
Table Of Content

DeepSeek V3.2 vs GPT-5.1 Codex MAX vs Opus 4.5
Table Of Content
I previously compared DeepSeek v3.2 and Claude Opus 4.5 across two tests: writing a PRD and then building a space dashboard app from that PRD. Opus came out on top, and the version it built looked professional, nailed the brief, and only had one or two minor bugs. A viewer suggested testing DeepSeek again using the full Opus PRD instead of its own shorter one.
That made sense, so I gave DeepSeek another chance using the full Opus PRD. I also added a third model to the mix, GPT-5.1 Codex Max. Both DeepSeek and Codex received the exact same PRD, and I compared their builds against the Opus reference.
DeepSeek V3.2 vs GPT-5.1 Codex MAX vs Opus 4.5 - context
In the first test, DeepSeek produced a very brief PRD with limited detail. Opus delivered a complete, production-ready PRD. That could be a big reason Opus performed better on the build.I wanted to see if a richer PRD would help DeepSeek build a better space dashboard. I also wanted to see how GPT-5.1 Codex Max handled the same brief. For a focused writing-tool comparison between Opus and GPT-5.1 in another domain, see this direct head-to-head on writing tasks.
DeepSeek V3.2 vs GPT-5.1 Codex MAX vs Opus 4.5 - PRD we used
The Opus PRD I used here was detailed. It included an executive summary, problem statement, goals and objectives, and target user information.It specified feature requirements, architecture design, UI and UX requirements, and technical specifications. It listed all required API endpoints and a recommended tech stack. Both models used the same stack: React 18 with TypeScript.
