
Table Of Content
- STEP3-VL by StepFun: How This Open-Source Vision Model Runs Locally?
- What makes STEP3-VL-10B strong
- Input processing pipeline
- Dual inference modes that lift performance
- Hands-on results
- Image description with OCR
- Landmark and location recognition
- Math reasoning on a visual multiple-choice
- Complex scientific figure understanding
- Document understanding - invoice status
- Handwritten content and translation
- Multilingual OCR limits
- Performance footprint and runtime notes
- Final thoughts

STEP3-VL by StepFun: How This Open-Source Vision Model Runs Locally?
Table Of Content
- STEP3-VL by StepFun: How This Open-Source Vision Model Runs Locally?
- What makes STEP3-VL-10B strong
- Input processing pipeline
- Dual inference modes that lift performance
- Hands-on results
- Image description with OCR
- Landmark and location recognition
- Math reasoning on a visual multiple-choice
- Complex scientific figure understanding
- Document understanding - invoice status
- Handwritten content and translation
- Multilingual OCR limits
- Performance footprint and runtime notes
- Final thoughts
StepFun AI has released another fun model. STEP3-VL-10B is punching way above its weight class. This 10 billion parameter multimodal model is outperforming systems 10 to 20 times its size, including 100 billion plus models like GLM 4.6 Vision and even Qwen 3 reasoning, which I believe is one of the best open-source models at this point in time.
I installed STEP3-VL-10B locally and tested it across OCR, document understanding, vision-language reasoning, math, and multilingual tasks. I will also outline the architecture choices that make it strong.
STEP3-VL by StepFun: How This Open-Source Vision Model Runs Locally?
I ran it on Ubuntu with an Nvidia RTX 6000 GPU and 48 GB of VRAM.
Setup I used:
- Created a Python virtual environment.
- Installed the prerequisites from the repo.
- Ran an app.py script from GitHub and put a Gradio interface on top of it.
- On first run, the model downloaded and then loaded into the GPU.
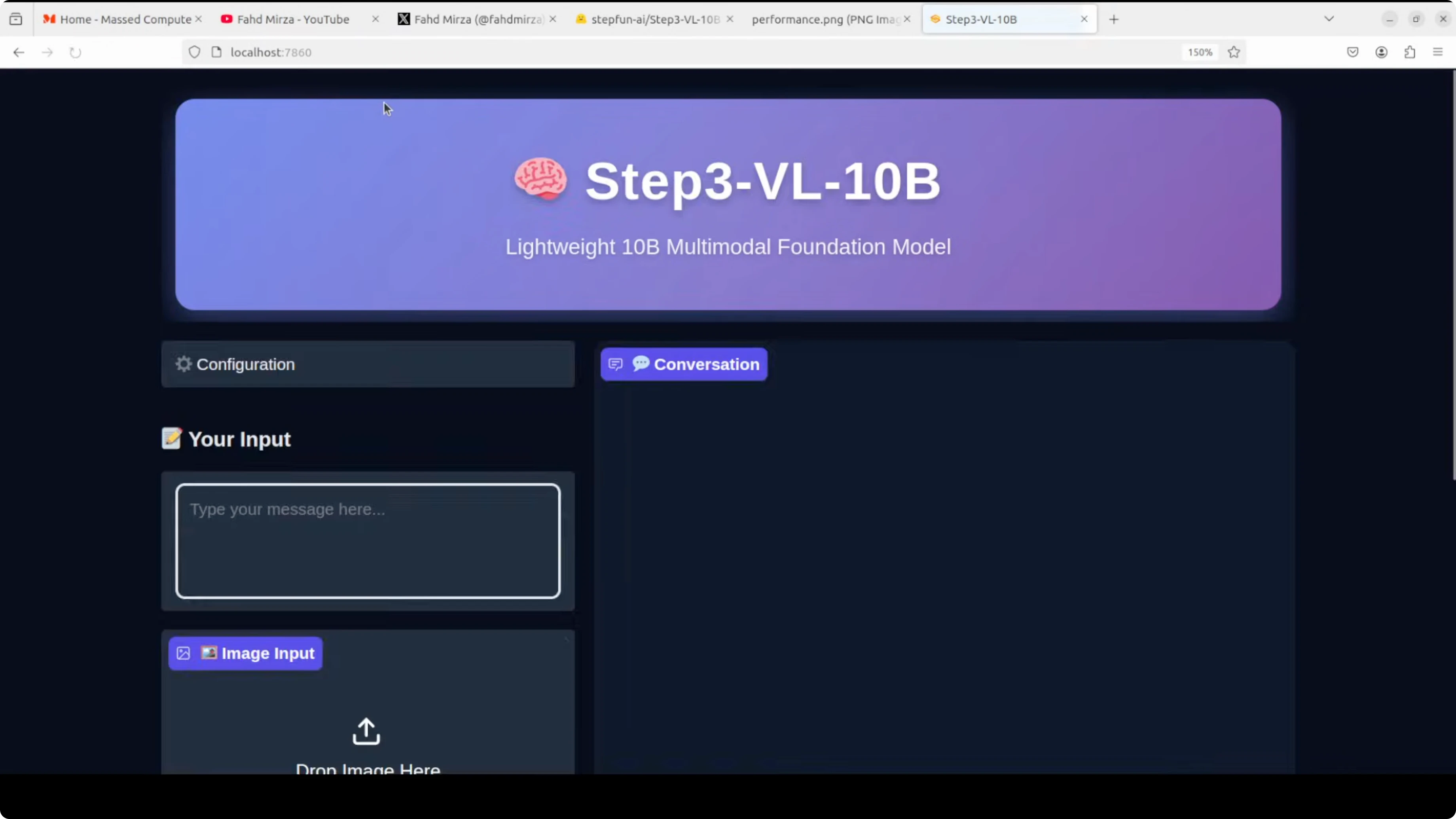
- Accessed the web UI at localhost:7860.
