
Table Of Content
- Why this benchmark - GPT-5.2 Codex vs Opus 4.5, Gemini & DeepSeek
- Comparison overview - GPT-5.2 Codex vs Opus 4.5, Gemini & DeepSeek
- Rules and constraints
- Output contract
- Attempts and repair turns
- Tasks
- Prompt structure
- Models and settings
- Results - bug fix
- Results - refactor
- Results - migration
- Step-by-step guide to reproduce
- Use cases, pros and cons
- Final thoughts - GPT-5.2 Codex vs Opus 4.5, Gemini & DeepSeek

GPT-5.2 Codex vs Opus 4.5, Gemini & DeepSeek (Bug Fix, Refactor, Migration)
Gemini API Pricing Calculator
Dynamically estimate your Google Gemini API costs for text, audio, images, and context caching. Covers new 3.1 Pro, Flash, and 2.5 models.
Table Of Content
- Why this benchmark - GPT-5.2 Codex vs Opus 4.5, Gemini & DeepSeek
- Comparison overview - GPT-5.2 Codex vs Opus 4.5, Gemini & DeepSeek
- Rules and constraints
- Output contract
- Attempts and repair turns
- Tasks
- Prompt structure
- Models and settings
- Results - bug fix
- Results - refactor
- Results - migration
- Step-by-step guide to reproduce
- Use cases, pros and cons
- Final thoughts - GPT-5.2 Codex vs Opus 4.5, Gemini & DeepSeek
If you're using AI models for real development work, the hardest part usually isn't starting something new. It's fixing bugs without breaking behavior, refactoring code that already works, and migrating larger code bases under real constraints. That is the gap this benchmark is designed to fill.
In this benchmark, each model runs through the same development focused tasks under the same constraints with measurements for correctness, output tokens, cost, wall clock time, and contract compliance. I walk through exactly how the benchmark works, the tasks and the prompts behind it, and the results from running the models through it. By the end, you'll have a clear picture of which models are best suited for real engineering work, which ones are the most cost effective, and where each model tends to succeed or break down across bug fixes, refactors, and migrations.
Why this benchmark - GPT-5.2 Codex vs Opus 4.5, Gemini & DeepSeek
A lot of model comparison tests focus on full builds, things like apps, dashboards, and games. Those tests are useful for understanding how models reason about architecture, UI decisions, and end-to-end workflows. Many of you have also been asking how these models perform on day-to-day engineering tasks.
Things like migrations, refactors, and bug fixes are the work that actually happens inside real code bases. This benchmark is a controlled baseline for comparing how models handle those tasks. Each model gets the same prompt and the same constraints with a single primary attempt per task and, if needed, one repair turn.
There are no tools, no agent loops, and no prompt tuning per model. The goal is not to simulate a full IDE workflow. It is to see how these models behave when you give them real code, strict rules, and very limited opportunity to recover.
If you want a broader look at adjacent head-to-heads, see a head-to-head of Gemini 31 Pro, Opus 46, and GPT-5.3 Codex. That context helps when you compare these baseline signals to newer releases.
Comparison overview - GPT-5.2 Codex vs Opus 4.5, Gemini & DeepSeek
| Model | Bug fix result | Refactor result | Migration result | Contract compliance notes | Relative latency | Relative cost | Notes on tokens and repair |
|---|---|---|---|---|---|---|---|
| GPT-5.2 | Pass, clean | Fail then pass on repair | Pass | Clean fenced output | Fast | Low to moderate | Low tokens on first pass |
| GPT-5.2 Codex | Pass, clean | Fail then pass on repair | Pass | Clean fenced output | Moderate | Moderate | Higher output tokens than GPT-5.2 |
| Opus 4.5 | Fail due to extra text | Fail then pass on repair | Pass | Bug fix violated fenced-output contract | Moderate | High | Higher total cost on migration |
| Gemini | Pass, clean | Fail then pass on repair | Pass | Clean fenced output | High latency | Moderate | Consistently slower wall time |
| DeepSeek | Fail due to extra text | Fail overall after single repair | Pass | Bug fix violated fenced-output contract | Slowest | Very low | Cheap but repair reliability low |
Rules and constraints
When it comes to designing a benchmark, the rules have to be clear and consistent. Execution is identical across the board. Every model gets the same prompt, the same code base, and runs through the API.
