

GPT-5 Codex vs Claude Sonnet 4.5 vs Grok Code vs Composer (Speed Test)
I put four models head-to-head with the same prompt and asked each one to build a habit tracking web app. The goal was a one-shot build for each model, then a timed review and a quick functional test. The models were Claude Sonnet 4.5, Cursor Composer 1, GPT-5 Codex, and Grok Code.
Each model worked in its own isolated project folder. A Vite React scaffold was already present inside each assigned directory, and the prompt made it clear they could modify or create files only within their folder.
Setup and prompt
I used Cursor 2.0’s Agents Mode to run multiple agents in parallel, with one agent configured per model. This let me kick off all four builds at the same time and monitor progress and file changes in one place.
The build prompt opened with a clear build-phase instruction and a folder assignment, for example: you are responsible for the version located in habit-tracker-gpt5 (for the GPT-5 Codex build). The task was to build a habit tracker web app using React, with a Vite scaffold already present in the folder.
Core requirements were non-negotiable: add new habits, mark daily completion, display streaks, show an overall completion summary, and persist data using localStorage. Beyond that, I explicitly encouraged creativity and original features that would improve usefulness, design, or user experience.
Stability was the top priority. A fully working, bug-free app outranked any creative extras, and UI needed to stay clean, minimal, and responsive.
After building, each model had to produce a README with setup and run instructions and an EVAL file summarizing features, edge cases handled, performance considerations, accessibility decisions, known issues, and a short reflection on extra features or design choices.
I enforced rules to keep the process clean: do not modify or access other directories, work only within the assigned project folder, confirm current working directory and list files before building, run successfully with no errors or broken features, and prioritize clarity, stability, and maintainable code.