It also included a development roadmap that broke the project into tasks. It covered risks and mitigations, future considerations, and an appendix. In short, a complete PRD built for production.
For context on how a newer Codex model compares against Opus in a broader sense, check this Codex vs Opus analysis.
DeepSeek V3.2 vs GPT-5.1 Codex MAX vs Opus 4.5 - setup
I worked in Cursor with a split-screen setup. On the left, I connected a client to the DeepSeek v3.2 API. On the right, I used the Codex extension with GPT-5.1 Codex Max and set reasoning to extra high.
I pasted the full Opus PRD into both workspaces. I let each model handle the build process. I then ran both dashboards in dev mode for testing.
Build times and stability
Both models completed the build. Codex finished in 18 minutes.
DeepSeek took about 40 minutes and got stuck a few times. I had to cancel and prompt it to continue with the task.
I am not sure if that was an API connection issue or a client issue. It did not happen in the first DeepSeek test. Either way, it took longer to complete the build this time.
If you care about throughput and operating costs on newer variants, see these notes on speed, cost, and quality for GPT-5.2 vs Opus 4.5.
DeepSeek V3.2 vs GPT-5.1 Codex MAX vs Opus 4.5 - DeepSeek v3.2 results
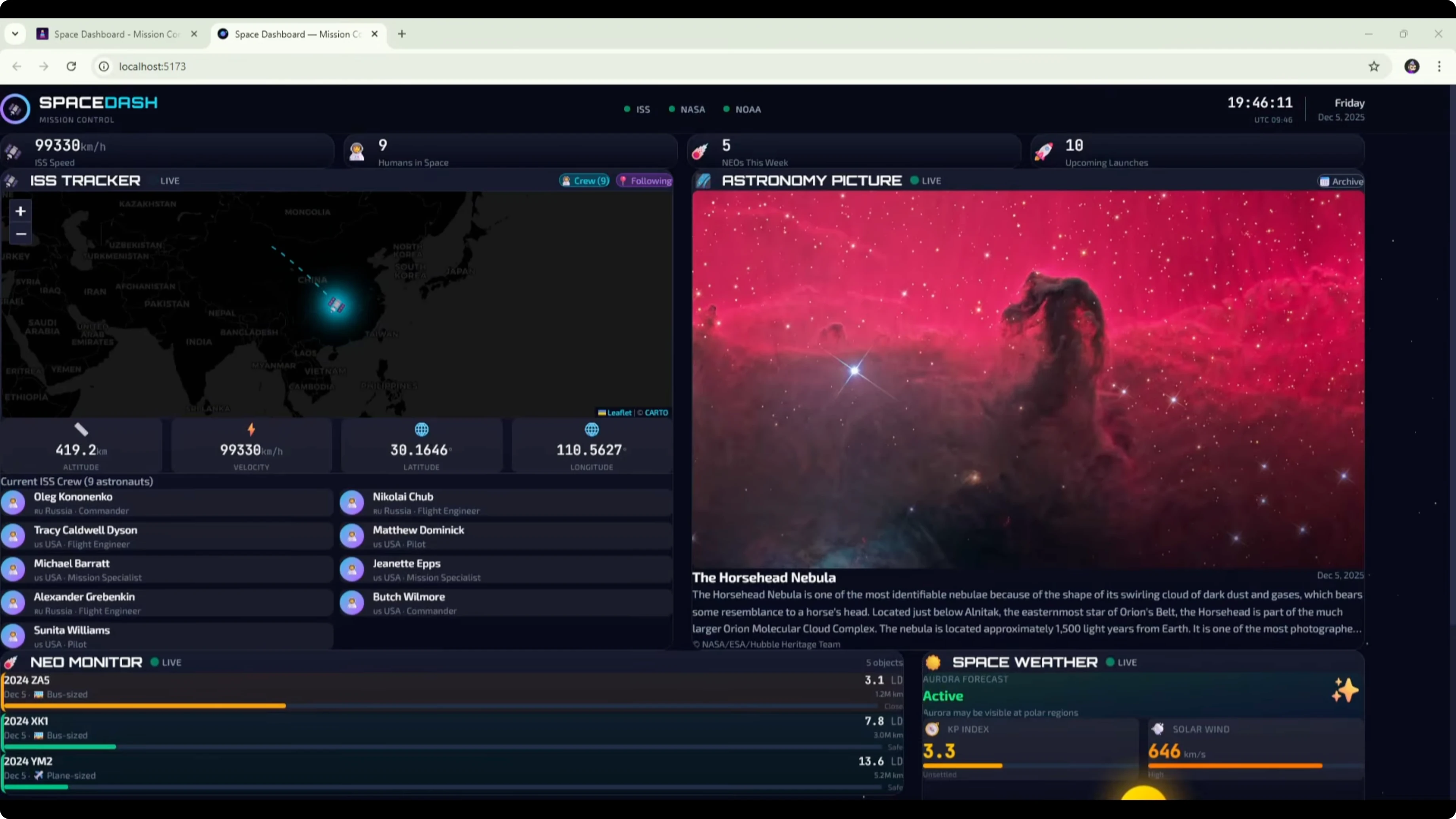
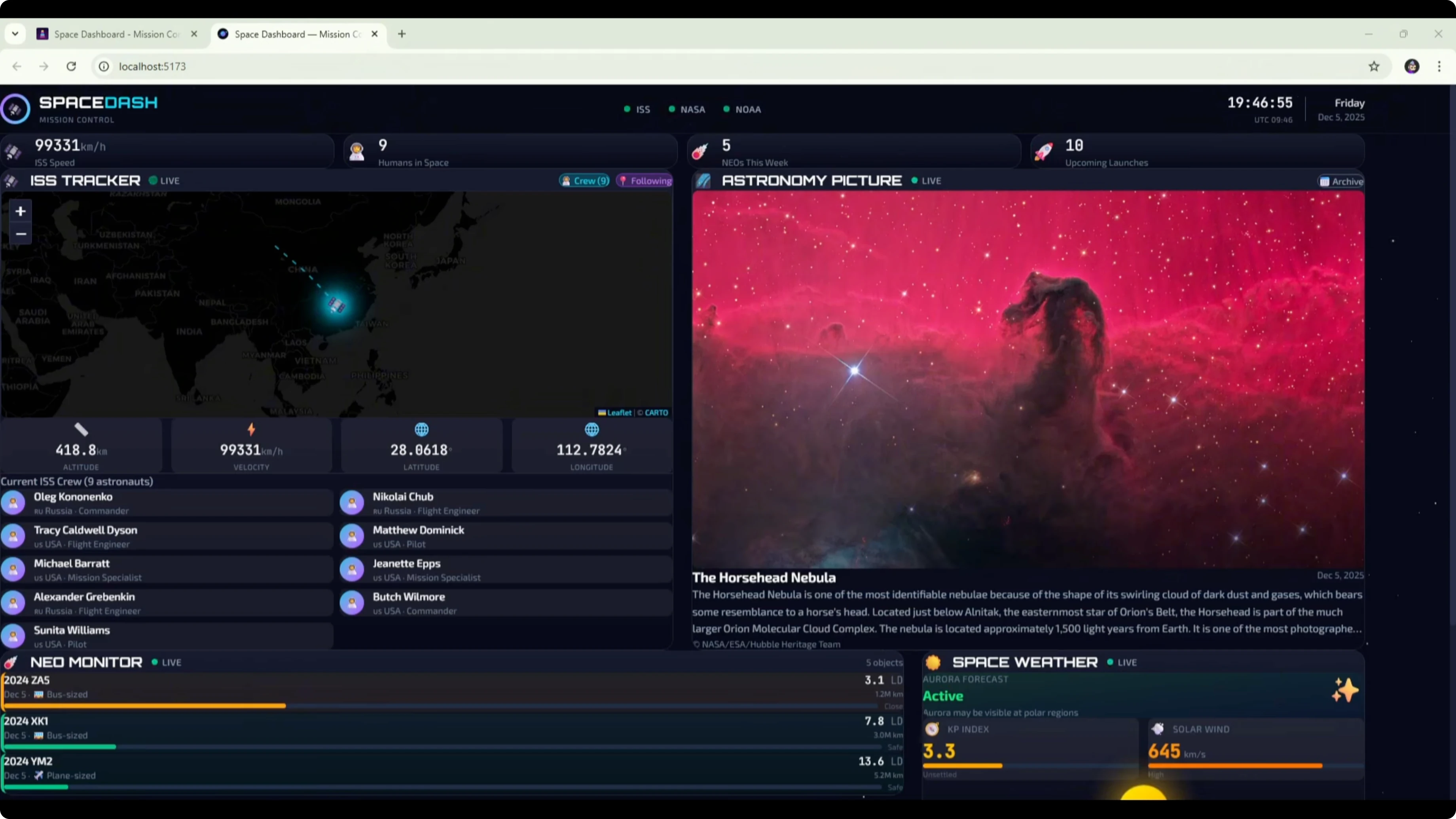
Here is the DeepSeek v3.2 version of the space dashboard built from the Opus PRD. The UI and design look a bit better than before. The background, widgets, and title feel like an improvement.Some font and formatting could be improved. The font was too large in places and made text hard to read. That caused clear formatting issues that look like a CSS problem to fix.
