
Table Of Content
- GPT-5.2 vs Opus 4.5 overview
- Speed and cost in GPT-5.2 vs Opus 4.5
- GPT-5.2 vs Opus 4.5 finance app
- Setup and prompt
- Opus 4.5 build
- GPT-5.2 build
- Verdict
- GPT-5.2 vs Opus 4.5 breakout game
- Prompt and build time
- GPT-5.2 version
- Opus 4.5 version
- Verdict
- Use cases in GPT-5.2 vs Opus 4.5
- GPT-5.2 strengths and trade-offs
- Opus 4.5 strengths and trade-offs
- Step-by-step test guide for GPT-5.2 vs Opus 4.5
- Final thoughts on GPT-5.2 vs Opus 4.5

GPT-5.2 vs Opus 4.5: How Do Speed, Cost, and Build Quality Compare?
Table Of Content
- GPT-5.2 vs Opus 4.5 overview
- Speed and cost in GPT-5.2 vs Opus 4.5
- GPT-5.2 vs Opus 4.5 finance app
- Setup and prompt
- Opus 4.5 build
- GPT-5.2 build
- Verdict
- GPT-5.2 vs Opus 4.5 breakout game
- Prompt and build time
- GPT-5.2 version
- Opus 4.5 version
- Verdict
- Use cases in GPT-5.2 vs Opus 4.5
- GPT-5.2 strengths and trade-offs
- Opus 4.5 strengths and trade-offs
- Step-by-step test guide for GPT-5.2 vs Opus 4.5
- Final thoughts on GPT-5.2 vs Opus 4.5
OpenAI just dropped its newest model, GPT-5.2. I put it head-to-head against Claude Opus 4.5 on two practical builds: a personal finance app with spending charts and a monthly health score, and a classic Breakout game with paddle controls and collision detection. In my last test, Opus swept GPT-5.1 on creative writing, so I wanted to see if the newest model from OpenAI can close the gap on a few coding based projects.
Quick note on pricing. GPT-5.2 is 40% more expensive than 5.1, but it is still significantly cheaper than Opus. We are talking $1.75 per million input tokens versus $5 for Opus and $14 versus $25 for output, so roughly three times cheaper on input and almost two times cheaper on output.
If you want a deeper breakdown of the per-token math and usage, see these pricing details: token-by-token cost comparison.
GPT-5.2 vs Opus 4.5 overview
| Aspect | GPT-5.2 | Opus 4.5 |
|---|---|---|
| Input/Output pricing | $1.75 in / $14 out per 1M tokens | $5 in / $25 out per 1M tokens |