For a deeper model-to-model comparison on speed, cost, and output quality, see this breakdown.
Speed test: build times and code output
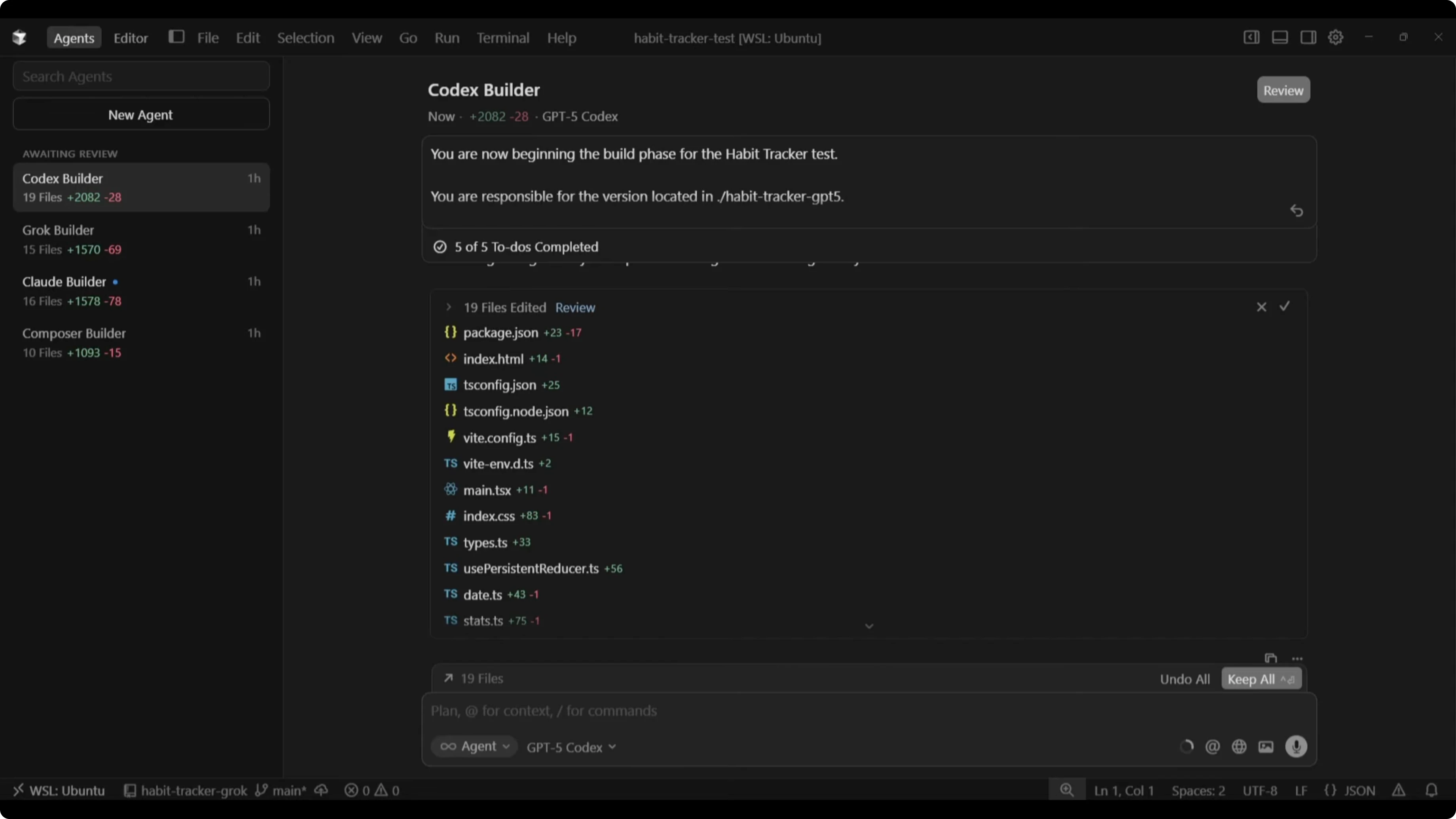
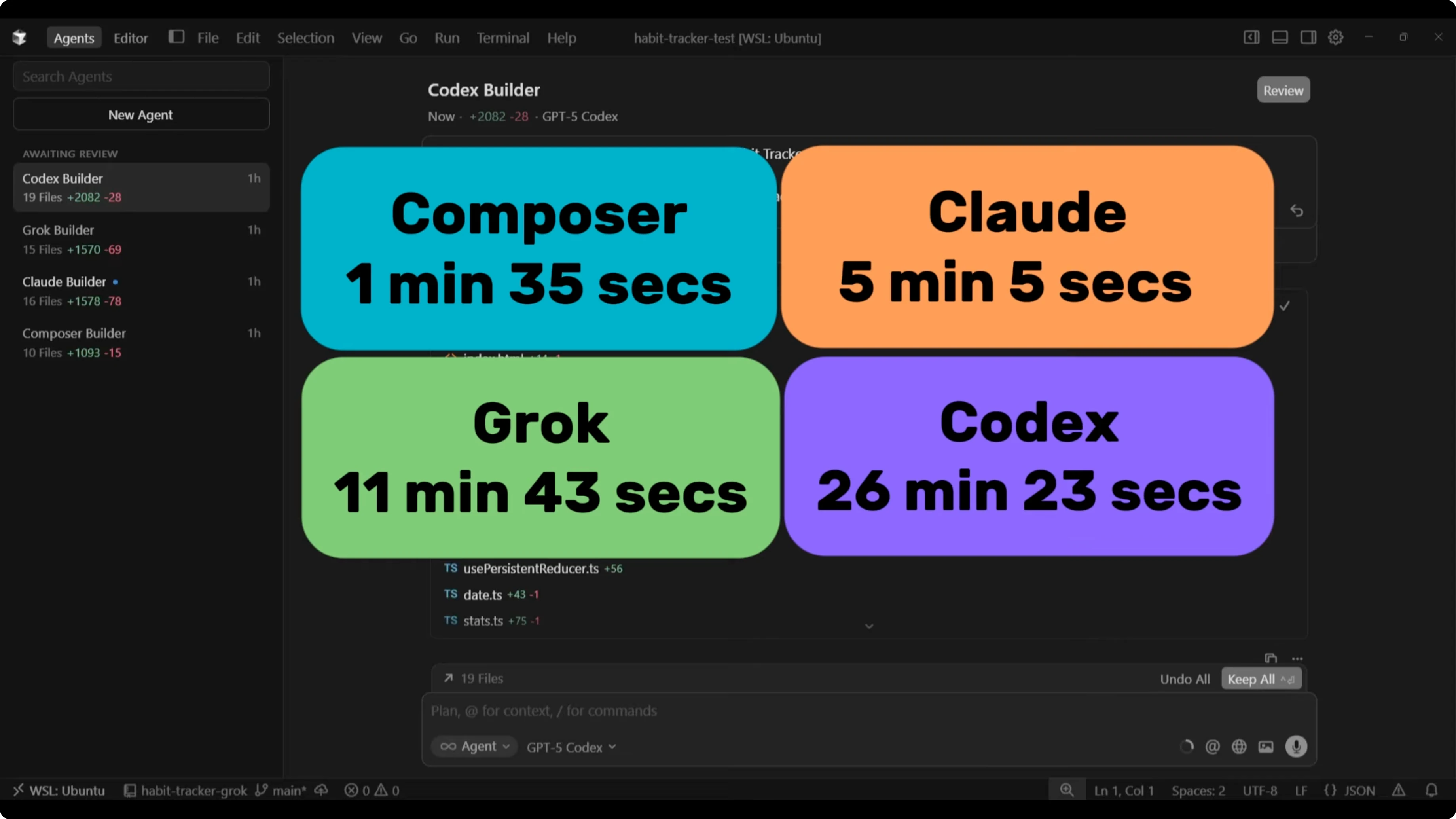
There were massive differences in completion time across the four builds. Composer finished first at 1 minute 35 seconds, Claude at 5 minutes 5 seconds, Grok at 11 minutes 43 seconds, and GPT-5 Codex at 26 minutes 23 seconds. The gap between Composer and GPT-5 Codex was huge.
Code output varied too. GPT-5 Codex produced 19 files and 282 lines of code, Grok produced 15 files and 1,570 lines of code, Claude produced 16 files and 1,578 lines of code, and Composer produced 10 files and 1,093 lines of code.
For additional context on GPT‑5 Codex and Opus trade-offs, check this comparative analysis.
GPT-5 Codex vs Claude Sonnet 4.5 vs Grok Code vs Composer (Speed Test): overview table
| Model | Build time | Files | Lines of code | Notable features observed in test | Noted issues in test |