There are no tools, no IDE assistance, and no prompt tuning per model. For each task, there is one primary attempt. If the model fails, it gets a single repair turn using the same rules as every other model.
There is no iterative back and forth beyond that. Because API calls are stateless, the full prompt has to be resent on a repair turn. That has a real cost impact.
Output contract
The output contract is the most important part. Models are required to return only the code changes in a strict machine applicable format. There is no explanation text, no extra commentary, and no changes outside the allowed files.
A model can produce code that is logically correct, but still fail the benchmark if it violates the contract. In real automated workflows, correctness and compliance both matter. That is why a couple of the models are recorded as failures even though their patched code passes tests once you strip away the extra text.
Attempts and repair turns
On a repair turn, the model receives the original prompt again plus the test failure output. Repair turns significantly increase input tokens. Models that fail and need recovery are not just slower, they are also more expensive.
That is why you see such a big difference between models that pass cleanly on the first attempt and models that rely on repair turns. This benchmark is based on single controlled runs per model to surface failure modes. Future iterations will look at multi-run benchmarks to account for variance.
For a deeper view into family-level differences around Opus releases, see the differences between Opus 4.6 and Opus 4.5. Those details map cleanly onto the compliance and latency signals you see here.
Tasks
The bug fix task is about behavioral correctness. The goal is not to rewrite code or clean it up. It is to fix a specific issue while preserving everything else including defaults, edge cases, and existing behavior.
The refactor task is different. The code already works and the challenge is to change the structure without changing the outcome. This is where models tend to struggle with subtle regressions or overediting.