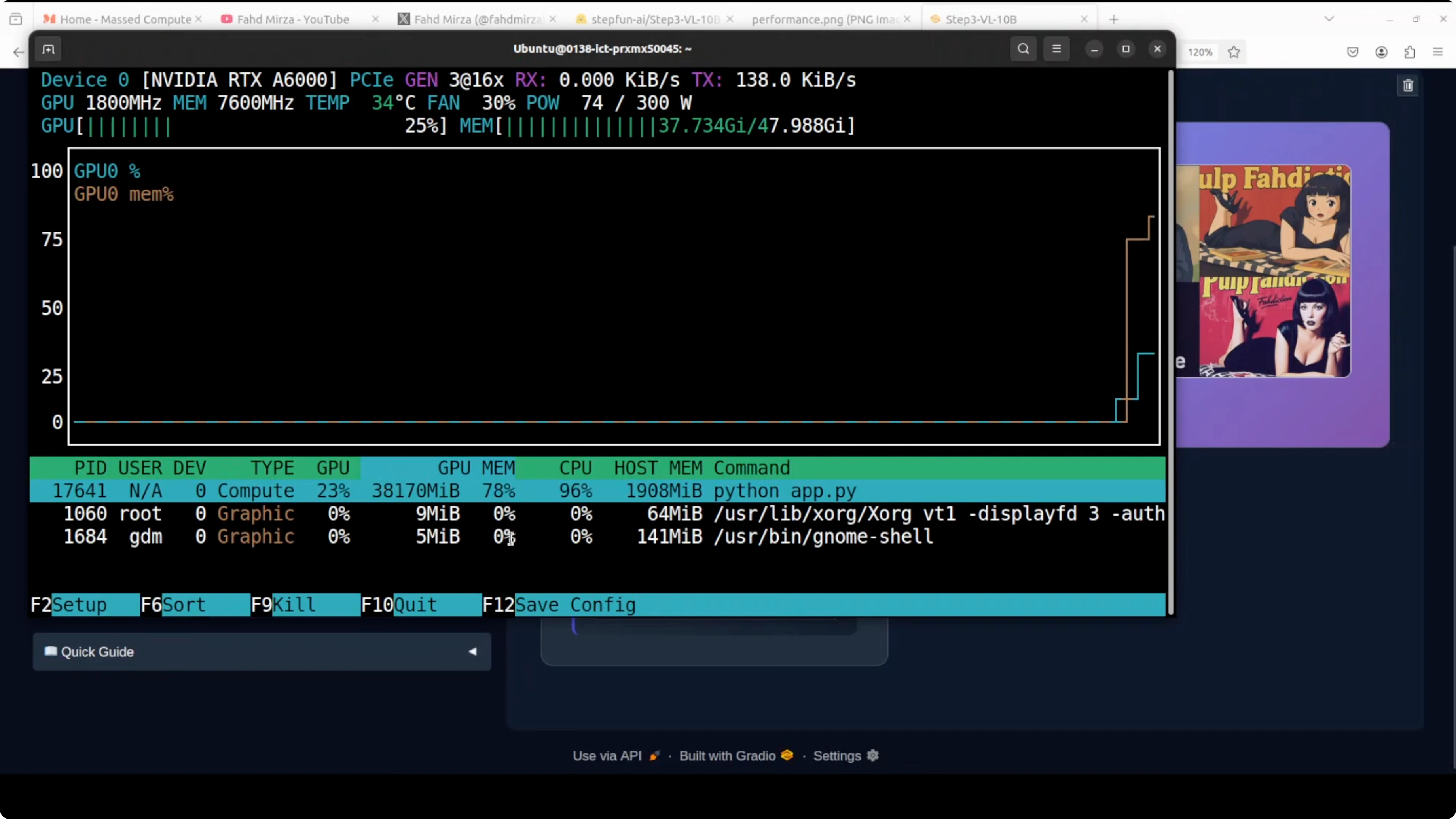
What I observed on first load:
- VRAM usage climbed to almost 40 GB once fully loaded.
