
Table Of Content
- Qwen3.5-9B: How It Thinks Like Claude with Opus 4.6
- Distillation focus
- Setup and install
- Testing the reasoning
- Ambiguous startup hiring question
- Trick question with no room for waffle
- What improved and what did not
- Benchmarks snapshot
- Use cases and tradeoffs
- Qwen3.5-9B distilled from Claude Opus 4.6
- Base Qwen3.5-9B
- Claude Opus 4.6
- Step-by-step testing prompts
- Tension around distillation
- Final thoughts

Qwen3.5-9B: How It Thinks Like Claude with Opus 4.6
Qwen Model Recommender
Not sure which Qwen model fits your GPU? Pick your VRAM, use case, and task type — get matched to the right model instantly. Covers Qwen3, QwQ, QVQ, Qwen2.5-VL, Qwen3-Coder, Qwen3-TTS, and 80+ models.
Table Of Content
- Qwen3.5-9B: How It Thinks Like Claude with Opus 4.6
- Distillation focus
- Setup and install
- Testing the reasoning
- Ambiguous startup hiring question
- Trick question with no room for waffle
- What improved and what did not
- Benchmarks snapshot
- Use cases and tradeoffs
- Qwen3.5-9B distilled from Claude Opus 4.6
- Base Qwen3.5-9B
- Claude Opus 4.6
- Step-by-step testing prompts
- Tension around distillation
- Final thoughts
Someone is trying to make Qwen 3.5 models think like Claude. I am going to show you hands-on how this Qwen3.5-9B distilled from Claude works and how exactly it was done. I will also talk about the tension that arises from blending these two models.
This Qwen3.5-9B was fine-tuned with reasoning traces distilled from Claude Opus 4.6 interactions from Anthropic. The idea behind knowledge distillation is straightforward. Instead of training a model from scratch on raw data, you take a smaller model and teach it to think like a much larger, more capable model by feeding it examples of how that larger model reasons through problems.
