
Table Of Content
- GPT-5.2 vs Opus 4.5: Comparing Real App Builds and Token Costs
- Test setup
- Test 1 - Kanban task manager
- GPT-5.2 build - Kanban
- Opus 4.5 build - Kanban
- Cost breakdown - Kanban
- Test 2 - Space Invaders
- GPT-5.2 build - Space Invaders
- Opus 4.5 build - Space Invaders
- Cost breakdown - Space Invaders
- Comparison overview
- How to reproduce the builds and the cost accounting
- Use cases, pros, and cons - GPT-5.2 vs Opus 4.5
- GPT-5.2 - use cases
- GPT-5.2 - pros
- GPT-5.2 - cons
- Opus 4.5 - use cases
- Opus 4.5 - pros
- Opus 4.5 - cons
- Final thoughts

GPT-5.2 vs Opus 4.5: Comparing Real App Builds and Token Costs
Table Of Content
- GPT-5.2 vs Opus 4.5: Comparing Real App Builds and Token Costs
- Test setup
- Test 1 - Kanban task manager
- GPT-5.2 build - Kanban
- Opus 4.5 build - Kanban
- Cost breakdown - Kanban
- Test 2 - Space Invaders
- GPT-5.2 build - Space Invaders
- Opus 4.5 build - Space Invaders
- Cost breakdown - Space Invaders
- Comparison overview
- How to reproduce the builds and the cost accounting
- Use cases, pros, and cons - GPT-5.2 vs Opus 4.5
- GPT-5.2 - use cases
- GPT-5.2 - pros
- GPT-5.2 - cons
- Opus 4.5 - use cases
- Opus 4.5 - pros
- Opus 4.5 - cons
- Final thoughts
OpenAI released GPT-5.2 recently, and I put it head-to-head against Opus 4.5 on real builds. The headline claim is that GPT-5.2 is cheaper per token, but the important question is whether that saving holds when you build actual apps. I tested both models on the same prompts, tracked exact input and output tokens via the providers, and computed precise costs.
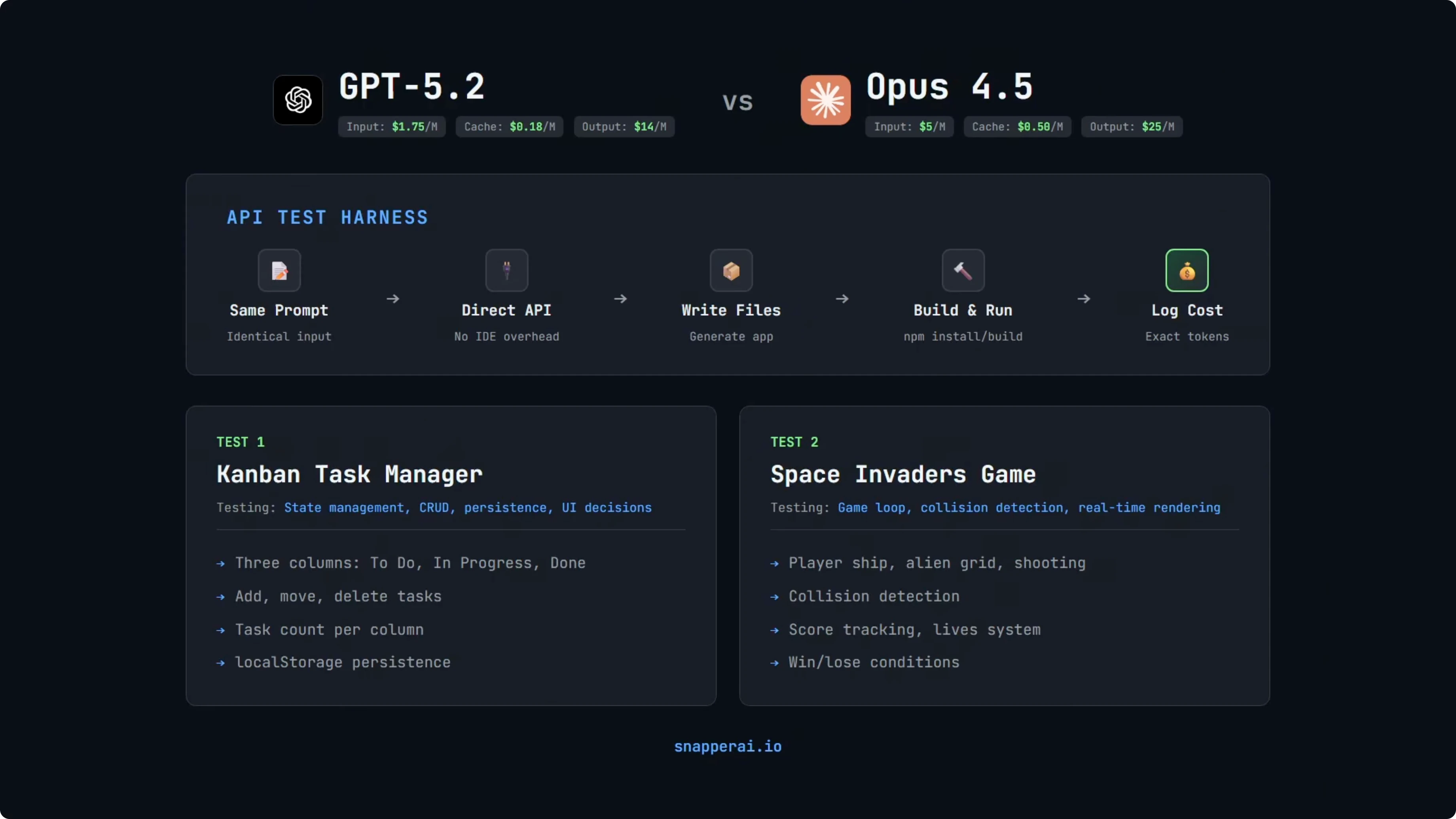
I built a simple API test setup that calls the OpenAI and Anthropic endpoints with identical prompts. The rig logs input and output tokens and calculates cost using the providers’ rates. That gives a true cost comparison rather than just raw token counts.
We’ll look at two builds: a Kanban task manager and a Space Invaders game. Both builds use React 18 with Vite and no extra libraries. For rendering the game, the prompt specifies HTML5 canvas.
