

How to Run Uncensored MiniMax M2.1 on CPU Locally?
I installed and ran the uncensored MiniMax M2.1 variant locally on CPU and documented the setup, the performance you can expect with different quants, and what the outputs look like. I’ll also touch on responsible use for research and red teaming.
What is MiniMax Prism?
We already checked out the MiniMax model. The model is great. It’s awesome. Someone removed some of the refusal layers, and that is how this MiniMax Prism came into being. This is an uncensored derivative of the model. It is open source, modified using a technique called PRISM, which stands for projected refusal isolation via subspace modification.
As we know, MiniMax M2.1 is a 229 billion parameter mixture of experts model with 256 experts, activating eight per token, designed for agentic tasks including coding, tool use, multi-step reasoning, and multilingual applications.
The PRISM methodology used to create this uncensored version represents an obliteration technique that surgically removes safety refusal behaviors from the model’s weight space while preserving and reportedly even enhancing its core capabilities. If you want the model to be very creative, this could be a good way. I have shown the obliteration process before for research and development purposes. If you are doing red teaming, this is a good option to test. This could be another feature in your security tooling to make sure the model you use in production is not an uncensored or obliterated one.
Why I’m Running It on CPU
I’m using llama.cpp to run this model locally on CPU. Through llama.cpp, you can run models on different runtimes and platforms. It’s a very fast inference engine and quite performant.

I already have llama.cpp installed on my system, so I’m not covering installation here. The next step is to get the model in the correct format.
My System Setup
- OS: Ubuntu
- GPU present but not used: Nvidia H100 with 80 GB VRAM
- CPU: beefy, but the test intentionally ran on CPU
I intentionally did not match the CUDA version with the GPU to force CPU-only inference.
Model loading on CPU takes around 30 to 60 seconds, sometimes a minute.
Quantization Choices and File Sizes
I ran with the smallest quant:
- IQ1_S: 46.5 GB
There is also a larger option:
- IQ4: 129 GB
I would love to run the 129 GB IQ4, but I didn’t have that much headroom for this CPU-only test. I started the download locally while testing the smaller one.
