
Table Of Content
- GLM 5.1 vs MiniMax M2.7: OpenClaw Coding Challenge - Test 1: Cold code creation
- GLM 5.1 vs MiniMax M2.7: OpenClaw Coding Challenge - Test 2: COBOL-to-Python modernization
- GLM 5.1 vs MiniMax M2.7: OpenClaw Coding Challenge - Test 3: Feature addition in a FastAPI TIP
- The setup
- The prompt and expected deliverables
- GLM 5.1 output
- MiniMax M2.7 output
- Pros and Cons - GLM 5.1
- Pros and Cons - MiniMax M2.7
- Features breakdown - GLM 5.1
- Features breakdown - MiniMax M2.7
- Use cases and scenarios - GLM 5.1
- Use cases and scenarios - MiniMax M2.7
- Final Conclusion

GLM 5.1 vs MiniMax M2.7: OpenClaw Coding Challenge
OpenClaw Error Fixer
Paste any OpenClaw error and get the exact fix instantly — cause, steps, copy-ready commands, and related guides.
Table Of Content
- GLM 5.1 vs MiniMax M2.7: OpenClaw Coding Challenge - Test 1: Cold code creation
- GLM 5.1 vs MiniMax M2.7: OpenClaw Coding Challenge - Test 2: COBOL-to-Python modernization
- GLM 5.1 vs MiniMax M2.7: OpenClaw Coding Challenge - Test 3: Feature addition in a FastAPI TIP
- The setup
- The prompt and expected deliverables
- GLM 5.1 output
- MiniMax M2.7 output
- Pros and Cons - GLM 5.1
- Pros and Cons - MiniMax M2.7
- Features breakdown - GLM 5.1
- Features breakdown - MiniMax M2.7
- Use cases and scenarios - GLM 5.1
- Use cases and scenarios - MiniMax M2.7
- Final Conclusion
I planned a coding comparison between two of the most capable models available right now. GLM 5.1 from Zhipu AI and MiniMax M2.7 ran in OpenClaw on identical servers with the same repos, same environment, same everything. I ran the same prompts and let the output speak for itself.
I planned four test segments. Cold code creation, COBOL modernization, feature addition in an existing FastAPI codebase, and a bug fixing plus refactoring challenge on a purpose-built threat intelligence platform API. These are real workloads, not toy examples.
For broader multi-model context, see our roundup of large-code-model benchmarks here: deeper GLM vs Opus vs GPT comparisons.
| Category | GLM 5.1 result | MiniMax M2.7 result | Notes |
|---|---|---|---|
| Cold code creation - raw SVG world map with Bezier arc animation in vanilla JS, no libraries, sub-agent use | Slower to finish, but delivered a real-time feel with arrows streaming, accurate world map including New Zealand, live feed, responsive interactions, moving total IOCs | Finished earlier, map was okay, random selection worked, but the score range felt off, feed looked blunt, and the page lacked a real-time feel | Quality clearly favored GLM; speed favored MiniMax |
| COBOL to Python modernization - translate JSON parser module with tests | Located the repo after path correction, reviewed codebase, and started converting and refactoring promptly; after ~11 minutes it was steadily modernizing | Spent most time still reviewing, struggled to progress to implementation in the same window | I did not expect the full monorepo to be finished; GLM still won the round |
| Feature addition - FastAPI TIP: watchlists with alerts when watched IOCs turn malicious | Understood architecture, followed existing patterns, created model/repository/service/schema/routes, set up Alembic from scratch when DB was unreachable by writing a manual migration, integrated Celery alerting post-enrichment; missed an explicit old-classification guard | Implemented all layers, integrated Celery with explicit guard that old classification is not equal to malicious to avoid duplicate alerts, did full CRUD plus entry management and alert acknowledgement, wrote thorough Alembic migrations with upgrade/downgrade and FK ordering/indexing, separated alerts into their own routes and schemas, used PATCH for partial updates; token usage ~62K vs GLM ~32K | MiniMax produced a more modular, explicit implementation; GLM was faster and cheaper in tokens |
| Bug fixing and refactoring on the TIP API | Planned next | Planned next | Results not covered here |
GLM 5.1 vs MiniMax M2.7: OpenClaw Coding Challenge - Test 1: Cold code creation
The prompt drew a world map in raw SVG with no library, spun up a sub-agent, and animated Bezier arcs along paths in vanilla JS. It is hard because many models either fake it or produce a broken attempt. Both took time.