Here the teacher is Claude Opus 4.6, one of the most capable reasoning models available at the moment. The student is Qwen3.5-9B. The training focused specifically on the internal thinking process, which is the structured step-by-step breakdown inside think tags, not just the final answer.
The result is a 9B model that has internalized a Claude-like reasoning style that is confident, modular, non-repetitive, and organized. I will also test it out. I will talk about the tension that arises from this approach and why it matters.
Qwen3.5-9B: How It Thinks Like Claude with Opus 4.6
Distillation focus
The dataset targeted internal chains of thought rather than only final outputs. The goal was a student that can identify key variables, structure them, and arrive at a conditional recommendation. That confident conditional recommendation is the differentiator I look for in Claude.
If you want a deeper feature-level view of Claude’s current behavior and strengths, see this full breakdown of Opus 4.6. For a concise overview, you can also check this Opus 4.6 guide. Those pieces give useful context for what this distillation tries to echo.
Setup and install
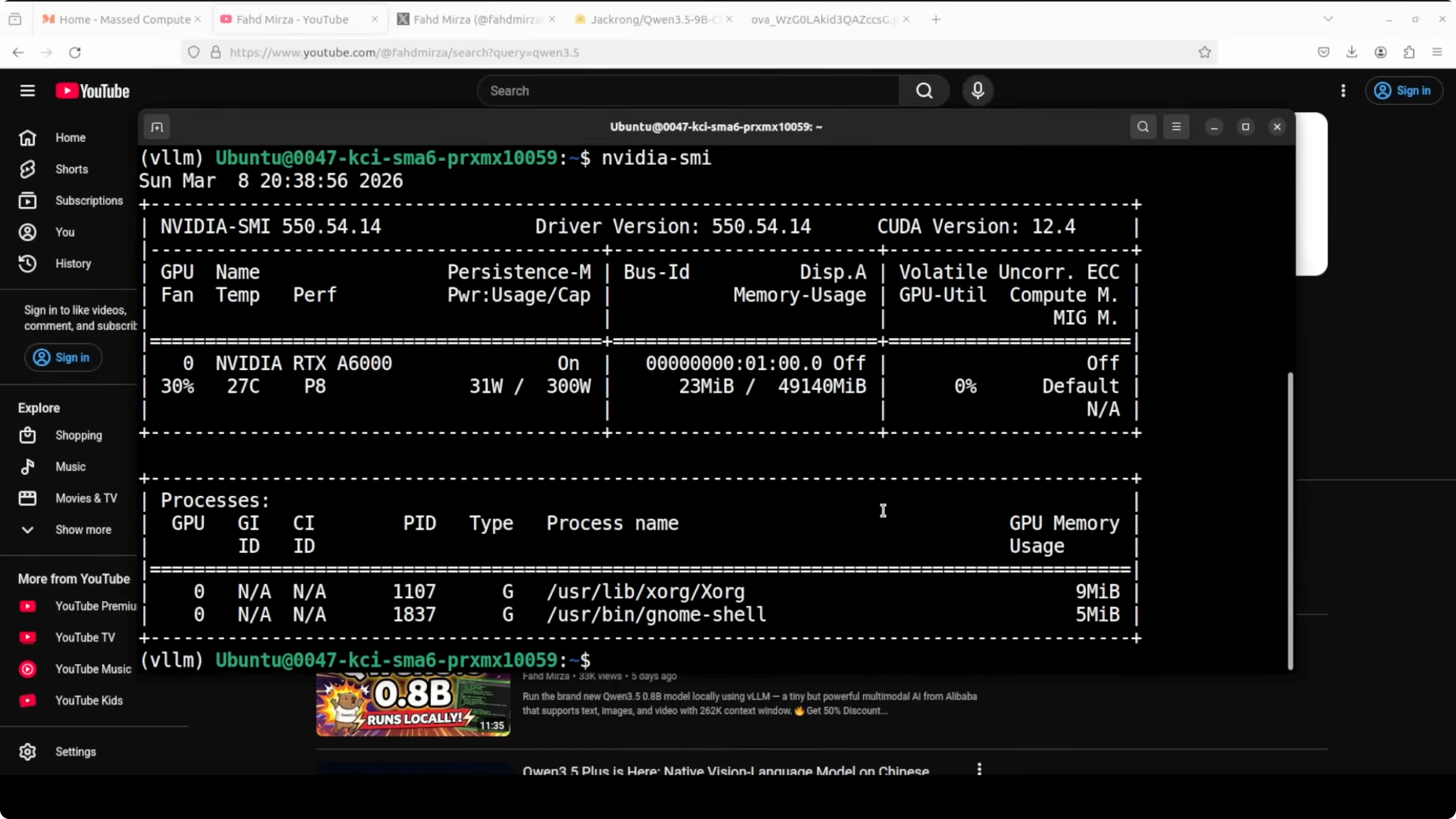
I used an Ubuntu system with an NVIDIA RTX 6000 GPU with 48 GB VRAM. I served the model locally with vLLM and also tested through Open WebUI for a graphical interface. VRAM use was close to 44 GB due to the context length, which is in line with my prior Qwen 9B runs.
Step 1: Prepare Python and CUDA on Ubuntu, then install vLLM.
python3 -m venv .venv
source .venv/bin/activate
pip install --upgrade pip
pip install vllmStep 2: Launch the vLLM OpenAI-compatible server with the distilled model.
vllm serve Jackrong/Qwen3.5-9B-Claude-4.6-Opus-Reasoning-Distilled \
--dtype auto \
--max-model-len 32768Step 3: Check VRAM and server health.
