
Table Of Content
- Deepseek vs Kimi vs GLM vs Qwen vs Minimax vs Mimo: Test Design and Key Findings
- Deepseek vs Kimi vs GLM vs Qwen vs Minimax vs Mimo: Model Summaries
- Deepseek vs Kimi vs GLM vs Qwen vs Minimax vs Mimo: Execution and Setup Results
- Setup Commands Observed
- Features Breakdown: Deepseek vs Kimi vs GLM vs Qwen vs Minimax vs Mimo
- Kimi K2.6
- Qwen 3.6 Max Preview
- GLM 5.1
- MiniMax M2.7
- DeepSeek V4 Pro
- MiMo V2.5 Pro
- Pros and Cons: Deepseek vs Kimi vs GLM vs Qwen vs Minimax vs Mimo
- Kimi K2.6
- Qwen 3.6 Max Preview
- GLM 5.1
- MiniMax M2.7
- DeepSeek V4 Pro
- MiMo V2.5 Pro
- Use Cases: Where Each Option Excels
- Kimi K2.6
- Qwen 3.6 Max Preview
- GLM 5.1
- MiniMax M2.7
- DeepSeek V4 Pro
- MiMo V2.5 Pro
- Final Conclusion

Deepseek vs Kimi vs GLM vs Qwen vs Minimax vs Mimo
Qwen Model Recommender
Not sure which Qwen model fits your GPU? Pick your VRAM, use case, and task type — get matched to the right model instantly. Covers Qwen3, QwQ, QVQ, Qwen2.5-VL, Qwen3-Coder, Qwen3-TTS, and 80+ models.
Table Of Content
- Deepseek vs Kimi vs GLM vs Qwen vs Minimax vs Mimo: Test Design and Key Findings
