
Table Of Content
- Gemma 4 26B A4B vs Qwen3.5 35B A3B
- Local setup with vLLM - Gemma 4 26B A4B vs Qwen3.5 35B A3B
- Serve Gemma 4 26B A4B
- gemma.py
- Serve Qwen3.5 35B A3B
- qwen.py
- Coding challenge - Gemma 4 26B A4B vs Qwen3.5 35B A3B
- Multilingual translation - Gemma 4 26B A4B vs Qwen3.5 35B A3B
- Creative writing - Gemma 4 26B A4B vs Qwen3.5 35B A3B
- Practical use cases
- Final thoughts

Gemma 4 26B A4B vs Qwen3.5 35B A3B
Qwen Model Recommender
Not sure which Qwen model fits your GPU? Pick your VRAM, use case, and task type — get matched to the right model instantly. Covers Qwen3, QwQ, QVQ, Qwen2.5-VL, Qwen3-Coder, Qwen3-TTS, and 80+ models.
Table Of Content
- Gemma 4 26B A4B vs Qwen3.5 35B A3B
- Local setup with vLLM - Gemma 4 26B A4B vs Qwen3.5 35B A3B
- Serve Gemma 4 26B A4B
- gemma.py
- Serve Qwen3.5 35B A3B
- qwen.py
- Coding challenge - Gemma 4 26B A4B vs Qwen3.5 35B A3B
- Multilingual translation - Gemma 4 26B A4B vs Qwen3.5 35B A3B
- Creative writing - Gemma 4 26B A4B vs Qwen3.5 35B A3B
- Practical use cases
- Final thoughts
Yesterday I ran Gemma 4 26B A4B and Qwen3.5 35B A3B head to head on a single GPU under identical rules. Both are mixture of experts models that only activate a small portion of weights per token. Gemma activates about 3.8 billion parameters per token and Qwen activates about 3 billion.
Even with very large total parameter counts, each runs roughly at the speed of a 4 billion model while carrying much broader knowledge. That is the efficiency promise of MoE in practice. On paper, their model card benchmarks are extremely close across most suites.
Qwen leads on Codeforces ELO and agent tasks, while Gemma leads on LiveCodeBench and multilingual. Treat those prefilled numbers as a soft guide. The point here is a direct local test across coding, multilingual, and style mimicry.
See a broader speed, cost, and quality comparison framework here to ground expectations before local runs.
Gemma 4 26B A4B vs Qwen3.5 35B A3B
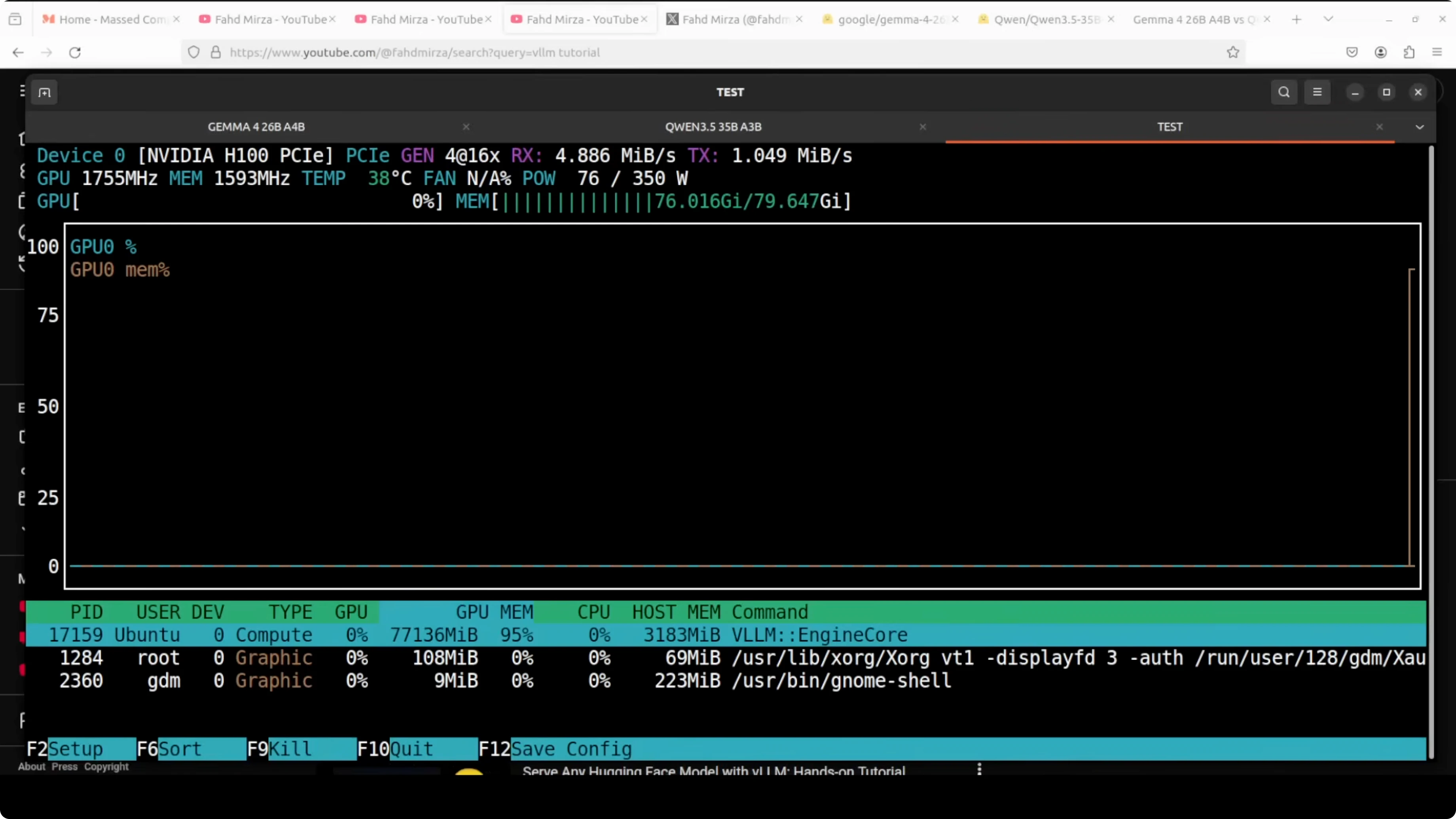
I ran both models on an Ubuntu server with an Nvidia H100 80 GB. VRAM consumption for each service was a little over 77 GB including fully loaded weights, KV cache, CUDA graphs, and runtime buffers.
