

Zaya1 8B by Zyphra: Efficient Local Intelligence Run
Zyphra just released Zaya1 8B. The lab was active last year with models like Zonos and ZR1, went quiet, and now returns with a new open-source model. It is the first model at this performance level trained entirely on AMD hardware.
The model takes a very specific approach. It is an 8.4 billion parameter mixture of experts with only 760 million active parameters per token. The stated goal is to squeeze maximum intelligence out of minimum parameters, and the early results are impressive.
Zaya1 8B by Zyphra overview
This is a mixture of experts model, not a dense one. A router activates a small subset of specialist experts for each token rather than using everything at once. That is how the active parameter count stays low while the total parameter count is large.
Training was done on AMD accelerators end to end. That point alone makes it stand out, and the performance numbers make a strong case.
Benchmarks and comparisons for Zaya1 8B by Zyphra
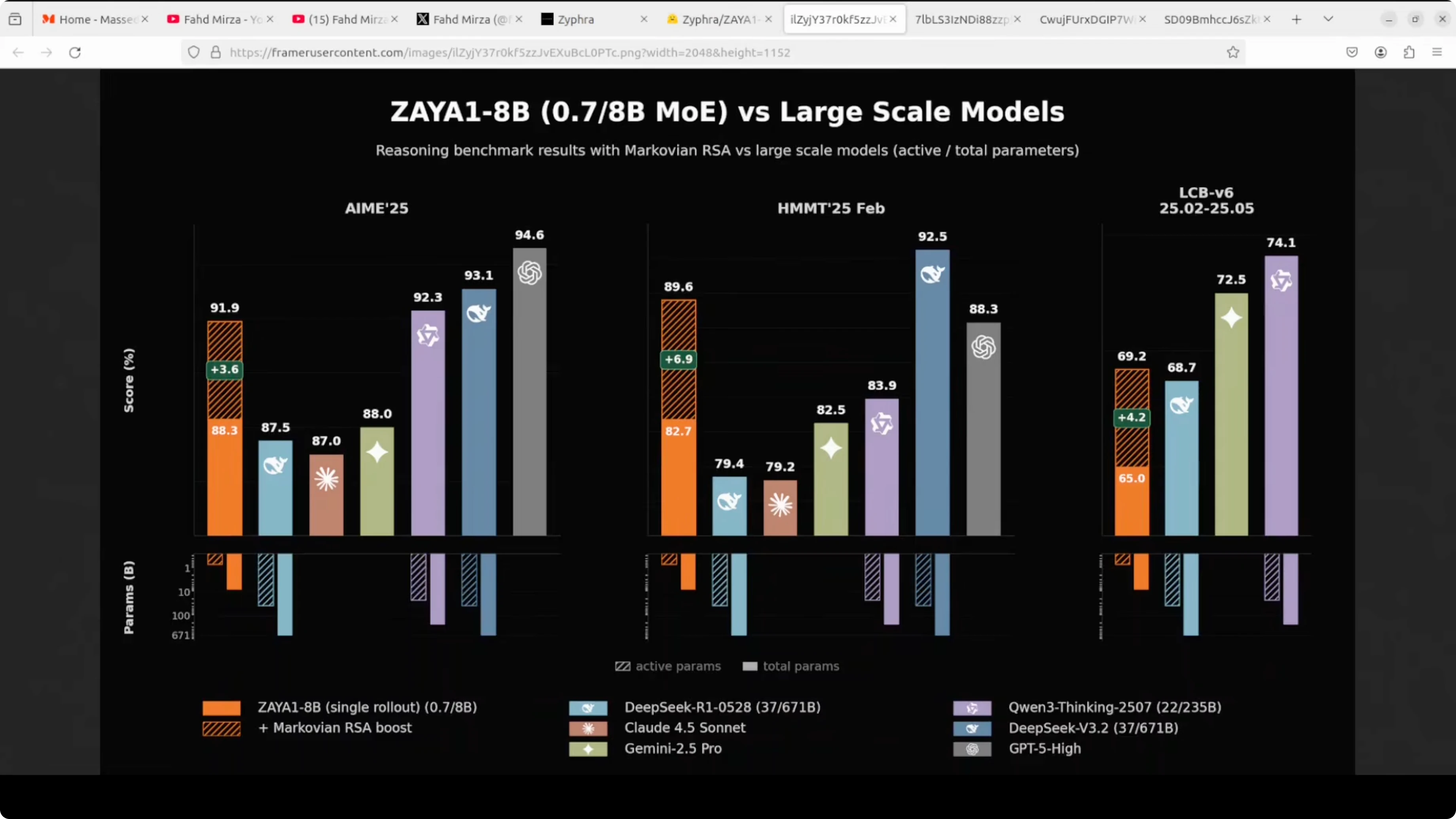
On large scale comparisons, Zaya1 8B with its Marovian RSA boost beats Claude 4.5 Sonnet and Gemini 2.5 Pro on hard tasks. Remember, we are comparing an 8 billion parameter model with only 760 million active parameters. It stays competitive with DeepSeek R1 and really comes close to GPT5, which is remarkable.