| Finance app build time | 11 minutes 20 seconds | 5 minutes 40 seconds |
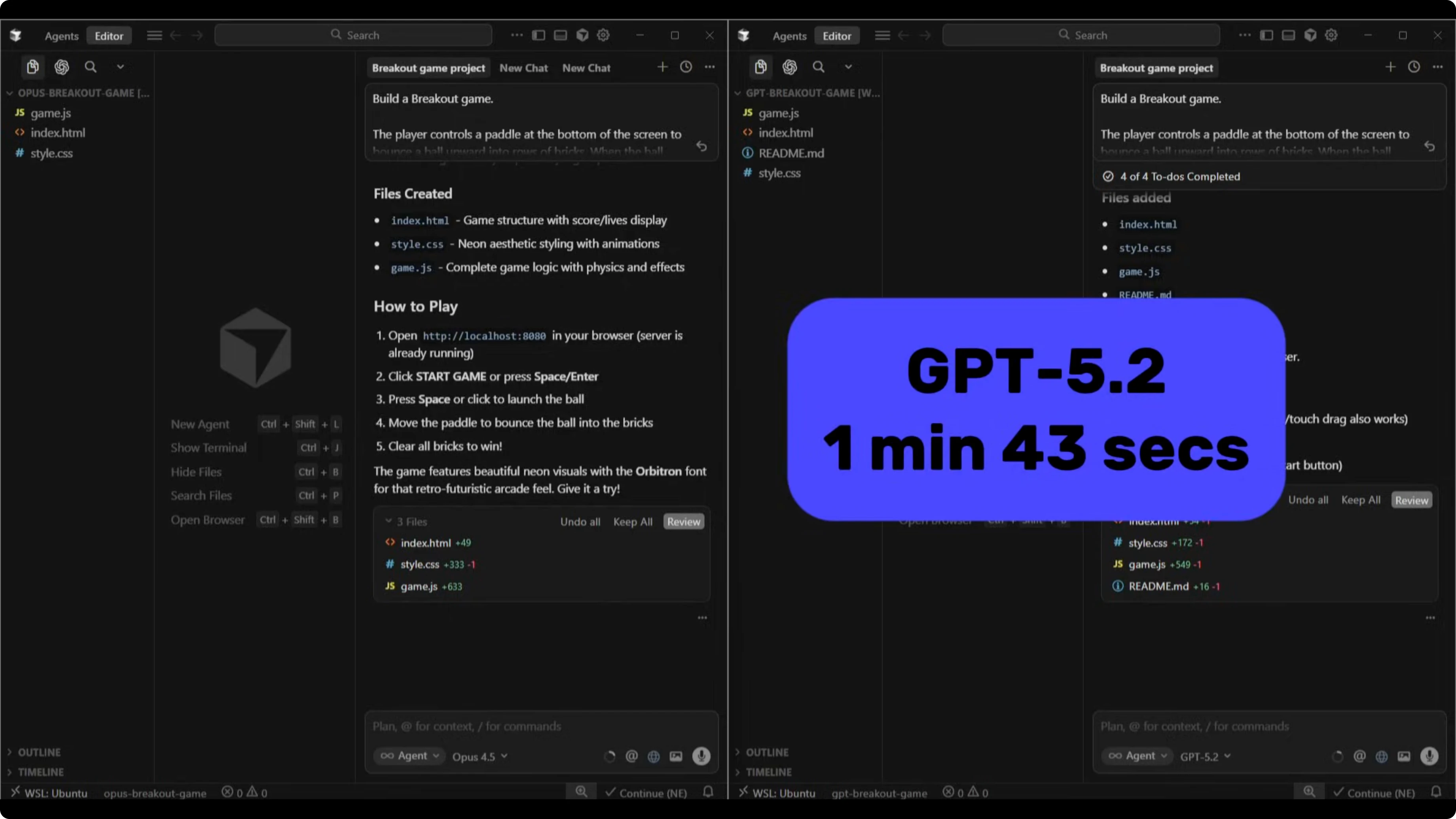
| Breakout game build time | 1 minute 43 seconds | 6 minutes 27 seconds |
| Tech choices | React with local storage; planned and scaffolded step by step | React with local storage; started building immediately |
| Auto categorization | Needed a manual override for petrol to transport | Correctly categorized petrol as transport out of the box |
| Design polish | Functional but generic dark mode; flat health score bar | Branded, clean UI; gauge-based health score with emojis |
| Debug friction | Hit a Tailwind configuration issue and fixed it | Spent minutes troubleshooting click detection during game build |
| Extras | Add sample data button; manual category override with labels | Full brand identity in finance app; neon retro aesthetic in game |

If you want to see these two next to a third strong option, check our side-by-side take on GLM 4.7 alongside both models here: GLM 4.7 vs GPT-5.2 vs Opus 4.5.
Speed and cost in GPT-5.2 vs Opus 4.5
The finance app flipped in favor of Opus on speed. Opus 4.5 finished in 5 minutes and 40 seconds, while GPT-5.2 took 11 minutes and 20 seconds.
The Breakout game reversed that completely. GPT-5.2 shipped in 1 minute and 43 seconds, while Opus 4.5 took 6 minutes and 27 seconds, much of that spent debugging its own click detection.
If you care about project budgets and throughput, this cost-to-build discussion adds context beyond this head-to-head: cost and build speed notes.
GPT-5.2 vs Opus 4.5 finance app
Setup and prompt
I set both models up in Cursor with separate empty directories. Opus 4.5 ran in a high effort reasoning mode, GPT-5.2 ran with medium reasoning.
I gave both the same prompt. Build an app where users can input transactions with an amount, description, and date, autocategorize spending like food, transport, and entertainment, show a visual breakdown with charts, and calculate a monthly health score.