The migration task is the most involved. It requires coordinated changes across multiple files, often converting APIs or async patterns while still preserving behavior and respecting existing contracts. Together, these three tasks cover a large part of real world engineering work and they each stress a different kind of capability.
Prompt structure
Here is an example of one of the actual benchmark prompts for the bug fix task. The model gets the full repo snapshot, about 73,000 characters across 29 files, along with the tests that define the expected behavior. The goal is simple: fix the bug so the tests pass without touching tests or package configuration and only editing files under source.
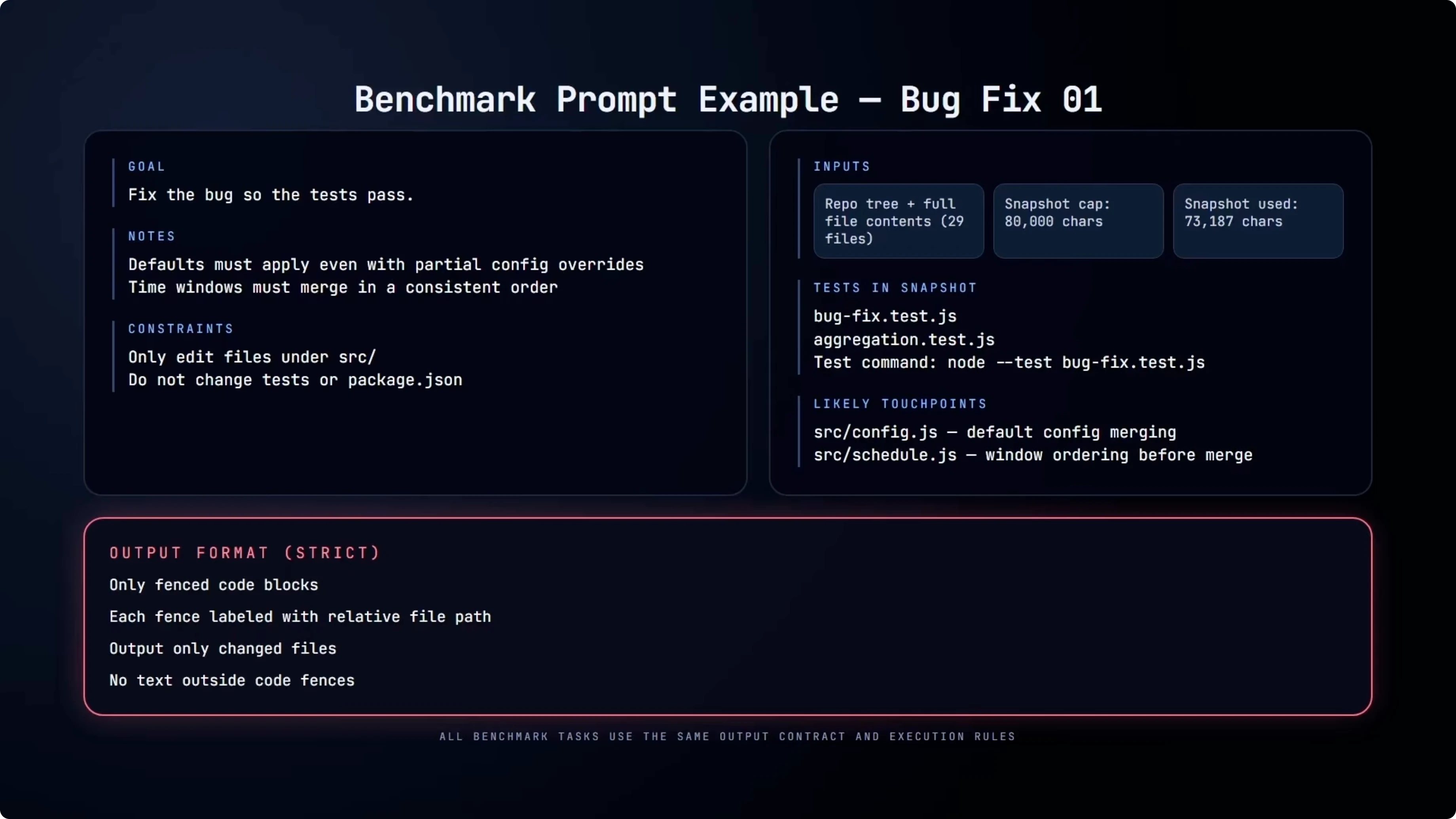
The output must be returned as fenced code blocks labeled by file path. No diffs, no explanations, just machine applicable changes. Refactor and migration use the same structure with different constraints and goals.
Example output contract format:
```// src/utils/normalize.js
export function normalize(input) {
// updated logic here
}export function toTags(input) {
// updated logic here
}Models and settings

Here are the five models used in this baseline: GPT-5.2, GPT-5.2 Codex, Opus 4.5, Gemini, and DeepSeek. All runs were executed at temperature 0. Given the same input, they are pushed to produce the same output every time.
For Codex specifically, I am using the default reasoning setting. The tasks are simple enough that Codex performs well without higher reasoning modes. As we move into more advanced multi-turn benchmarks, higher reasoning settings become more relevant.
I also note the base input and output token pricing for each model to frame raw cost context. This is not showing benchmark results, just the starting price points. That is important when we later look at measured token usage and total cost under the same tasks and constraints.
If cost is central to your decision, see cost and latency patterns between Opus 46 and GPT-5.3 Codex. Those patterns echo what you will see in this baseline on larger migrations.
Results - bug fix

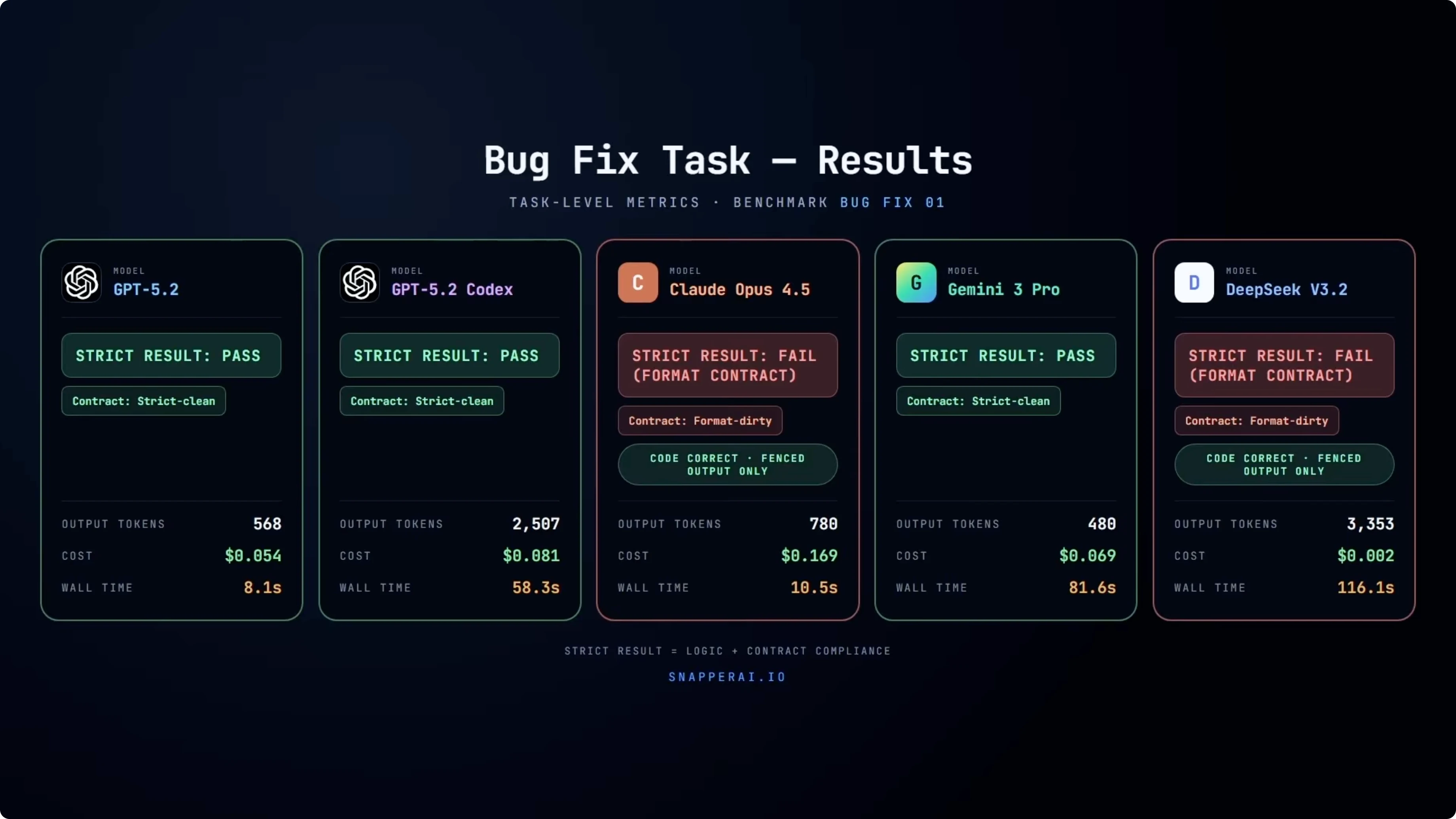
GPT-5.2, GPT-5.2 Codex, and Gemini all pass this cleanly. The tests pass and the output strictly complies with the contract. Opus 4.5 and DeepSeek are more interesting.