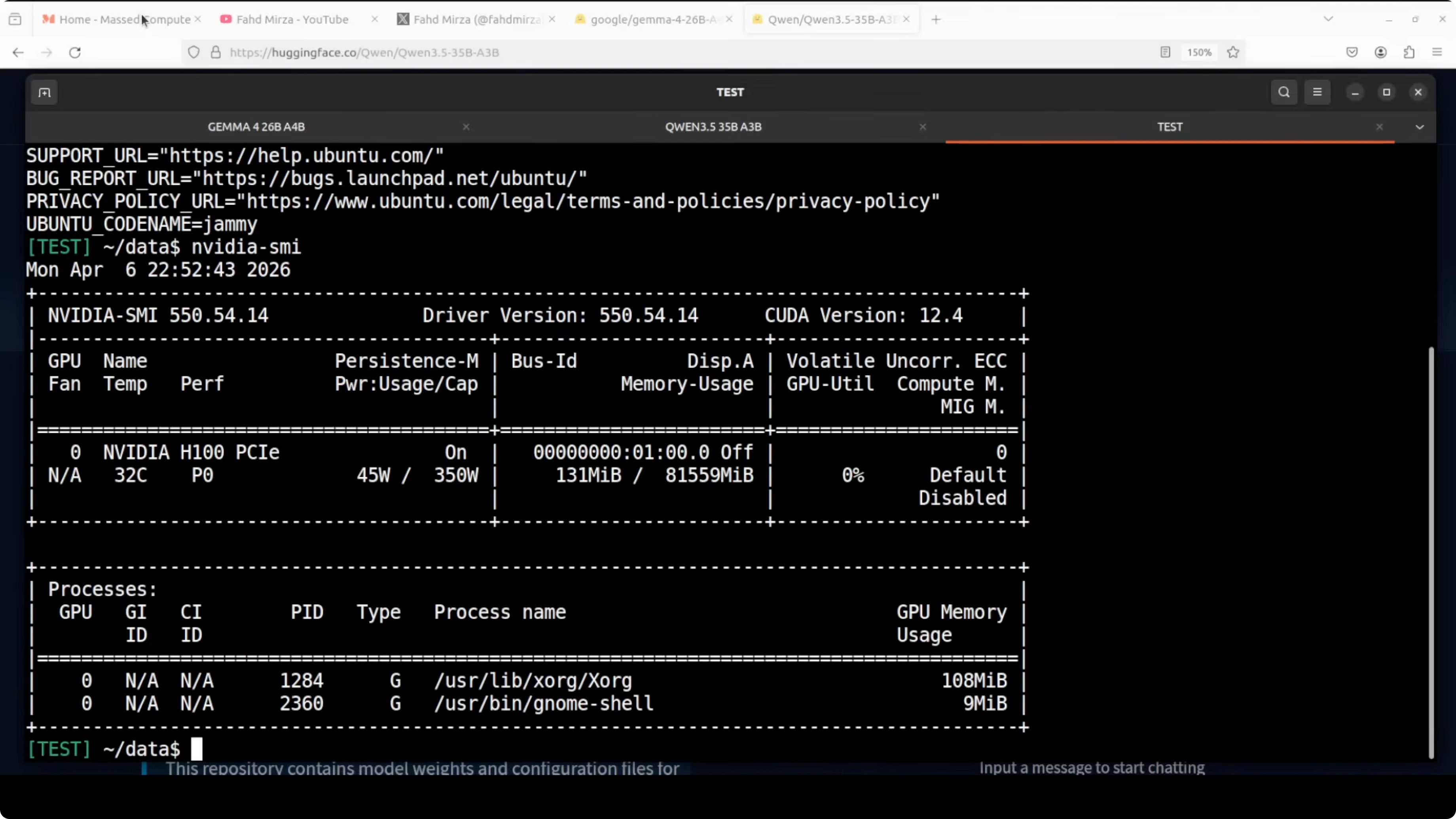
Thinking and reasoning were turned on for both during tests. The focus was parity of setup and prompts.