Opus 4.5 build
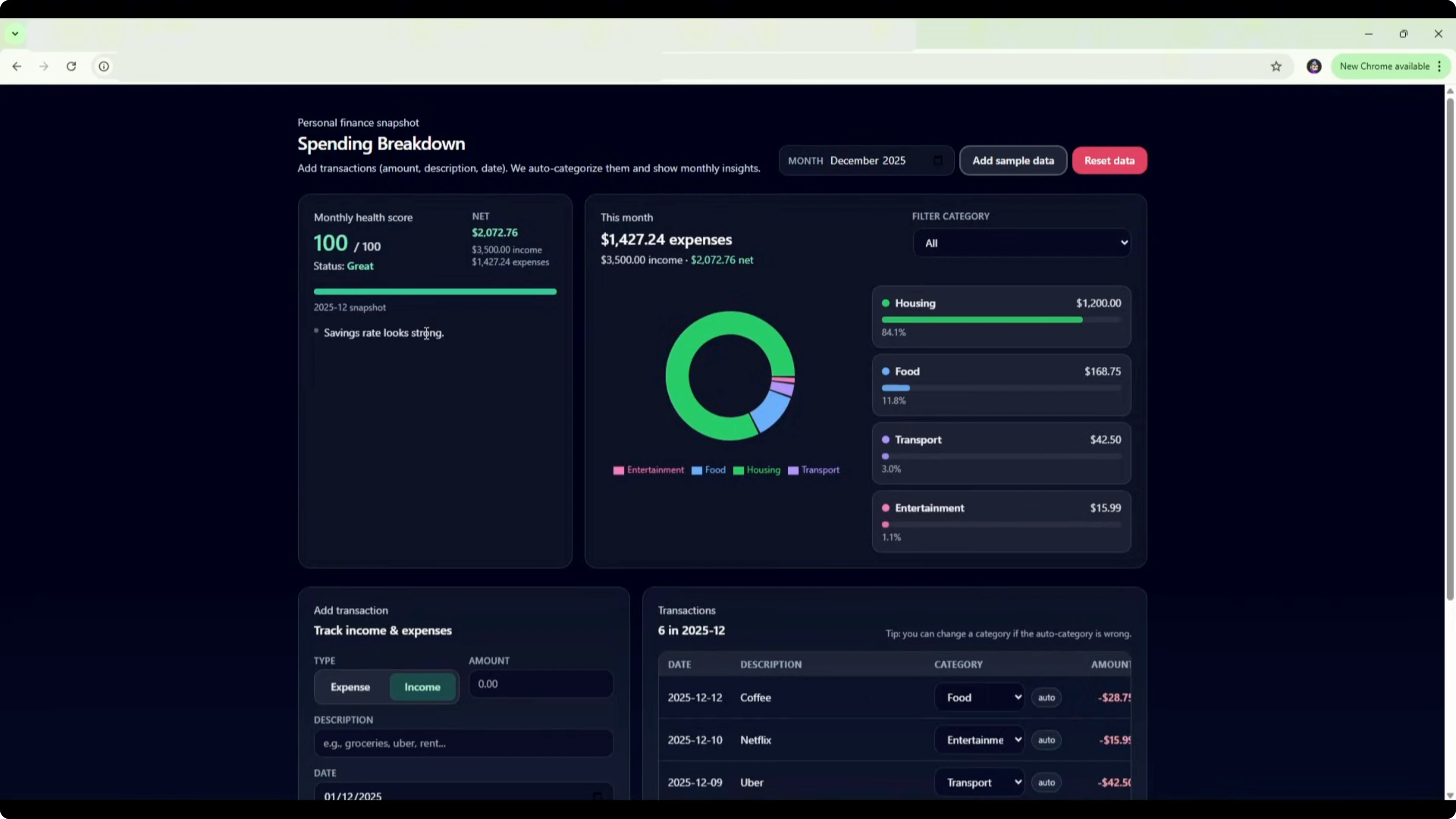
Opus 4.5 went straight into building. It used React with local storage, delivered a polished UI with a full brand identity called Opus Finance, and shipped a gauge-based monthly health score with tasteful emoji touches.
I tested it with $300 for groceries, $150 on restaurants, $80 on petrol, and $5,000 salary income. It auto-categorized groceries and restaurant into food and dining, petrol into transport, and salary as income. The breakdown showed 84% food and dining and 15% transport, the health score updated to 55 fair, and it flagged a low savings rate, spending below income, high spending in food and dining, and a focus on essentials.
GPT-5.2 build
GPT-5.2 took a more methodical route. It laid out a plan, scaffolded the project step by step, hit a Tailwind configuration issue, and resolved it before completing the React plus local storage build.
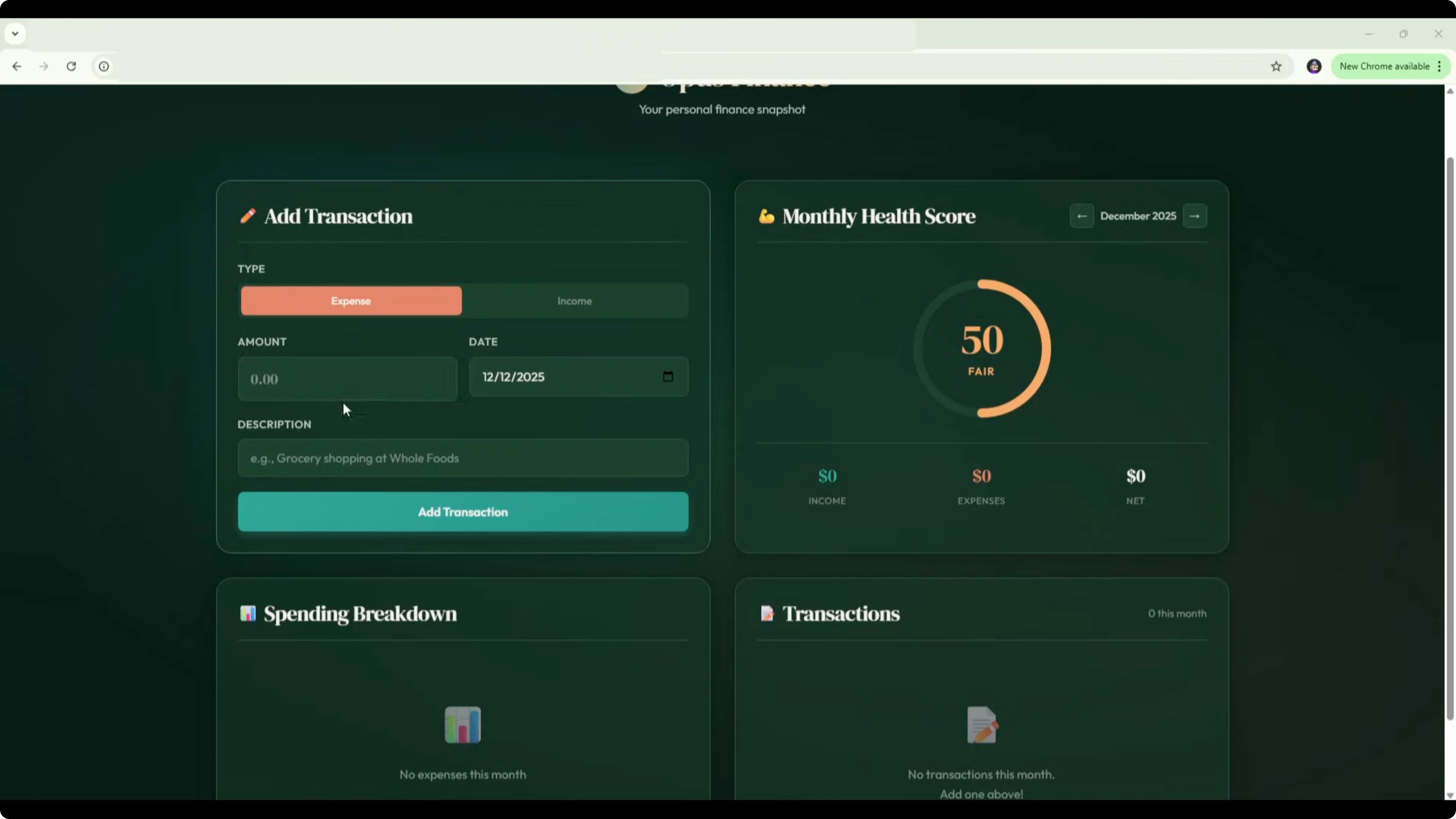
The UI landed as a generic dark mode with a simple health score bar, but it added two useful touches. It included an add sample data button and a manual category override with a clear label indicating a manual category on change. With the same transactions, GPT-5.2 categorized groceries and restaurants as food, marked petrol as other, and salary as income, and I changed petrol to transport using the dropdown override.

The health score came out as 88 great with notes that savings rate looks strong and discretionary spending is relatively high. All charts, transactions, categories, and the health score were functional.