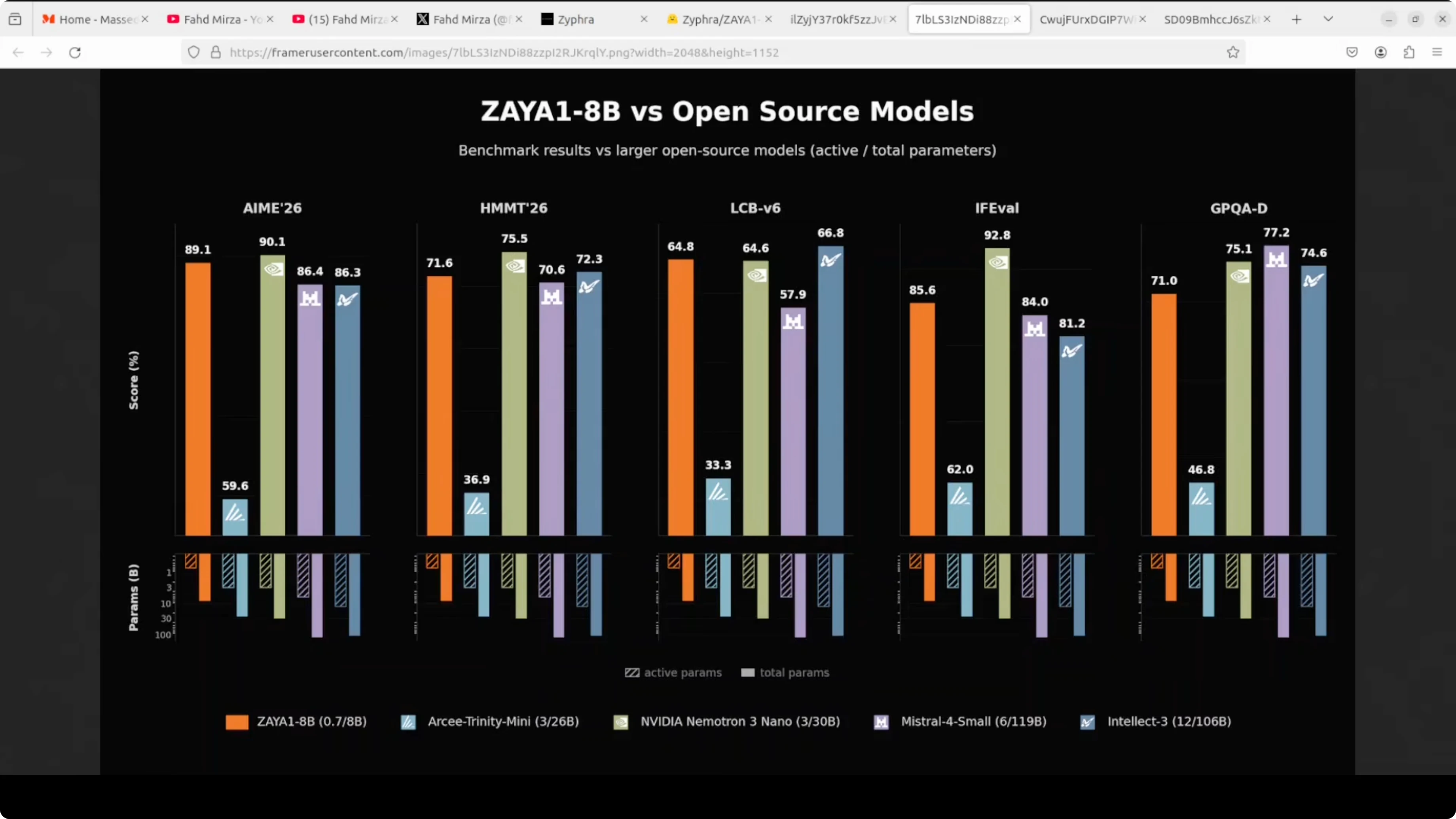
Against open-source models, it has beaten Acriity Mini and Mistral Small on most benchmarks. It gets beaten by NVIDIA Nemotron-3 Nano on a few tasks. The standout story is that an 8 billion total parameter model is competing with 100 billion plus models on hard tasks.