GPT-5.2 vs Opus 4.5: Comparing Real App Builds and Token Costs
I included some design direction in the prompts so we could focus on function and cost without having the UI be an unfair factor. The goal was to see how both models perform on the same constraints. If a model needed fixes, I re-prompted and included that cost.
For a broader multi-model comparison beyond these two, see this three-way test on real builds: GLM 4.7 vs Opus 4.5 vs GPT-5.2.
Test setup
Both models received the same prompts for each build. I tracked exact token usage and cost from the API responses. If a build needed fixes, the re-prompt included the full source as context so the model knew what it was editing.
I ran the same dependency constraints for both tests. React 18 with Vite and no extra libraries. That keeps the stack fixed and removes framework choice as a variable.
The two tests stress different capabilities. The Kanban app checks state, CRUD, persistence, and UI choices. The Space Invaders game stresses a game loop, collision detection, and real-time rendering.
Test 1 - Kanban task manager

The prompt asked for three columns labeled To-do, In Progress, and Done. It required adding tasks with a title, moving tasks between columns, deleting tasks, and a task count per column. Everything had to persist to localStorage.
Dependencies were locked to React 18 and Vite. No extra libraries. That keeps the comparison on the models, not the frameworks. I also gave design direction to create a polished modern UI with complete creative freedom, including color scheme, animations, and micro interactions.
GPT-5.2 build - Kanban
The app opened with example tasks in three columns. Adding a task worked with a modal that let me set a title and a status on creation, and it updated the per-column counts.

Drag-and-drop worked and updated status correctly. It also supported moving tasks with arrow controls between columns. After restarting the dev server, tasks persisted, so localStorage was correct.