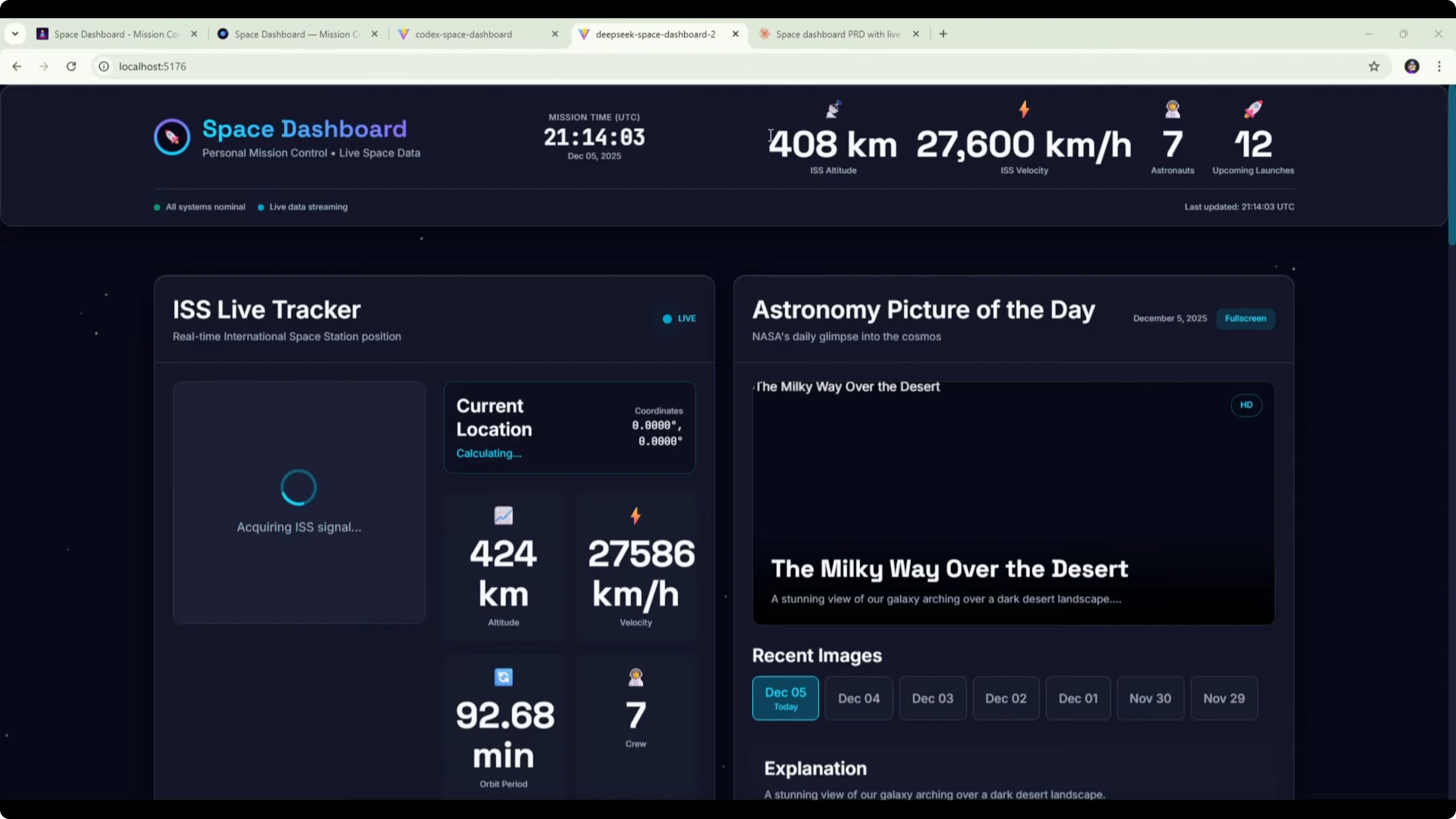
The ISS tracker was still loading at the time of testing. The astronomy picture of the day widget broke the image. Upcoming events, data sources, and about sections were present.
Comparing this to the original DeepSeek v3.2 dashboard built from the shorter DeepSeek PRD, there were no formatting issues in the earlier one. The layout was very similar across both versions, with the map and picture of the day at the top and three widgets below. The main difference was the new design and the formatting problems here.
It might be that the detailed PRD contributed to the formatting problem. One possible workaround is to break the PRD into tasks. You could ask Opus to break it into modules, then ask DeepSeek to build module by module.
DeepSeek V3.2 vs GPT-5.1 Codex MAX vs Opus 4.5 - GPT-5.1 Codex Max results
Here is the Codex version of the space dashboard. It included a mission control section at the top showing the time, information about the crew, and the next launch. It also had the ISS live tracker with an interactive map, coordinates, and crew on board.The astronomy picture of the day widget appeared to have broken images. That could be an API or CORS issue to fix. The widget itself looked clean from a UI perspective.
