
Table Of Content
- MolmoBot: the core problem
- MolmoBot: the AI2 approach
- MolmoBot: training data at scale
- MolmoBot: manipulation from synthetic data
- MolmoBot: how it runs
- MolmoBot: step-by-step setup
- MolmoBot: reference code
- Minimal sketch - adapt to your environment
- 1) Simulation and robot setup
- Assume `molmo` is a python API for MolmoSpace and `mujoco` backend is available
- 2) Load the MolmoBot policy from Hugging Face
- 3) Language instruction
- 4) Control loop at ~15 Hz => 66 ms per step
- MolmoBot: status and cautions
- MolmoBot: why it matters
- Use cases
- Final thoughts

MolmoBot: How AI Is Making Robotics Accessible to All
Table Of Content
- MolmoBot: the core problem
- MolmoBot: the AI2 approach
- MolmoBot: training data at scale
- MolmoBot: manipulation from synthetic data
- MolmoBot: how it runs
- MolmoBot: step-by-step setup
- MolmoBot: reference code
- Minimal sketch - adapt to your environment
- 1) Simulation and robot setup
- Assume `molmo` is a python API for MolmoSpace and `mujoco` backend is available
- 2) Load the MolmoBot policy from Hugging Face
- 3) Language instruction
- 4) Control loop at ~15 Hz => 66 ms per step
- MolmoBot: status and cautions
- MolmoBot: why it matters
- Use cases
- Final thoughts
Generative AI with robotics is the ultimate AGI, if any such thing exists. What if you could teach a robot to pick up objects, open drawers, and navigate real rooms without ever letting it touch the real world. No human demonstrations, no months of data collection, just a simulation.
Then you take that robot, drop it into a real environment with objects it has never seen before and it just works. That is not a hypothetical. The Allen Institute for AI has just pulled this off in a project called MolmoBot, and the way they did it challenges one of the most deeply held assumptions in robotics research.
If you are mapping this to larger autonomous stacks, a primer on agent behavior is helpful. For a clear introduction to how agents plan and act, see agentic foundations.
MolmoBot: the core problem
Robots are hard not because the hardware is bad, but because making them reliable in messy, unpredictable real world environments is genuinely one of the hardest problems in AI. For years, researchers used simulation as a starting point because it is cheap, fast, and safe. But simulation alone was never enough.

The real world is messier than any virtual environment. Lighting changes, objects are slightly different, surfaces behave unexpectedly. This gap between simulation and reality is so well known in the field that it has its own name, the sim to real gap.
To bridge it, researchers spent months collecting teleoperated demonstrations, which is a human physically guiding a robot arm through tasks over and over. The model could then learn from real world experience. It worked, but it was slow, expensive, and hard to scale.

Every new robot, every new task, every new environment meant starting that process again. The Allen Institute for AI decided to take a different bet. Instead of accepting that real world data was necessary, they asked a more fundamental question.
What if the information was not just diverse enough. What if the reason the sim to real gap existed was not because simulation was inherently limited but because researchers were not throwing enough variety at it.
MolmoBot: the AI2 approach
To test that idea they built two things. The first is MolmoSpace, a massive open simulation ecosystem designed to generate training data at a scale and diversity that had not been attempted before. The second, which matters even more, is the MolmoBot model family, a robot manipulation model trained entirely on that synthetic data with no real world demonstration whatsoever.

If you are thinking about how operators might supervise or audit behaviors, a control surface helps. For a practical interface that complements this kind of work, explore the OpenClaw dashboard.
MolmoBot: training data at scale
MolmoSpace is not just a simulator, it is an ecosystem. It contains over 230,000 indoor scenes, more than 130,000 curated object assets, and over 42 million physics grounded robot grasp annotations in one unified platform. In practice, a robot inside MolmoSpace is not seeing the same room with the same object over and over.

It is looking at kitchens, living rooms, offices, and bedrooms. It is seeing mugs and bowls and salt shakers and drawers in every possible position. Training across hundreds of thousands of wildly different scenarios produces a robot that understands the underlying task and can generalize.