Opus 4.5 build - Kanban
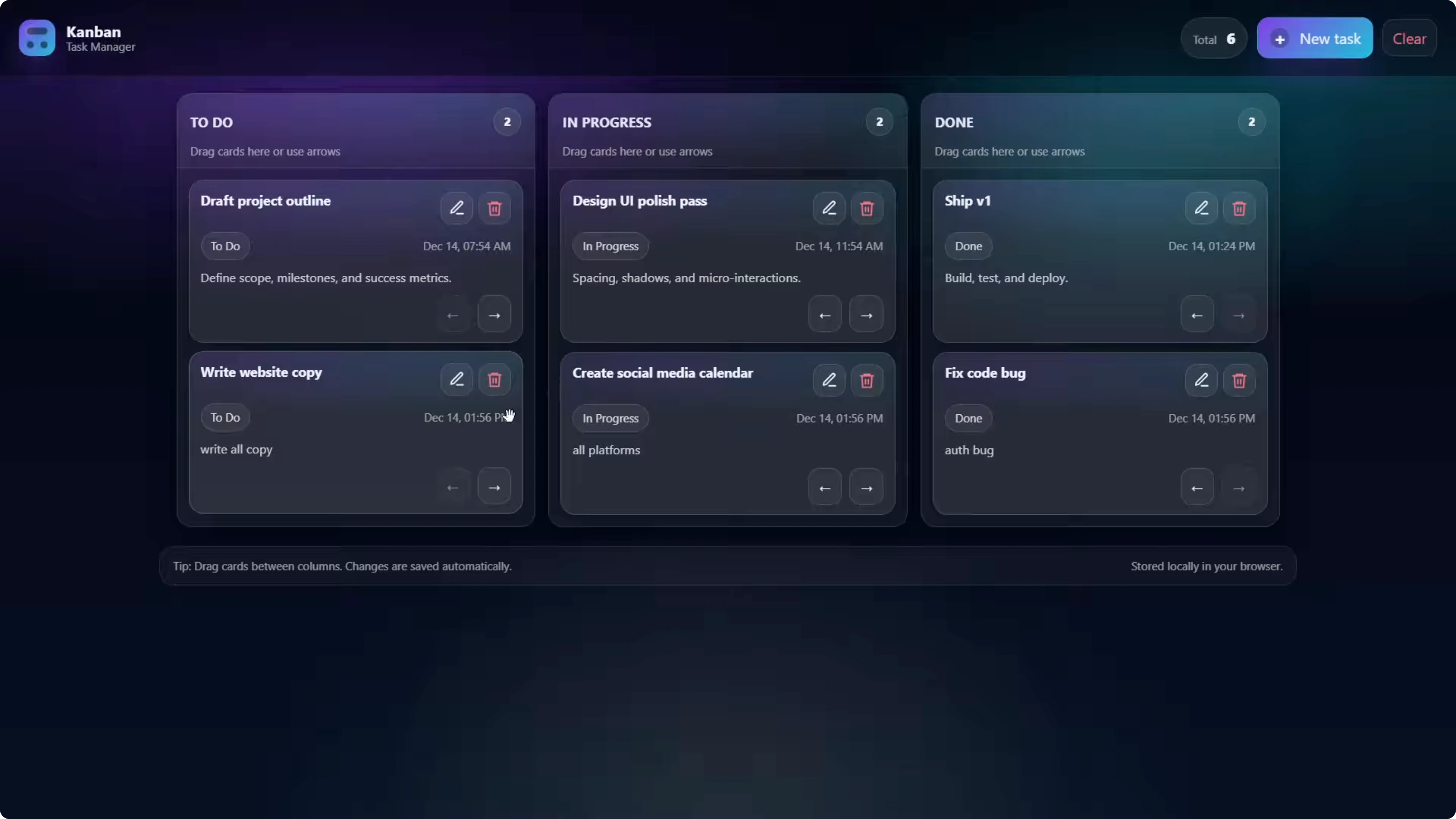
The board rendered with a title and logo, and the three columns. Adding a task worked, but it always added the new task to To-do without a status selector in the create flow.
The card showed a button labeled In Progress even while in the To-do column, which could be confusing. Drag-and-drop worked and the counter updated correctly, and tasks persisted after a restart. That covers the required features with a slightly different approach.
Cost breakdown - Kanban

Both models passed on the first turn with no bugs or reprompts. That’s a clean one-shot for both.
Input tokens differed because tokenizers are different per provider: 566 for GPT-5.2 vs 732 for Opus 4.5. Output was 9,337 tokens for GPT-5.2 vs 6,445 for Opus 4.5, so GPT-5.2 produced almost 50 percent more code and UI.
Total cost came to 13.2 cents for GPT-5.2 vs 16.5 cents for Opus 4.5. That’s about 20 percent cheaper for GPT-5.2, even though it generated more output.
GPT-5.2 wrote 1,263 lines across 11 files. Opus 4.5 wrote 718 lines across 6 files. Functionality was comparable, and the cost gap will add up over time on larger projects.