Local setup with vLLM - Gemma 4 26B A4B vs Qwen3.5 35B A3B
I served both models locally with vLLM using the OpenAI-compatible API. Below are clean, reproducible commands and clients that mirror the run.
Serve Gemma 4 26B A4B
Replace /models/gemma-4-26b-a4b with your local path or model ID.
python -m vllm.entrypoints.openai.api_server \
--model /models/gemma-4-26b-a4b \
--dtype bfloat16 \
--max-model-len 8192 \
--tensor-parallel-size 1 \
--port 8000Check VRAM in another shell to confirm load.
nvidia-smiCreate a small client to send prompts to the local server.
# gemma.py
from openai import OpenAI
client = OpenAI(base_url="http://localhost:8000/v1", api_key="sk-local")
prompt = """Create a complete single-file HTML app for a pet hotel management system.
It must include:
- Full CRUD for pets and bookings
- State management with dynamic UI updates
- Occupancy tracking for rooms with check-in and check-out
- Pet profiles, data and stats panes
- Polished responsive design
- No canvas tricks
"""
resp = client.chat.completions.create(
model="gemma-4-26b-a4b",
messages=[{"role": "user", "content": prompt}],
temperature=0.2,
max_tokens=4000,
)
html = resp.choices[0].message.content
with open("paw_gemma.html", "w", encoding="utf-8") as f:
f.write(html)
print("Saved paw_gemma.html")Serve Qwen3.5 35B A3B
Stop the Gemma server or start Qwen on a different port. Replace /models/qwen-3_5-35b-a3b with your local path or model ID.
python -m vllm.entrypoints.openai.api_server \
--model /models/qwen-3_5-35b-a3b \
--dtype bfloat16 \
--max-model-len 8192 \
--tensor-parallel-size 1 \
--port 8001Confirm VRAM again to verify similar allocation.
nvidia-smiUse the same prompt through a separate client pointed at the Qwen service.
# qwen.py
from openai import OpenAI
client = OpenAI(base_url="http://localhost:8001/v1", api_key="sk-local")
prompt = """Create a complete single-file HTML app for a pet hotel management system.
It must include:
- Full CRUD for pets and bookings
- State management with dynamic UI updates
- Occupancy tracking for rooms with check-in and check-out
- Pet profiles, data and stats panes
- Polished responsive design
- No canvas tricks
"""
resp = client.chat.completions.create(
model="qwen-3_5-35b-a3b",
messages=[{"role": "user", "content": prompt}],
temperature=0.2,
