
Table Of Content
- Gemma-4 31B vs Qwen3.5 27B: Local Model Comparison
- Test setup and environment
- Coding test: complex simulation in a single HTML file
- Prompt summary
- Observations
- Multilingual test: fashion show opening announcement
- English source line
- Task
- Observations
- Vision and reasoning test: handwritten physics equations
- Prompt summary
- Observations
- Features Breakdown
- Gemma-4 31B
- Model traits
- On-paper benchmarks
- Qwen3.5 27B
- Model traits
- On-paper benchmarks
- Pros and Cons
- Gemma-4 31B
- Pros
- Cons
- Qwen3.5 27B
- Pros
- Cons
- Use Cases and Scenarios
- Where Gemma-4 31B excels
- Where Qwen3.5 27B excels
- Final Conclusion

Gemma-4 31B vs Qwen3.5 27B: Local Model Comparison
Qwen Model Recommender
Not sure which Qwen model fits your GPU? Pick your VRAM, use case, and task type — get matched to the right model instantly. Covers Qwen3, QwQ, QVQ, Qwen2.5-VL, Qwen3-Coder, Qwen3-TTS, and 80+ models.
Table Of Content
- Gemma-4 31B vs Qwen3.5 27B: Local Model Comparison
- Test setup and environment
- Coding test: complex simulation in a single HTML file
- Prompt summary
- Observations
- Multilingual test: fashion show opening announcement
- English source line
- Task
- Observations
- Vision and reasoning test: handwritten physics equations
- Prompt summary
- Observations
- Features Breakdown
- Gemma-4 31B
- Model traits
- On-paper benchmarks
- Qwen3.5 27B
- Model traits
- On-paper benchmarks
- Pros and Cons
- Gemma-4 31B
- Pros
- Cons
- Qwen3.5 27B
- Pros
- Cons
- Use Cases and Scenarios
- Where Gemma-4 31B excels
- Where Qwen3.5 27B excels
- Final Conclusion
Two of the best open-source models in the same weight class, on the same hardware, one GPU, one winner. This is a head-to-head comparison between Google DeepMind’s Gemma-4 31B and Alibaba’s Qwen3.5 27B. Both are dense, multimodal, Apache-2.0 models running locally on a single GPU, tested on coding, reasoning, vision, and multilingual tasks with identical prompts and identical parameters.