If you’re comparing coding-focused variants across vendors, I also benchmarked this pairing with code-centric prompts here: GPT-5.2 Codex vs Opus 4.5.
Test 2 - Space Invaders
This build is more complex. The requirements included a full game loop, collision detection, and real-time rendering on HTML5 canvas.
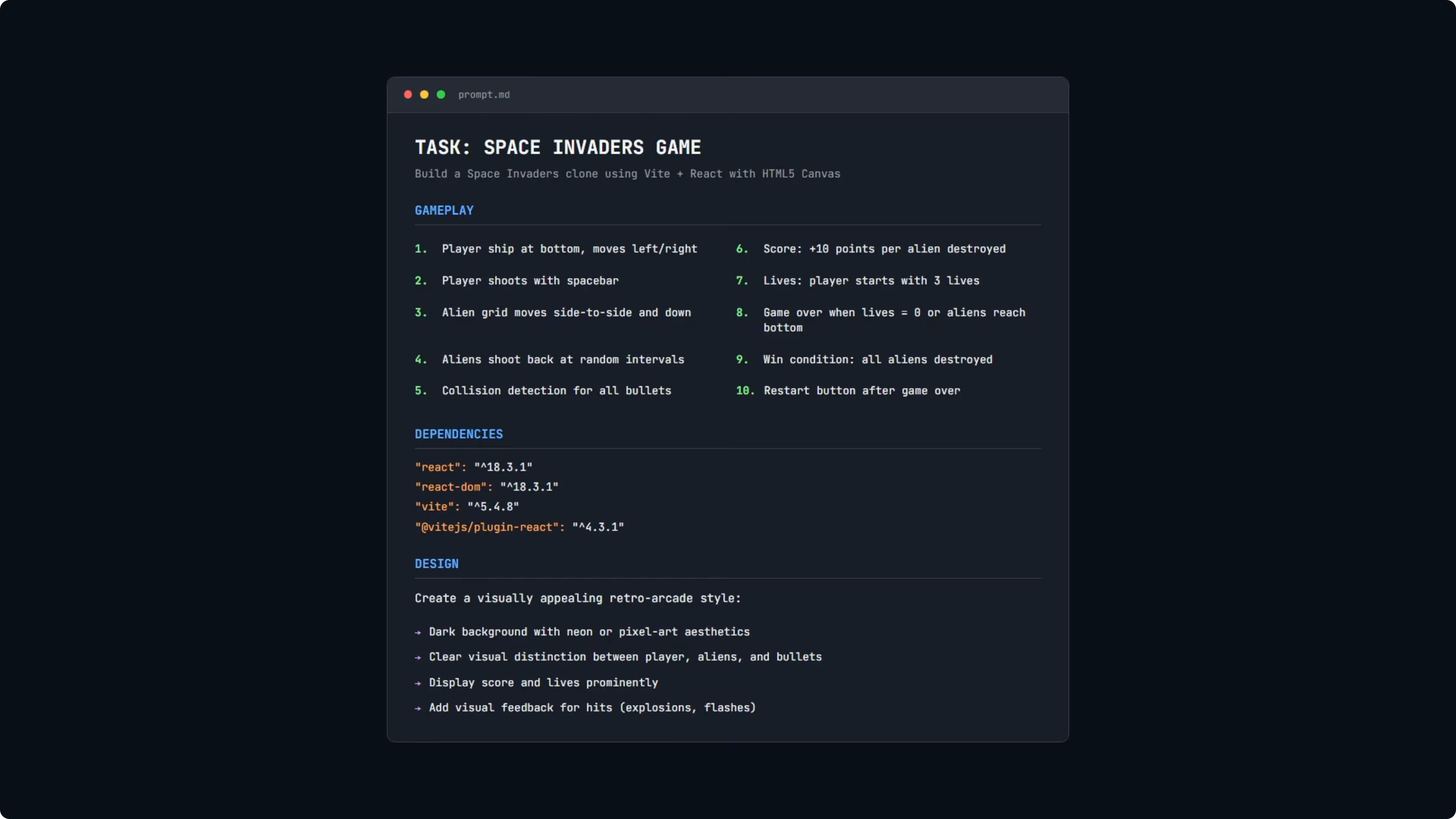
I asked for movement left and right, spacebar to shoot, a grid of aliens that move and step down, alien shots at random intervals, collision detection across player shots and alien shots, score tracking, a lives system, win and lose conditions, and a restart button. Same stack rules as before with React 18 and Vite and no extra libraries.