MolmoBot: manipulation from synthetic data
MolmoBot is trained end to end on that synthetic data. There are no teleoperated demonstrations. There is no real world fine tuning.
The policy is conditioned on language, vision, and robot state. You give it a task in plain English. It acts using its visual inputs and joint positions to complete the task.
For readers building vision language planning stacks, staged reasoning is useful. See a compact walkthrough of step-based VLP in our note on Step3 VL.
MolmoBot: how it runs
Here is the flow that makes the system tick. A simulated environment is set up by loading a house from MolmoSpace into a physics engine. A Franka robot arm is placed at a specific pose in the scene.
The robot is equipped with two cameras. A wrist camera at the gripper sees what it is about to grab. An external camera nearby gives a wider view of the scene.
An object set is placed in the environment, for example a bowl as the receptacle and a salt shaker as the item to move. The pre-trained MolmoBot policy is loaded exactly as trained. No fine tuning happens here.
You give the robot a task in plain English like put the salt shaker in the bowl. From that point on, the policy runs in a loop. Every 66 milliseconds, the robot reads its current joint positions, captures images from both cameras, appends the task description, and the model outputs an action that the robot executes.
MolmoBot: step-by-step setup
Install dependencies for simulation, control, and model inference.
Create or load a MolmoSpace scene and place the Franka arm.
Attach a wrist camera and an external camera.
Place a bowl and a salt shaker at randomized poses.
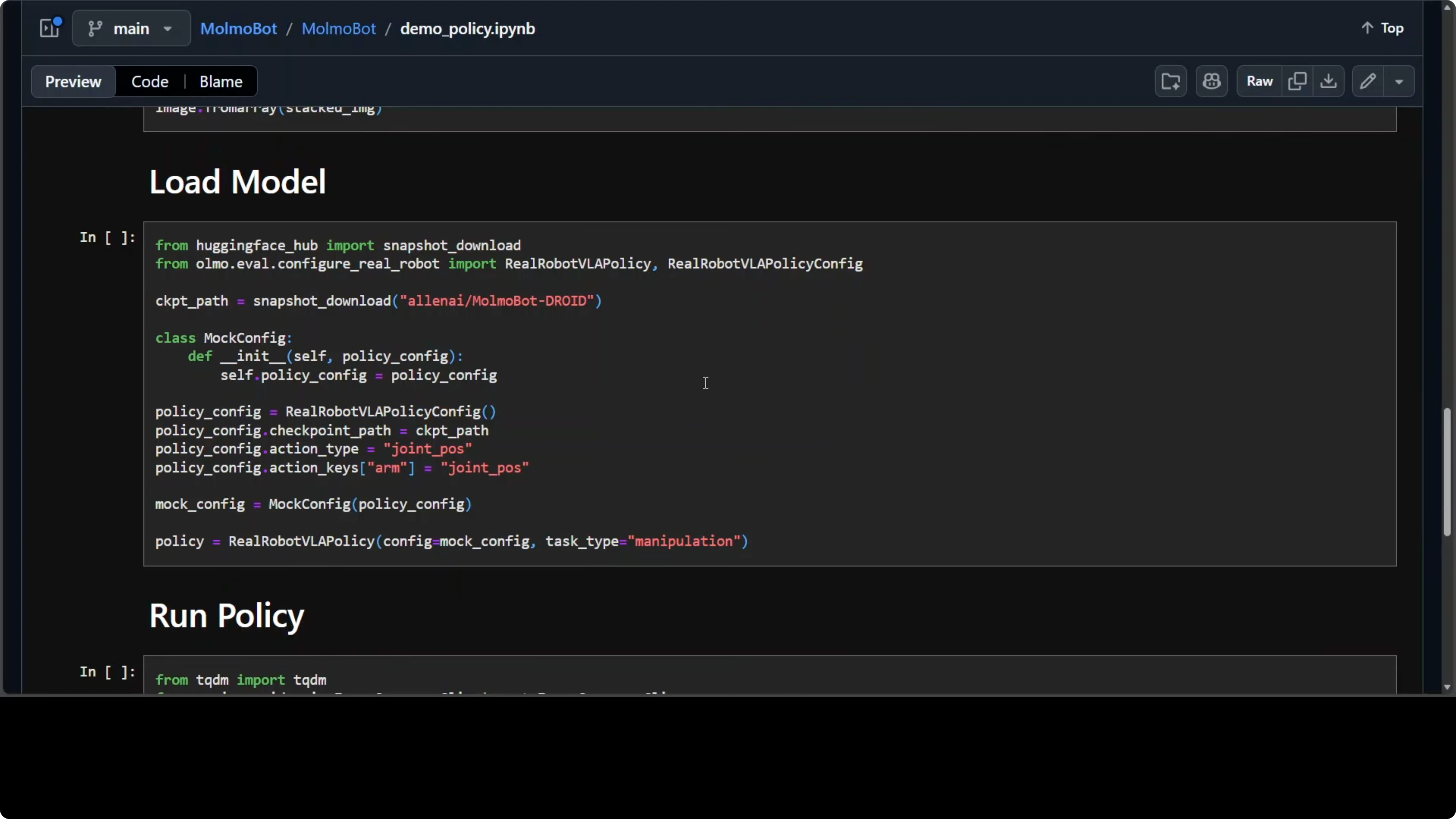
Load the MolmoBot policy from your model hub.
Define the natural language instruction.
Run a 15 Hz control loop that feeds observations to the policy and applies the returned action.
MolmoBot: reference code
# Minimal sketch - adapt to your environment
import time
import numpy as np
# 1) Simulation and robot setup
# Assume `molmo` is a python API for MolmoSpace and `mujoco` backend is available
from molmo import MolmoSpace, FrankaPanda, Camera
from transformers import AutoTokenizer, AutoModelForCausalLM # placeholder if policy ships via HF
scene = MolmoSpace.load_scene(scene_id="house_random_001", physics="mujoco") # MuJoCo, not Mojo
robot = FrankaPanda(scene=scene, base_pose=[0.0, 0.0, 0.0])
wrist_cam = Camera(parent=robot, mount="wrist", resolution=(256, 256))
ext_cam = Camera(parent=scene, mount_pose=[1.2, -0.8, 1.0], resolution=(256, 256))
bowl = scene.place_object(category="bowl", randomize_pose=True)
salt_shaker = scene.place_object(category="salt_shaker", randomize_pose=True)
# 2) Load the MolmoBot policy from Hugging Face
policy_repo = "ai2/molmobot-base" # example slug
tokenizer = AutoTokenizer.from_pretrained(policy_repo)
policy = AutoModelForCausalLM.from_pretrained(policy_repo)
# 3) Language instruction
task_text = "Put the salt shaker in the bowl."
# 4) Control loop at ~15 Hz => 66 ms per step
dt = 1.0 / 15.0
while not scene.done():
# Observations
obs = {
"rgb_wrist": wrist_cam.capture(), # shape [H, W, 3], uint8
"rgb_external": ext_cam.capture(), # shape [H, W, 3], uint8
"qpos": robot.get_joint_positions(), # shape [7], float32
"task": task_text
}
# Pack inputs for the policy - the real API will differ
inputs = tokenizer.encode_plus(
obs["task"],
return_tensors="pt",
add_special_tokens=True
)
# In practice, vision + state would be fed through multimodal encoders
# Here we show a placeholder forward call
action_tokens = policy.generate(**inputs, max_new_tokens=16)
action = np.zeros(7, dtype=np.float32) # replace with decoded action from policy output
# Apply action and step simulation
robot.apply_action(action) # e.g., delta joint targets or end-effector pose
scene.step(dt)
time.sleep(dt)If you are integrating remote operators or bots to trigger routines, pairing this with a simple ops channel can help. A lightweight pattern is to use agent runners that post task states and accept new commands, which pairs well with tools like Autoclaw agents on Telegram and Windows.
MolmoBot: status and cautions