No cherry-picking, no favoritism. On paper it is too close to call, which is exactly why I ran the tests myself. I run a lot of open-source Apache-2 models for clients and I need to decide what to use going forward, Gemma-4 or Qwen3.5.
For a full written breakdown of this matchup, see this side-by-side comparison too: Gemma 4 vs Qwen3.5 analysis.
| Category | Gemma-4 31B | Qwen3.5 27B |
|---|---|---|
| Type | Dense, multimodal | Dense, multimodal |
| License | Apache-2.0 | Apache-2.0 |
| Parameters | 31B | 27B |
| Hardware used | 1x Nvidia H100 80 GB | 1x Nvidia H100 80 GB |
| Serving | vLLM, one model at a time | vLLM, one model at a time |
| VRAM usage | Under 80 GB with KV cache | Less than Gemma-4 with similar parameters |
| Context setup | Same context window for both | Same context window for both |
| Tool use | Enabled | Enabled |
| Benchmarks on paper | Edge on Codeforces ELO and multilingual | Leads on some math and GPQA |
| Coding test result | Produced a working one-shot HTML game, later runs inconsistent | Produced a much longer file but no animation in one shot |
| Multilingual test | Completed all 78 languages, including rare ones | Cut off mid-sentence on some, missed a few languages |
| Vision test | Accurate, organized by row, minor transcription errors | Accurate, organized by topic, better hard-equation transcription |
| Verdict by task | Coding winner, Multilingual winner | Vision winner |
Gemma-4 31B vs Qwen3.5 27B: Local Model Comparison
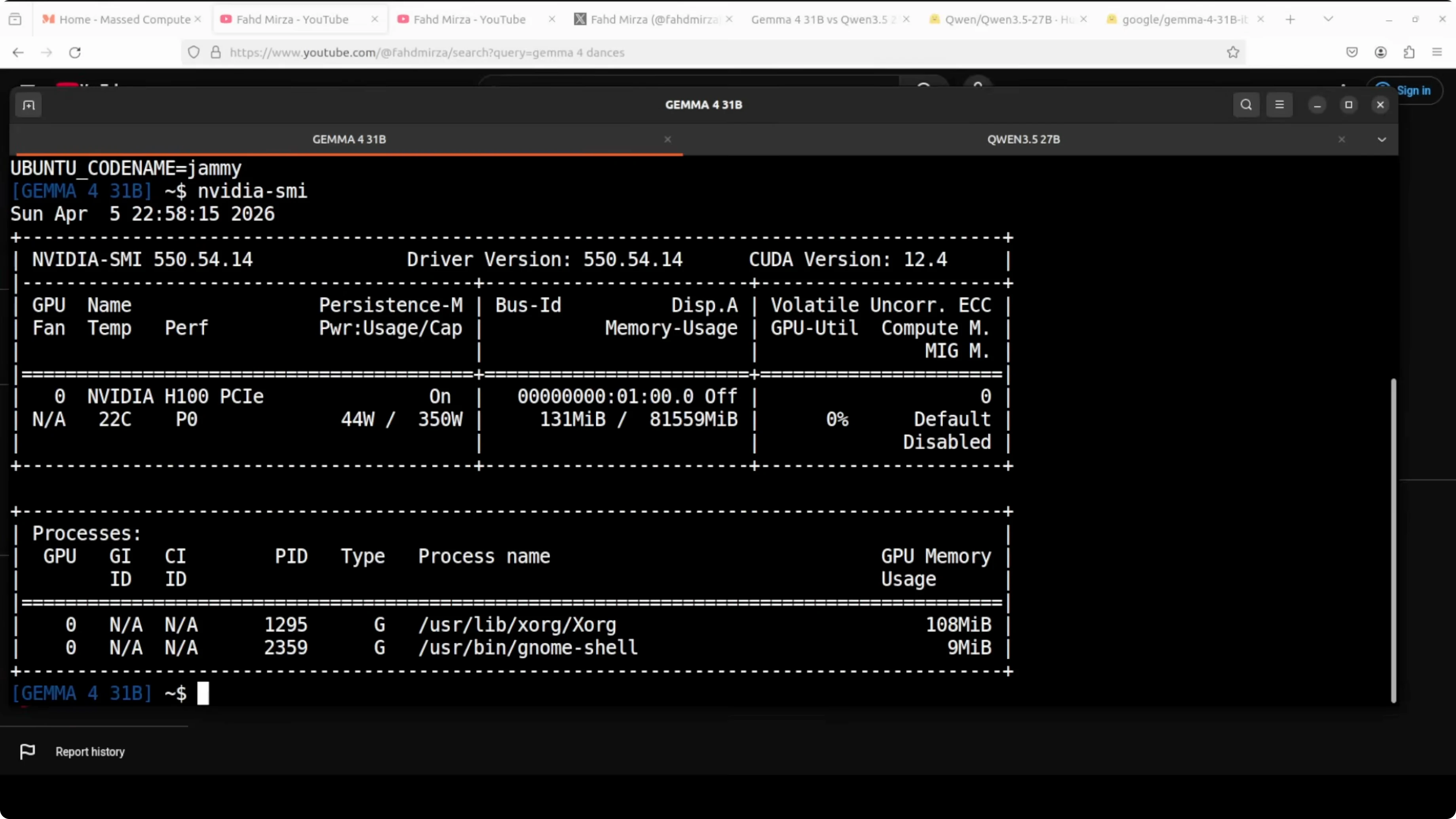
Test setup and environment
- Ubuntu, single Nvidia H100 80 GB.
- Both models served locally via vLLM, one at a time, with the same context window and identical prompts.
- Tool use was enabled, and KV cache was set.
If you also compare premium assistants for long-context work, see this focused look at model families: Claude Opus versions compared.
Coding test: complex simulation in a single HTML file
Prompt summary
- Architect a complete game from scratch in a single HTML file, no external libraries.
- An ant colony defends its nest against an invading segmented snake.
- Multiple AI agents, physics, canvas rendering, game state, and win conditions.