max_tokens=4000,
)
html = resp.choices[0].message.content
with open("paw_qwen.html", "w", encoding="utf-8") as f:
f.write(html)
print("Saved paw_qwen.html")Coding challenge - Gemma 4 26B A4B vs Qwen3.5 35B A3B
Prompt: build a fully functional pet hotel manager as a single HTML file. It must implement real CRUD, stateful UI updates, occupancy tracking, booking forms with validation, stats panels, and a polished layout.
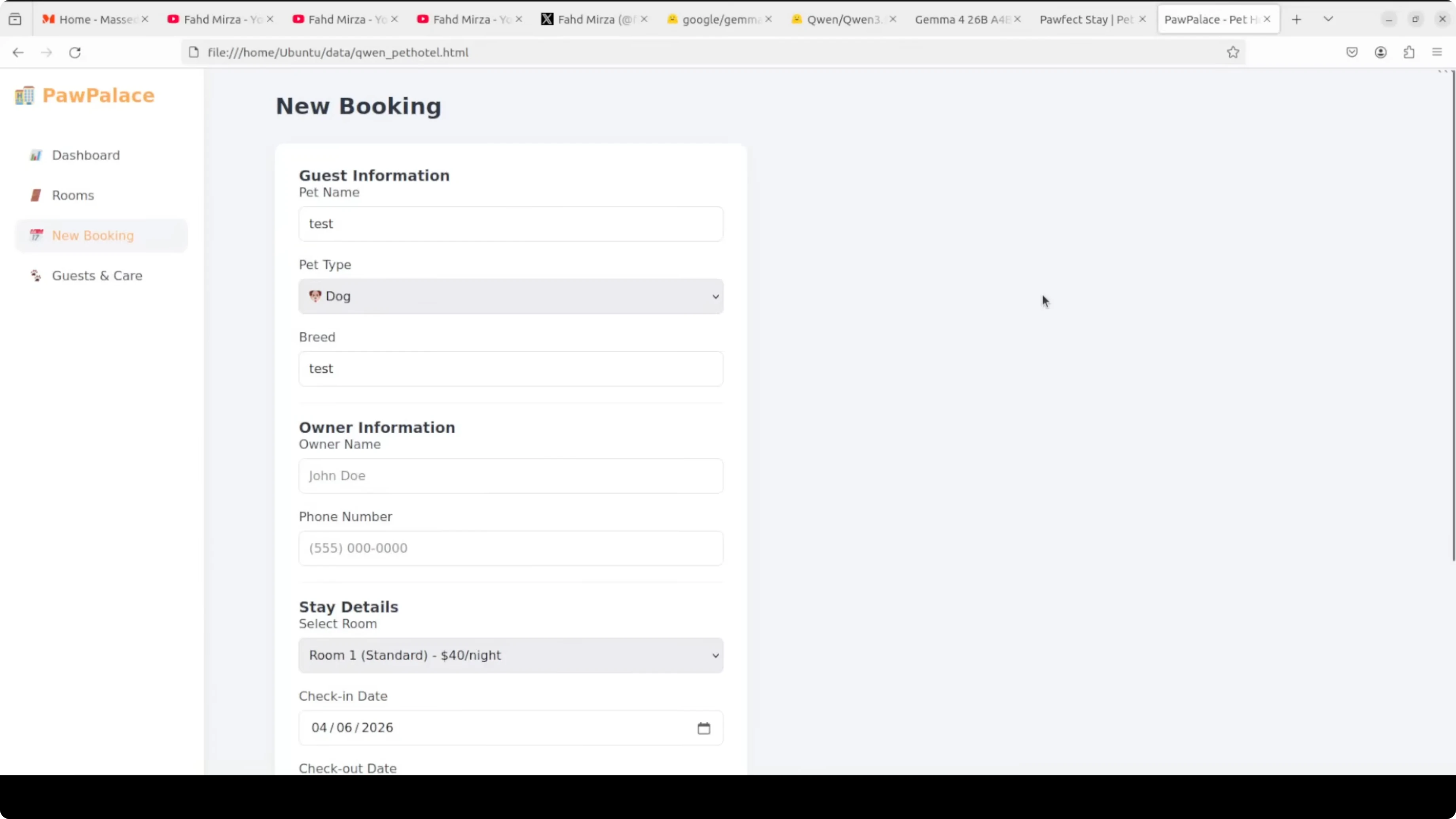
Qwen’s output stood out in end-to-end functionality. The dashboard booted cleanly, rooms initialized vacant, estimated cost updated correctly when dates changed, and all CRUD actions reflected across dashboard and rooms.
The booking form validated missing fields and surfaced a clear error. Check-in and check-out flows updated occupancy immediately, and the overall design looked coherent.
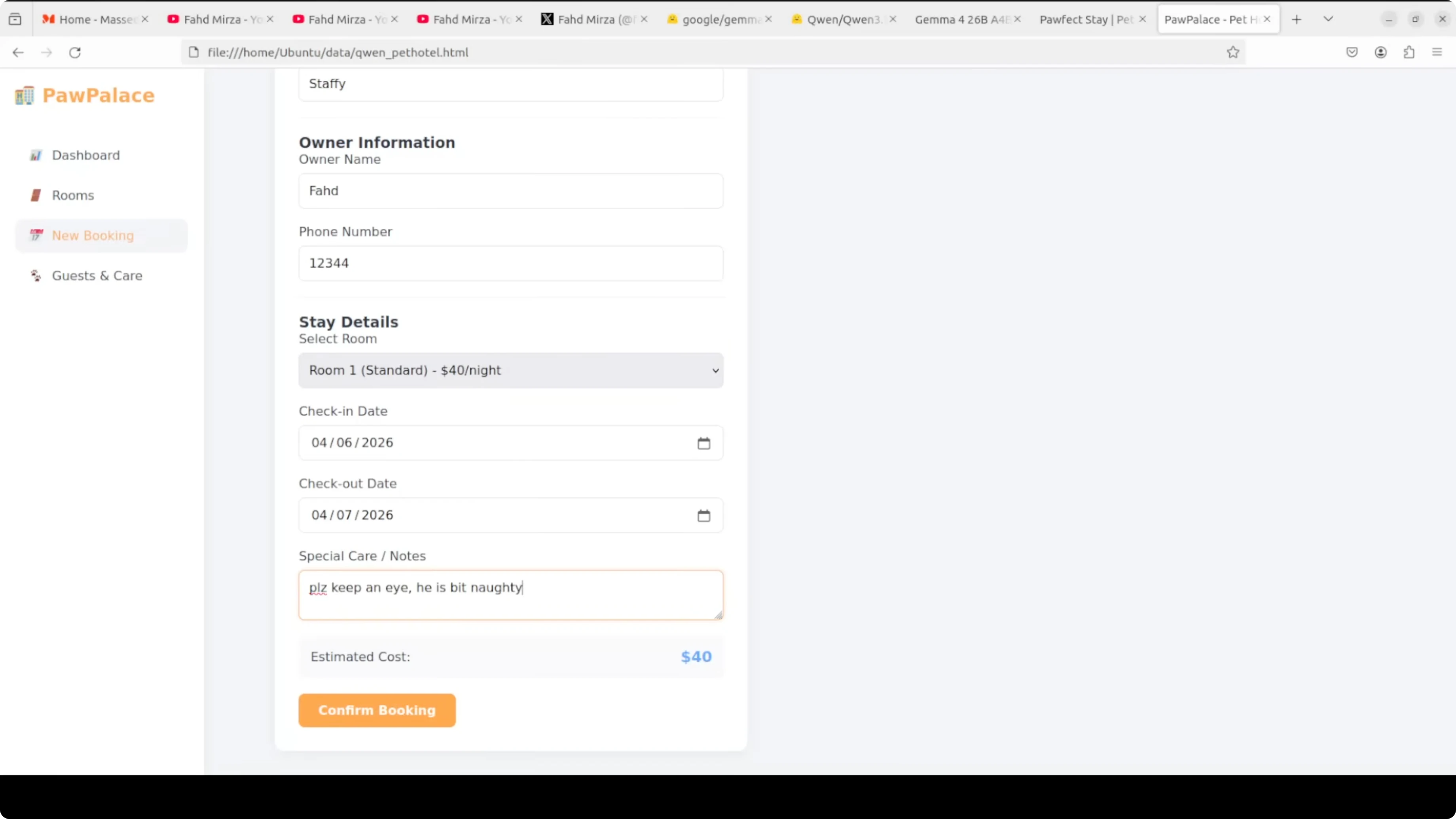
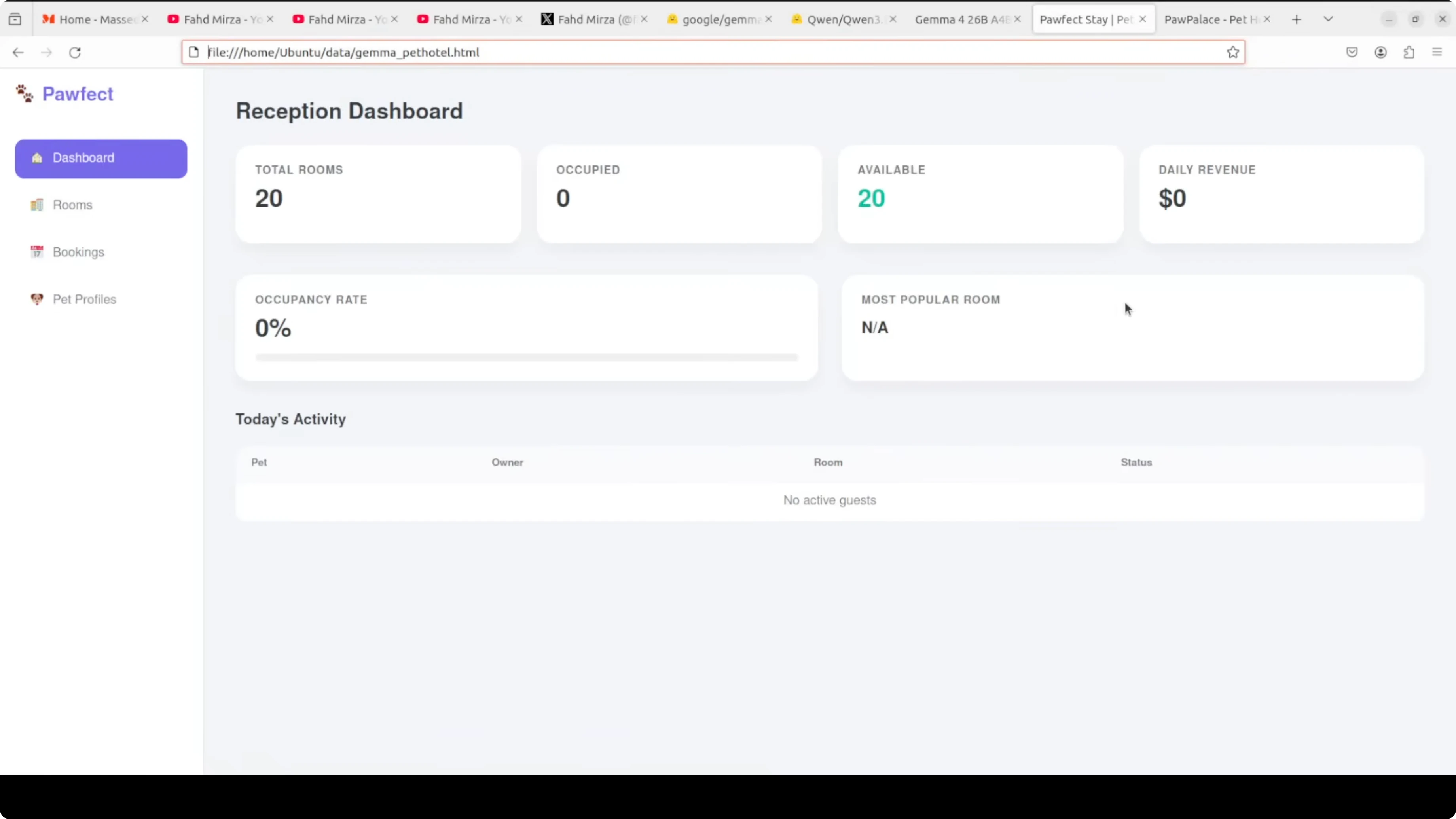
Gemma’s output looked clean, with thoughtful touches like floors for room grouping. It did not surface estimated cost during booking and offered fewer booking options and validations in this prompt-constrained single file.