Verdict
Both apps hit the core requirements. Opus 4.5 stood out on auto categorization accuracy and shipped a cleaner, more branded design that felt ready to show to users.
GPT-5.2 added manual overrides and shipped solid functionality, but the default UI looked more basic. If you are cost conscious, there is a solid workflow here: use GPT-5.2 for backend logic and core features, then bring Opus 4.5 in for UI and design polish.
For more on model choice for coding work, here is a deeper comparison focused on coding-oriented variants: GPT-5.2 Codex vs Opus approaches.
GPT-5.2 vs Opus 4.5 breakout game
Prompt and build time
The prompt asked for a classic Breakout. There is a paddle at the bottom, a ball that bounces, rows of bricks, scoring, lives, and a win condition when all bricks are cleared.
GPT-5.2 kept it simple with self-contained HTML, CSS, and JavaScript and shipped in 1 minute and 43 seconds. Opus 4.5 committed to a full neon retro aesthetic with particle effects, ball trails, CRT scan lines, and animated UI, but it spent minutes trying to troubleshoot its own click detection, which slowed the build to 6 minutes and 27 seconds.
GPT-5.2 version
First impression, the UI looked basic. A title, a start button, score and lives in the corners, and a clean but plain layout.
Gameplay worked after serving the ball, but the physics were a little off. It sometimes cleared multiple blocks in a line instead of rebounding, and I could get the ball stuck in a straight up-and-down pattern. Lives and score tracking worked as expected, and the game loop functioned end to end.