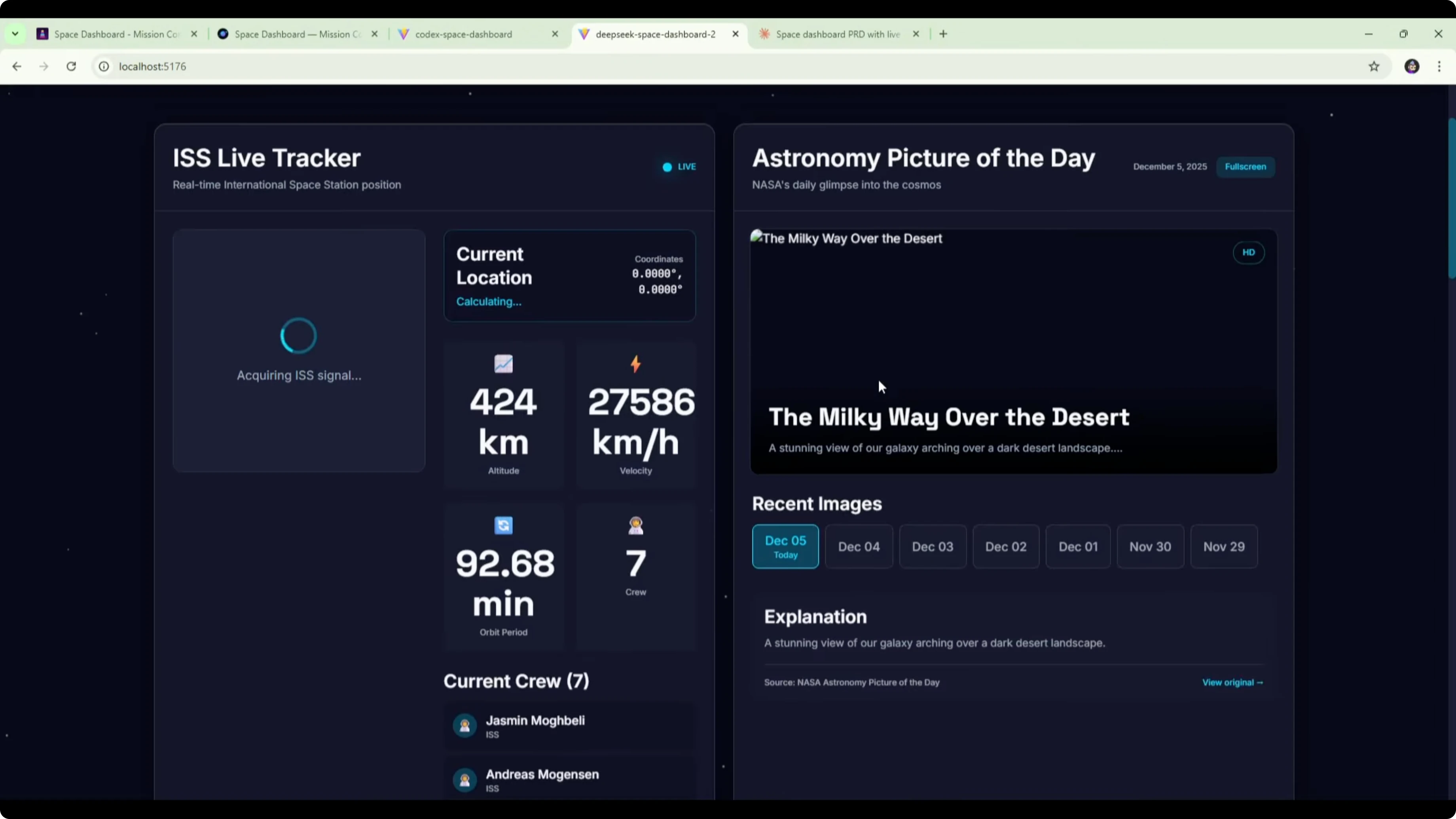
Further down, there was a space events calendar, a near-Earth object monitor, and space weather. There was a clear formatting issue in the middle section where content was squeezed and text wrapped to one word per line. There was a lot of empty space caused by poor layout in that row.
It did not nail how those three sections should work together. The ISS tracker section was solid. The mission control section at the top was also good.