- Deepseek vs Kimi vs GLM vs Qwen vs Minimax vs Mimo: Model Summaries
- Deepseek vs Kimi vs GLM vs Qwen vs Minimax vs Mimo: Execution and Setup Results
- Setup Commands Observed
- Features Breakdown: Deepseek vs Kimi vs GLM vs Qwen vs Minimax vs Mimo
- Kimi K2.6
- Qwen 3.6 Max Preview
- GLM 5.1
- MiniMax M2.7
- DeepSeek V4 Pro
- MiMo V2.5 Pro
- Pros and Cons: Deepseek vs Kimi vs GLM vs Qwen vs Minimax vs Mimo
- Kimi K2.6
- Qwen 3.6 Max Preview
- GLM 5.1
- MiniMax M2.7
- DeepSeek V4 Pro
- MiMo V2.5 Pro
- Use Cases: Where Each Option Excels
- Kimi K2.6
- Qwen 3.6 Max Preview
- GLM 5.1
- MiniMax M2.7
- DeepSeek V4 Pro
- MiMo V2.5 Pro
- Final Conclusion
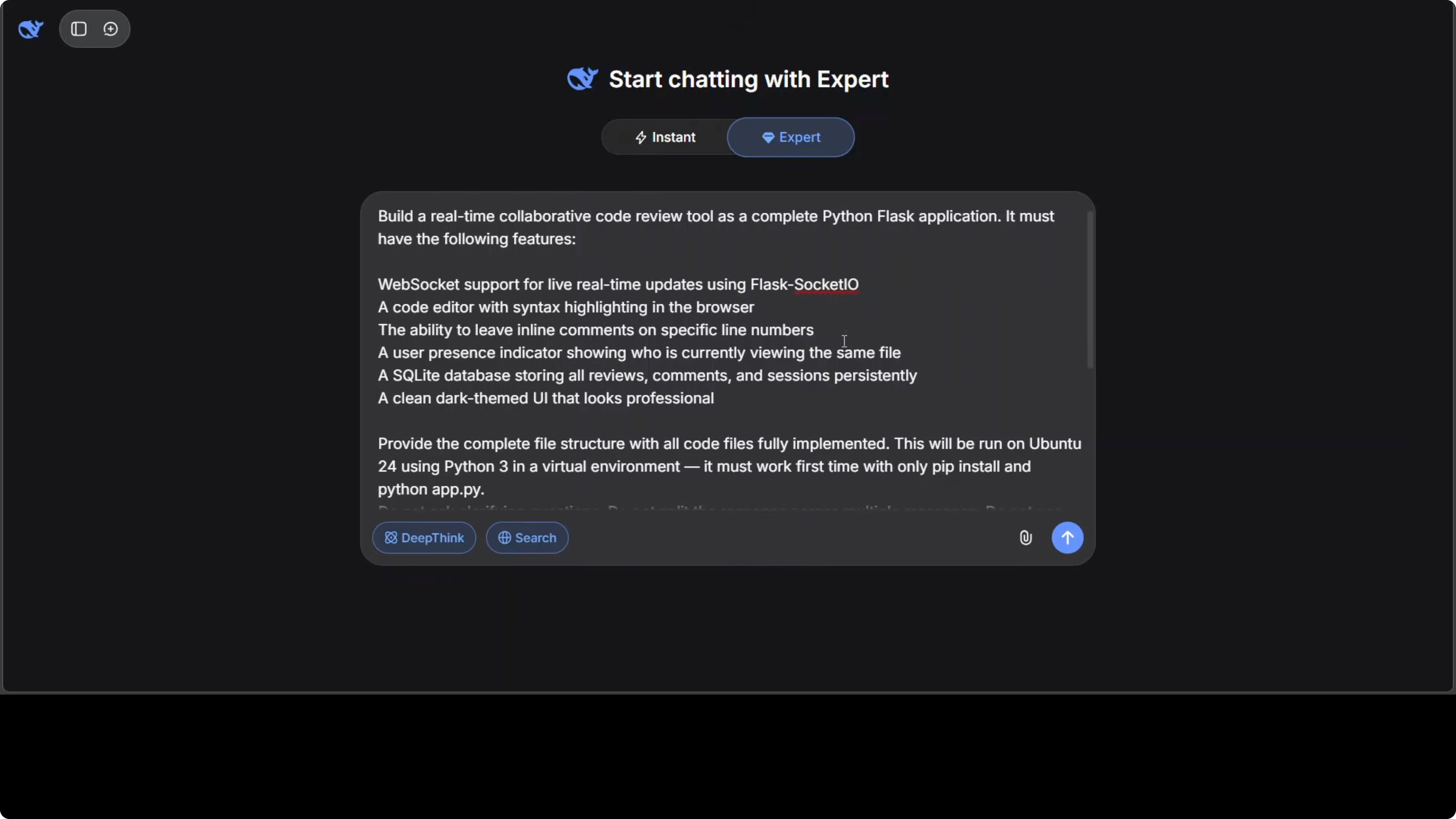
Six top Chinese AI models, six different labs, same prompts, no retries, no cherry picking. Today we find out who actually built the best AI in China. All were set to expert or thinking mode.
The single prompt was a production grade Python Flask application for a realtime collaborative code review tool. It required WebSocket support, a code editor with inline commenting, a database backed UI, and a complete file structure. We ran each output locally to see which one works and how much.