I also did not find a clear checkout action in the Gemma file during spot checks. Given parity on prompt and settings, Qwen takes the coding round by a very small margin on functionality and instruction following.
For more code-centric model matchups, see this code-focused comparison for additional context on code generation behavior.
Multilingual translation - Gemma 4 26B A4B vs Qwen3.5 35B A3B
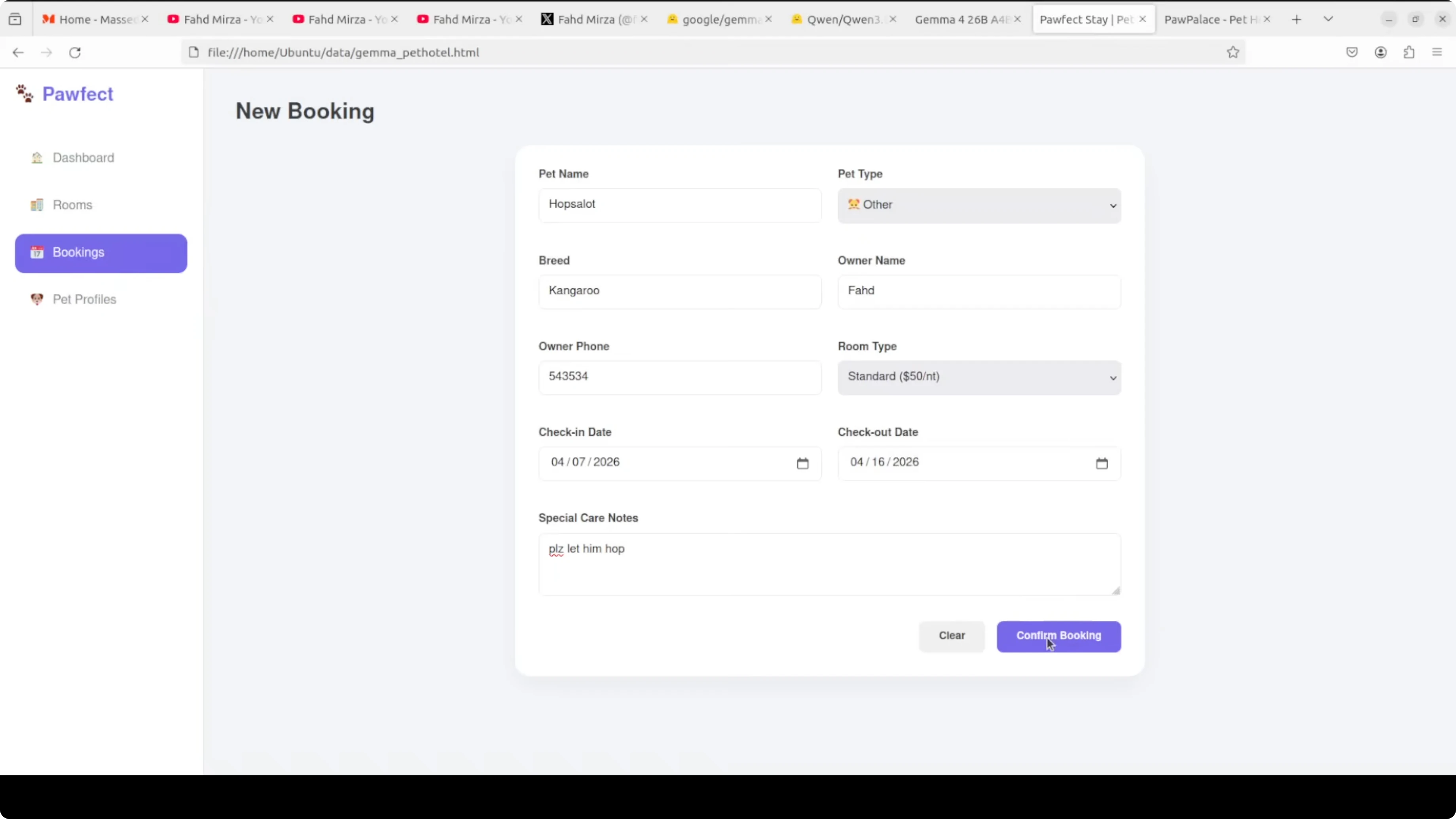
Scenario prompt: a tour guide in the Sundarbans whispers to tourists after spotting a royal Bengal tiger. The line to translate carried number handling, urgency, gendered reference, and required natural tone across 78 languages.
Both models produced complete sets. Gemma’s output was cleaner and more consistent across the board, and rare South Asian languages like Maithili and Bhojpuri were distinct rather than reused.
Qwen introduced a few specific errors. Tagalog output used 30 in instead of 30 m, Greek mentioned a Venezuelan tiger, and Amharic and Tigrinya appeared copy-pasted. Gemma wins the multilingual round.