- First inference took longer as weights downloaded and initialized.
- Subsequent requests reused the loaded state and VRAM stayed around the same.
You can do multi-turn interactions on the same image. The web interface makes testing straightforward.
What makes STEP3-VL-10B strong
I believe the secret is aggressive optimization of both training data quality and post-training refinement. Instead of the typical frozen encoder approach, this model uses a fully unfrozen single-stage pre-training strategy on 1.2 trillion tokens that allows its 1.8 billion parameter vision encoder (PE lang) and Qwen 38 billion decoder to develop tight vision-language integration from the ground up. Behind the scenes, it uses the Qwen 38 billion decoder.
Input processing pipeline
- A language-optimized perception encoder processes images at around 728x728 global resolution plus multiple 504x504 local crops.
- It downsamples through two consecutive strides.
- The output then feeds into the 38 billion parameter decoder.
Dual inference modes that lift performance
What sets it apart is a dual inference mode strategy.
- Sequential reasoning (SE): uses standard chain-of-thought generation up to 64k tokens.
- Parallel coordinated reasoning: scales test-time compute by aggregating evidence from 16 parallel rollouts across a 128k context window.
This pushes performance on hard benchmarks like me 2025 from 87.7% to 94.4%. I think they have done meticulous data curation, extended RL training, and strategic test-time compute allocation.
Hands-on results
Image description with OCR
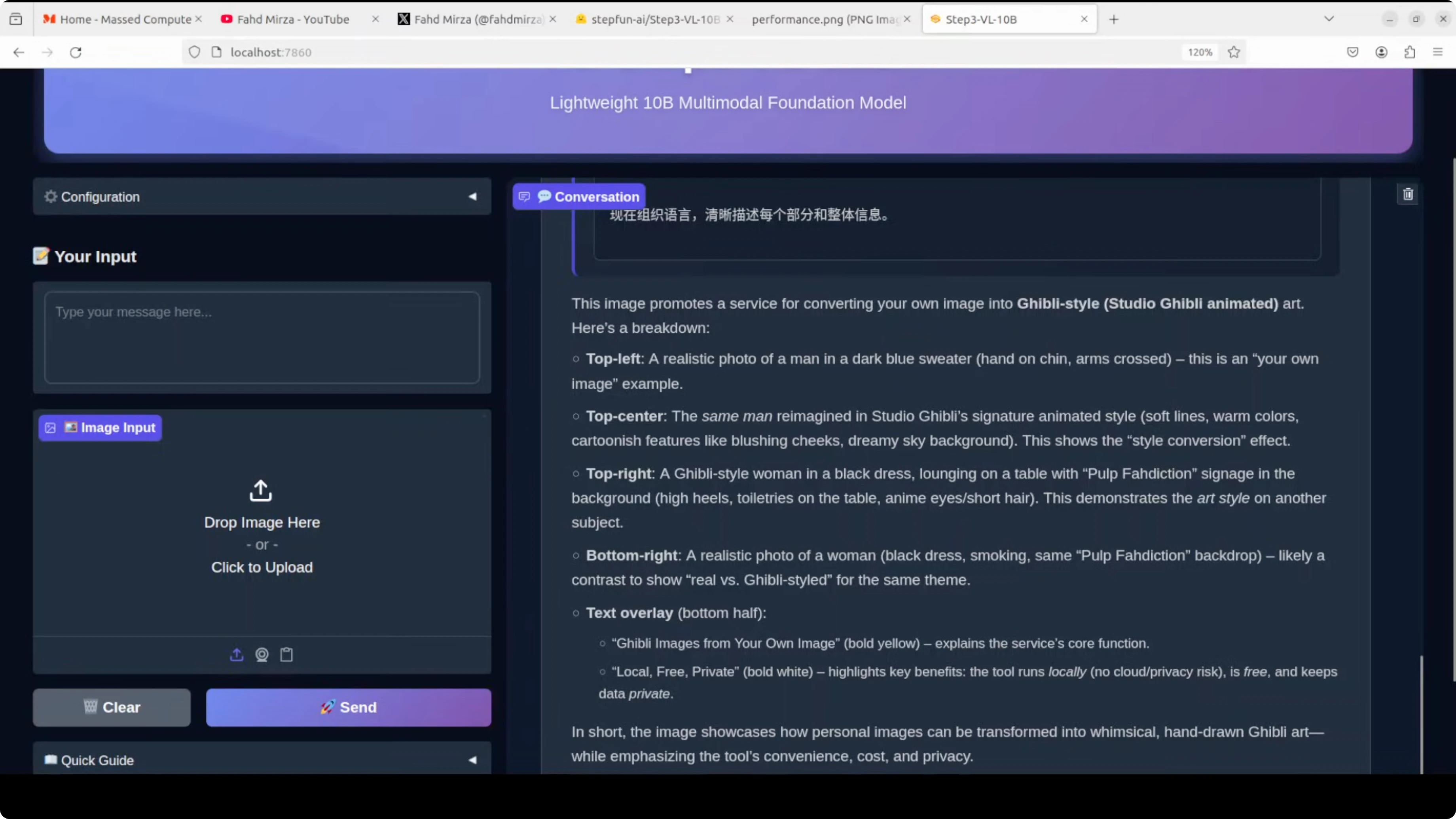
I asked it to describe an image promoting a service for converting your photo into Ghibli style. It extracted text correctly and summarized the layout:
- Top left: realistic photo of a man.