If you are exploring compact local models too, you can compare approaches in this practical guide to running Minimax M21 locally.
Read More: How To Run Z Image Turbo On Google Colab
Install Zaya1 8B by Zyphra locally
I used vLLM to serve the model. My machine is Ubuntu with an NVIDIA RTX 6000 GPU and 48 GB of VRAM, and the model consumed about 47 GB when fully loaded.
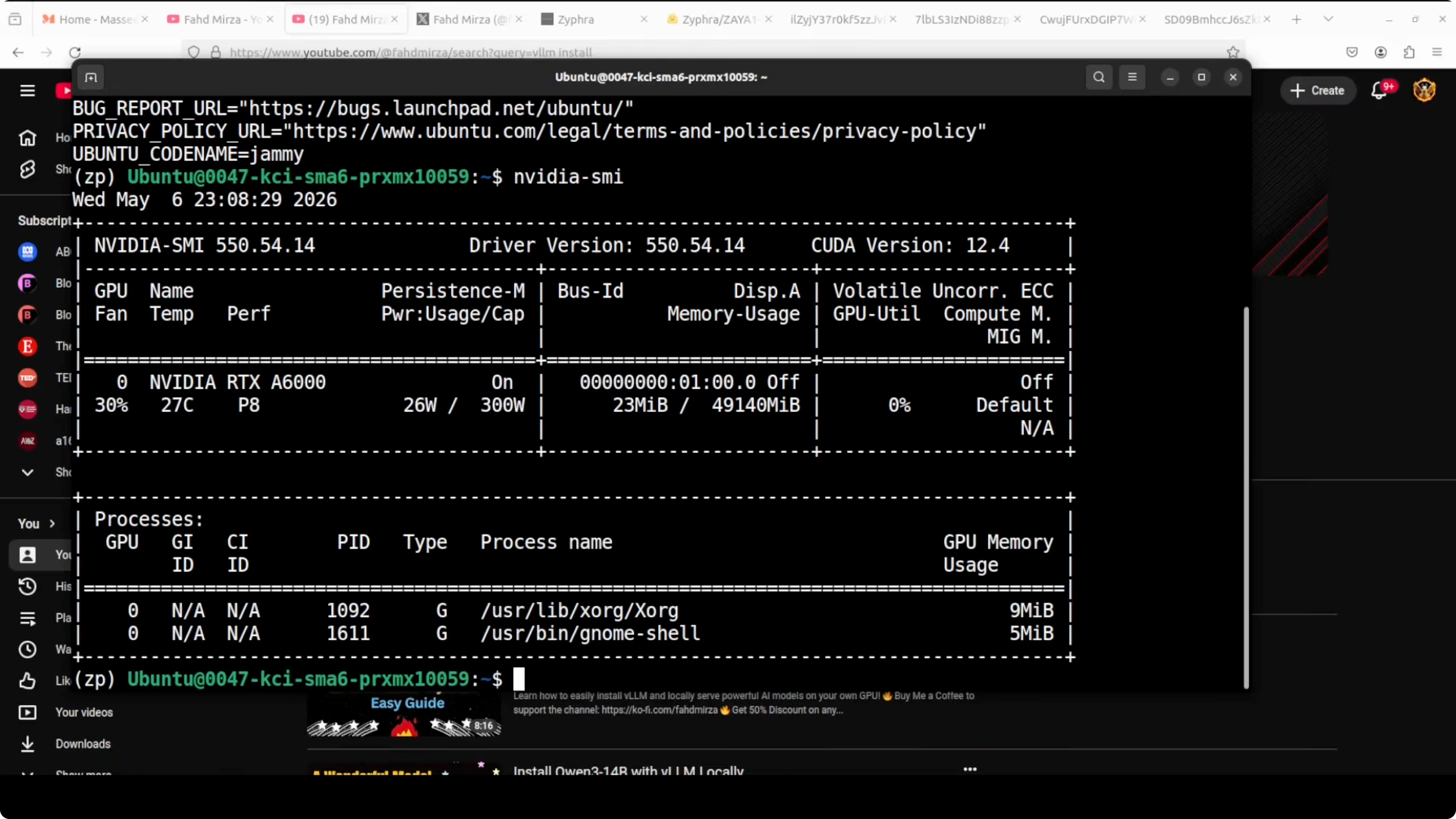
Install vLLM if you do not have it:
pip install -U vllmServe the model with vLLM. Replace the model path with the correct Zaya1 8B repository or local path you downloaded:
vllm serve --model <path-or-repo-for-zaya1-8b>Open WebUI connected to vLLM made testing easier. Once the server reports it is ready, load it in your preferred chat UI and confirm memory use aligns with your GPU capacity.