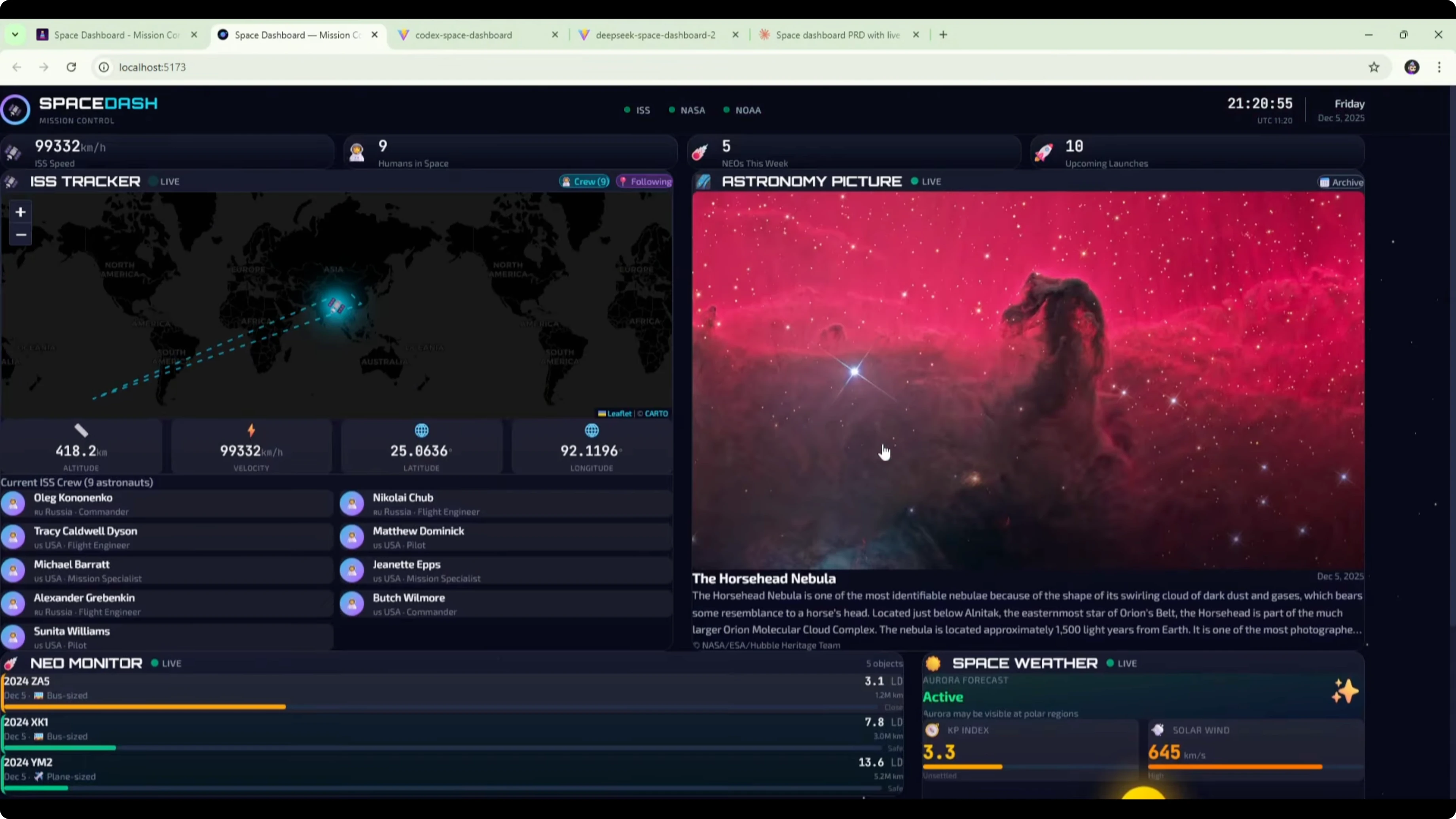
DeepSeek V3.2 vs GPT-5.1 Codex MAX vs Opus 4.5 - Opus 4.5 reference
The original Opus 4.5 build remains the best of all. It nailed the UI design and the API integrations. All features worked and the result looked clean and modern.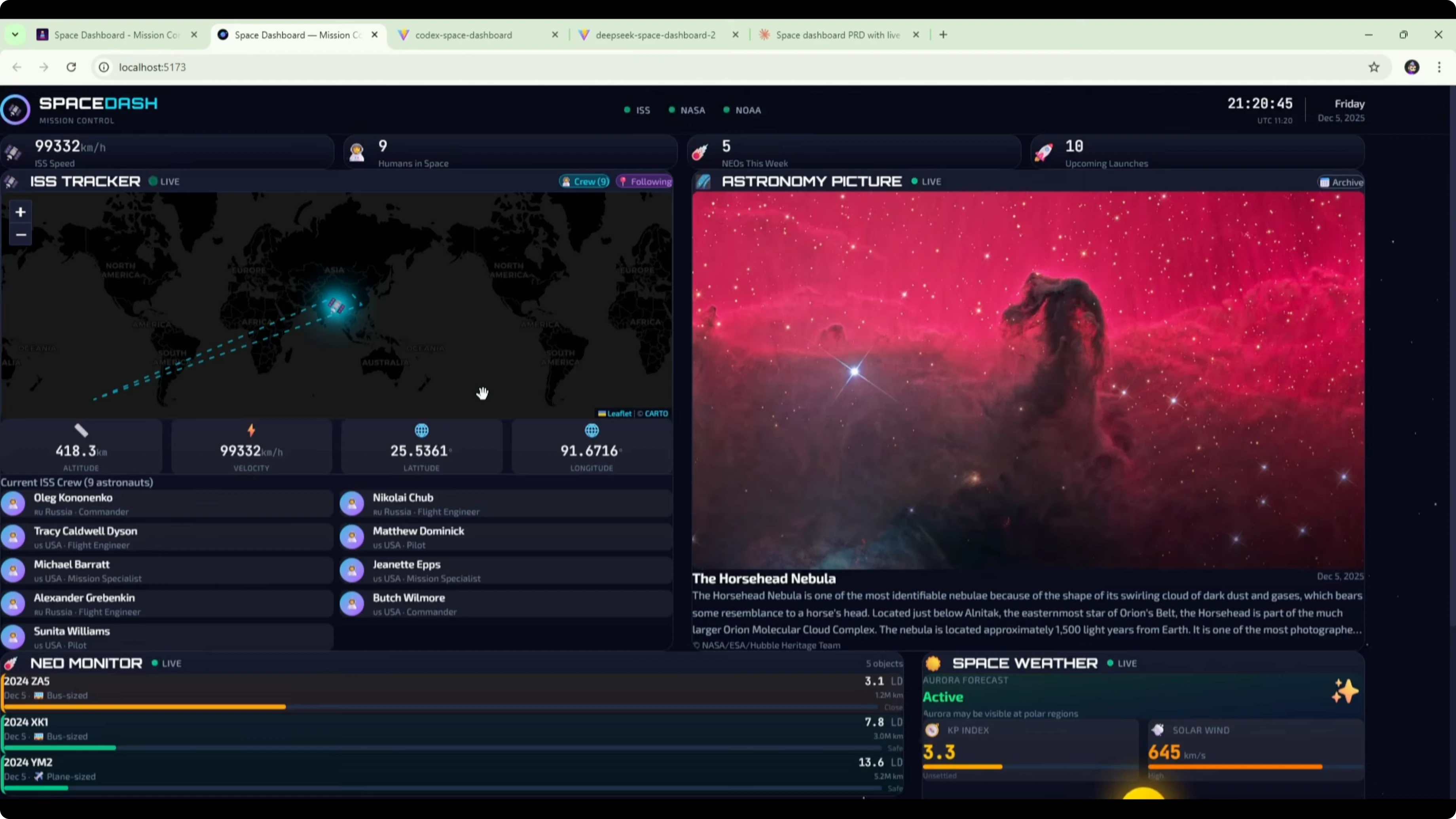
Opus 4.5 again comes out on top when compared with the DeepSeek v3.2 version using the detailed PRD and the GPT-5.1 Codex Max build. That held true across both design quality and functional reliability.
For estimates on usage at scale, you can review this breakdown of token costs for GPT-5.2 vs Opus 4.5.
DeepSeek V3.2 vs GPT-5.1 Codex MAX vs Opus 4.5 - comparison overview
| Criteria | DeepSeek v3.2 | GPT-5.1 Codex Max | Opus 4.5 |
|---|---|---|---|
| PRD used | Full Opus PRD | Full Opus PRD | Own PRD from first test |
| Build time | ~40 minutes | ~18 minutes | N/A here - reference build |
| Build stability | Got stuck, needed continue prompts | Completed without intervention | Stable in prior test |
| UI quality | Improved look, font too large, formatting issues | Clean in parts, middle section layout broken | Clean and modern throughout |
| API integrations | ISS loading, APOD image broken | ISS solid, APOD broken, others present | All features worked |
| ISS tracker | Loading state persisted | Good with interactive map and coordinates | Working |
| APOD widget | Image broken | Images broken | Working |