GPT-5.2 build - Space Invaders
The game opened with an animated background and a title screen that showed lives, score, and instructions. Start worked, arrow keys moved the player, and spacebar fired as expected.
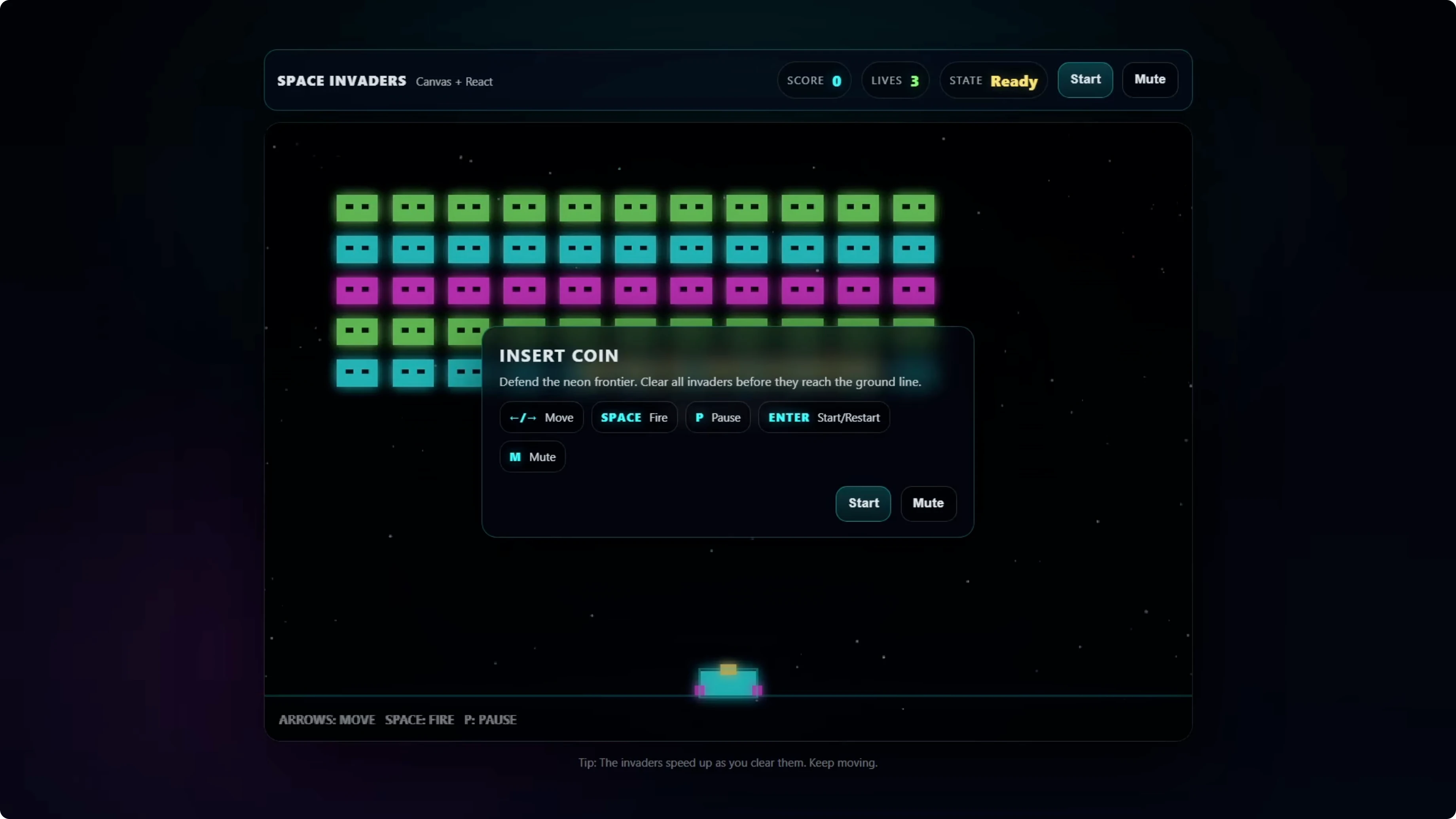
Aliens fired back at a sensible rate, hits flashed the ship, and victory triggered when all invaders were destroyed. Mute and pause toggled correctly and the state updated as expected. Functionally, it was a strong result on the first try.