If you want a lighter alternative for local serving and experiments, see this step-by-step on using Ollama as a free local AI assistant.
Reasoning test with Zaya1 8B by Zyphra
I started with a challenging multi-step prompt that mimics an aviation emergency over East Java. The aircraft is at 35,000 ft near Mount Semeru, with an ash cloud expanding radially at 35 knots. The task asked for ash cloud arrival time, corrected heading to Bali, fuel sufficiency, and immediate recommendation.
The goal was to see if it can handle geometry, wind drift, fuel burn rate, and time calculations all at once. The model was quick and felt focused once fully loaded on the GPU. It correctly handled fuel calculation, wind vector math, and the ash cloud timing of 80 minutes.
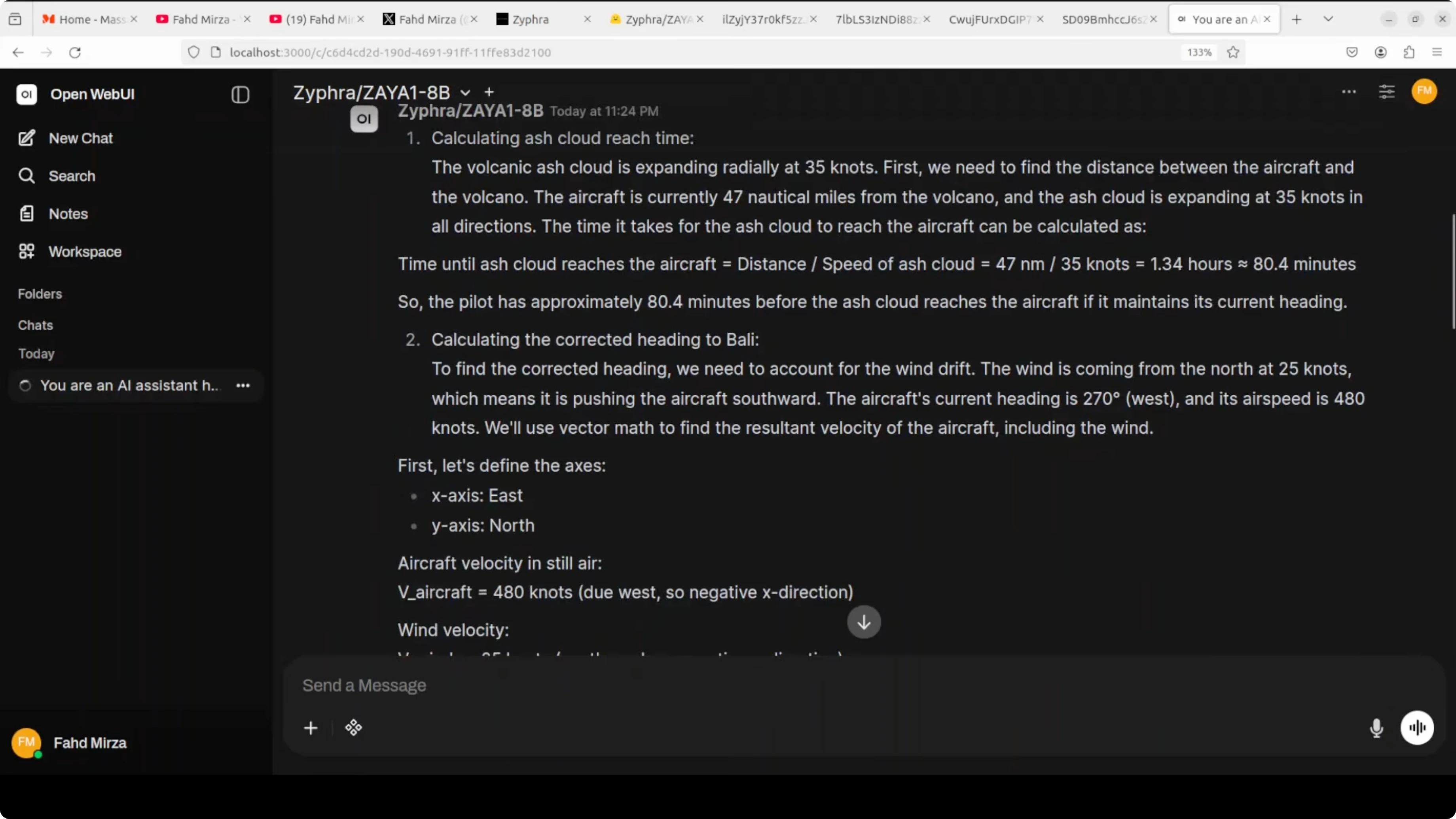
The aircraft is stationary relative to the ash in the sense that you do not sum velocities directly, and the timing reflected that. There was one clear mistake in the heading. It calculated 183 degrees instead of about 228 degrees to Bali, likely confusing wind correction angle with bearing.