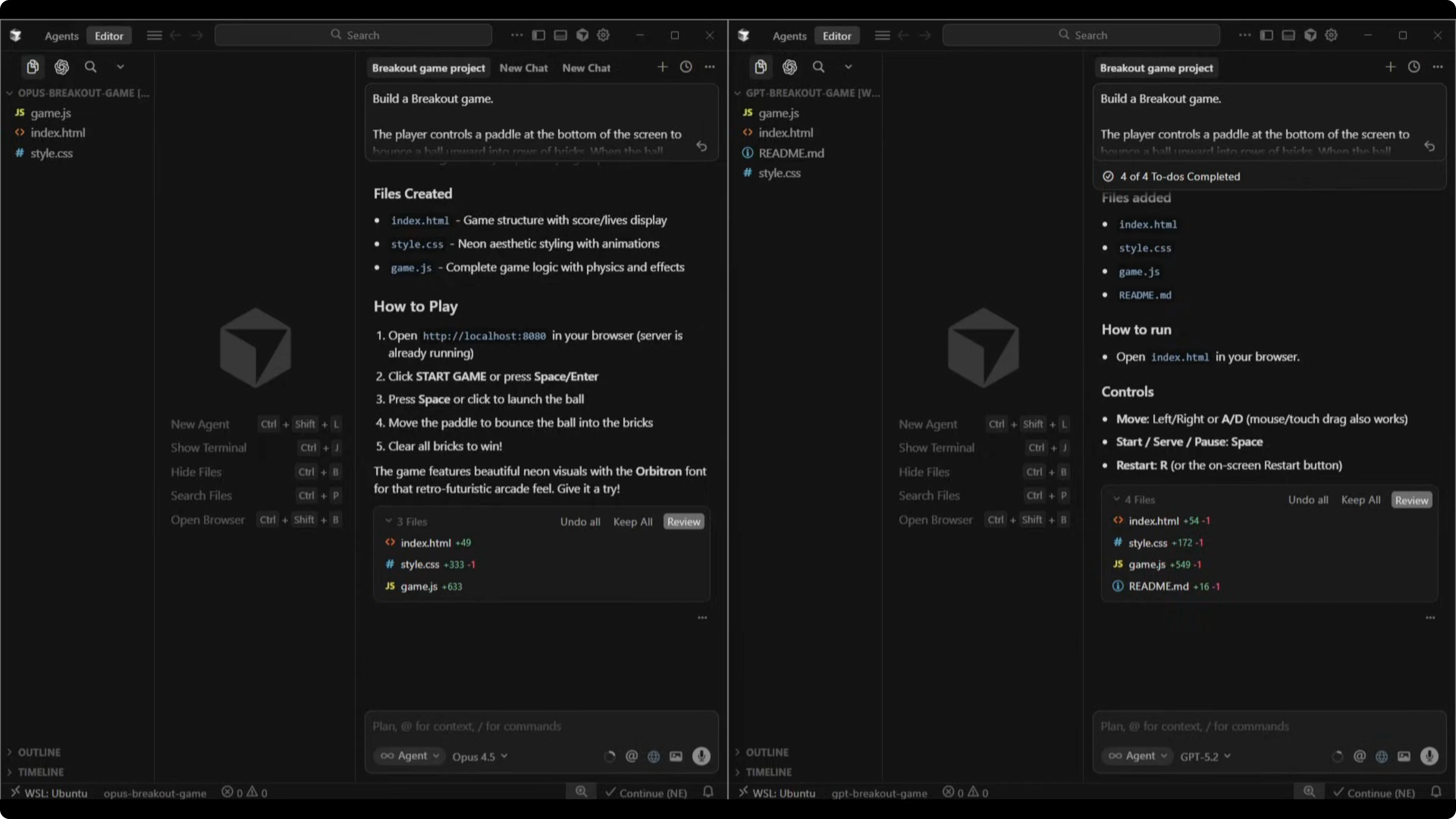
Opus 4.5 version
Opus named the game Neon Breakout. The UI looked stronger immediately, with a glowing title, a tagline, a hover-lit start button, and diamond icons for lives.