- Top center and right: Ghibli-styled versions of the same theme.
- It recognized the play on words and summarized that the service can transform personal images into whimsical hand-drawn Ghibli art, while emphasizing local, free, and private usage.
I also noticed its internal thinking stream sometimes came out in Chinese before giving the final answer in English.
Landmark and location recognition
I asked for the location and building type from a photo of the Badshahi Mosque in Lahore, Pakistan.
- It correctly identified the Badshahi Mosque and Lahore, Pakistan.
- It noted Mughal architecture and provided accurate historical significance.
- There are many similar buildings in the region, and it still got it right.
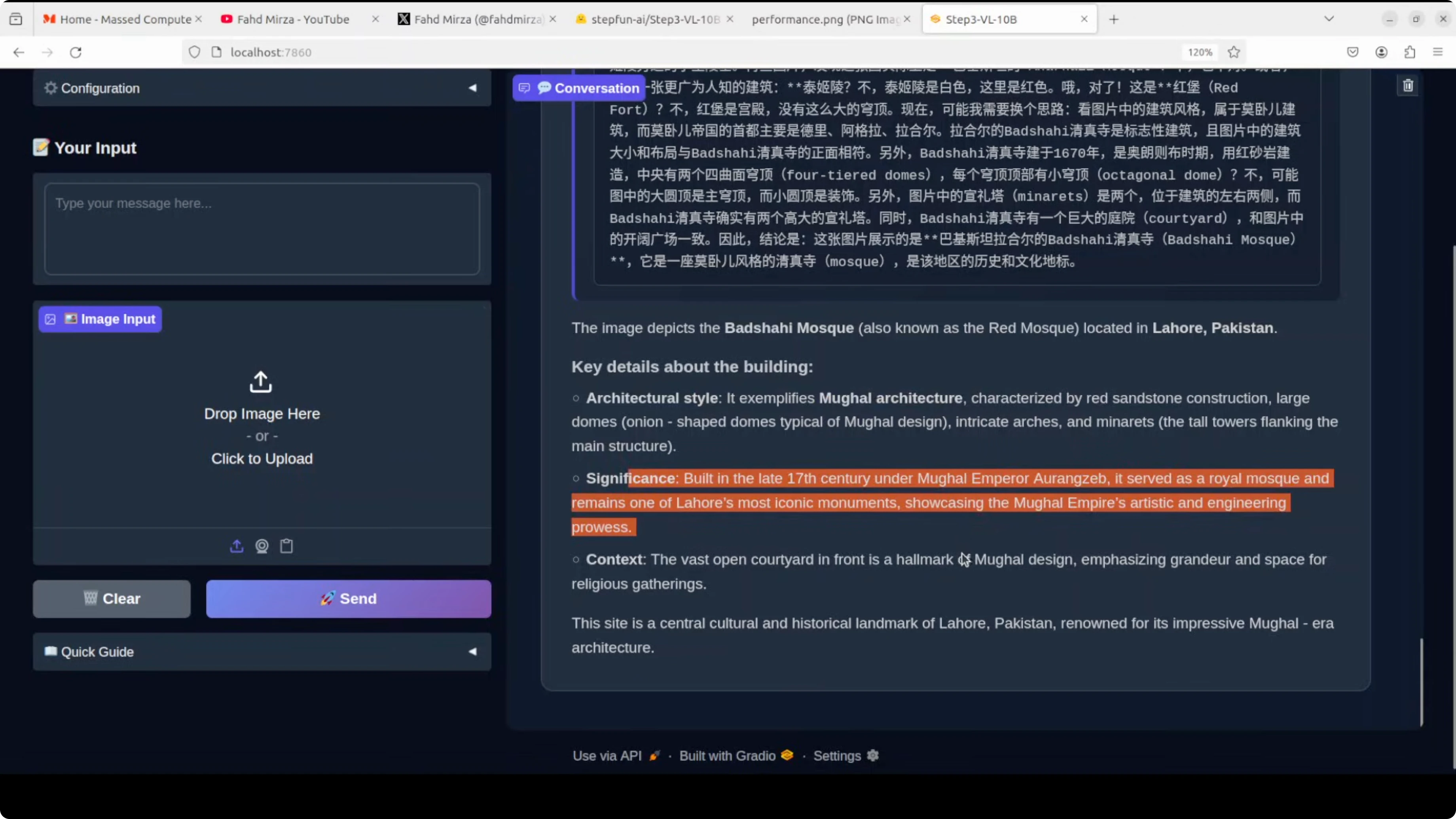
You can ask follow-up questions on the same image.