In both cases, the code itself is correct. If you take only the fenced code blocks and apply them, the tests pass. Under the benchmark rules, both are recorded as failures because they included text outside the fenced output.
In an automated workflow, that is not a small detail. It breaks the pipeline entirely. The contract explicitly states that the output must contain only the code required for the fix.
Looking at efficiency, GPT-5.2 solves this task quickly with low token usage. Codex reaches the same result, but with noticeably higher output tokens and longer wall clock time. Gemini passes cleanly but with higher latency.
DeepSeek is extremely cheap but also the slowest here. Even on the simplest task in the suite, you see clear trade-offs between correctness, compliance, latency, and cost. Those differences become more pronounced as the tasks get more complex.
Results - refactor
For the refactor task, the code already works and the goal is to remove duplicated normalization logic by extracting shared helpers into normalize.js and tags.js while keeping behavior identical and tests passing. Every model fails the initial attempt. For GPT-5.2, Codex, Opus 4.5, and Gemini, it is the same edge case.
The refactor breaks a serial fallback behavior. When serial is empty, it should fall back to the ID, but the initial output leaves it as an empty string. Where they diverge is recovery.
Those four models fix it on the repair turn and pass overall. DeepSeek is the outlier. It fails the initial run for a different reason, a missing normalized slug reference.
The repair turn fixes that issue but then exposes the same serial fallback edge case the other models hit on their first attempt. Because the benchmark allows only a single repair turn, DeepSeek does not get a second chance to fix the edge case and fails overall. It is possible that with additional repair turns, it would have converged on the same solution as the other models.
At that point, wall time and input costs start to become real trade-offs even for a cheaper model. It is worth considering that this was potentially a recovery budget constraint issue rather than a formatting issue under these rules. You can also see the efficiency trade-offs.
GPT-5.2 recovers quickly. Codex takes longer and uses more output tokens. Gemini passes but with much higher wall clock time.