Observations
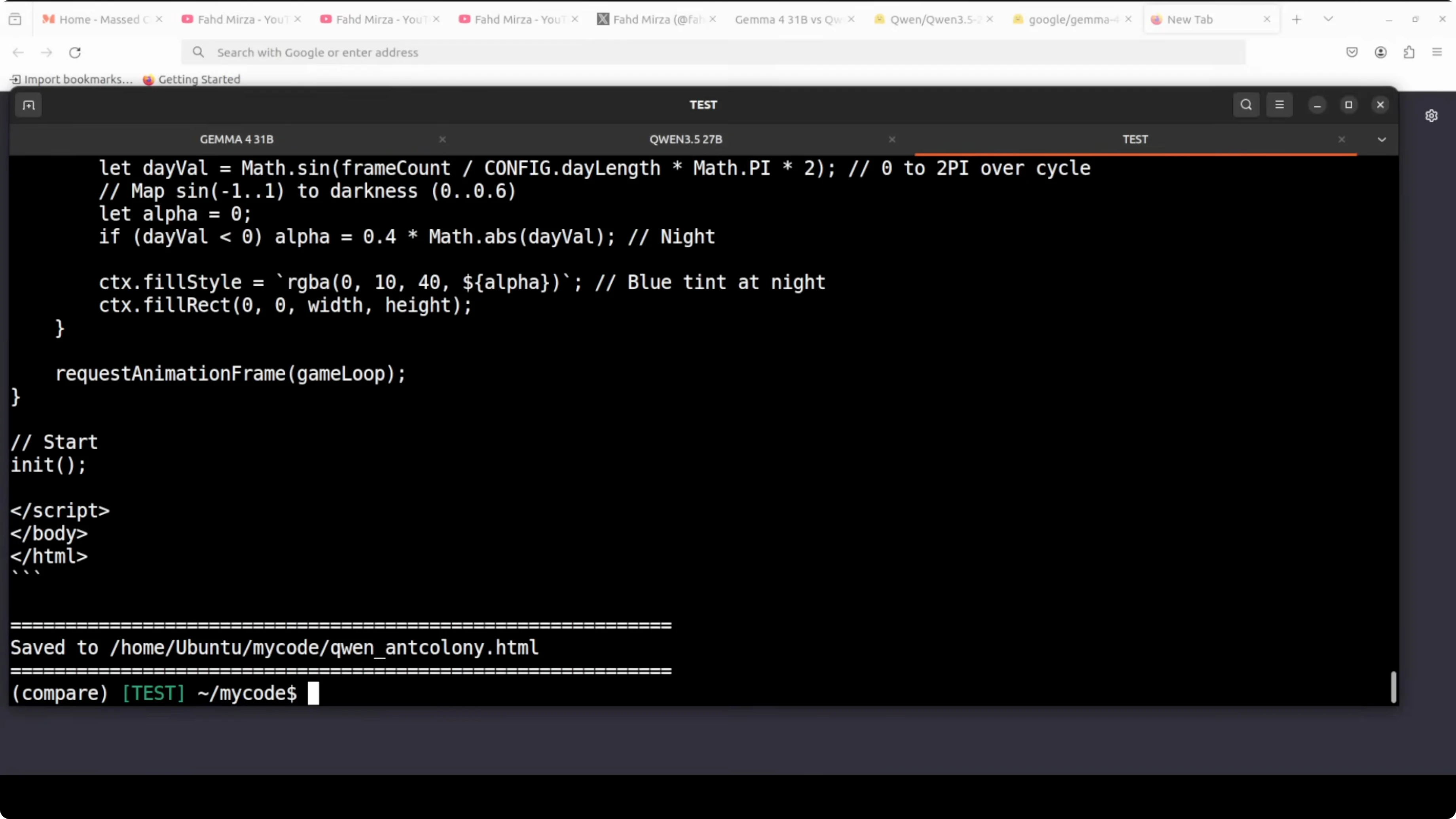
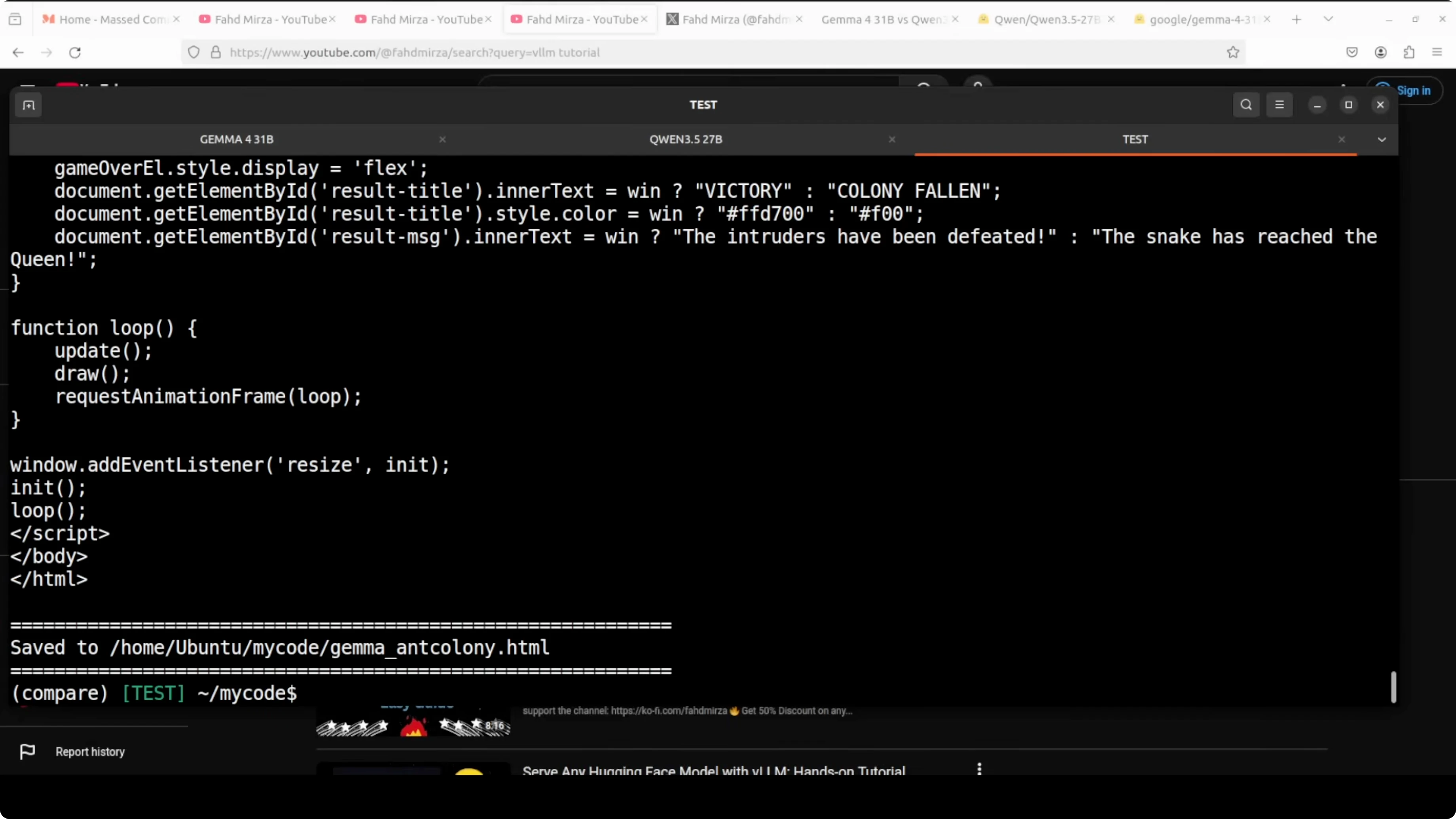
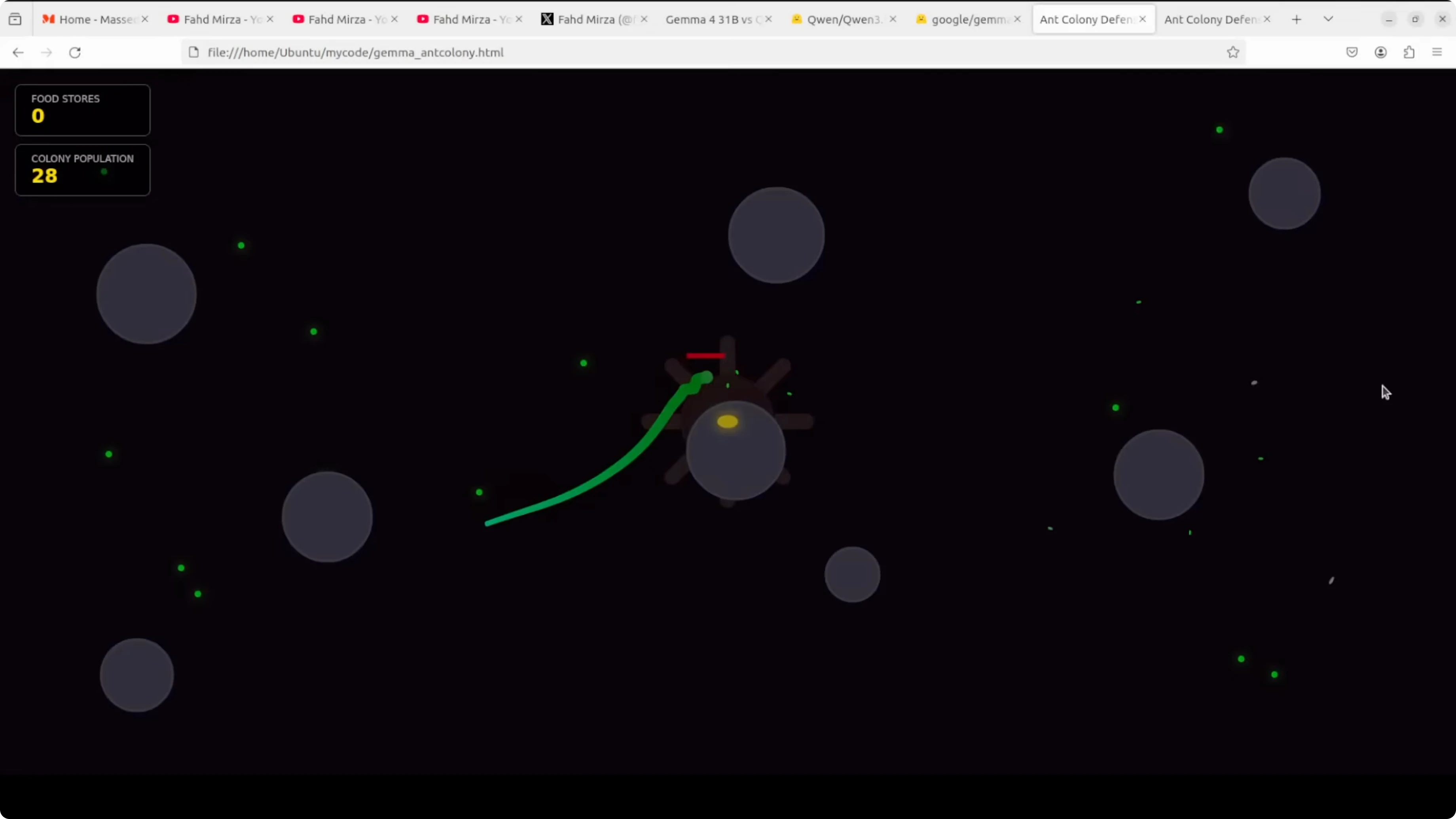
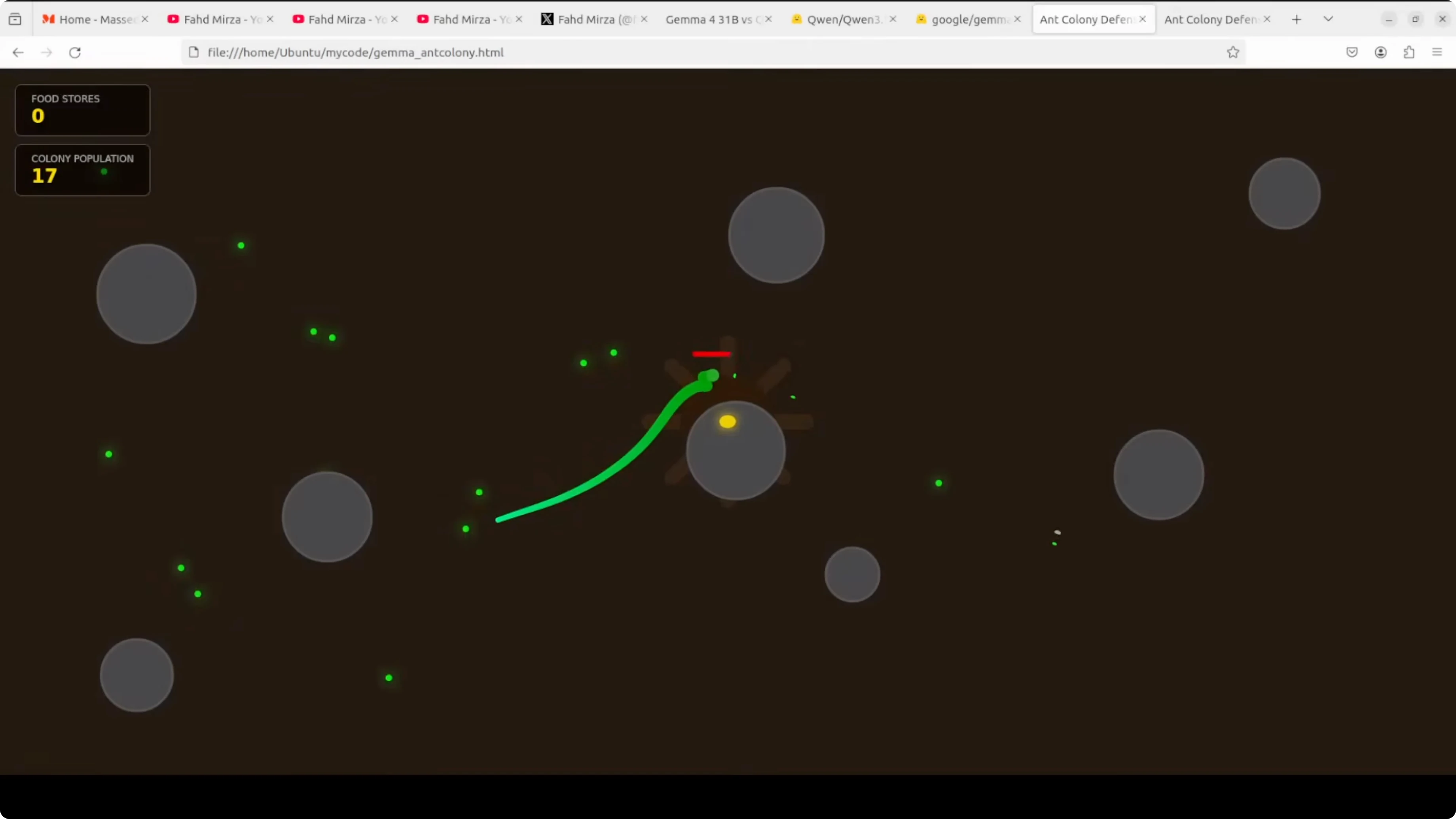
- Gemma produced index.html for the ant colony. It ran with visuals and behavior, but on later reloads the snake stalled and did not progress.
- Qwen produced a much longer HTML file that read feature-rich on inspection, but in a one-shot run it showed no animation on load and required reloads without coming alive.
- Functional beats feature-complete but broken. Gemma wins the coding round.
For more code-focused model talk, you might also like this programming-oriented comparison: code-generation models overview.
Multilingual test: fashion show opening announcement
English source line
- “Ladies and gentlemen, welcome to the greatest runway on earth, where every stride tells a story, every fabric holds a culture. And tonight, beauty speaks every language.”
Task
- Translate the announcement into a large list of languages, including rare and regional ones.
- Output must be structured and culturally sensitive, within the specified context limit.
Observations
- Gemma completed all 78 languages, including the rare and obscure ones, and kept them present and correct.
- Qwen got cut off mid-sentence on Nepali, skipped Sinhala and Khmer, and some Scandinavian outputs were not good enough. It also struggled on Afrikaans and a few others in this one-shot pass.
- Both produced solid quality where translations were complete. Gemma wins the multilingual round for completeness and coverage.
Vision and reasoning test: handwritten physics equations
Prompt summary
- Transcribe the handwritten equations exactly as written.