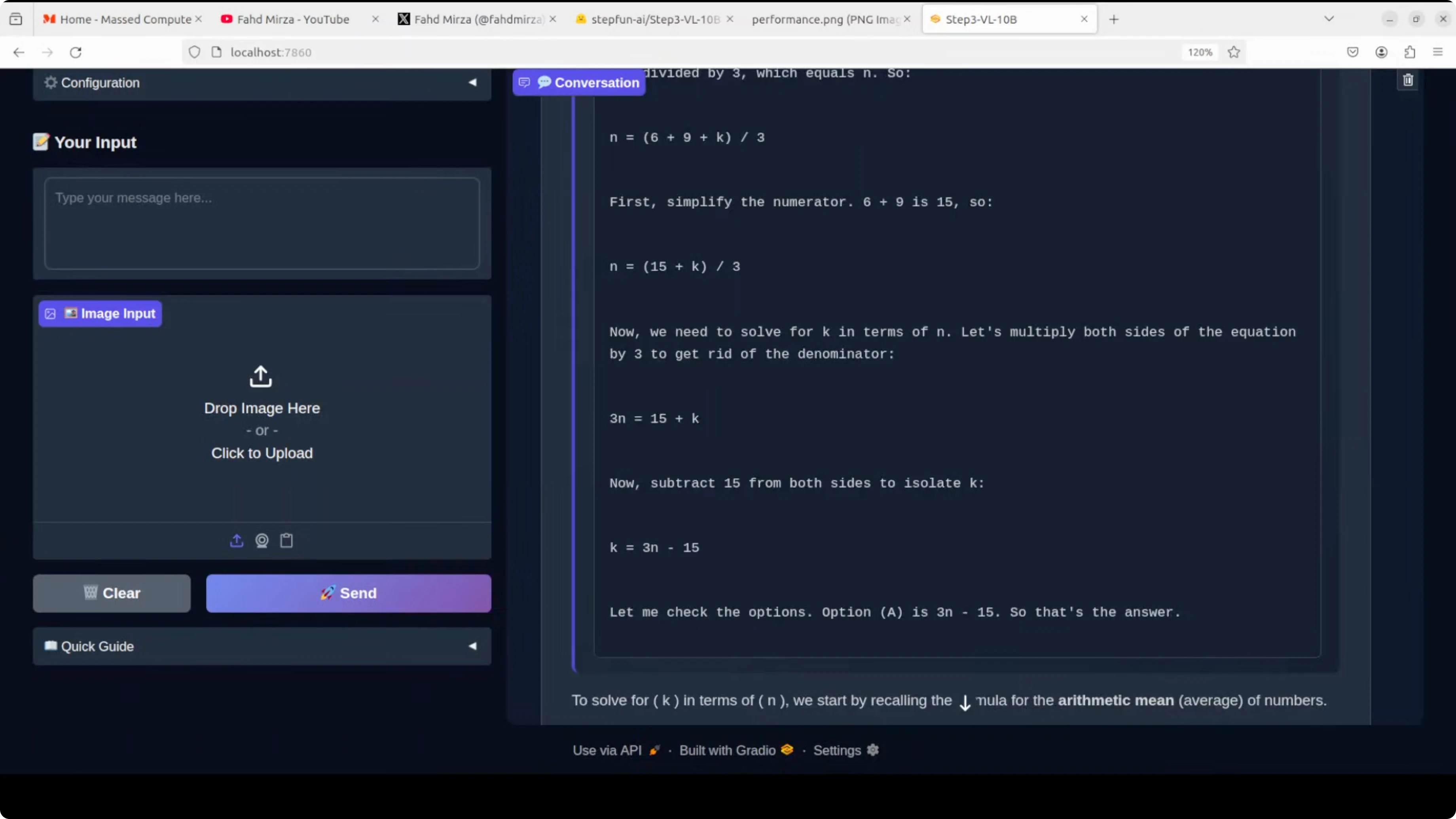
Math reasoning on a visual multiple-choice
I asked it to solve a math equation and pick the right answer. The correct answer was A. It showed step-by-step chain-of-thought in English and selected A correctly.