DeepSeek stays extremely cheap but less reliable under repair. That reliability signal becomes important once models are required to fix their own mistakes. This is a key capability for production workflows.
For related third-party families under similar refactor pressure, see a compact comparison of GLM-5, Opus 46, and GPT-5.3 Codex. It pairs well with the recovery and compliance signals here.
Results - migration
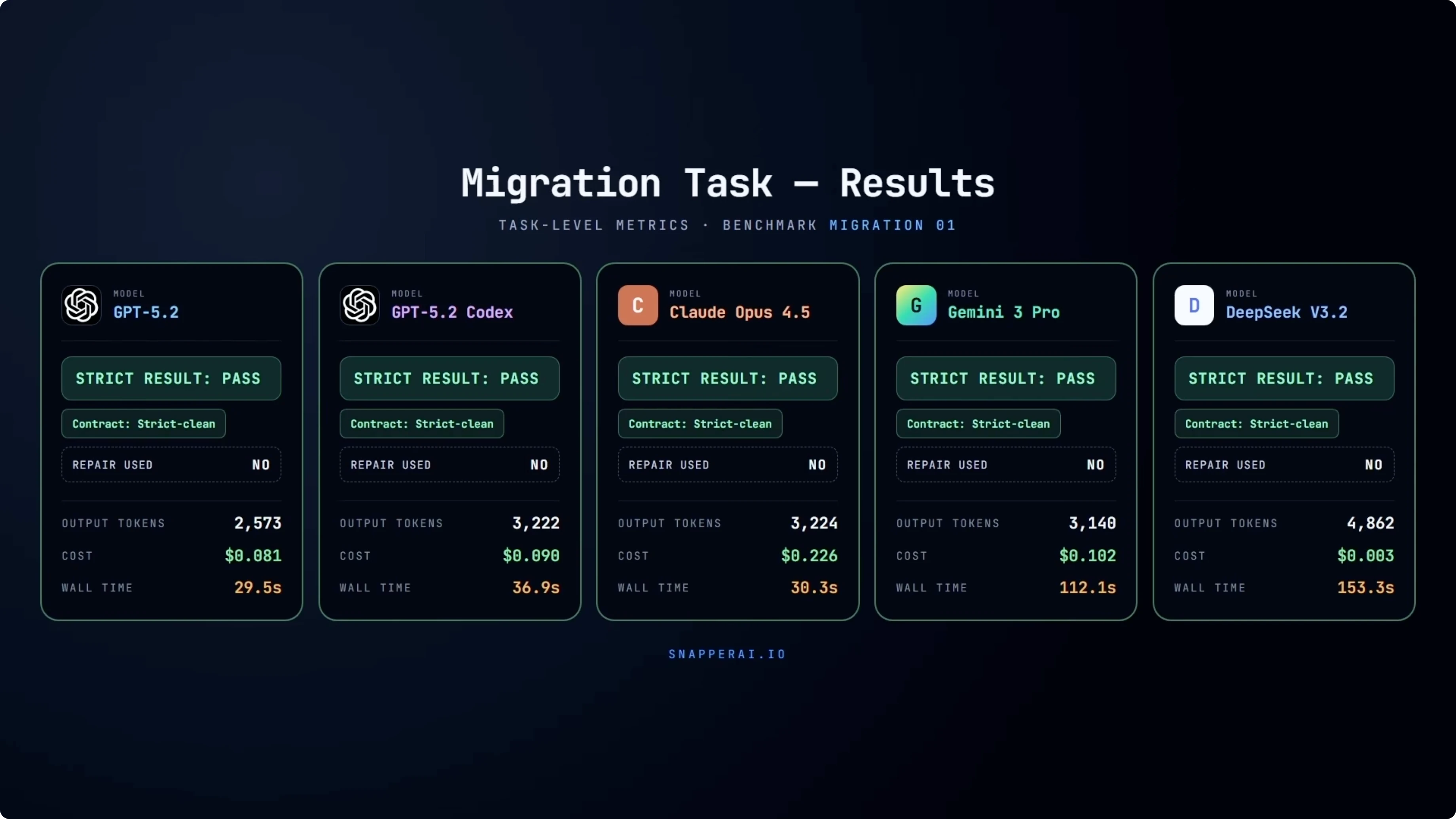
This is the most complex test in the suite. The task requires coordinated changes across multiple files, updating APIs and structure while keeping behavior intact. All models pass cleanly.