Overall, it showed strong reasoning under constraints and produced a structured response with only that navigation error. For a compact model with low active parameters, that level of multi-step handling is encouraging.
Architecture of Zaya1 8B by Zyphra
Think of Zaya1 8B as an assembly line where your text goes in at the bottom, passes through stacked processing stations, and a predicted token comes out at the top. The key innovation is a CCA block that improves how attention is paid to words in context. Then a router decides which of 16 specialist expert modules should handle the input rather than using all of them every time.
That routing is what keeps active parameters to 760 million while the total is 8.4 billion. It is a design that supports efficiency without running all experts at once. That is a major contributor to the model’s performance profile.
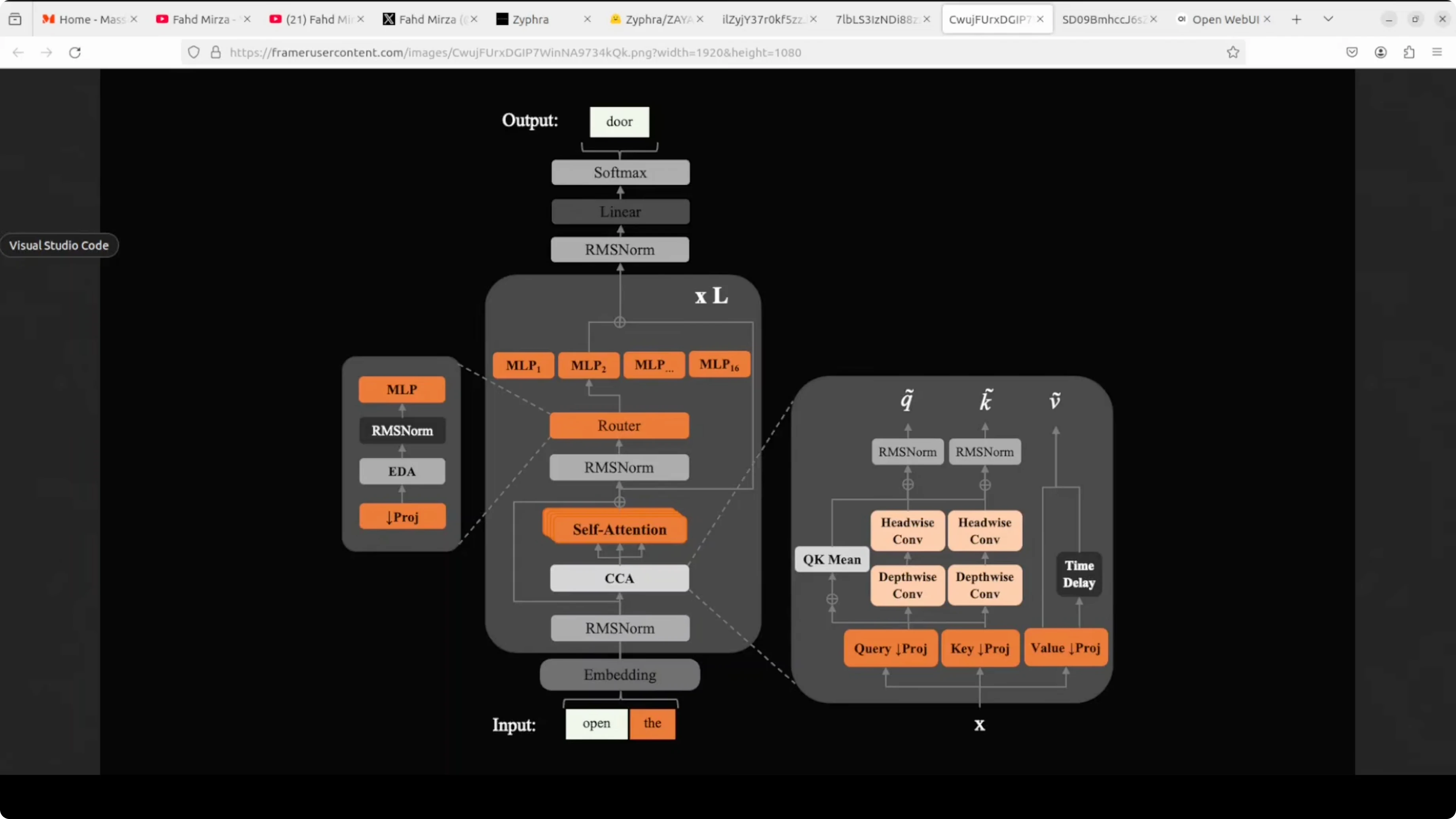
Zyphra also mentions a reasoning boost they call Marovian RSA. Imagine giving the same hard math or coding problem to multiple students at once, collecting only their final conclusions, then handing new students the question plus a few of those conclusions as hints. The process repeats while keeping the context window fixed, because only the tails of the reasoning traces are carried forward, not the entire traces.
This is the essence of Marovian RSA and it is what gives Zaya1 8B a big lift on hard math problems. It fits the result patterns I saw on the aviation test and the coding task. If you want to adapt similar reasoning-first workflows to another family, here is a practical reference on fine-tuning Qwen 3.5 8B locally.
Coding test with Zaya1 8B by Zyphra
The next test was a coding prompt to build a real-time collaborative code editor with Python and FastAPI. Requirements included a WebSocket server, session state management, front end integration, and broadcast updates in real time. The model took about four minutes and produced code that covered all components, plus a list of dependencies and run steps.