I am very excited because this brings AI closer to the physical world. But one caution, it is not a finished product yet. It is a research result, a proof of concept that questions a longstanding assumption about what robots need to learn.
The question it is really asking is how much of the intelligence can be built in a virtual world before it becomes real. Right now the answer looks like a lot more than we thought. AI2 has released the code, the data, and the simulation platform.
If you plan to test models behind restricted UIs or quotas, account gating can interrupt experiments. For mitigation steps and workarounds, see how to fix access restrictions when working with managed endpoints.
MolmoBot: why it matters
If simulation alone can produce robots capable of operating in the real world, then the bottleneck in robotics shifts fundamentally. Right now, progress is gated by how much real world data you can collect, which means it is gated by money, hardware access, and time. That concentrates progress in the hands of a small number of well resourced labs.
If you can train entirely in simulation, the constraint becomes something much more tractable. Designing richer virtual environments is a software problem. It scales with compute.
Because AI2 is releasing all of this openly, the model, the simulation, the grasp annotations, labs and even individual researchers around the world can build on this foundation rather than starting from scratch. That is a different kind of progress, faster, more collaborative, and harder for any single organization to monopolize. That is the best thing here.
For those building operator consoles and toolchains around manipulation, an onboard dashboard is a practical companion. You can explore a hands-on control layer in the OpenClaw dashboard and pair it with step-wise planners like Step3 VL for instruction-following flows.
Use cases
Teach pick and place in kitchens and offices where layouts, lighting, and object styles constantly vary. The same policy class can generalize to drawers, cabinets, and containers by conditioning on the language goal and the visual context. That reduces per-task data collection and speeds iteration.
Simulate long-running household routines like clearing tables, restocking shelves, or resetting a workbench. Randomize clutter, materials, and object geometry in MolmoSpace to push the policy toward robust grasps and placements. Then validate in a small number of real trials.
Prototype warehouse bin-picking or kitting with photoreal variation before touching a conveyor. Sweep through thousands of CAD variants and textures to harden grasp proposals and insertion maneuvers. When you move to production, wrap your skills with a simple operator chat bridge using Autoclaw agents for notifications and overrides.
If you want a broader conceptual base for planning agents that coordinate these tasks, expand with our primer on agentic foundations. And for step-by-step planners that translate language into actionable checkpoints, review Step3 VL to align instruction granularity with control frequency.
Final thoughts
MolmoBot shows that if you throw enough variety at simulation, a robot can learn skills that hold up in the real world without touching it first. The core shift is from collecting demonstrations to designing diverse virtual experiences and scaling them. With open releases, this invites a wider community to build, test, and improve robotic skills faster.
For operations teams adding human-in-the-loop guardrails and dashboards, pair simulated training with practical control layers like the OpenClaw dashboard. If your workflow relies on managed model access, keep an eye on quotas and review access restriction fixes so experiments do not stall.
Subscribe to our newsletter
Get the latest updates and articles directly in your inbox.

Related Posts

8 Best Claude Code Plugins in 2026 (You Need to Know)
8 Best Claude Code Plugins in 2026 (You Need to Know)

7 Best Claude Code Skills (You Need to Know)
7 Best Claude Code Skills (You Need to Know)

Claude Code Desktop IDE Features (You Need to Know)
Claude Code Desktop IDE Features (You Need to Know)