Opus 4.5 build - Space Invaders
The build auto-started on first load, which is why a game over state showed immediately. On play, alien bullets spawned so frequently that the player died almost instantly.
That fire-rate bug made the game unplayable and there was no start screen. I prompted a fix for both issues and included all source files as context so the model could patch the exact code it wrote.
The start screen and fire rate improved after the fix. The bullet frequency was still fast and hard to play, and it would have needed another iteration to be comfortable.
Cost breakdown - Space Invaders
On the one-shot comparison, GPT-5.2 came in at 15.4 cents vs Opus 4.5 at 16.2 cents. That’s a small gap at about 5 percent.
The Opus 4.5 repair cost was 31.8 cents. The reason is straightforward: to fix a bug, you send the full source context so the model can edit correctly, which cost 32,000 input tokens before it even wrote the fix.
Total cost for Opus 4.5 was 48 cents, combining the original 16.2 cents with the 31.8 cents repair. GPT-5.2 stayed at 15.4 cents by passing on the first try, and Opus 4.5 likely needed another iteration to tune the fire rate to a comfortable level.

If you are exploring the broader Opus family and model increments, these results pair well with my separate comparison: Claude Opus 4.6 vs Opus 4.5.
Comparison overview
| Metric | GPT-5.2 - Kanban | Opus 4.5 - Kanban | GPT-5.2 - Space Invaders | Opus 4.5 - Space Invaders |
|---|---|---|---|---|
| Prompt input tokens | 566 | 732 | similar-length prompt | similar-length prompt |
| Output tokens | 9,337 | 6,445 | passed one-shot | passed one-shot but had gameplay issues |
| One-shot cost | 13.2 cents | 16.5 cents | 15.4 cents | 16.2 cents |
| Repairs | none | none | none | start screen and fire-rate fix required |
| Repair cost | 0 | 0 | 0 | 31.8 cents |
| Total cost | 13.2 cents | 16.5 cents | 15.4 cents | 48 cents |
| Lines of code | 1,263 across 11 files | 718 across 6 files | solid feature set | playable after fixes but still too fast |
For a deeper look at mixed-vendor coding benchmarks that include GLM and multiple GPT variants, see this expanded study: GLM 5 vs Opus 4.6 vs GPT-5.3 Codex.
How to reproduce the builds and the cost accounting
Create the project with React 18 and Vite. Use the official Vite scaffolder to keep parity.
Run:
npm create vite@latest kanban-app -- --template react
cd kanban-app
npm install
npm run devLock the React version to 18.x in package.json. Keep dependencies minimal and avoid adding libraries.
For the Kanban app, implement three columns labeled To-do, In Progress, and Done. Add create, move, and delete operations, and show a per-column task count.
Use localStorage for persistence. Here is a minimal state and persistence example in React:
import { useEffect, useState } from 'react';
function useTasks() {
const [tasks, setTasks] = useState(() => {
const raw = localStorage.getItem('tasks');
return raw ? JSON.parse(raw) : [];
});
useEffect(() => {
localStorage.setItem('tasks', JSON.stringify(tasks));
}, [tasks]);
return [tasks, setTasks];
}Handle drag-and-drop by updating a task’s status and re-saving state. A simple move operation can map tasks and replace the dragged item’s status.
For the Space Invaders game, render with HTML5 canvas. Use requestAnimationFrame for timing and separate update and draw steps.
A minimal canvas loop in React:
import { useEffect, useRef } from 'react';
export default function Game() {
const ref = useRef(null);
const rafRef = useRef(0);
useEffect(() => {
const canvas = ref.current;
const ctx = canvas.getContext('2d');
let last = performance.now();
function update(dt) {
// update positions, handle input, check collisions
}
function draw() {
ctx.clearRect(0, 0, canvas.width, canvas.height);
// draw player, aliens, bullets, UI
}
function loop(ts) {
const dt = (ts - last) / 1000;
last = ts;
update(dt);
draw();
rafRef.current = requestAnimationFrame(loop);
}
rafRef.current = requestAnimationFrame(loop);
return () => cancelAnimationFrame(rafRef.current);
}, []);
return <canvas ref={ref} width={800} height={600} />;
}Set move left and right with arrow keys and shoot on spacebar. Implement collisions by checking bounding boxes for shots against aliens and alien shots against the player.