Read More: GLM 5.1 vs MiniMax M2.7 insights
| Model | Lab | Stated Specs or Claims | Setup Compliance | Local Run Outcome | Notable Behaviors |
|---|---|---|---|---|---|
| DeepSeek V4 Pro | DeepSeek | 1.6 trillion parameters, MIT licensed, Codeforces rating 3206 | Provided setup script | UI loaded but editor was not editable | Multi session did not work in first go |
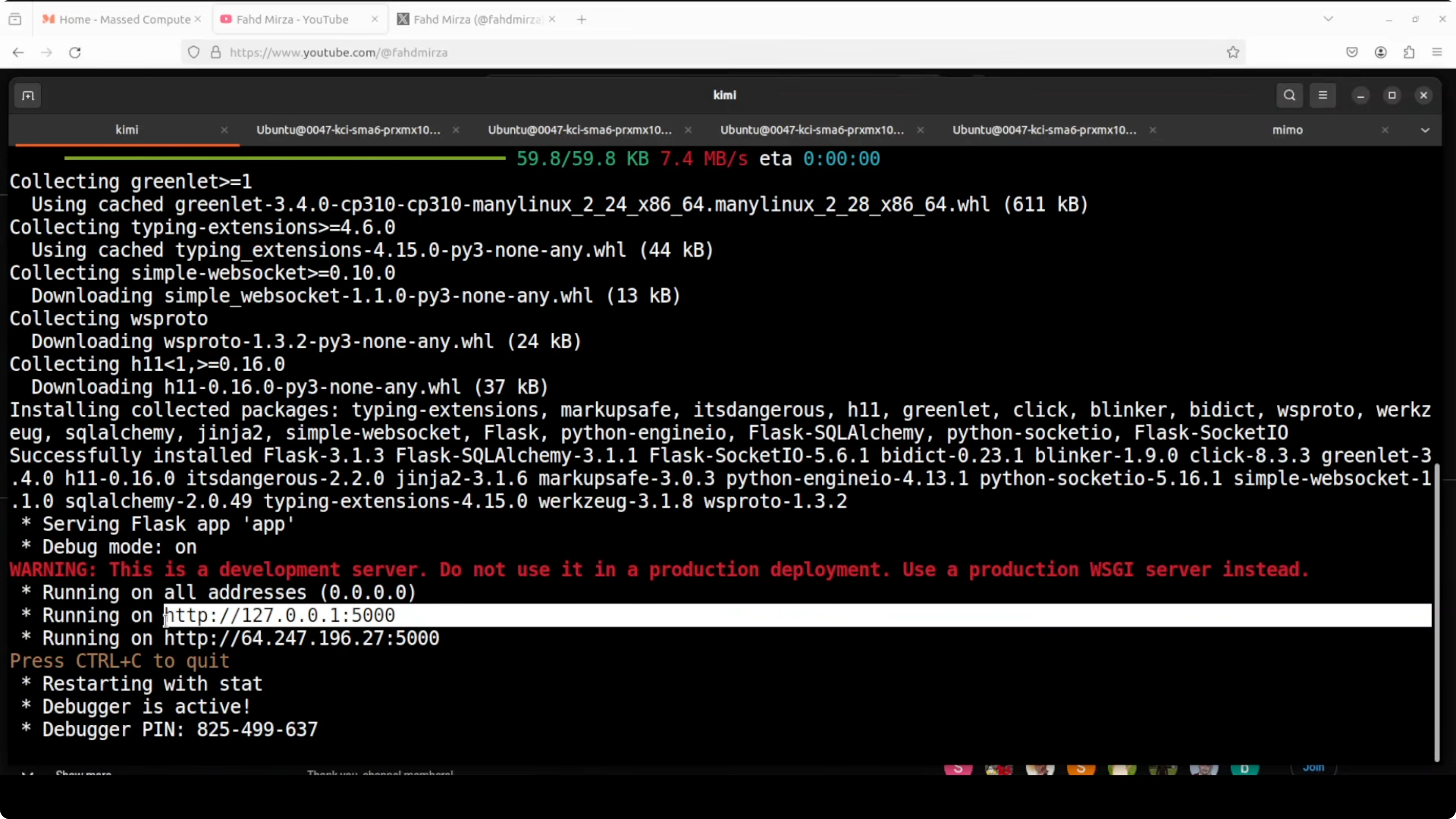
| Kimi K2.6 | Moonshot AI | 1 trillion parameter multimodal model, can spawn 300 sub agents | Provided setup.sh, installed requirements, started backend and frontend | Fully working realtime collaboration in one shot | WebSocket sync, SQLite behind the scenes, inline comments persisted |
| GLM 5.1 | Zhipu AI | Built to stay effective over thousands of tool calls, improves over long runs | Did not provide setup.sh | Syntax error on running app.py after install | Did not follow instruction to include setup.sh |
| Qwen 3.6 Max Preview | Alibaba | 1 million token context window, leads six agentic coding benchmarks | Provided setup script, created venv, installed dependencies | Worked, but sync not true realtime without refresh | Solid session management, UI controls like word wrap and comment filters |
| MiniMax M2.7 | MiniMax | First self evolving model that improved its own training process | Setup ran and UI loaded | Create review operations did not work | Multi session showed, but CRUD did not function |
| MiMo V2.5 Pro | Xiaomi | Built a compiler in 4.3 hours with 672 tool calls | Provided setup script, served on localhost | Review creation worked, comments or edit actions not available | Partial feature delivery only |
Deepseek vs Kimi vs GLM vs Qwen vs Minimax vs Mimo: Test Design and Key Findings
This prompt was not a tutorial project. It was a realtime system that required networking, database design, front end state management, and WebSocket architecture.