| Layout | Similar to earlier DeepSeek build | Similar overall, middle row squeezed | Well-balanced layout |
| Overall | Executed the build with CSS issues | Fast build, solid top sections, layout bugs | Best overall quality |
For more three-way perspectives that include other families, this broader comparison with GLM is helpful: GLM 4.7 vs Opus 4.5 vs GPT-5.2.
Use cases
DeepSeek V3.2 vs GPT-5.1 Codex MAX vs Opus 4.5 - DeepSeek v3.2
Good for teams that want to feed a rich PRD but may benefit from breaking work into modules. Suits scenarios where you can iterate on CSS and layout after the first pass. Works when you can guide it with stepwise prompts.DeepSeek V3.2 vs GPT-5.1 Codex MAX vs Opus 4.5 - GPT-5.1 Codex Max
Useful for faster turnarounds and getting a working skeleton quickly. Strong for map-based sections and dashboard headers. Best when you can correct mid-page layout issues.DeepSeek V3.2 vs GPT-5.1 Codex MAX vs Opus 4.5 - Opus 4.5
Best fit for production-ready dashboards with clean UI and reliable integrations. Strong choice when you need fewer fixes after the initial build. Ideal as a reference build for quality and completeness.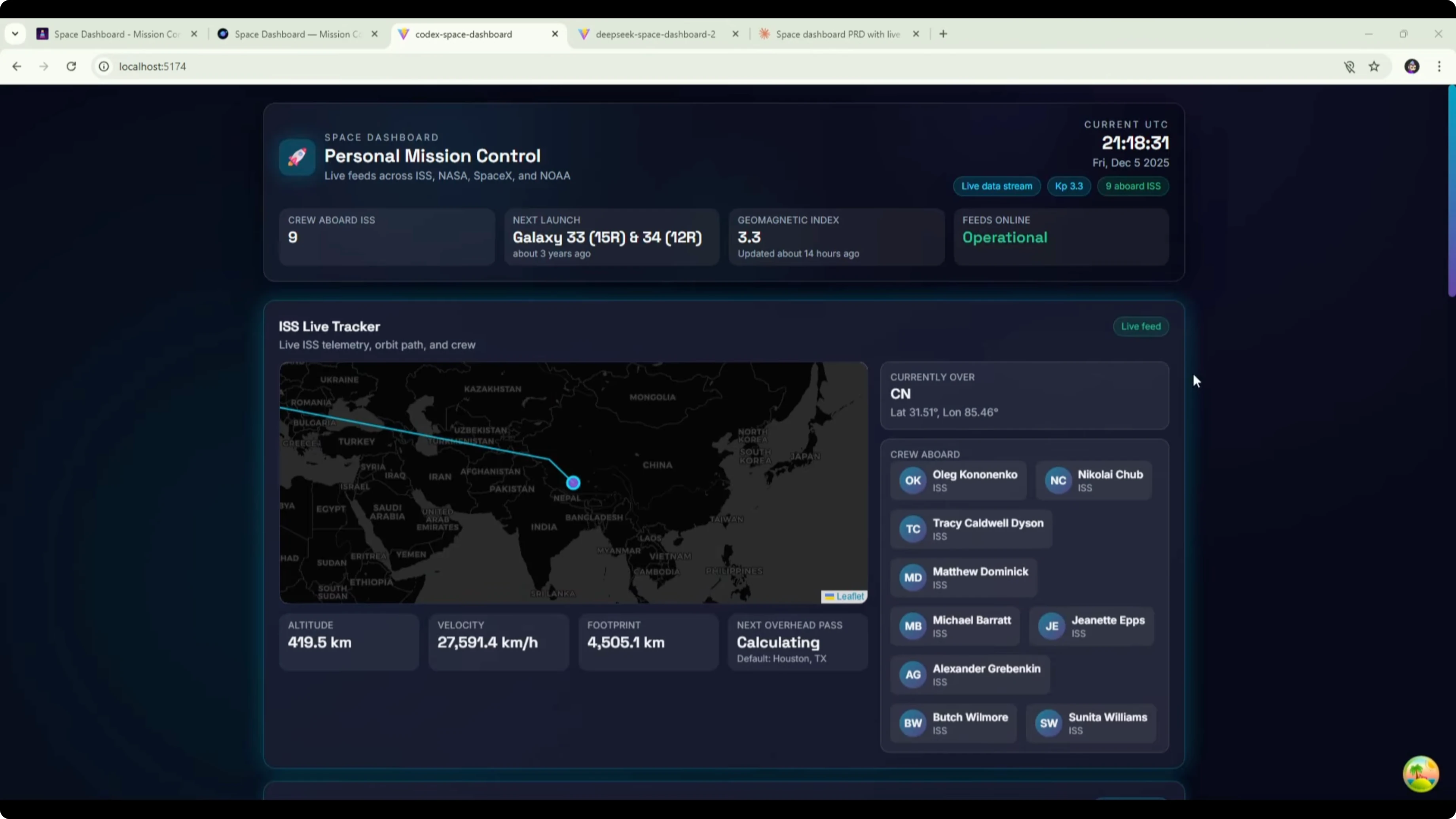
If you are comparing newer Codex variants to Opus on throughput and quality, here is another practical read on speed, cost, and quality trade-offs.
Pros and cons
DeepSeek V3.2 vs GPT-5.1 Codex MAX vs Opus 4.5 - DeepSeek v3.2