Track tokens and cost directly from the APIs. Read usage from each response so you can compute exact dollars and cents per turn.
OpenAI sample in Node:
import OpenAI from 'openai';
const openai = new OpenAI({ apiKey: process.env.OPENAI_API_KEY });
async function runGpt52(prompt) {
const res = await openai.chat.completions.create({
model: 'gpt-5.2',
messages: [{ role: 'user', content: prompt }],
temperature: 0.2
});
const usage = res.usage; // prompt_tokens, completion_tokens, total_tokens
console.log('GPT-5.2 usage:', usage);
// compute cost using your stored per-token rates
return res.choices[0].message.content;
}Anthropic sample in Node:
import Anthropic from '@anthropic-ai/sdk';
const anthropic = new Anthropic({ apiKey: process.env.ANTHROPIC_API_KEY });
async function runOpus45(prompt) {
const res = await anthropic.messages.create({
model: 'claude-3-opus-4.5',
max_tokens: 4096,
messages: [{ role: 'user', content: prompt }]
});
const usage = res.usage; // input_tokens, output_tokens
console.log('Opus 4.5 usage:', usage);
// compute cost using your stored per-token rates
return res.content[0].text;
}For repairs, send the full source as context so the model can edit what it wrote. Expect setup tokens to be large before the actual fix, which is why repair turns can cost more than the original build.
If your focus is strictly on cost-per-build and iteration overhead, I published a dedicated cost-first walkthrough here: GPT-5.2 cost build notes.
Use cases, pros, and cons - GPT-5.2 vs Opus 4.5
GPT-5.2 - use cases
It fit well for app builds that need to pass on the first turn with a strong balance of code volume and cost. The Space Invaders result showed it can coordinate real-time logic, input, and UI state without extra iterations. If you are running many builds, the 20 percent saving on the Kanban test and the clean one-shot on the game can compound quickly.
GPT-5.2 - pros
One-shot pass on both tests avoided repair costs. Lower per-token rates held up even when it produced more output tokens. It wrote more files and lines, which can help with separation of concerns.
GPT-5.2 - cons
It produced more code than Opus 4.5 on the Kanban test, which can be heavier to read. Design polish needed explicit prompting to show strong visual detail. If you prefer minimal output, you may need to ask for concise file structure.
Opus 4.5 - use cases
It delivered the Kanban features in a focused way with fewer files and lines. With design direction it still put solid effort into the UI. For tasks that fit its default patterns and pass on the first try, the one-shot cost is close to GPT-5.2.
Opus 4.5 - pros
Good UI effort from a basic brief aligned with past results. The Kanban app met the requirements and persisted state correctly. Tokenization differences did not prevent a competitive one-shot cost.
Opus 4.5 - cons
The Space Invaders build needed fixes for start handling and fire rate. The repair turn was costly because all source files had to be sent as context. It would likely need another iteration to reach a comfortable difficulty curve.
If you want a side-by-side that includes a coding-specialist GPT against Opus, this benchmark complements the findings here: a GPT-5.2 Codex vs Opus 4.5 comparison.
Final thoughts
On real builds with identical prompts and a fixed stack, GPT-5.2 came out cheaper overall. It passed both tests on the first try, which avoided repair turns that can dominate total cost.
Opus 4.5 was competitive on the Kanban test and delivered a clean result. On the Space Invaders test, the repair turn pushed total cost far above GPT-5.2, and it likely needed another small iteration for playability.
If you are choosing a default model for app work and care about total build cost with iteration risk factored in, GPT-5.2 is the safer pick from these results. For a larger cross-model context that includes GLM and newer GPT variants, see this broader benchmark set: a multi-model coding benchmark.
Subscribe to our newsletter
Get the latest updates and articles directly in your inbox.

Related Posts

8 Best Claude Code Plugins in 2026 (You Need to Know)
8 Best Claude Code Plugins in 2026 (You Need to Know)

7 Best Claude Code Skills (You Need to Know)
7 Best Claude Code Skills (You Need to Know)

Claude Code Desktop IDE Features (You Need to Know)
Claude Code Desktop IDE Features (You Need to Know)