nvidia-smi
curl http://127.0.0.1:8000/v1/models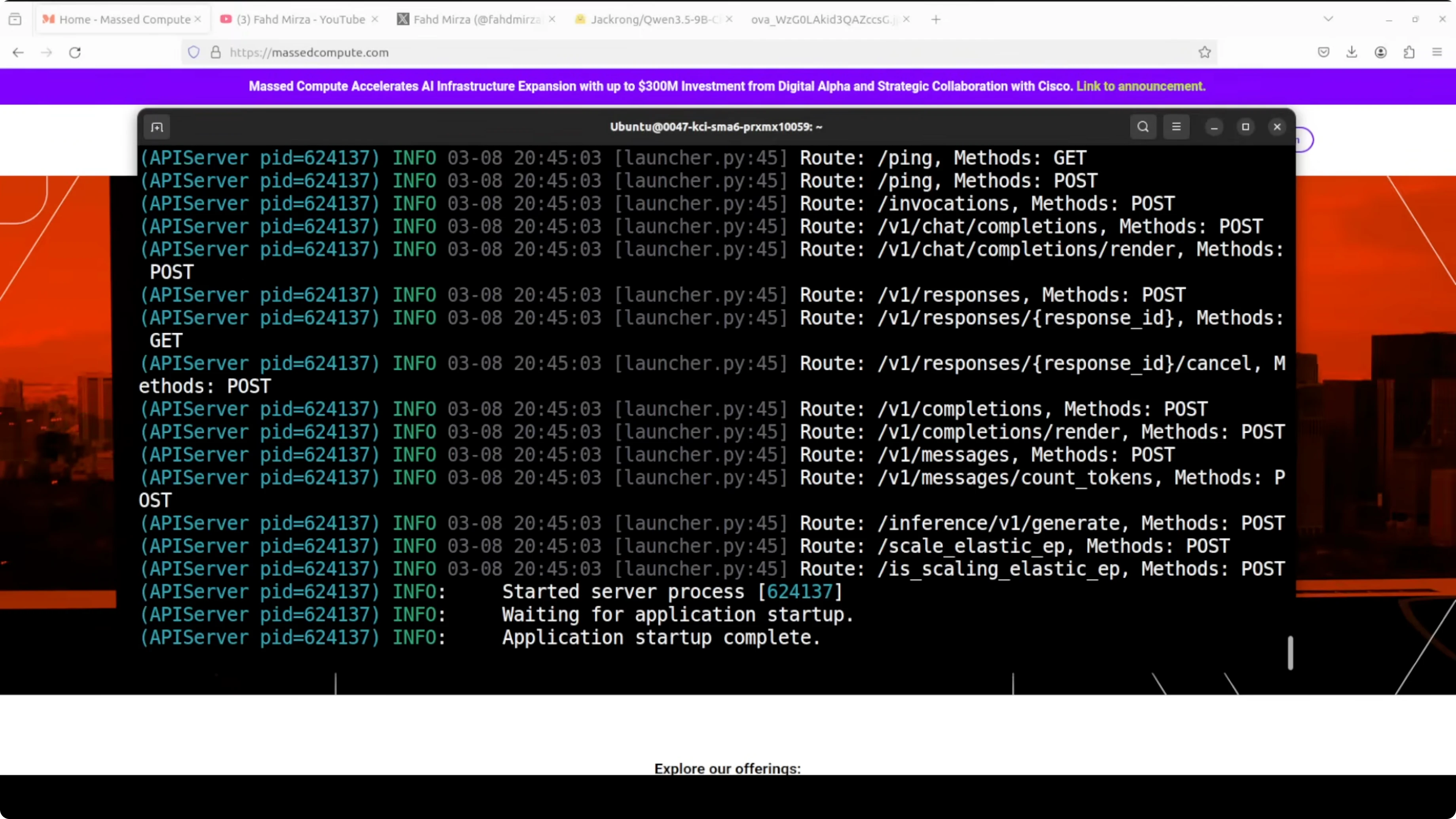
Step 4: Optional GUI with Open WebUI by pointing it at the vLLM server.
docker run -d --name open-webui -p 3000:8080 \
-e OPENAI_API_BASE_URLS=http://127.0.0.1:8000/v1 \
-e OPENAI_API_KEYS=sk-local \
open-webui/open-webui:mainStep 5: Send a test chat completion with the OpenAI-compatible API.
curl http://127.0.0.1:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "Jackrong/Qwen3.5-9B-Claude-4.6-Opus-Reasoning-Distilled",
"messages": [
{"role": "system", "content": "You are a helpful, precise assistant."},
{"role": "user", "content": "Give me a short, structured plan for a weekend hackathon."}
],
"temperature": 0.3
}'
Resource: Hugging Face model card.