Kimi K2.6 delivered a complete working stack in one shot with realtime collaboration and inline comments. Qwen 3.6 Max Preview worked but needed refreshes for comment sync, with strong session handling and useful UI controls.
GLM 5.1 did not provide setup.sh and threw a syntax error at runtime. MiniMax M2.7 did not persist or display created reviews, and DeepSeek V4 Pro rendered an editor that was not editable.
Read More: DeepSeek vs Claude context and scoring
Deepseek vs Kimi vs GLM vs Qwen vs Minimax vs Mimo: Model Summaries
Kimi K2.6 from Moonshot AI is a 1 trillion parameter multimodal model that can spawn 300 sub agents. It produced a working Flask app with backend, frontend, WebSocket sync, and SQLite support in one go.
GLM 5.1 from Zhipu AI is built to stay effective over thousands of tool calls. The longer it runs, the better it gets.
Qwen 3.6 Max from Alibaba has a 1 million token context window and leads six agentic coding benchmarks. It produced a functional app with near realtime collaboration and solid controls.
MiniMax M2.7 is the first self evolving model that improved its own training process. It did not complete review creation operations in this test.
DeepSeek V4 Pro is a 1.6 trillion parameter model with an MIT license and a Codeforces rating of 3206. It did not allow editing in the loaded editor in this test.
MiMo V2.5 Pro from Xiaomi reportedly built a complete compiler in 4.3 hours using 672 tool calls. It created a review but did not offer edit or comment actions.
Read More: Kimi and Qwen in a broader coding comparison
Deepseek vs Kimi vs GLM vs Qwen vs Minimax vs Mimo: Execution and Setup Results
All models were asked to return a single setup.sh to avoid multi file manual steps. Each model also included instructions to run the app locally.
Kimi followed the instruction perfectly and automated environment creation, dependency install, and server start. Qwen followed similarly with its own venv and service launch.
GLM did not provide setup.sh and relied on a Python script that failed on syntax. MiniMax and DeepSeek provided scripts and started servers but the apps failed functional checks, while MiMo partially worked.