Complex scientific figure understanding
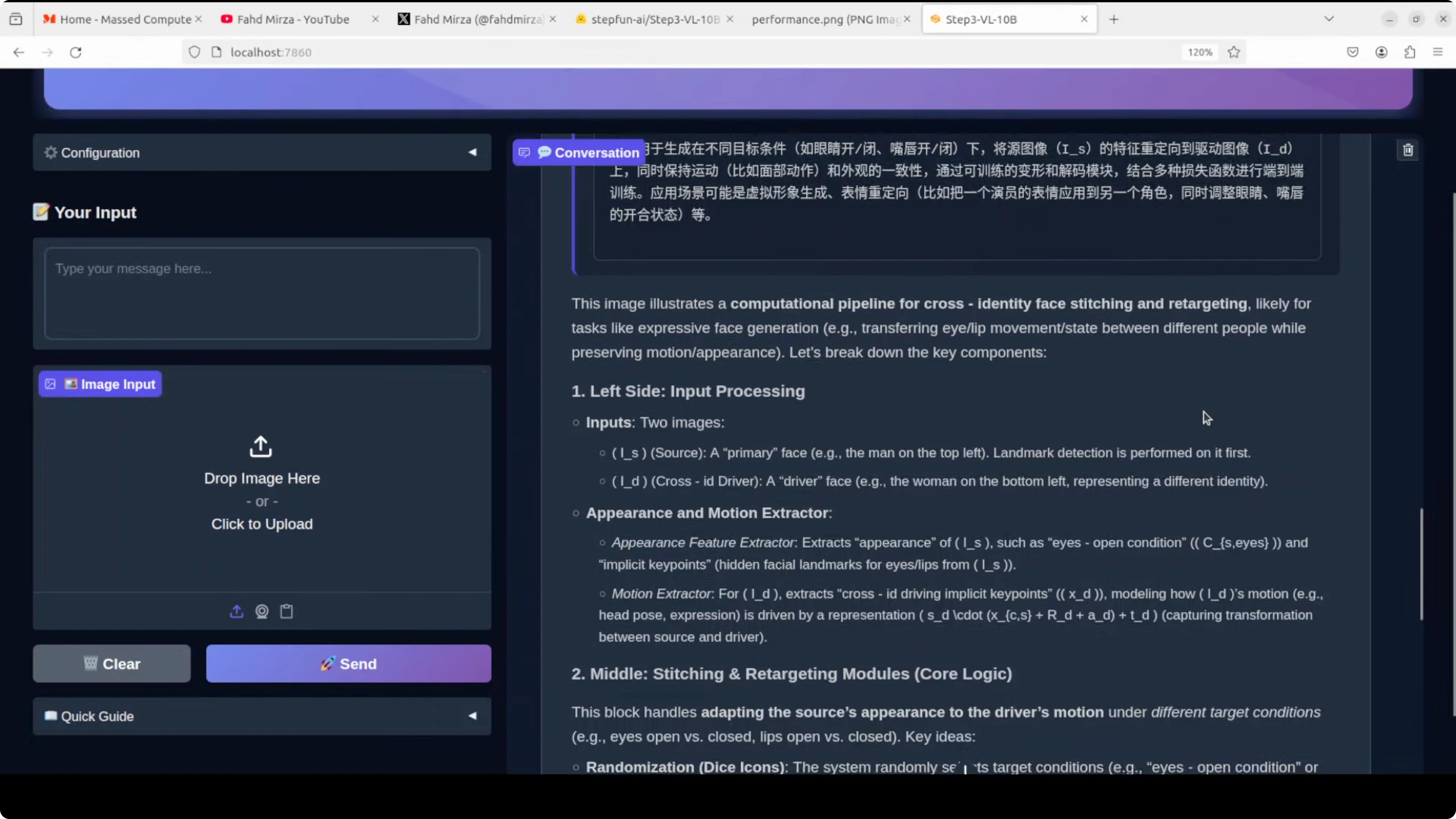
I tested a figure from a scientific paper showing a computational pipeline for cross-identity face stitching and retargeting.
- OCR quality was high.
- It reconstructed the flow correctly from left to right and explained the big picture.
- This response took over 2 minutes to return, but the analysis was spot on.