GLM took longer but delivered a live, real-time feel. The world map was accurate, including New Zealand, and arrows streamed across regions correctly. The feed felt alive, interactions were responsive, and total IOCs updated in real time.
MiniMax finished earlier and produced an okay map and random country selection. The score range was not as good as hoped, the feed felt blunt, and the page missed a real-time feel. It tried well, but there was no real comparison with GLM here.
If you want more code-heavy head-to-heads, see this focused matchup: a direct coding test between two top coders.
GLM 5.1 vs MiniMax M2.7: OpenClaw Coding Challenge - Test 2: COBOL-to-Python modernization
The task was to find, read, and fully understand a JSON parser module in a legacy COBOL codebase and translate it into clean idiomatic Python with a working test suite. No handholding and no hints. This was a codebase neither model had ever seen before.
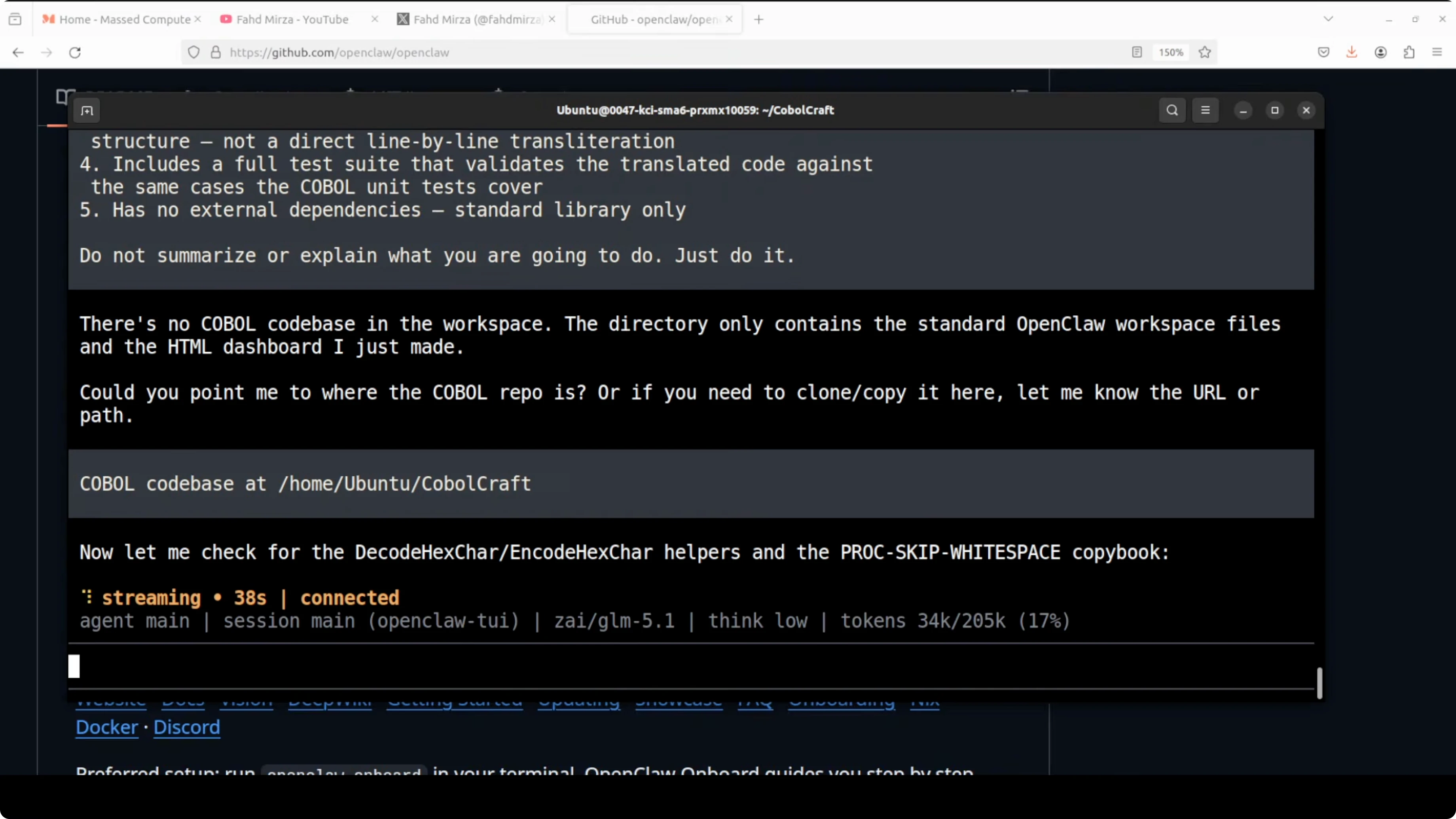
Initially, GLM could not find the repo because OpenClaw agents operate in their own working directory. I provided the full path to both models and restarted the task.
GLM started retrieving files, reviewed the codebase, and began writing Python. Around 11 minutes in, GLM was converting, refactoring, and modernizing steadily, while MiniMax was still reviewing with little forward motion.
For earlier generation benchmarks across families, check this roundup for added context: a prior GLM vs Opus vs GPT comparison.
GLM 5.1 vs MiniMax M2.7: OpenClaw Coding Challenge - Test 3: Feature addition in a FastAPI TIP
The setup
This test targeted a purpose-built threat intelligence platform API built with FastAPI, async SQLAlchemy, Redis, Celery workers, and a full IOC ingestion pipeline. Both models saw this codebase for the first time. The application was running in Docker.
The prompt and expected deliverables
Add a watchlist system where users can save IOCs to named watchlists and get automatic alerts when any watched IOC turns malicious. Full implementation across layers, aligned to the existing architecture, was expected.