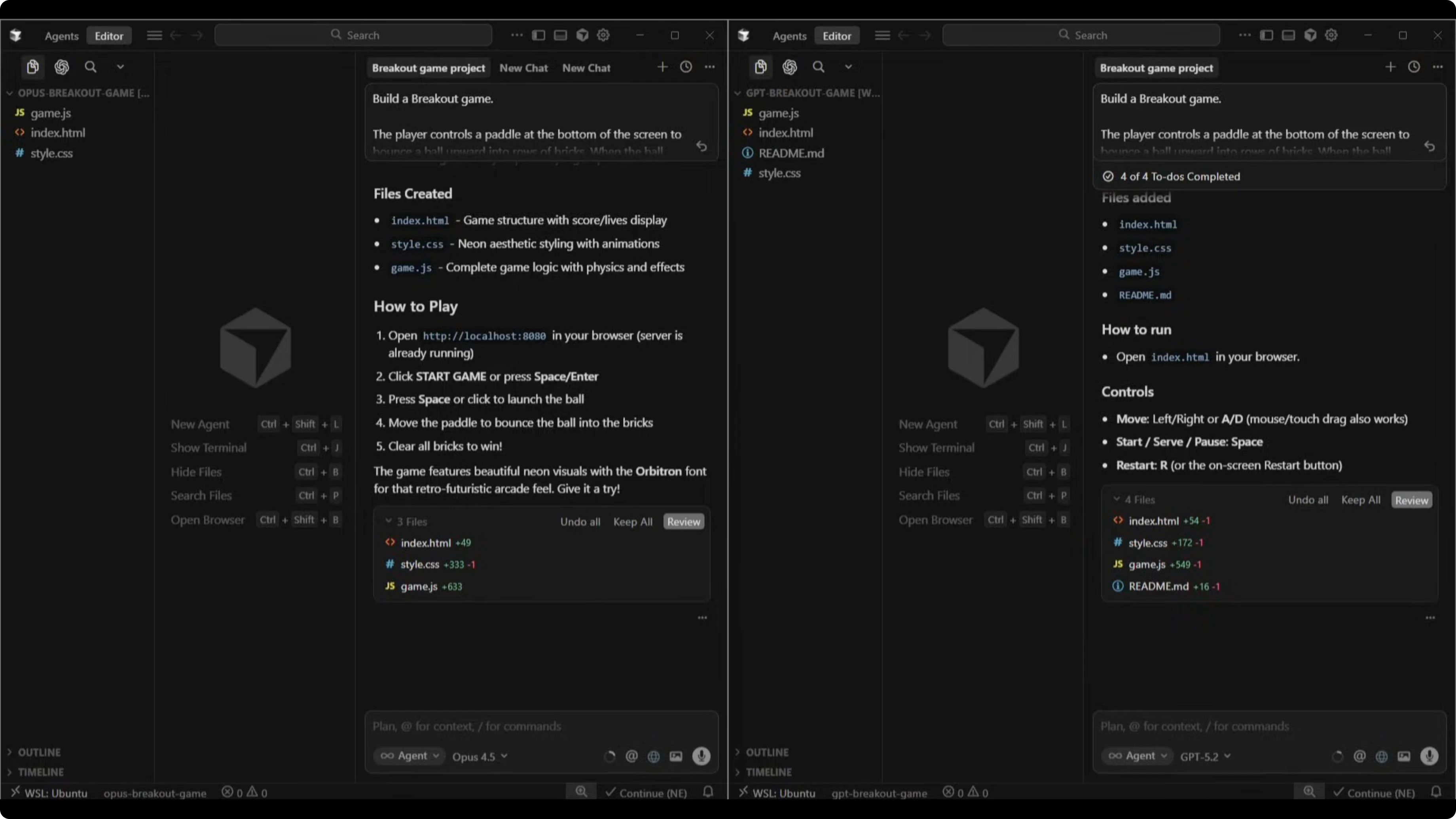
The brick layout was slightly off-center with a small gap on the left but not on the right. The ball moved faster and felt more challenging, score and lives updated correctly, and the game over screen offered a play again button. Physics and core mechanics were comparable to GPT-5.2, but the presentation clearly had more impact.
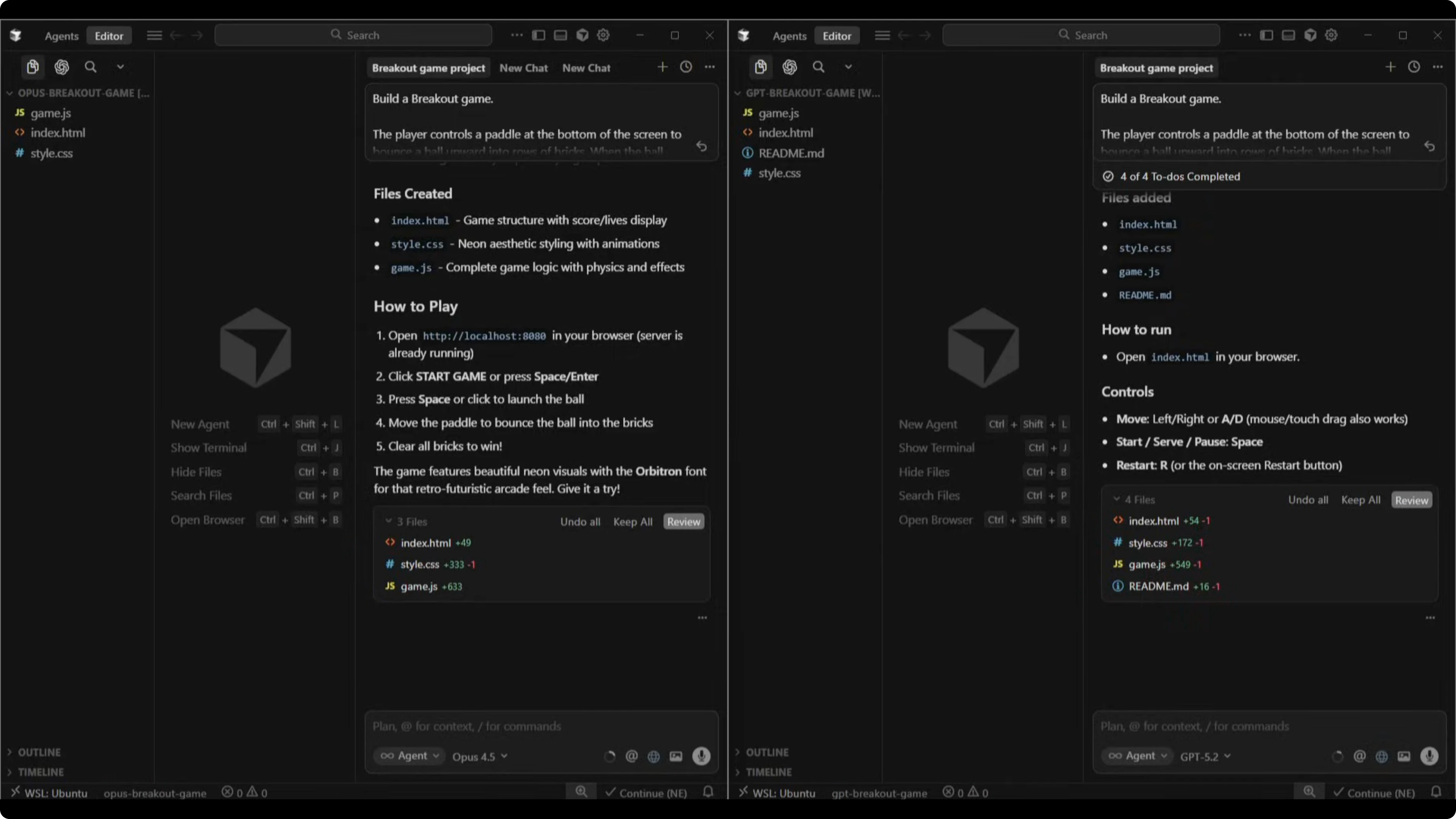
Verdict
Both games played correctly. The paddle moved, the ball bounced, bricks broke, score tracked, and lives counted down.
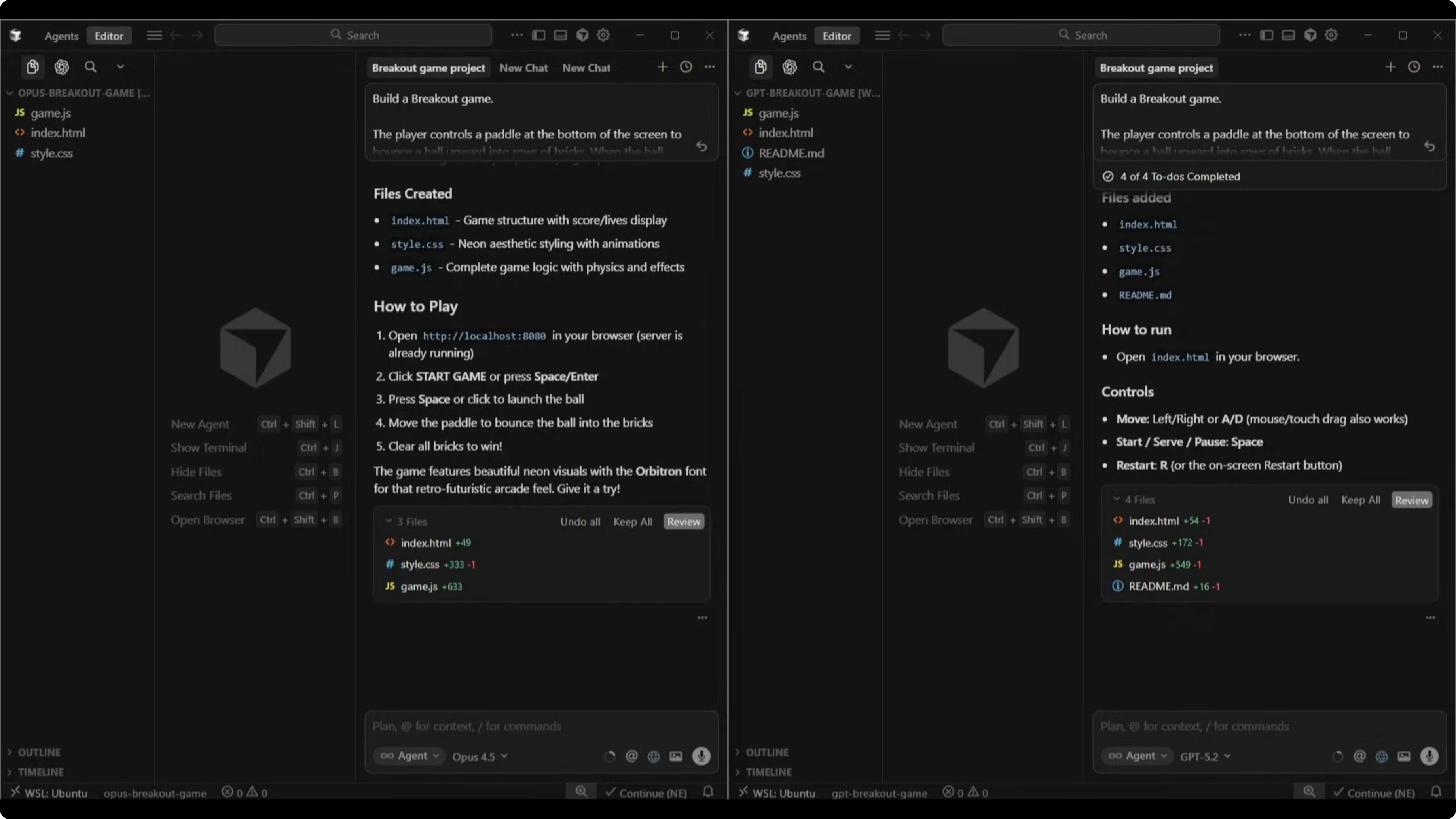
Opus 4.5 looked better with the neon retro aesthetic, while GPT-5.2 shipped faster with cleaner code. If you want more nuance on the Opus line before you decide, this comparison helps clarify model differences in that family: Opus 4.6 vs Opus 4.5.
Use cases in GPT-5.2 vs Opus 4.5
GPT-5.2 strengths and trade-offs
GPT-5.2 is significantly cheaper per token and, in the Breakout test, shipped very fast with a compact, self-contained build. It takes a methodical approach on larger tasks, planning and scaffolding, and it resolved its own Tailwind configuration issue on the way.
The trade-off is polish. The default UI read as generic and it needed a manual override on one category in the finance app, though that override feature itself is handy when you want more control.
Opus 4.5 strengths and trade-offs
Opus 4.5 shines when you need strong UI and design that looks production ready. It auto-categorized spending accurately in the finance app and shipped a brand identity and thoughtful visuals without extra nudging.