|---|---|---|---|---|---|
| Composer 1 | 1:35 | 10 | 1,093 | Dark/light toggle, per-habit last 7 days, deletion confirm | Progress showed 700% bug, “today’s progress” tied to weekly completion, missing day labels |
| Claude Sonnet 4.5 | 5:05 | 16 | 1,578 | Motivational quotes, calendar with day labels, sort and category filters, completion popups | “Today’s progress” updated only after full 14 days on one habit, daily metric not reflecting per-day ticks |
| Grok Code | 11:43 | 15 | 1,570 | Compact calendar view, similar summary metrics to Claude | Dark mode button non-functional, formatting error on expanded calendar, “completed today” metric not updating |
| GPT-5 Codex | 26:23 | 19 | 282 | Pending UI review in this pass | Pending UI review in this pass |
Composer 1 results
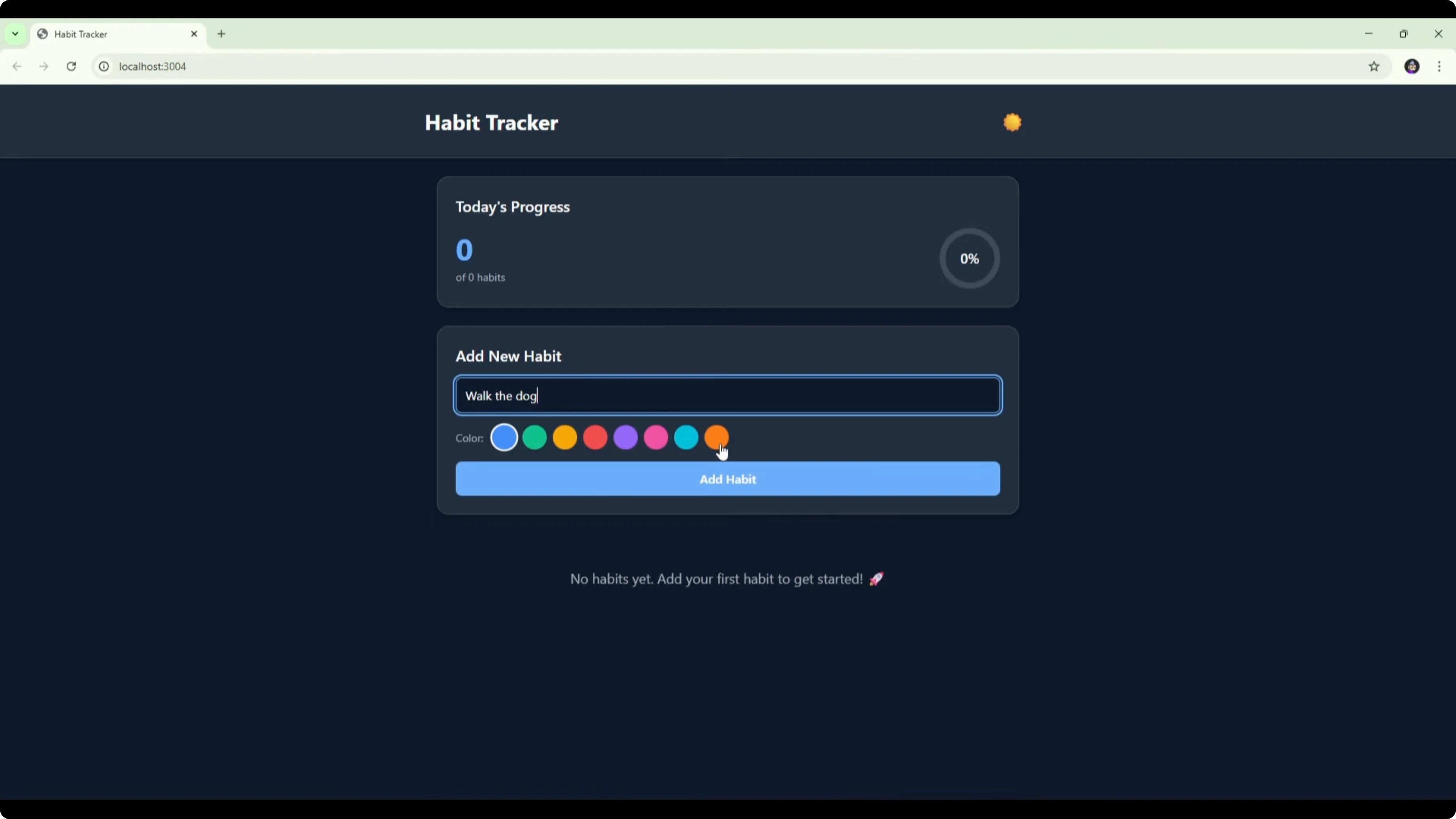
Composer’s habit tracker opened with a title, a crescent moon icon for theme toggle, a progress box, and an add-new-habit panel. The layout stated “no habits yet” and encouraged adding the first habit.