Testing the reasoning
Ambiguous startup hiring question
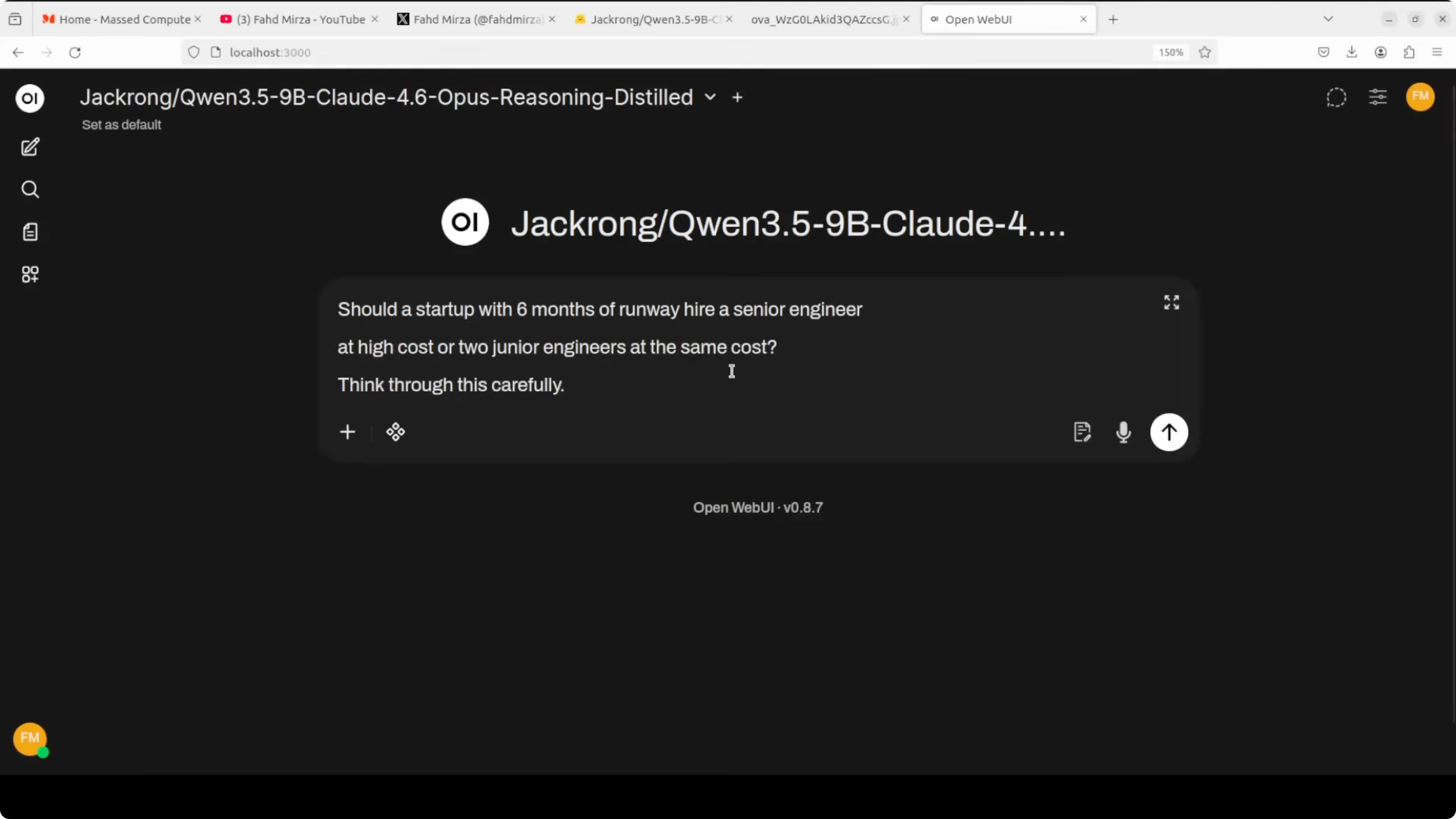
I tested an ambiguous problem with no single right answer: Should a startup with 6 months of runway hire a senior engineer at high cost or two junior engineers at the same cost. Think through this carefully. This is where reasoning style is most visible because there is no formula to follow.
A Claude-like answer immediately identifies the key variables, breaks into scenarios, and arrives at a confident conditional recommendation. That is what I saw. The final answer was confident and practical with clear if-then structure like senior when architectural leadership is needed and two juniors when implementation is the bottleneck.
If you want more context on how Opus 4.6 tends to structure plans and tradeoffs, see this short Opus 4.6 guide. The student here often echoes that structure in outputs. It thought for about 16 seconds before finishing, which felt improved.