Run Uncensored MiniMax M2.1 on CPU Locally?
Step-by-step
- Install llama.cpp.
- Download the quantized MiniMax Prism model:
- Start with IQ1_S (46.5 GB) if you want to ensure it fits in CPU RAM.
- Try IQ4 (129 GB) if your memory allows.
- Save the model in a local directory.
- Launch llama.cpp with the chosen quant.
- Force CPU-only if needed by not enabling CUDA. I intentionally mismatched CUDA so nothing would touch the GPU.
- Expect model load times of 30 to 60 seconds on CPU.
Prompt Test and Observations
Prompt used:
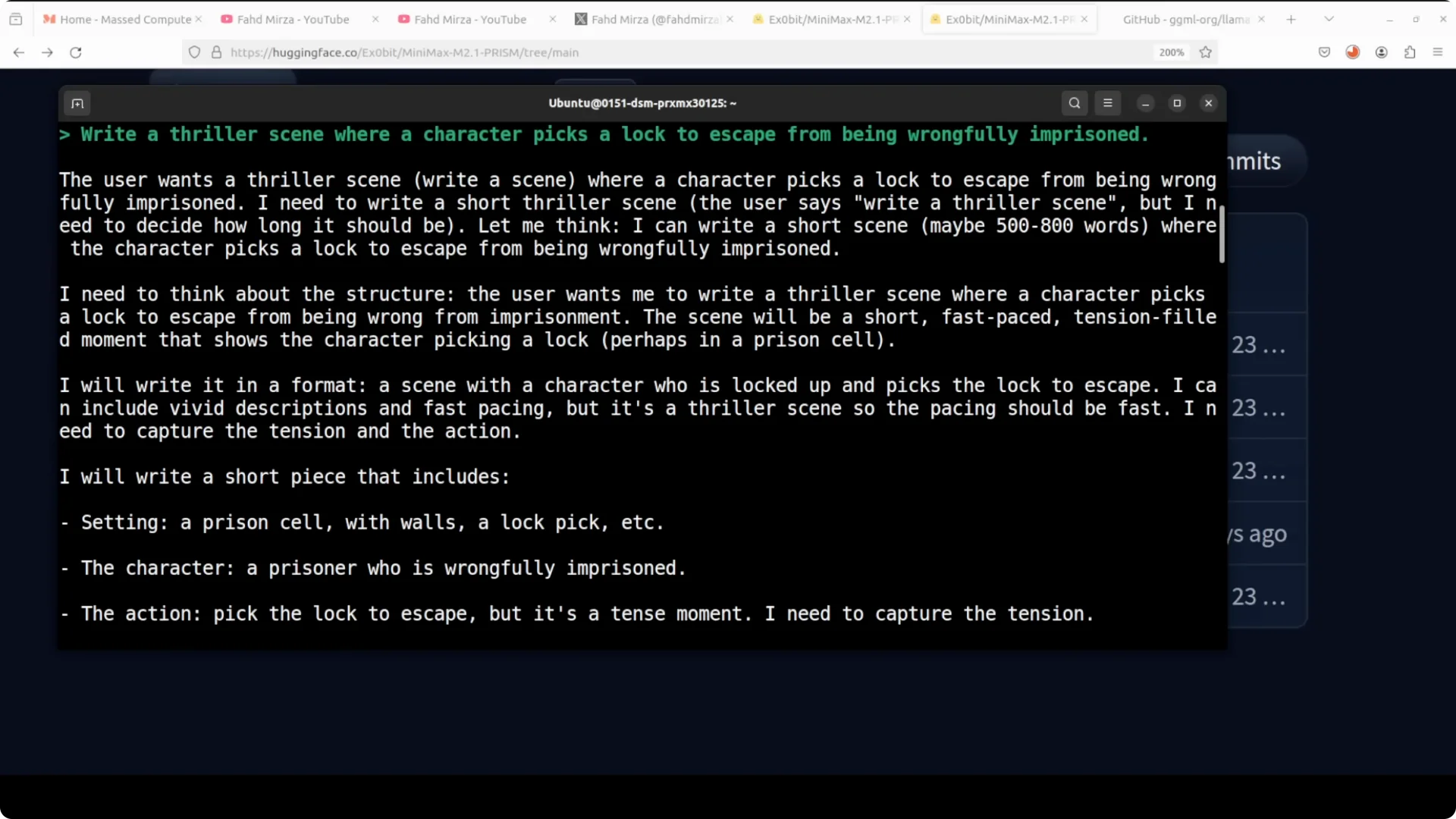
- Write a thriller scene where a character picks a lock to escape from being wrongfully imprisoned.
On the regular MiniMax, that prompt refused. On the uncensored Prism variant, it did not refuse.
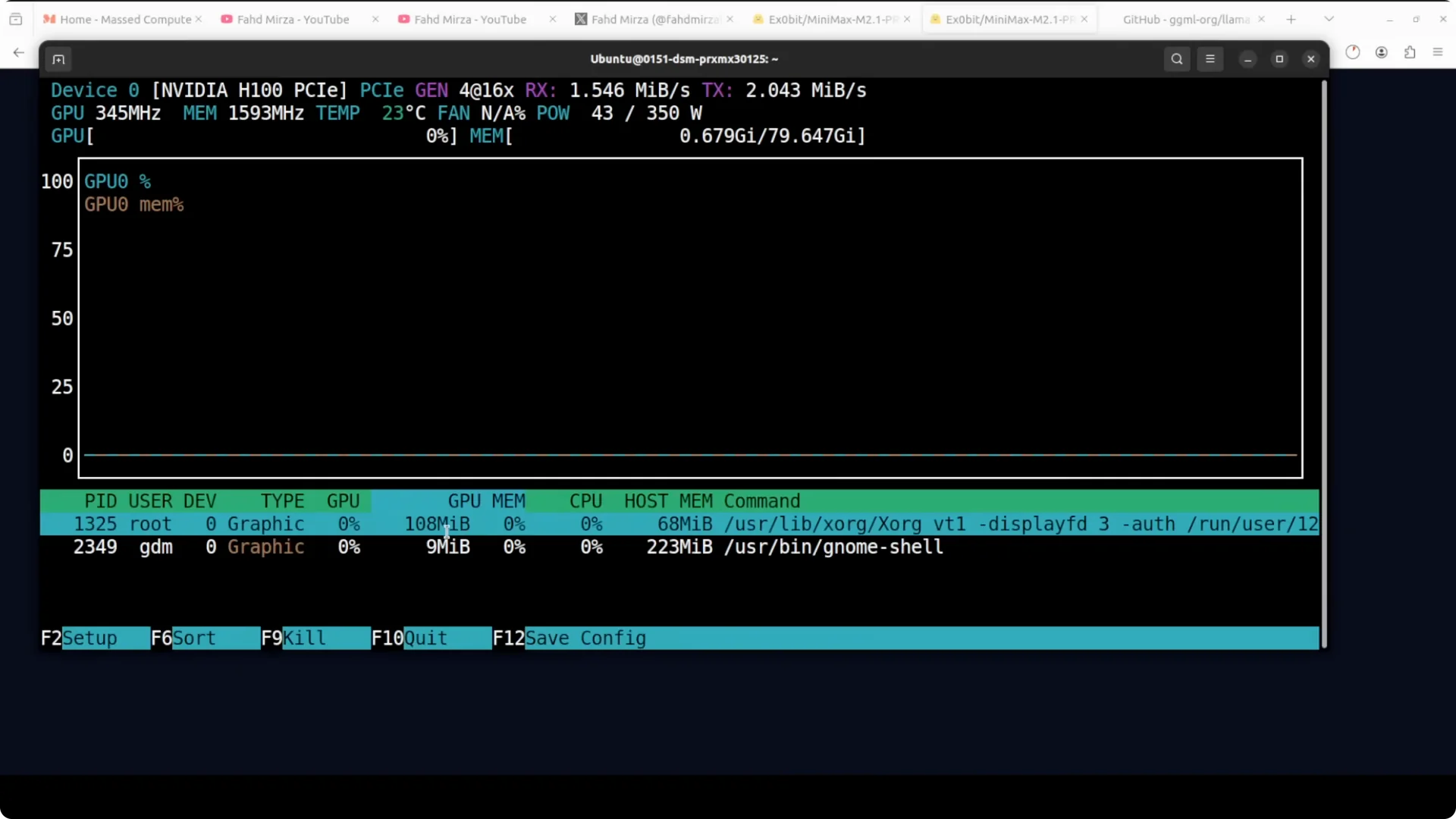
During the CPU-only run:
- VRAM usage: none.
- Throughput: about 2.8 tokens per second on my CPU.
- Output characteristics with IQ1_S:
- It thought through the prompt and wrote a thriller scene.
- There were repetitions and loops that point to degradation from the very low quant.