Document understanding - invoice status
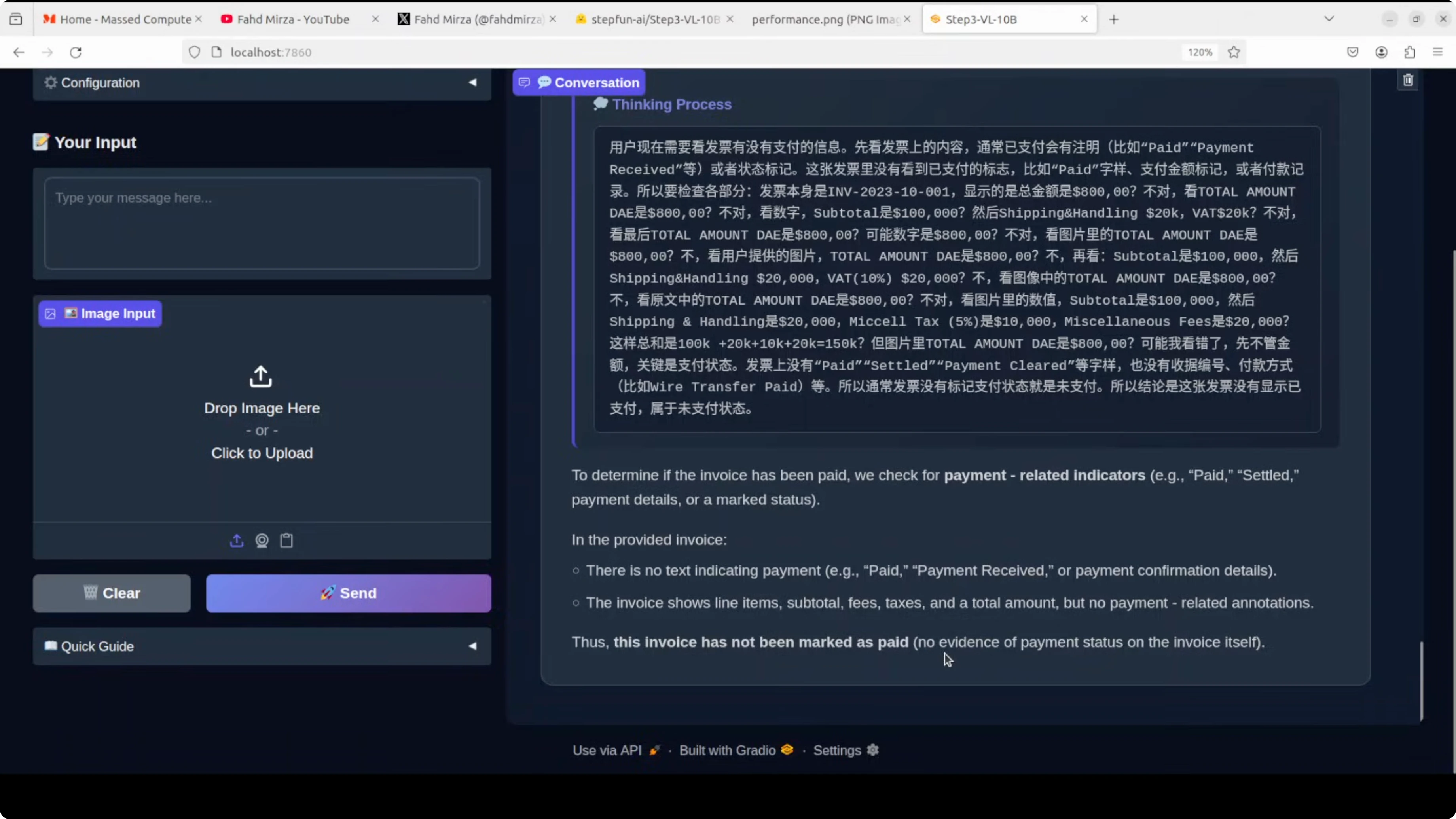
I gave it an invoice and asked if it had been paid.
- It concluded the invoice was not marked as paid and noted the absence of any payment status indicators.
- This showed solid handling of tabular and layout-heavy information.