If you track multilingual and reasoning spreads across families, see this multi-model comparison as a complementary reference.
Creative writing - Gemma 4 26B A4B vs Qwen3.5 35B A3B
Task: capture Pablo Neruda’s signature voice in exactly four lines with sensory body imagery, nature metaphors, breathless intimacy, and romantic longing. Both produced good poems within the constraint.
Gemma leaned on classic Neruda territory with tide, ocean, wine, fire, roots, and earth. It felt passionate and warm but somewhat predictable for the style.
Qwen’s lines used original imagery like dissolve into the ferns of your spine and drinking silence that felt closer to Neruda’s surreal edge. Qwen wins the poetry round on image freshness.
For a look at stylistic control and long-form compositional differences in other pairs, you can also check this head-to-head analysis.
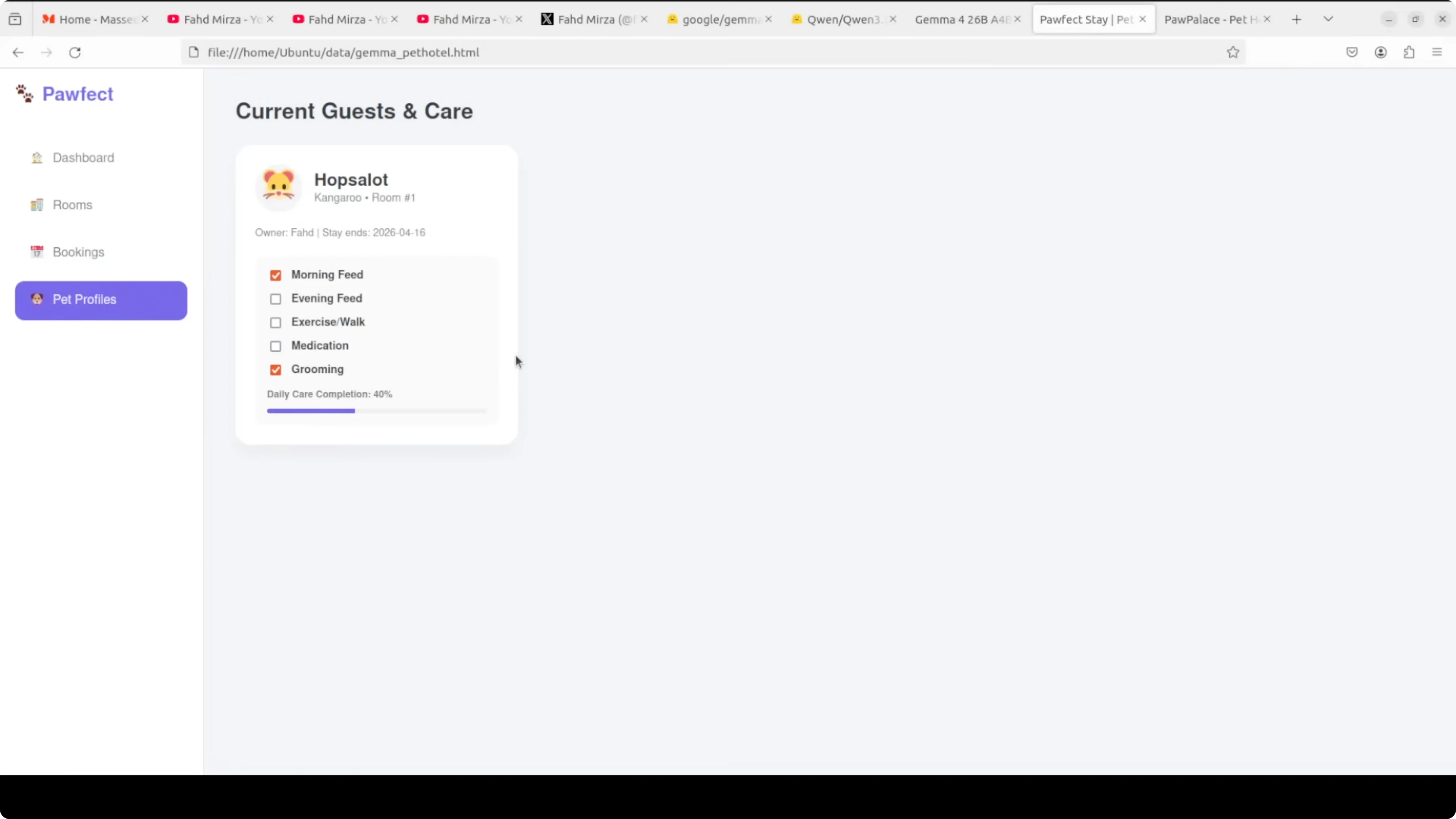
Practical use cases
If you want a local coding assistant that favors stricter form validation, live cost calculations, and tight CRUD conformance in compact prompts, Qwen3.5 35B A3B is a strong pick. It matched the HTML app spec closely and kept state transitions crisp.