Pros: Better look than the earlier DeepSeek build, executed the full brief, and included all sections. Cons: Slower, got stuck during build, font size and layout required CSS fixes.DeepSeek V3.2 vs GPT-5.1 Codex MAX vs Opus 4.5 - GPT-5.1 Codex Max
Pros: Faster build, solid ISS tracker, and a strong top section. Cons: Middle layout broke with squeezed text and empty space, APOD images failed.DeepSeek V3.2 vs GPT-5.1 Codex MAX vs Opus 4.5 - Opus 4.5
Pros: Best design quality, all features worked, and modern UI. Cons: None surfaced in this comparison.If you are weighing ongoing usage, see this breakdown on token costs for GPT-5.2 vs Opus 4.5 to plan budgets.
Step-by-step - reproduce the test
Open Cursor and set up a split-screen workspace.Connect the left workspace to the DeepSeek v3.2 API.
Install and open the Codex extension on the right with GPT-5.1 Codex Max.
Set reasoning to extra high in Codex.
Paste the full Opus PRD into both sides.
Prompt each model to build the space dashboard app.
Wait for builds to complete.
Switch to dev mode for each project.
Test the ISS tracker, APOD, events, NEO, and space weather widgets.
Note build times and any required prompts.
Record formatting issues, broken images, and layout problems.
Compare each build to the Opus 4.5 reference for quality.
For more context on Codex vs Opus across versions, here is a focused look at Codex vs Opus.
