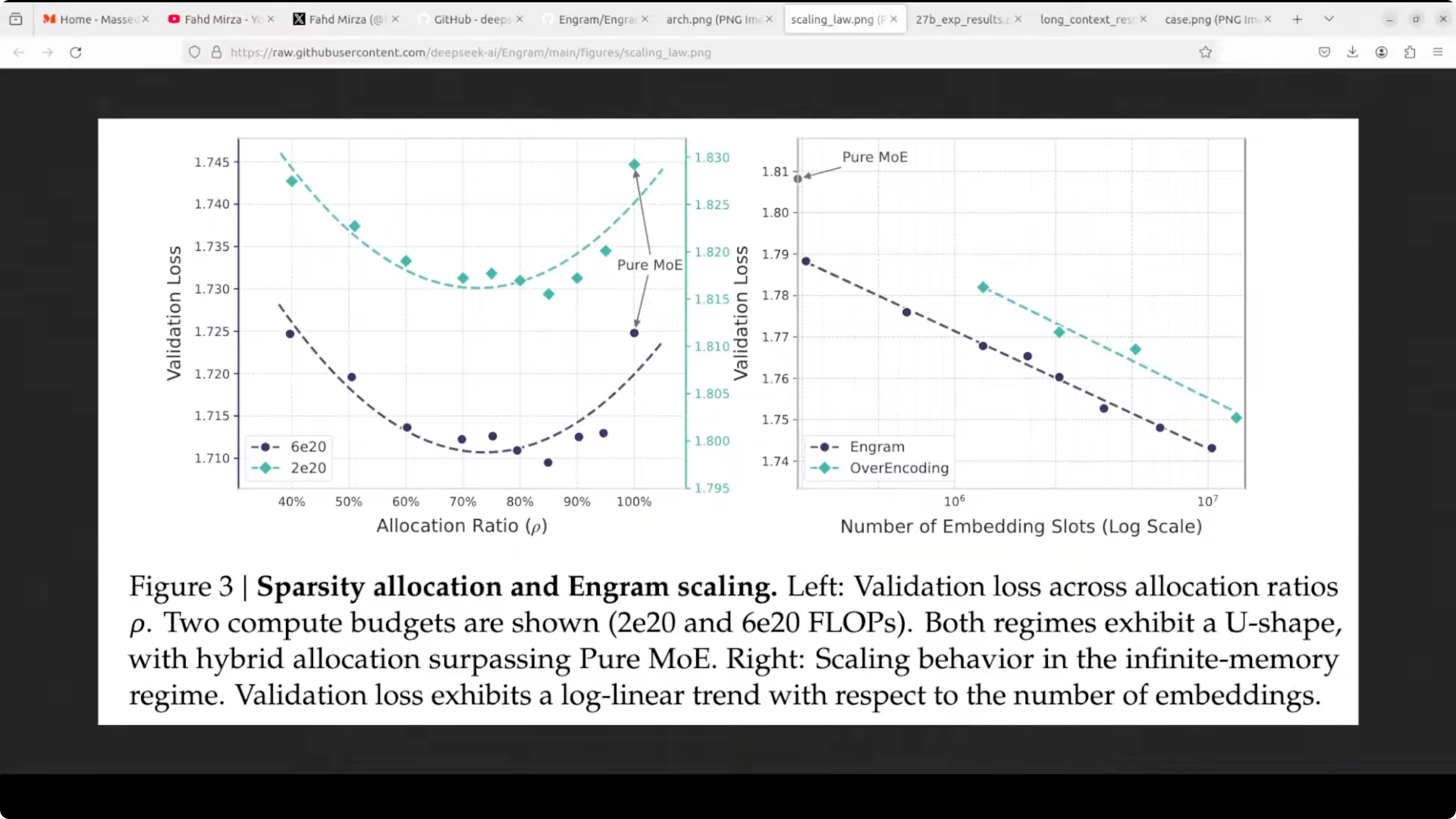
Why this helps
- Early layers stop repeating themselves and later layers get more headroom for reasoning.
- Attention has more room to focus on long range context because the short local patterns are handled by quick lookups.
- In their comparison, which they also have shared in the paper, this combination improves factual recall and multi-step reasoning and it plays nicely with mixture of expert rather than replacing it.
- Mixture of expert brings compute specialist, Engram brings memory lookups.
Demo: What I ran and what it shows
Environment
- Ubuntu
- Nvidia RTX 6000 with 48 GB of VRAM
- Created a virtual environment, cloned the repo, installed Torch, and installed the demo dependencies
What the demo script builds
- A tiny mock transformer with Engram turned on at two layers
- Tokenizes the example sentence and for each position takes the last two or three tokens
- Hashes them to get addresses into big lookup tables
- Fetches the corresponding memory vectors
- Uses a simple gate which compares the hidden state to the fetched vector to decide how much of that memory to keep
- Mixes the gated memory back into the model's hidden state with a small convolution
- Skips real attention which is primarily mocked here
- Runs a full forward pass and prints the run along with some tensor shapes
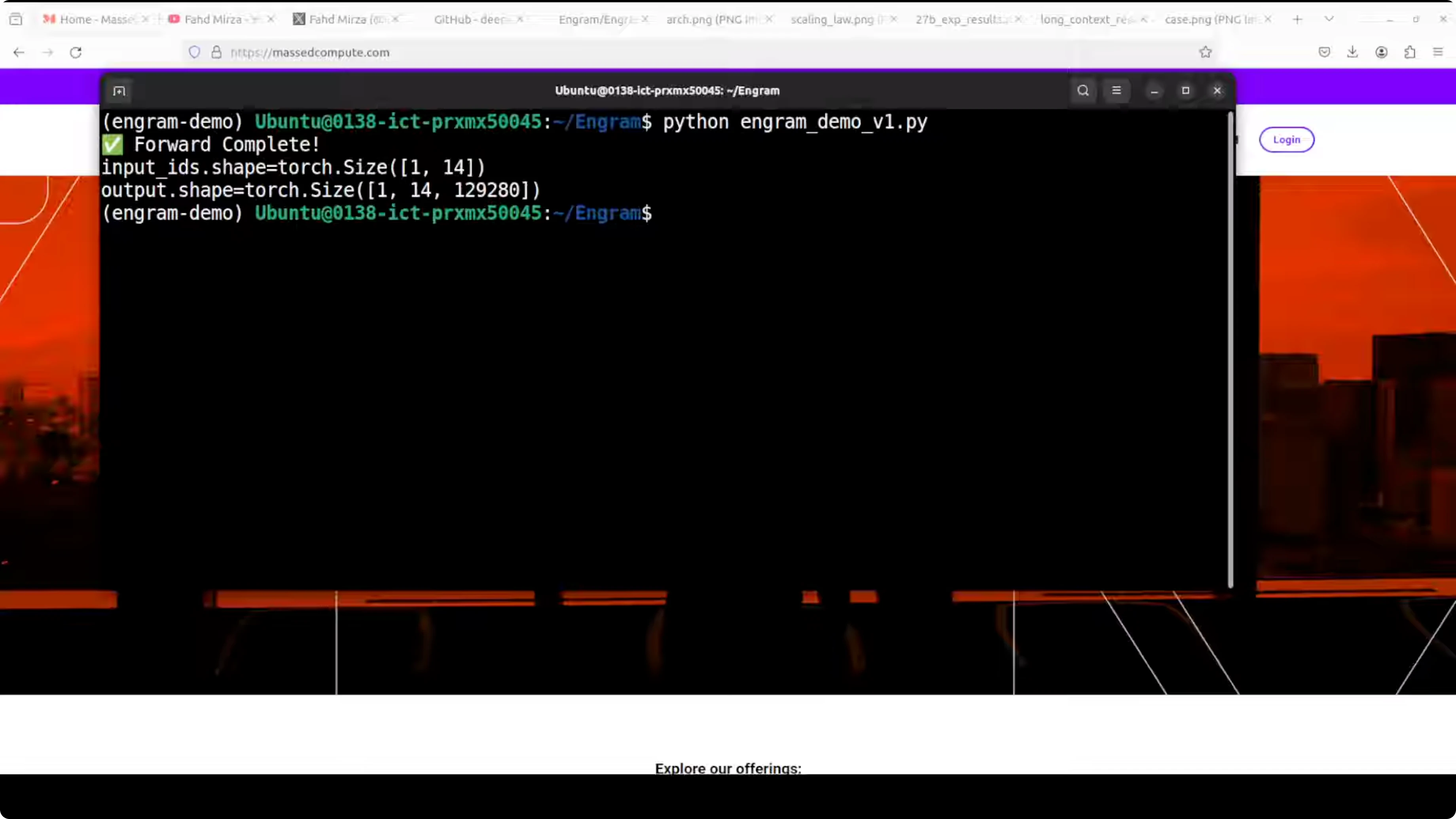
What the output shows
- Forward complete means the mock transformer with Engram ran a full forward pass without any errors.
- The first input ID is 1. This means the input was one sentence that became 14 tokens after tokenization.
- The output shape shows that for each of the 14 token positions, the model produced a score over 129,280 vocabulary tokens, or in other words, 14 sets of next token predictions across the whole vocabulary.
Final thoughts
Engram surely hints at a future where models carry built-in fast memory, wasting less compute on repeats and unlocking more room for deeper reasoning, longer context, and easier updates. As the architecture grows, combining conditional memory like Engram with conditional compute like mixture of expert can make future models faster, cheaper, and more reliable, scaling not just by size but by smarter use of memory and compute. I think really good stuff is ahead, and that means a lot of democratization of these models for end users.
Subscribe to our newsletter
Get the latest updates and articles directly in your inbox.

Related Posts

8 Best Claude Code Plugins in 2026 (You Need to Know)
8 Best Claude Code Plugins in 2026 (You Need to Know)

7 Best Claude Code Skills (You Need to Know)
7 Best Claude Code Skills (You Need to Know)

Claude Code Desktop IDE Features (You Need to Know)
Claude Code Desktop IDE Features (You Need to Know)