But the think block exposed a problem. It started strong, then lost the thread and drifted into generic filler like critical insight statements that read analytical but say little. It even cut off mid sentence at the end of the think block.
My take is that the distillation influenced the output layer more than the reasoning layer. The final answer reads like Claude. The thinking process still shows Qwen’s tendency to ramble and fill space.
Trick question with no room for waffle
I used a pure logical deduction prompt with a classic twist. A red house is made of red bricks. A blue house is made of blue bricks. A green house is made of glass. What is a black house made of.
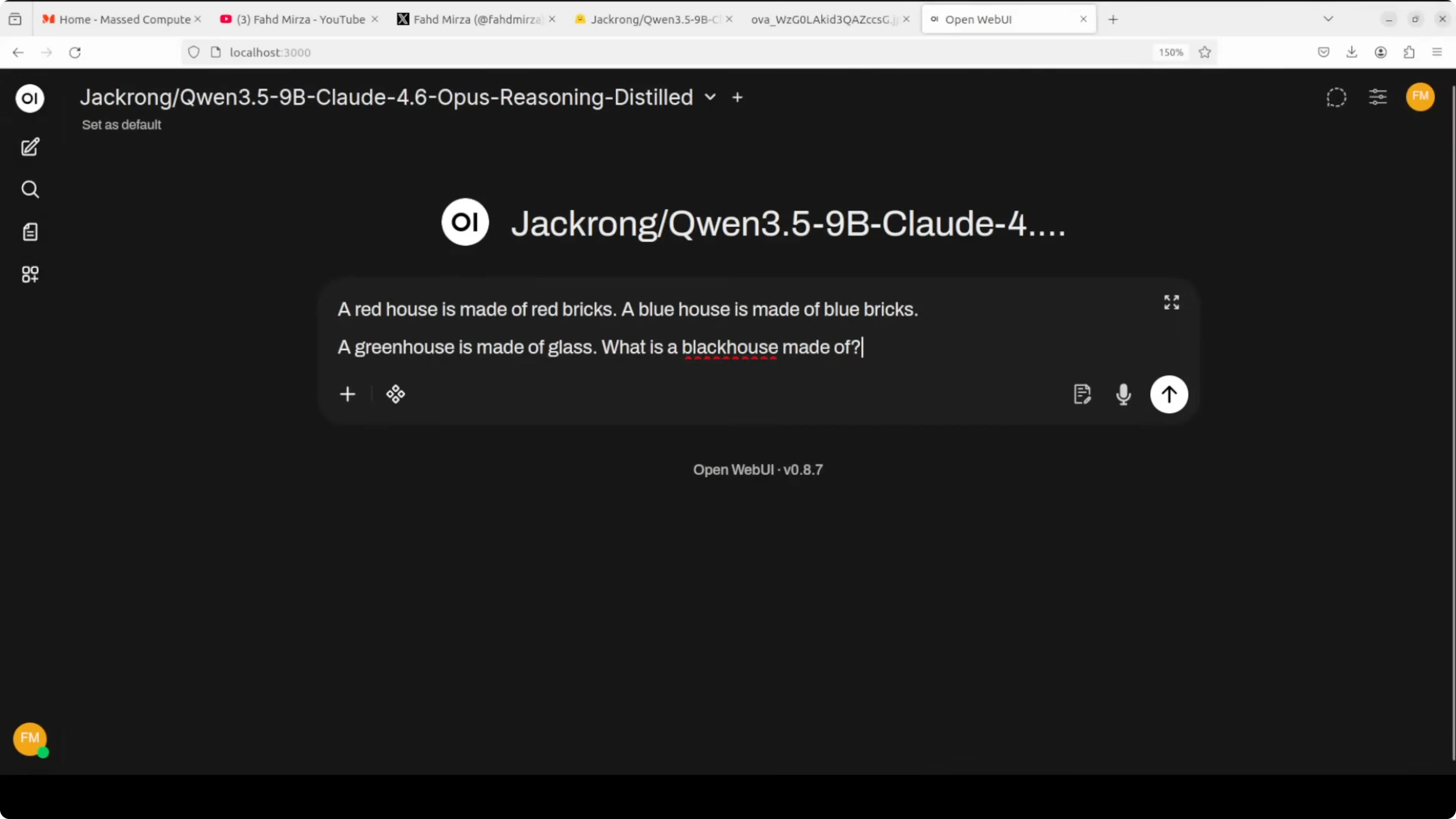
The correct answer is black bricks. The model answered nothing and then hallucinated a tangent about British slang that had nothing to do with the question.