Quick CSS fix - font and layout
If your text is oversized or rows are squeezing content, a small CSS pass helps. Adjust font sizing and grid behavior to reduce overflow. Here is a minimal example.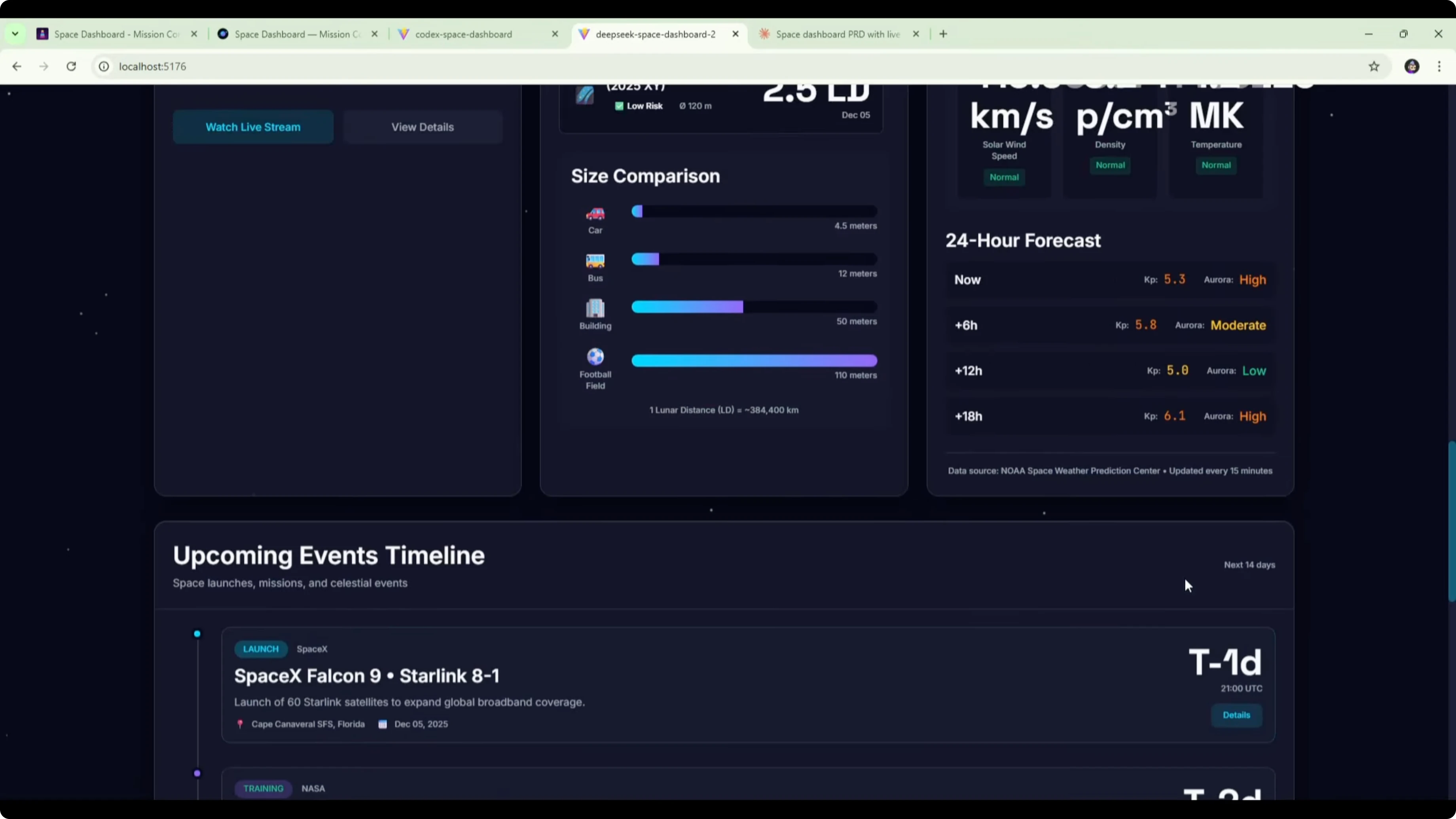
:root {
--font-base: 14px;
--font-scale: 1.1;
}
body {
font-size: var(--font-base);
line-height: 1.5;
-webkit-font-smoothing: antialiased;
-moz-osx-font-smoothing: grayscale;
}
.widget h2, .widget h3 {
font-size: calc(var(--font-base) * var(--font-scale));
margin: 0 0 8px;
line-height: 1.2;
word-break: keep-all;
overflow-wrap: anywhere;
}
.dashboard-row {
display: grid;
grid-template-columns: repeat(3, minmax(0, 1fr));
gap: 16px;
align-items: start;
}
.widget {
min-width: 0;
overflow: hidden;
padding: 12px;
background: rgba(255, 255, 255, 0.06);
border: 1px solid rgba(255, 255, 255, 0.1);
border-radius: 10px;
}
.widget p {
margin: 0 0 6px;
font-size: 0.95rem;
}
/* Fix for one-word-per-line issues in tight columns */
.widget .content {
white-space: normal;
word-break: break-word;
}Final thoughts
With the full Opus PRD, DeepSeek v3.2 delivered a better-looking dashboard than its earlier attempt, but ran into CSS and build stability issues. GPT-5.1 Codex Max built faster and shipped a solid header and ISS section, but stumbled on mid-page layout and broken APOD images. Opus 4.5 remained the clear winner on UI quality and working integrations.This test also suggests a practical tip for DeepSeek v3.2: break a large PRD into modules and build step by step. That can reduce stalls and formatting regressions and improve outcomes with the same input. For a broader lens that includes GLM, this three-way comparison is a good companion read: GLM 4.7 vs Opus 4.5 vs GPT-5.2.
Subscribe to our newsletter
Get the latest updates and articles directly in your inbox.

Related Posts

8 Best Claude Code Plugins in 2026 (You Need to Know)
8 Best Claude Code Plugins in 2026 (You Need to Know)

7 Best Claude Code Skills (You Need to Know)
7 Best Claude Code Skills (You Need to Know)

Claude Code Desktop IDE Features (You Need to Know)
Claude Code Desktop IDE Features (You Need to Know)