GLM 5.1 output
GLM understood the full architecture and followed existing patterns correctly. It created model, repository, service, schema, and routes, and set up Alembic from scratch, writing a manual migration when it could not reach the DB. It hooked alerting correctly into the Celery task after enrichment and delivered full CRUD, entry management, and alert acknowledgement.
Coverage of the nine requirements looked complete, but there was no explicit test mention for end-to-end alerting. It also missed an explicit guard comparing old and new classifications to suppress duplicate alerts. Token usage was around 32K.
For another architecture-aware evaluation with different systems, see this related analysis: a look at composer-style orchestration vs code-focused models.
MiniMax M2.7 output
MiniMax also produced a complete implementation across model, repository, service, schema, and routes. It integrated Celery for alerting with an explicit guard that old classification is not equal to malicious, which is the correct protection against duplicates.
It wrote Alembic migrations with upgrade and downgrade, careful foreign key ordering, and indexing, which felt more thorough than GLM’s handwritten migration. It separated alerts into their own route file and schema, used PATCH for partial updates, and delivered a clean separation of concerns.
MiniMax consumed roughly 62K tokens to explore the codebase more thoroughly before writing. It took longer than GLM but produced a more modular, explicit implementation.
For more cross-family comparisons that stress different strengths, explore this match-up: contrast on reasoning-heavy tasks.
Pros and Cons - GLM 5.1
-
Pros:
- Higher quality in cold code creation with accurate raw SVG and convincing real-time behavior.
- Strong at rapidly understanding large unfamiliar repos and starting modernization work quickly.
- Lower token usage in the FastAPI feature test while still delivering end-to-end functionality.
-
Cons:
- Slower on the raw SVG task compared to MiniMax, though quality was higher.