My misdirection with greenhouse worked too well, but it did not fall for glass. It went in a third wrong direction entirely and did so confidently. That is a limit this run exposed.
What improved and what did not
The startup question showed real Claude-like structure. It clearly identified variables and delivered a conditional recommendation instead of a flat it depends.
The think traces still had Qwen’s exploratory loop bleeding through. Distillation did not fully replace it and likely suppressed it in the final answer.
I work with Claude a lot in production use cases, especially for coding. The difference I look for is confident conditional recommendations rather than cautious hedging. This student can sound like that even when the internal chain is messy.
Benchmarks snapshot
Qwen3.5-9B distilled here consistently leads or sits near the top across eight benchmarks shown to me. It beat GPT5 Nano and Gemini 2.5 Flash convincingly in almost every category in that snapshot. The most impressive line was GPQA Diamond.
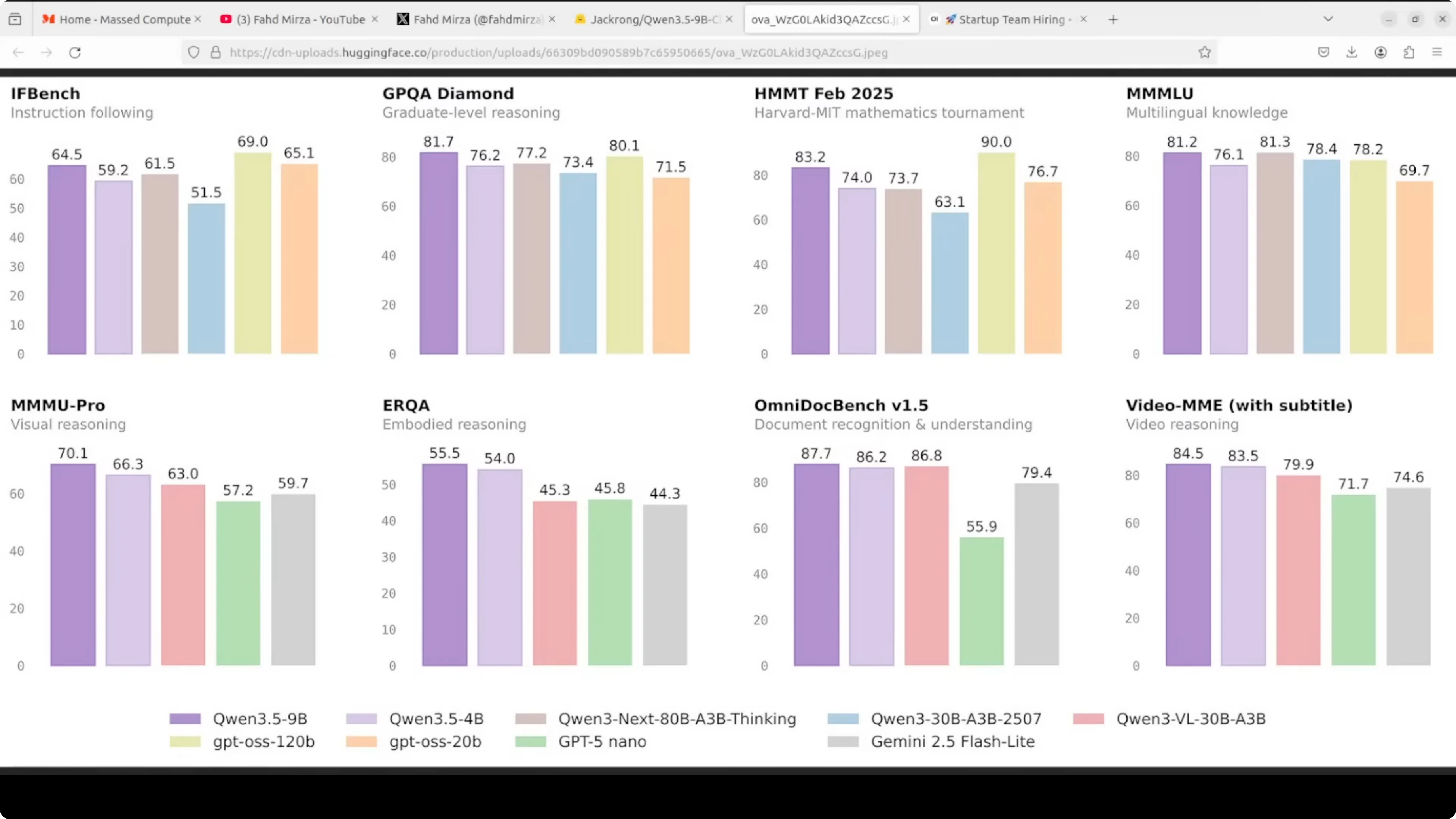
If you want to understand what changed from Opus 4.5 to Opus 4.6 during this period, see this Opus 4.6 vs Opus 4.5 comparison. For a news-style summary of the Opus 4.6 update, check this quick update. For a broader cross-family contrast, see this DeepSeek vs Opus 4.5 analysis.