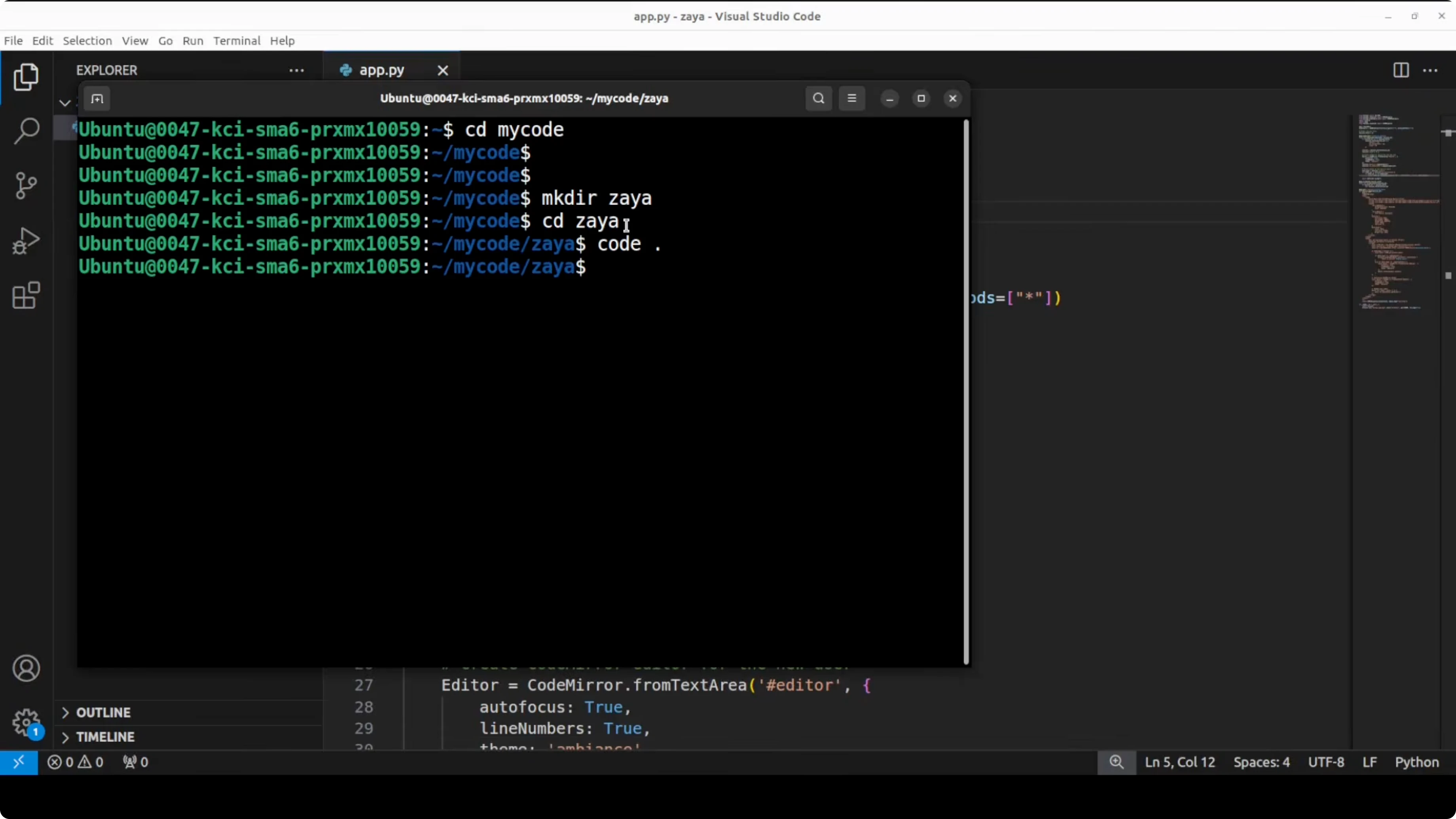
I pasted the generated code into app.py, created a new directory, and opened it in VS Code. Install the dependencies as suggested by the response, then run the server:
pip install fastapi uvicorn websockets
uvicorn app:app --reloadI opened two separate browser windows to simulate two users. Both joined the same session using a session ID in the URL, for example 4123. Whatever one user typed appeared instantly in the other window over WebSockets, and a new isolated session like 125 stayed independent.
The code ran without issues and achieved correct bidirectional sync. That confirms the model can architect and implement a multi-component system from a single prompt. Its coding capabilities are solid.
Final thoughts on Zaya1 8B by Zyphra
Zaya1 8B is a compact reasoning-first model with strong math and coding skills and a unique AMD training story. The mixture of experts design with a smart router and the Marovian RSA approach produce results that punch far above the active parameter count. I am impressed by the speed, the targeted thinking, and the quality of code it generates.
If you enjoy building creative local apps with small models, you might also like this hands-on project for a local AI music generator.
Subscribe to our newsletter
Get the latest updates and articles directly in your inbox.

Related Posts

8 Best Claude Code Plugins in 2026 (You Need to Know)
8 Best Claude Code Plugins in 2026 (You Need to Know)

7 Best Claude Code Skills (You Need to Know)
7 Best Claude Code Skills (You Need to Know)

Claude Code Desktop IDE Features (You Need to Know)
Claude Code Desktop IDE Features (You Need to Know)