Setup Commands Observed
For models that complied with the one script policy:
bash setup.shFor GLM 5.1 which did not include setup.sh:
pip install -r requirements.txt
python app.pyRead More: Context on GLM family performance
Features Breakdown: Deepseek vs Kimi vs GLM vs Qwen vs Minimax vs Mimo
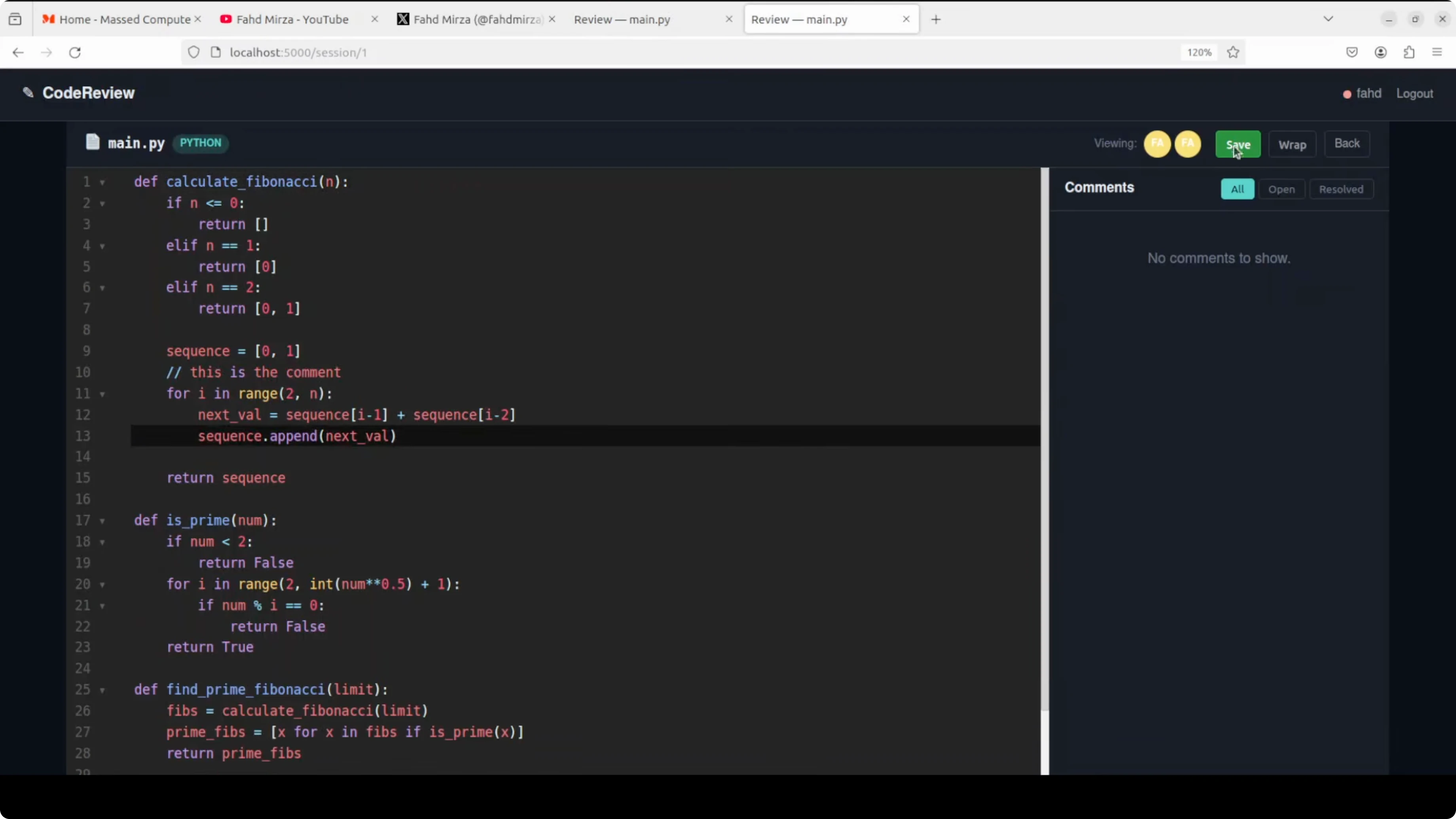
Kimi K2.6
Kimi returned a full Flask stack with backend and frontend running immediately after setup. Realtime editor sync, multi user presence, inline comments, and persisted sessions all worked.
The tool handled WebSocket events correctly and saved state to SQLite. It met the one script setup and delivered the production test.