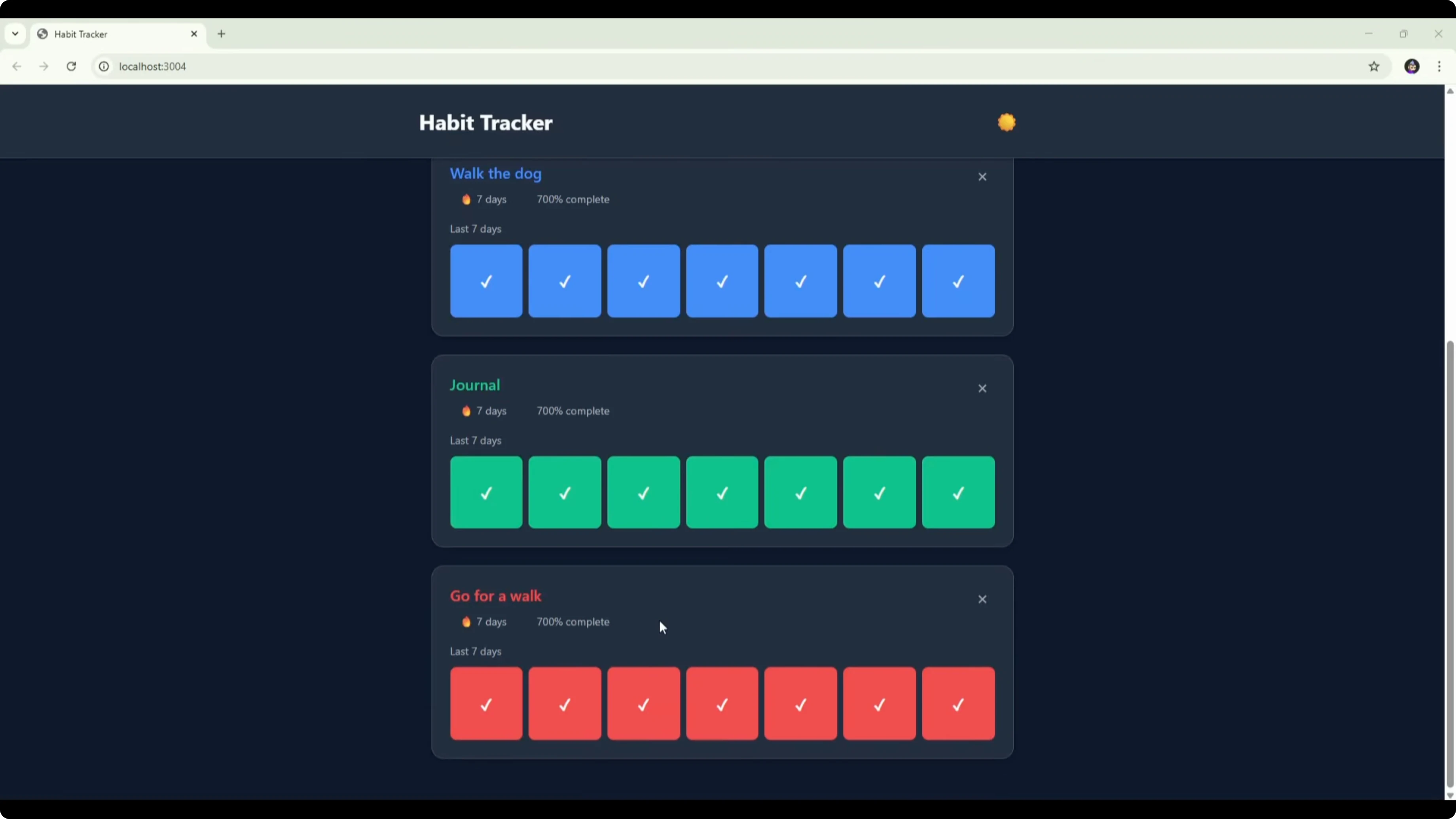
I added three habits with distinct colors, and each habit rendered its own section with a last 7 days grid. Ticking boxes updated completion, but I saw a 700% figure appear, which looked like a bug.
“Today’s progress” showed 1 of 3 only after marking a full week on a habit, which seemed incorrectly tied to weekly completion. Deleting a habit worked with a confirmation step. For a one-shot build in under two minutes, it worked, but it would benefit from day labels, a daily progress logic fix, and possibly a calendar or history view.
For more on how Codex variants compare with Opus 4.5 at larger scales, see this head-to-head on Codex Max.
Claude Sonnet 4.5 results
Claude’s interface included a title, a tagline (“Build better habits one day at a time”), and an add-new-habit flow with name, category, and color. It also surfaced a motivational quote after habit creation.
The dashboard showed today’s progress, active habits, active streaks, and a 7-day rate. A calendar had day labels and a last 14 days view, with sort options (date created, name, current streak) and category filters.
Ticking days worked and triggered a “completed” popup with an emoji, but top-level metrics did not reflect daily ticks at first. After I ticked an entire 14-day span for one habit, today’s progress finally updated and the 7-day rate showed 33% with one of three completed. The interface felt robust for a one-shot build, with a daily metric logic fix needed to reflect per-day completion.
If you also compare Claude’s newer Opus variant against 4.5, this focused review helps: Claude Opus 4.6 vs 4.5.