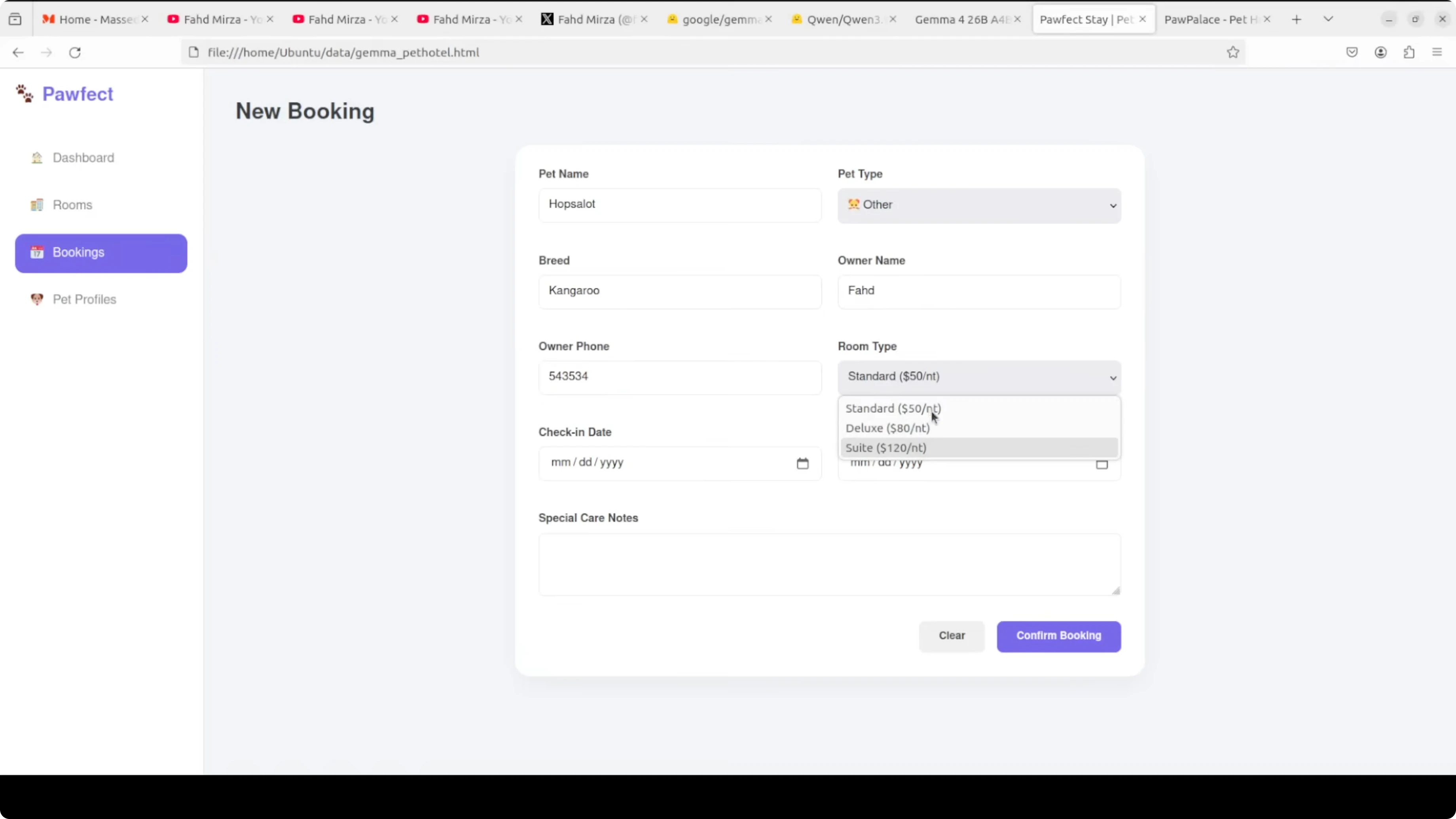
If your top need is multilingual reliability across a very wide language set, Gemma 4 26B A4B showed cleaner coverage and fewer oddities in rare languages. It also kept the urgency of the original line intact.
For broader planning across model tiers, see how upgrade deltas matter in this version-to-version comparison to set expectations on incremental gains.
Final thoughts
On this local MoE faceoff, Qwen3.5 35B A3B edged out Gemma 4 26B A4B on the coding and poetry tasks by a slim margin. Gemma answered with a clean win on the multilingual stress test.
Both ran near 4B-model speed while lighting up only a few billion active parameters per token. If you care most about form fidelity in compact, single-file app prompts, start with Qwen, and if language coverage is critical, start with Gemma.
For more context on performance tradeoffs across families and sizes, see a step-up analysis and a speed and cost overview before you lock in a local stack.
Subscribe to our newsletter
Get the latest updates and articles directly in your inbox.

Related Posts

8 Best Claude Code Plugins in 2026 (You Need to Know)
8 Best Claude Code Plugins in 2026 (You Need to Know)

7 Best Claude Code Skills (You Need to Know)
7 Best Claude Code Skills (You Need to Know)

Claude Code Desktop IDE Features (You Need to Know)
Claude Code Desktop IDE Features (You Need to Know)