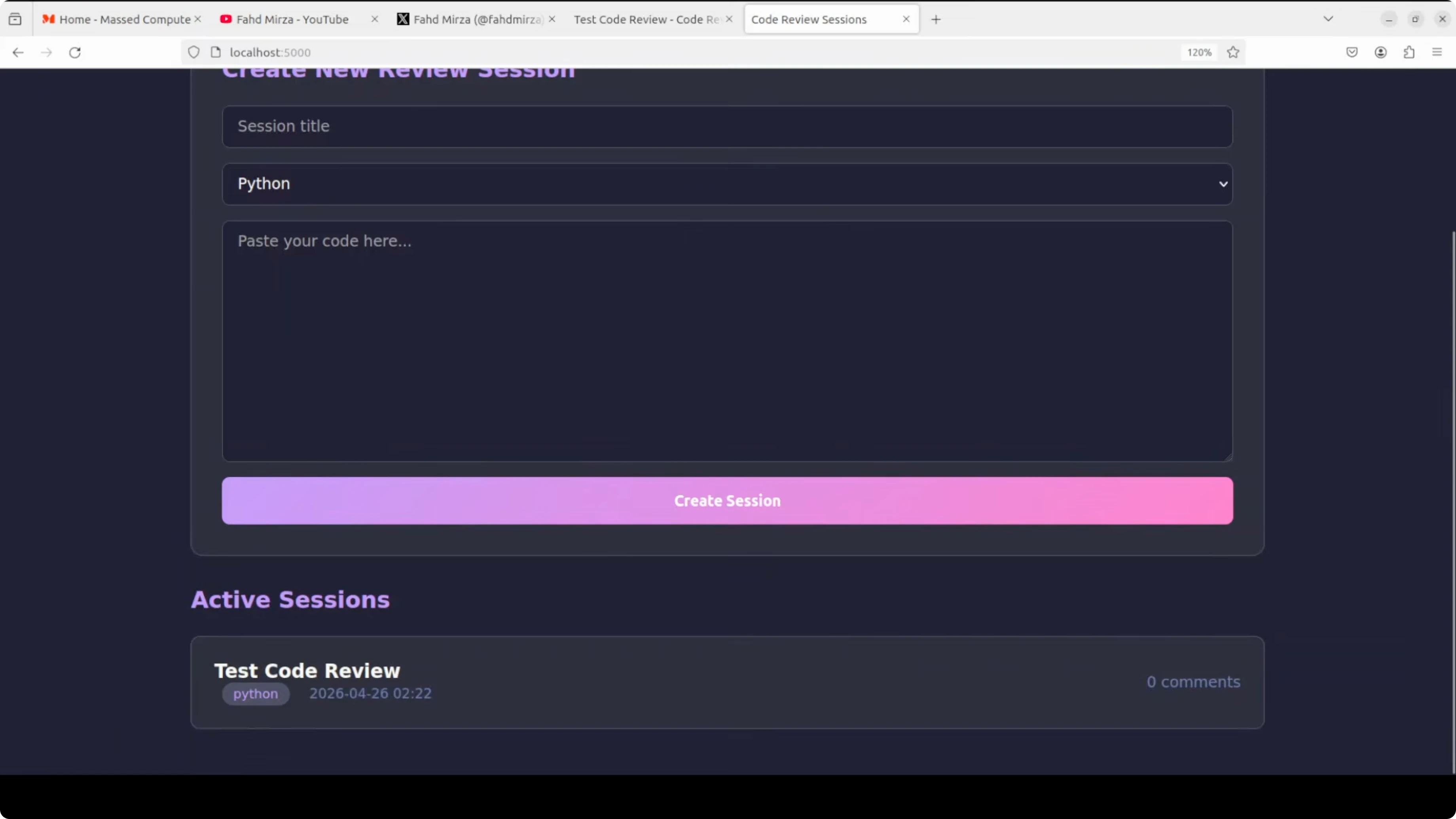
Qwen 3.6 Max Preview
Qwen built the app with a login screen, file naming, and editor. Comments appeared after a refresh and session management indicated multiple active sessions.
Controls like word wrap and comment filters worked. It was close to realtime but not fully instant in sync.
GLM 5.1
GLM skipped the setup.sh instruction. Requirements installed, but running the main script raised a syntax error.
It failed the run without manual edits. The instruction miss also counts against it.
MiniMax M2.7
MiniMax brought up a UI with review creation panels. Review creation did not persist and the reviews page stayed empty.
It did not deliver a workable CRUD path for the test. Multi session panes appeared but were not useful without saved state.