The trade-off shows up in cost and occasional debugging slowdowns, like the click detection in the game. If budget is not a concern and you want the best single-shot output on presentation, Opus remains the model to beat.
If you want a broader sense of model selection for code-heavy projects, you can browse these notes on cost and build planning across engines: project cost and build planning.
Step-by-step test guide for GPT-5.2 vs Opus 4.5
Create two empty project folders in your IDE and open them in separate sessions. Select Opus 4.5 in a high effort reasoning mode and GPT-5.2 in a medium reasoning mode.
Paste the finance app prompt exactly as specified, then run both builds and measure elapsed time. Open the resulting apps, add transactions for $300 groceries, $150 restaurants, $80 petrol, and $5,000 salary, and confirm auto categorization and health score behavior.
Note any misclassification and test a manual override to transport for petrol in the GPT-5.2 version. Record the health score values and any feedback or flags each app returns.
Paste the Breakout prompt into both models and start both builds. For GPT-5.2, open the single HTML file and play immediately, then validate paddle movement, ball bounce, brick breaking, score, and lives.
For Opus 4.5, load the game, confirm the neon-themed presentation, and check the same gameplay loop and UI elements. Record total build times, any debugging steps the model attempted, and small layout issues like the off-center brick grid.
If you want to compare costs across a broader set of engines before you run the tests, this reference helps position GPT-5.2 and Opus against another contender: GLM 4.7 against GPT-5.2 and Opus.
Final thoughts on GPT-5.2 vs Opus 4.5
Across two builds, both models delivered functional results. Opus 4.5 won the finance app with better auto categorization, stronger UI, and a quicker build time.
The Breakout game landed closer to a draw. Opus 4.5 brought stronger visuals, while GPT-5.2 shipped in under two minutes with cleaner code and a lower cost per token, making a solid case for core logic work.
If you are optimizing for cost and efficiency, use GPT-5.2 for backend logic and core features, then bring in Opus 4.5 to refine the front end and design. If budget is not a concern and you want the strongest single pass on visual quality, Opus 4.5 is still the model to beat. For a related coding-focused comparison that informs this split, you can also check this head-to-head on coding engines: coding-focused comparison.
Subscribe to our newsletter
Get the latest updates and articles directly in your inbox.

Related Posts

8 Best Claude Code Plugins in 2026 (You Need to Know)
8 Best Claude Code Plugins in 2026 (You Need to Know)

7 Best Claude Code Skills (You Need to Know)
7 Best Claude Code Skills (You Need to Know)

Claude Code Desktop IDE Features (You Need to Know)
Claude Code Desktop IDE Features (You Need to Know)