Grok Code results
Grok’s initial layout looked very similar to Claude’s, including the title, tagline, and add-new-habit box. A dark mode button was present but did not toggle.
Adding habits worked with a drop-down category selector and color choice. The progress calendar expanded to a longer view, though a formatting error was visible.
Summary metrics matched Claude’s structure with active habits completed today, completion rate, and longest streak. Ticking days updated completion rate, but “completed today” did not change. The compact calendar was easier to scan than Claude’s larger grid.
For broader multi-model comparisons that include Gemini 3 Pro alongside Codex and Opus, check this analysis: Gemini vs Codex vs Opus.
GPT-5 Codex status
GPT-5 Codex took the longest to complete the build at 26 minutes and 23 seconds. It generated 19 files with a total of 282 lines of code.
UI testing notes are pending in this pass, with timing and output size captured above.
Reproduce the speed test
Create a project directory with a separate folder for each model so each build remains isolated.
Ensure a Vite React scaffold already exists in every model’s folder.
Set up Cursor 2.0 Agents Mode with one agent per model and assign each agent to its corresponding folder.
Paste the build prompt, including the folder-specific responsibility line that confirms the assigned directory.
Kick off all agents in parallel to start the build phase for each model.
Wait for completion, then record build time, files created, and total lines of code.
Run each app in dev mode to validate that it launches without errors.
Add multiple habits with different colors and categories to test creation flows.
Tick through days on the calendar or last-7/14-day grids to verify daily completion, streaks, and summary metrics.
Delete a habit to test the removal workflow and confirmation UI.
Review the README and EVAL files for setup steps, features implemented, edge cases covered, performance, accessibility, known issues, and reflection on extra features.
Confirm no cross-directory access occurred and that the app behaves consistently across reloads with localStorage.
If you care about speed, cost, and output nuances beyond this single prompt test, see this resource: speed, cost, and quality breakdown.
Use cases, pros, and cons
Composer 1 fits fast prototyping when you want a working baseline in under two minutes. Pros: very fast build, fewer files, and a functional theme toggle with straightforward habit creation. Cons: incorrect percentage math, daily progress logic tied to weekly completion, and missing day labels reduce immediate clarity.
Claude Sonnet 4.5 suits richer interfaces that benefit from sorting, filtering, and motivational microcopy. Pros: day-labeled calendar, category filters, sort controls, and completion popups add polish and feedback. Cons: top-level progress metrics did not reflect per-day ticks until a full 14-day span was completed for a habit, which needs a logic fix.
Grok Code can work for teams that prefer a compact calendar with quick scanning. Pros: smaller calendar makes daily review manageable and category setup is smooth. Cons: dark mode toggle did not work, a formatting issue appeared on the expanded calendar, and “completed today” did not update even as completion rate changed.
GPT-5 Codex may aim for a leaner code surface with many small files and fewer lines of code. Pros: a small line count can be easier to navigate during maintenance and review. Cons: significantly longer build time here, and UI test notes were not captured in this pass.
For another angle on GPT‑5 and Opus matchups at different capability tiers, see this related read: Opus 4.5 vs GPT-5.1 Codex Max.
Final thoughts
Composer 1 won on speed by a huge margin and produced a usable baseline with some calculation and progress-tracking issues. Claude Sonnet 4.5 delivered the most complete feature set and a solid interface, with a daily metric bug that needs correction.
Grok Code landed in the middle on speed with a usable, compact calendar and a few UI issues that held back the summary metrics and theming. GPT-5 Codex produced the smallest total line count but took the longest to build, with interface testing still pending in this run.
If you want to compare broader families and their trade-offs across tasks, this reference can help you decide faster: in-depth Codex vs Opus.
Subscribe to our newsletter
Get the latest updates and articles directly in your inbox.

Related Posts

8 Best Claude Code Plugins in 2026 (You Need to Know)
8 Best Claude Code Plugins in 2026 (You Need to Know)

7 Best Claude Code Skills (You Need to Know)
7 Best Claude Code Skills (You Need to Know)

Claude Code Desktop IDE Features (You Need to Know)
Claude Code Desktop IDE Features (You Need to Know)