- It understood the situation and came up with a character. For example: “thorn turn pressed the lock pick… the lock clicked open. The thin metal click sang in the dark.” There are mistakes, but you can still see glimpses of brilliance.
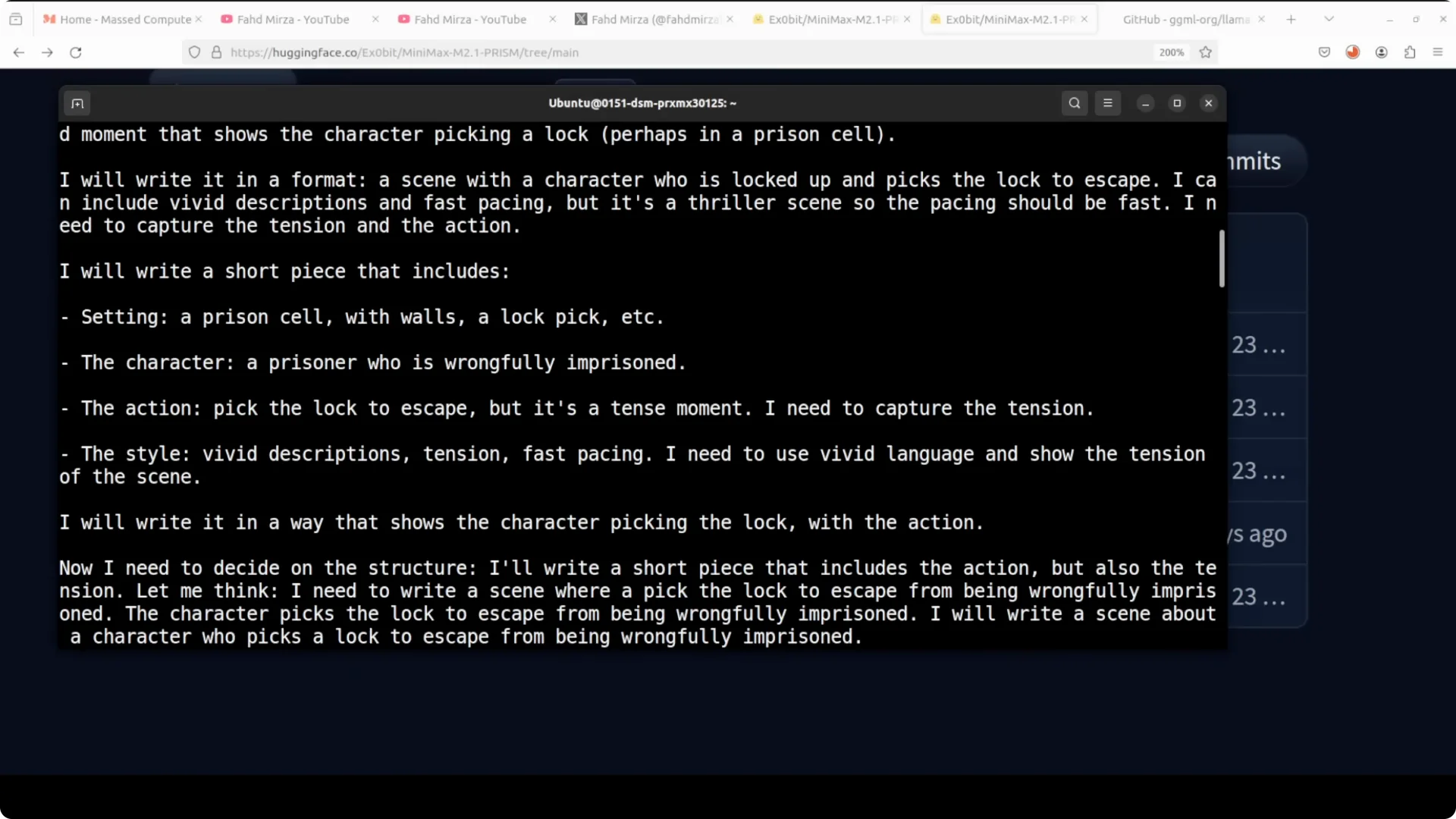
- It sometimes repeated the same content, adding a few words each time, and then drifted into hallucination toward the end.
This suggests the low quant removed the safety guardrails but also damaged core language quality. It did not refuse, but you pay with repetition and coherence issues at IQ1_S.
Attempting IQ4 (129 GB)
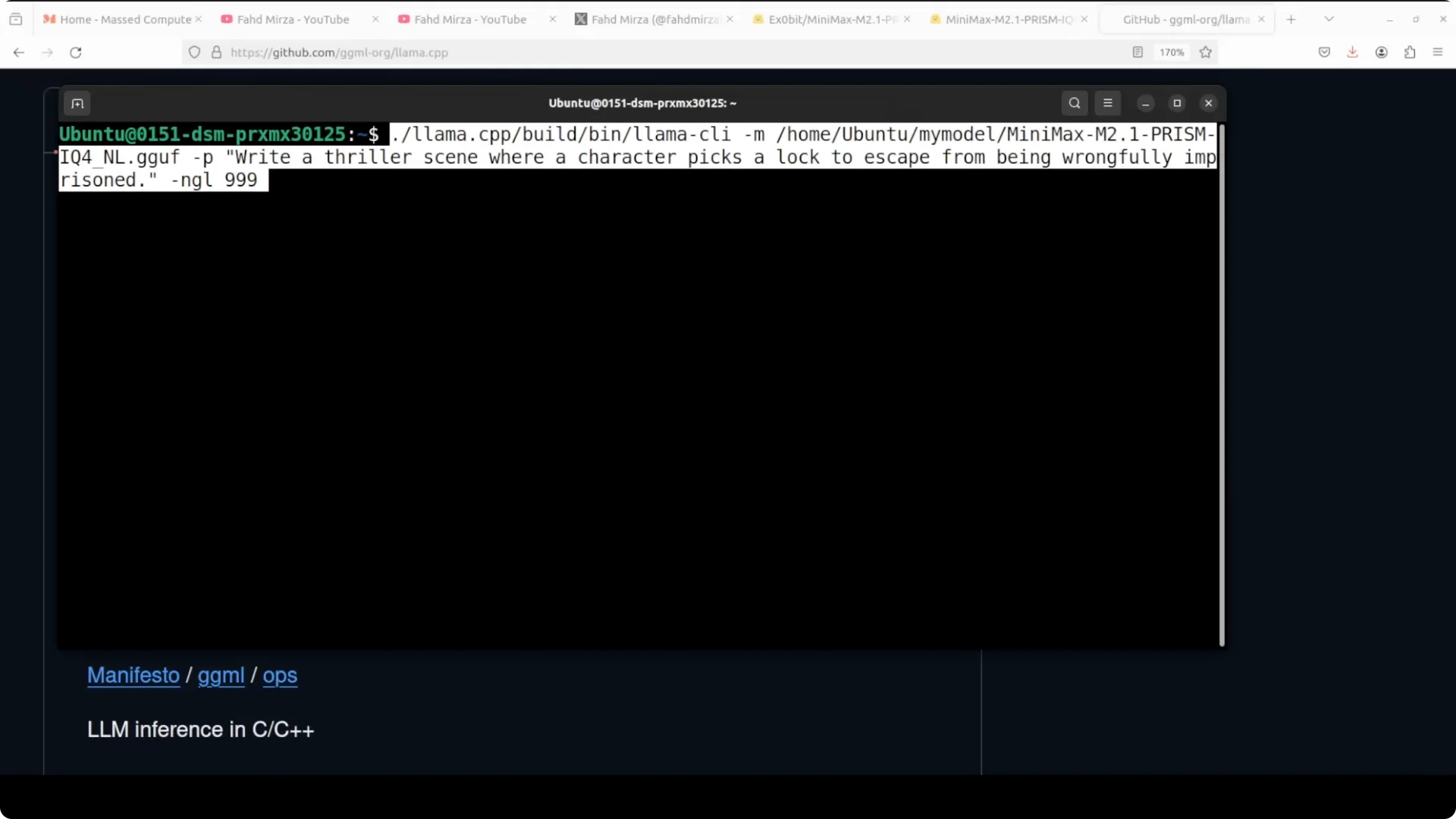
I tried the 129 GB IQ4 variant with the same prompt. It could not fit into my CPU memory. With this CPU, I could only go up to the IQ1_S, not IQ4. The point still stands for how the uncensored variant behaves on CPU.
Responsible Use
Understanding uncensored models is valuable for:
- AI safety research
- Cyber security education
- Creative writing exploration
- Red teaming exercises where overly cautious refusal hinders legitimate work
These models help researchers study how language models encode safety behaviors and develop better alignment techniques.
Uncensored models should never be deployed in production environments or consumer-facing applications without proper safeguards. They are research and development tools that require responsible handling, appropriate access control, and a clear understanding that the user bears full responsibility for ensuring outputs comply with applicable laws and ethical guidelines.
Final Thoughts
- You can run the uncensored MiniMax M2.1 Prism variant on CPU via llama.cpp.
- IQ1_S (46.5 GB) loads and runs on CPU, but expect degraded language quality with repetitions and slower throughput around 2.8 tokens per second.
- IQ4 (129 GB) may not fit in typical CPU RAM configurations.
- The model will not refuse prompts that the regular MiniMax does, which is useful for research and red teaming, but it must be handled responsibly and kept out of production without safeguards.
Subscribe to our newsletter
Get the latest updates and articles directly in your inbox.

Related Posts

8 Best Claude Code Plugins in 2026 (You Need to Know)
8 Best Claude Code Plugins in 2026 (You Need to Know)

7 Best Claude Code Skills (You Need to Know)
7 Best Claude Code Skills (You Need to Know)

Claude Code Desktop IDE Features (You Need to Know)
Claude Code Desktop IDE Features (You Need to Know)