Use cases and tradeoffs
Qwen3.5-9B distilled from Claude Opus 4.6
Use cases include structured decision support, short planning tasks, and coding assistance where clarity in the final answer matters. Pros include confident conditional recommendations, modular structure, and non-repetitive outputs. Cons include think traces that can ramble, occasional confident mistakes, and visible drift in long chains.
Base Qwen3.5-9B
Use cases include exploration-heavy prompts, brainstorming that benefits from looking at both sides, and cases where caution is preferred. Pros include thorough exploration and a tendency to second guess that reduces risky leaps. Cons include landing on it depends without committing and slower convergence to a clear recommendation.
Claude Opus 4.6
Use cases include production coding, complex planning, and decision making that benefits from confident conditional structure. Pros include decisive recommendations, clean variable factoring, and organized reasoning. Cons include premium access constraints and the risk that a wrong path stays confident unless corrected by constraints.
Step-by-step testing prompts
Send the ambiguous startup prompt through your vLLM server to check conditional reasoning.
curl http://127.0.0.1:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "Jackrong/Qwen3.5-9B-Claude-4.6-Opus-Reasoning-Distilled",
"messages": [
{"role": "system", "content": "You are a helpful, precise assistant."},
{"role": "user", "content": "A startup has 6 months of runway. Should it hire 1 senior engineer at high cost or 2 junior engineers at the same total cost? Think carefully and give a conditional recommendation."}
],
"temperature": 0.2
}'Then test a pure logic prompt with a known correct answer to catch confident errors.
curl http://127.0.0.1:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "Jackrong/Qwen3.5-9B-Claude-4.6-Opus-Reasoning-Distilled",
"messages": [
{"role": "system", "content": "You are a precise reasoner."},
{"role": "user", "content": "A red house is made of red bricks. A blue house is made of blue bricks. A green house is made of glass. What is a black house made of?"}
],
"temperature": 0
}'Check both the final answer and the hidden think traces if your UI exposes them. Look for structured variables up front, scenario breakdowns, and a clear conditional recommendation. Note any drift into filler or mid sentence cutoffs.
Tension around distillation
There is a real tension here. Anthropic has accused several labs of distilling their models or stealing their information, which is part of the wider discussion around teacher-student training.
The more this student sounds like Claude, the more important it is to verify it actually reasons like Claude. When the reasoning goes wrong, it can go confidently wrong, which can be more dangerous than Qwen’s cautious looping.
Final thoughts
Distillation clearly influenced the output style. The startup test showed a Claude-like structure and a decisive conditional recommendation.
The trick question exposed a limit where the model went confidently wrong. The question is if you want a model that thinks like Claude or one that just sounds like it.
For context on what Opus 4.6 brings to the table, this focused guide and this version-to-version comparison help frame expectations.
Subscribe to our newsletter
Get the latest updates and articles directly in your inbox.

Related Posts

8 Best Claude Code Plugins in 2026 (You Need to Know)
8 Best Claude Code Plugins in 2026 (You Need to Know)

7 Best Claude Code Skills (You Need to Know)
7 Best Claude Code Skills (You Need to Know)

Claude Code Desktop IDE Features (You Need to Know)
Claude Code Desktop IDE Features (You Need to Know)