DeepSeek V4 Pro
DeepSeek served the app on localhost. The editor did not accept edits and multi session interactions were blocked by the non editable state.
It failed functional editing in first go. The rest of the UI loaded but the core action was not possible.
MiMo V2.5 Pro
MiMo set up and allowed review creation with a clean UI. Commenting or edit actions were not available or discoverable.
It delivered partial functionality without collaboration actions. The core test of inline code review did not complete.
Read More: GLM vs Opus vs GPT Codex comparison
Pros and Cons: Deepseek vs Kimi vs GLM vs Qwen vs Minimax vs Mimo
Kimi K2.6
- Pros:
- One script setup that installed and launched both backend and frontend
- Working WebSocket sync and inline comments with persistence
- Stable multi user session handling
- Cons:
- None observed in this specific test run
Qwen 3.6 Max Preview
- Pros:
- Functional app with session management and useful editor controls
- Clear UI for open or resolved comments and word wrap
- One script setup with dependency install
- Cons:
- Sync not truly realtime without manual refresh
- Slight delay in comment visibility across sessions
GLM 5.1
- Pros:
- Requirements installation was straightforward
- Cons:
- No setup.sh provided against instruction
- Syntax error on app start and no functional result
MiniMax M2.7
- Pros:
- UI panels rendered and multi session panes appeared
- Cons:
- Review creation did not persist or display
- CRUD flow failed, leaving the app non functional
DeepSeek V4 Pro
- Pros:
- Server came up on localhost and UI rendered
- Cons:
- Editor was not editable, blocking the core task
- Multi session did not help due to blocked editing
MiMo V2.5 Pro
- Pros:
- Review creation succeeded with a clean interface
- Cons:
- No editable code or inline comments available
- Collaboration actions missing
Use Cases: Where Each Option Excels
Kimi K2.6
- Realtime collaborative coding tools that require synchronous editing and inline review.
- Rapid prototyping of full stack Python apps with WebSocket communication.
- Teams that need a one shot scaffold with minimal manual setup.
Qwen 3.6 Max Preview
- Collaborative tools where near realtime sync is acceptable.
- Projects that benefit from large context windows for long files or session history.
- Teams that value clear session controls and editor options.
GLM 5.1
- Long running tool use chains where iterative calls can improve over time.
- Scenarios that can tolerate manual intervention if scripts need fixes.
- Teams exploring tool calling depth and orchestration longevity.
MiniMax M2.7
- Research settings that focus on self improvement traits of models.
- Prototyping UI shells where internal CRUD can be added later.
- Teams exploring agent style iteration patterns.
DeepSeek V4 Pro
- Benchmark heavy exploration given its Codeforces rating.
- Scenarios where UI generation can be followed by manual wiring.
- Teams that prefer to extend scaffolds rather than rely on full automation.
MiMo V2.5 Pro
- Fast build experiments where partial flows are acceptable.
- Single user review shells that can be extended with comment features.
- Tool chain tasks that rely on discrete compile or build steps.
Final Conclusion
Kimi K2.6 is the clear winner in this test, delivering a fully working realtime collaborative Flask app with one script setup and correct WebSocket plus database behavior. Qwen 3.6 Max Preview comes second with strong features and near realtime sync that required refreshes.
GLM 5.1, MiniMax M2.7, DeepSeek V4 Pro, and MiMo V2.5 Pro did not meet the production grade bar in this run. Choose Kimi if you need working collaboration out of the box, consider Qwen if you accept minor refresh gaps, and reserve the others for experiments where you plan to fix or extend code after generation.
Subscribe to our newsletter
Get the latest updates and articles directly in your inbox.

Related Posts

8 Best Claude Code Plugins in 2026 (You Need to Know)
8 Best Claude Code Plugins in 2026 (You Need to Know)

7 Best Claude Code Skills (You Need to Know)
7 Best Claude Code Skills (You Need to Know)

Claude Code Desktop IDE Features (You Need to Know)
Claude Code Desktop IDE Features (You Need to Know)