- Handwritten Alembic migration was less explicit and thorough than a full scripted migration.
- Missed an explicit old vs new classification guard to prevent duplicate alerts.
Pros and Cons - MiniMax M2.7
-
Pros:
- Faster initial completion in the cold code task, even if quality lagged behind.
- Thorough exploration of the FastAPI codebase that led to cleaner modularity and explicit migrations.
- Correct guard against duplicate alerts, proper use of PATCH, and good separation of alerts into their own routes and schemas.
-
Cons:
- Cold code creation output had a weaker real-time feel and blunter feed presentation.
- Struggled to move past review into implementation during the COBOL modernization window.
- Higher token usage in the FastAPI test, making it potentially more expensive.
For more head-to-heads across model families at various sizes, see this reference set: GLM vs Opus vs GPT under coding workloads.
Features breakdown - GLM 5.1
-
Cold code creation:
- Accurate world map in raw SVG with convincing real-time animations and live feed.
- Sub-agent orchestration behaved correctly under OpenClaw.
-
Legacy modernization:
- Quickly shifted from repo discovery to conversion and refactoring.
- Showed strong momentum even in a large legacy codebase.
-
FastAPI feature addition:
- Followed existing architectural patterns across layers.
- Implemented Celery alerting and full CRUD with entry management and acknowledgement.
- Wrote a manual Alembic migration when DB access was blocked.
Features breakdown - MiniMax M2.7
-
Cold code creation:
- Faster initial completion with acceptable SVG output and random selection logic.
- Lacked the live, real-time feel and polish in scoring and feed.
-
Legacy modernization:
- Spent more time reviewing and did not progress as far in the same timeframe.
-
FastAPI feature addition:
- More explicit migrations with upgrade/downgrade, FK ordering, and indexing.
- Clear modularity with separate alerts routes and schemas and correct PATCH semantics.
- Guard to avoid duplicate alerts by comparing old vs new classifications.
Use cases and scenarios - GLM 5.1
- You need high-fidelity cold code creation that looks and feels live, with accurate rendering and interactive behavior. GLM’s SVG output quality and responsiveness stood out.
- You have to move a legacy module into modern Python and want fast momentum from analysis to implementation. GLM pushed forward quickly here.
- You want a complete feature addition with lower token cost and rapid turnaround, accepting that some guards or migration details may need a second pass.
Use cases and scenarios - MiniMax M2.7
- You need a thoroughly engineered feature addition in a modern API with migrations, guards, and modular separation dialed in. MiniMax’s watchlist and alerts design felt very clean.
- You can afford higher token usage and extra time up front to get clearer migrations and route organization. The end result is neat and explicit.
- You value guardrails against duplicate alerts and correct HTTP semantics like PATCH for partial updates.
For another style of multi-model comparison with reasoning-oriented tasks, check this contrast: a reasoning-focused benchmark.
Final Conclusion
Cold code creation was a clear GLM 5.1 win on quality, even though it ran slower. COBOL modernization also went to GLM because it moved beyond review into refactoring and conversion rapidly.
Feature addition in FastAPI favored MiniMax M2.7 thanks to explicit Alembic migrations, modular routes and schemas, correct PATCH semantics, and a proper duplicate-alert guard. MiniMax traded more tokens and time for a cleaner architectural result.
Choose GLM 5.1 for higher-fidelity cold code creation and fast momentum on legacy modernization. Choose MiniMax M2.7 for meticulous feature work in modern backends where migration rigor, guards, and modularity matter more than speed or token cost.
Subscribe to our newsletter
Get the latest updates and articles directly in your inbox.

Related Posts

8 Best Claude Code Plugins in 2026 (You Need to Know)
8 Best Claude Code Plugins in 2026 (You Need to Know)

7 Best Claude Code Skills (You Need to Know)
7 Best Claude Code Skills (You Need to Know)

Claude Code Desktop IDE Features (You Need to Know)
Claude Code Desktop IDE Features (You Need to Know)