- Identify the governing physical laws and explain them.
- If solvable, show step-by-step reasoning. Thorough and precise outputs expected.
Observations
- Both models identified all 30 equations correctly and explained them accurately.
- Qwen organized by topic like special relativity, dynamics, wave optics, nuclear physics, and more, with cleaner sectioning and stronger domain context.
- Qwen correctly identified equation 12 as the diffraction grating equation and equation 27 as the Duane-Hunt law. Gemma made a small error on equation 14 with an approximate transcription and had a slightly off denominator on Planck’s law. Qwen wins the vision round.
If you are exploring other strong open-source or hybrid lineups, this multi-model face-off is helpful: model families contrasted.
Features Breakdown
Gemma-4 31B
Model traits
- Dense, multimodal, Apache-2.0, 31B parameters.
- Strong multilingual capability and competitive coding behavior in a single-shot run.
- VRAM use stayed under 80 GB on H100 with KV cache enabled.
On-paper benchmarks
- Within a percentage point of Qwen on MMLU, GPQA Diamond, and LiveCodeBench.
- Edge on Codeforces ELO and multilingual benchmarks.
Qwen3.5 27B
Model traits
- Dense, multimodal, Apache-2.0, 27B parameters.
- Slightly lower VRAM footprint than Gemma at similar settings.
- Notable depth and organization in vision and physics reasoning.
On-paper benchmarks
- Very close to Gemma across general benchmarks.
- Leads on some math-style evaluations and GPQA in reported numbers.
For another angle on open models vs closed assistants, see this benchmark-driven write-up: DeepSeek vs Claude comparison.
Pros and Cons
Gemma-4 31B
Pros
- Produced a functional one-shot complex HTML simulation without external libraries.
- Completed 78-language translation set, including rare languages, within the context limit.
- Strong multilingual and code-oriented signals backed by competitive benchmarks.
Cons
- Inconsistent behavior on repeated runs of the HTML simulation.
- Minor transcription issues in a few equations during the vision test.
- Slightly higher VRAM use compared to Qwen under similar parameters.
Qwen3.5 27B
Pros
- Excellent organization by topic and depth in the vision reasoning test.
- Accurate handling of harder equations like diffraction grating and Duane-Hunt.
- Slightly lighter VRAM footprint while maintaining strong accuracy.
Cons
- One-shot HTML simulation did not animate on load, despite a much longer code file.
- Multilingual run cut off in some languages and missed a few entirely in this pass.
- Some translation quality gaps noted in Scandinavian and Afrikaans outputs.
Use Cases and Scenarios
Where Gemma-4 31B excels
- Rapid prototyping of interactive front-end simulations where a working first run matters.
- Large multilingual copy generation and batch translation tasks with broad language coverage.
- General-purpose local assistant work on a single GPU with focus on code plus text.
Where Qwen3.5 27B excels
- Technical reading, interpretation, and tutoring on math and physics-heavy content.
- Tasks needing structured, topic-wise organization and thorough domain context.
- Local deployments that want slightly lower VRAM use while maintaining reasoning depth.
If you want a written take focused only on this matchup, here is another concise side-by-side: in-depth Gemma vs Qwen notes.
Final Conclusion
Gemma-4 31B wins coding and multilingual in this one-shot local test, primarily due to a functional HTML game and complete 78-language coverage. Qwen3.5 27B wins vision and reasoning with cleaner organization, accurate handling of hard physics equations, and slightly better transcription fidelity.
Choose Gemma-4 31B if your priority is multilingual coverage and practical code outputs that run on first pass. Choose Qwen3.5 27B if your priority is technical reasoning, physics-math reading, and structured explanations with a lighter VRAM footprint. If you are surveying more comparisons beyond these two, see this broader model overview as well: Claude variants head-to-head.
Subscribe to our newsletter
Get the latest updates and articles directly in your inbox.

Related Posts

8 Best Claude Code Plugins in 2026 (You Need to Know)
8 Best Claude Code Plugins in 2026 (You Need to Know)

7 Best Claude Code Skills (You Need to Know)
7 Best Claude Code Skills (You Need to Know)

Claude Code Desktop IDE Features (You Need to Know)
Claude Code Desktop IDE Features (You Need to Know)