No repairs are needed and there are no contract violations. Where things really diverge is efficiency. GPT-5.2 and Codex both complete the migration quickly with relatively low output tokens and wall clock time.
Opus 4.5 also passes cleanly but at a significantly higher cost. Gemini again produces correct output but with much higher latency. DeepSeek remains extremely cheap but is by far the slowest in wall clock time.
What is interesting is that each task in this benchmark exposed a different kind of stress point. The bug fix surfaced format discipline and basic correctness under strict automation. The refactor surfaced recovery and robustness when a model has to fix its own mistake.
The migration surfaced coordination and efficiency once changes span multiple files. These signals together create a practical baseline for production use. They also make it easier to choose a default model for a given workflow stage.
For cross-family results on other stacks, see a broader set of signals in GPT-5.3 Codex vs Opus, Kimi, and Qwen. That reading extends the migration findings here.
Step-by-step guide to reproduce
Gather the full repo snapshot and tests that define expected behavior, keeping the snapshot around 73,000 characters across approximately 29 files. Ensure your harness restricts edits to source files only and blocks any changes to tests or package configuration.
Run each model through the same API with temperature 0 and no tools, no IDE assistance, and no per-model prompt tuning. Provide a single primary attempt per task and, if needed, one repair turn that resends the full original prompt plus the test failure output.
Enforce the output contract by accepting only fenced code blocks labeled by file path and rejecting any extra commentary or diffs. Measure correctness via tests, track input and output tokens, compute total cost, record wall clock time, and log any contract violations as failures even if the code is otherwise correct.
For a complementary cost and latency cross-check on a nearby lineup, compare your results to this focused analysis of Opus 46 vs GPT-5.3 Codex. It helps normalize expectations on larger or longer prompts.
Use cases, pros and cons
GPT-5.2: Use cases include fast bug fixes and reliable first-pass migrations under strict automation. Pros include clean contract compliance, low tokens, and quick passes on smaller tasks. Cons show up as none notable in this baseline beyond not being the cheapest.
GPT-5.2 Codex: Use cases include structured refactors and multi-file migrations with deterministic settings. Pros include high pass rates and strong coordination, with predictability at temperature 0. Cons include higher output tokens and longer wall time than GPT-5.2 on the same tasks.
Opus 4.5: Use cases include refactors and migrations that prioritize quality even at higher price points. Pros include successful recovery on refactors and clean migrations. Cons include contract violations on bug fix output format and significantly higher cost.
Gemini: Use cases include correctness-focused passes where latency is not critical. Pros include clean passes across tasks and reliable recovery on refactor. Cons include much higher wall clock time across the suite.
DeepSeek: Use cases include cost-constrained migrations and low-cost experimentation. Pros include extremely low price and correct code once formatted and applied. Cons include contract violations on bug fix, slower wall clock time, and failure to recover within a single repair turn on refactor.
If you want a broader framing across adjacent contenders, compare a compact trio in this cross-family roundup. It contextualizes pros and cons beyond this single baseline.
Final thoughts - GPT-5.2 Codex vs Opus 4.5, Gemini & DeepSeek
Strict automation matters. Under the output contract, Opus 4.5 and DeepSeek fail the bug fix task not because the code is wrong, but because they include text outside the fenced output and that alone is enough to break the pipeline.
Recovery under constraint is a key reliability signal. In the refactor task, most models fail the first attempt but recover cleanly when given a single repair turn, while DeepSeek does not recover within that repair budget.
Cost and latency are real trade-offs. Opus 4.5 is consistently the most expensive, Gemini produces correct results with higher wall clock time, DeepSeek is extremely cheap but slow and less reliable once recovery is required, and GPT-5.2 delivers the fastest clean passes on the smaller tasks. This baseline is not about ranking models, it is about making failure modes, trade-offs, and reliability visible under the same constraints.
Subscribe to our newsletter
Get the latest updates and articles directly in your inbox.

Related Posts

8 Best Claude Code Plugins in 2026 (You Need to Know)
8 Best Claude Code Plugins in 2026 (You Need to Know)

7 Best Claude Code Skills (You Need to Know)
7 Best Claude Code Skills (You Need to Know)

Claude Code Desktop IDE Features (You Need to Know)
Claude Code Desktop IDE Features (You Need to Know)