Handwritten content and translation
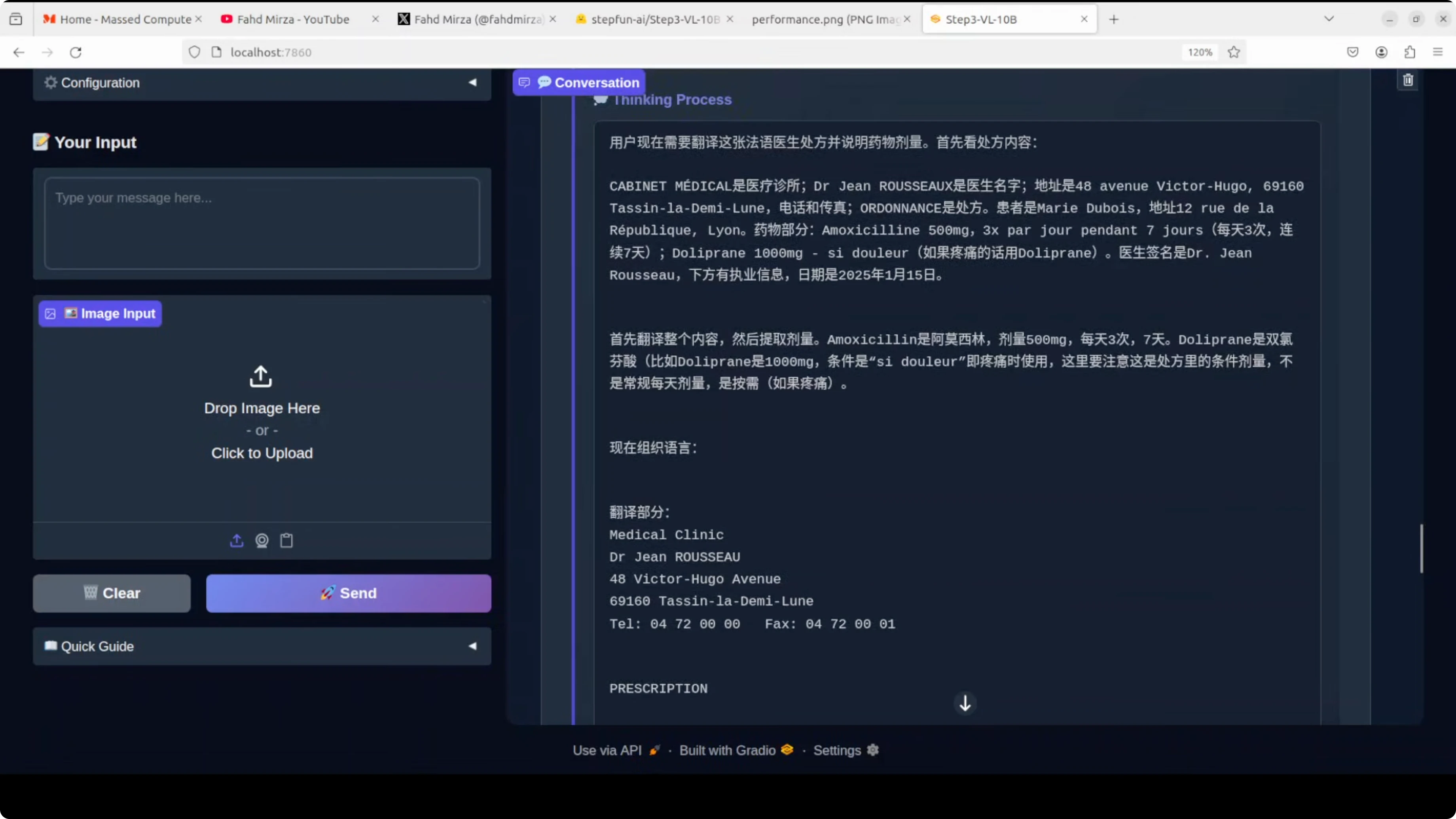
I provided a French medical document and asked for translation into English plus exact medication doses.
- It translated headers like cabinet médical and the address.
- It extracted patient details and the prescription content.
- It listed the exact medication names, doses, and durations, and even captured an additional note.
Multilingual OCR limits
I tested Arabic text for OCR, extraction, and language identification.
- It took 3 to 5 minutes and was still processing during the run.
- From my tests, it supports some top languages well, like French, but not all of them at the same level.
Performance footprint and runtime notes
- First run downloads and initializes the weights.
- Once loaded, VRAM consumption stayed around 40 GB on my RTX 6000 48 GB card.
- Some tasks, especially complex figures and long reasoning, can take a couple of minutes.
- Multi-turn conversations on the same image work as expected.
Final thoughts
I think this is one of the best vision models I have seen this year. The combination of a fully unfrozen pre-training setup, a capable vision encoder with the Qwen 38B decoder, and dual inference modes shows up in practical strengths: high-quality OCR, detailed reasoning on complex figures, robust document understanding, and accurate landmark identification. Latency can increase on heavy tasks, and language coverage is stronger for some languages than others, but the overall capability is exceptional for a 10B parameter model that runs locally on a single 48 GB GPU.
Subscribe to our newsletter
Get the latest updates and articles directly in your inbox.

Related Posts

8 Best Claude Code Plugins in 2026 (You Need to Know)
8 Best Claude Code Plugins in 2026 (You Need to Know)

7 Best Claude Code Skills (You Need to Know)
7 Best Claude Code Skills (You Need to Know)

Claude Code Desktop IDE Features (You Need to Know)
Claude Code Desktop IDE Features (You Need to Know)