
Table Of Content
- Tencent WeDLM-8B 10x and the promise of diffusion LLMs
- Why many DLMs did not hit real speed gains
- How Tencent WeDLM-8B 10x fixes the cache problem
- Topological reordering with causal attention
- Installing Tencent WeDLM-8B 10x locally
- Setup steps
- Testing Tencent WeDLM-8B 10x
- Dynamic sliding window in Tencent WeDLM-8B 10x
- Streaming instead of block generation
- Final Thoughts

How Tencent’s WeDLM-8B Makes LLMs 10x Faster with Diffusion?
Table Of Content
- Tencent WeDLM-8B 10x and the promise of diffusion LLMs
- Why many DLMs did not hit real speed gains
- How Tencent WeDLM-8B 10x fixes the cache problem
- Topological reordering with causal attention
- Installing Tencent WeDLM-8B 10x locally
- Setup steps
- Testing Tencent WeDLM-8B 10x
- Dynamic sliding window in Tencent WeDLM-8B 10x
- Streaming instead of block generation
- Final Thoughts
Year 2025 is done, but Chinese labs are not. Tencent has just released a model that's changing how we think about AI text generation. You have probably heard about diffusion models in image generation. They are the technology behind Stable Diffusion Flux where the model starts with noise and gradually refines it into a clear image. Diffusion language models or DLMs apply this same concept to text generation and that is what Tencent has done in a serious way.
This is not something new. We have seen it with Lada which was released a few months back, but Tencent has really made it productionized. I am going to install this VDLM locally and show how it works, and more importantly explain how it achieves its speedups because this is going to be a big deal going into next year.
Tencent WeDLM-8B 10x and the promise of diffusion LLMs
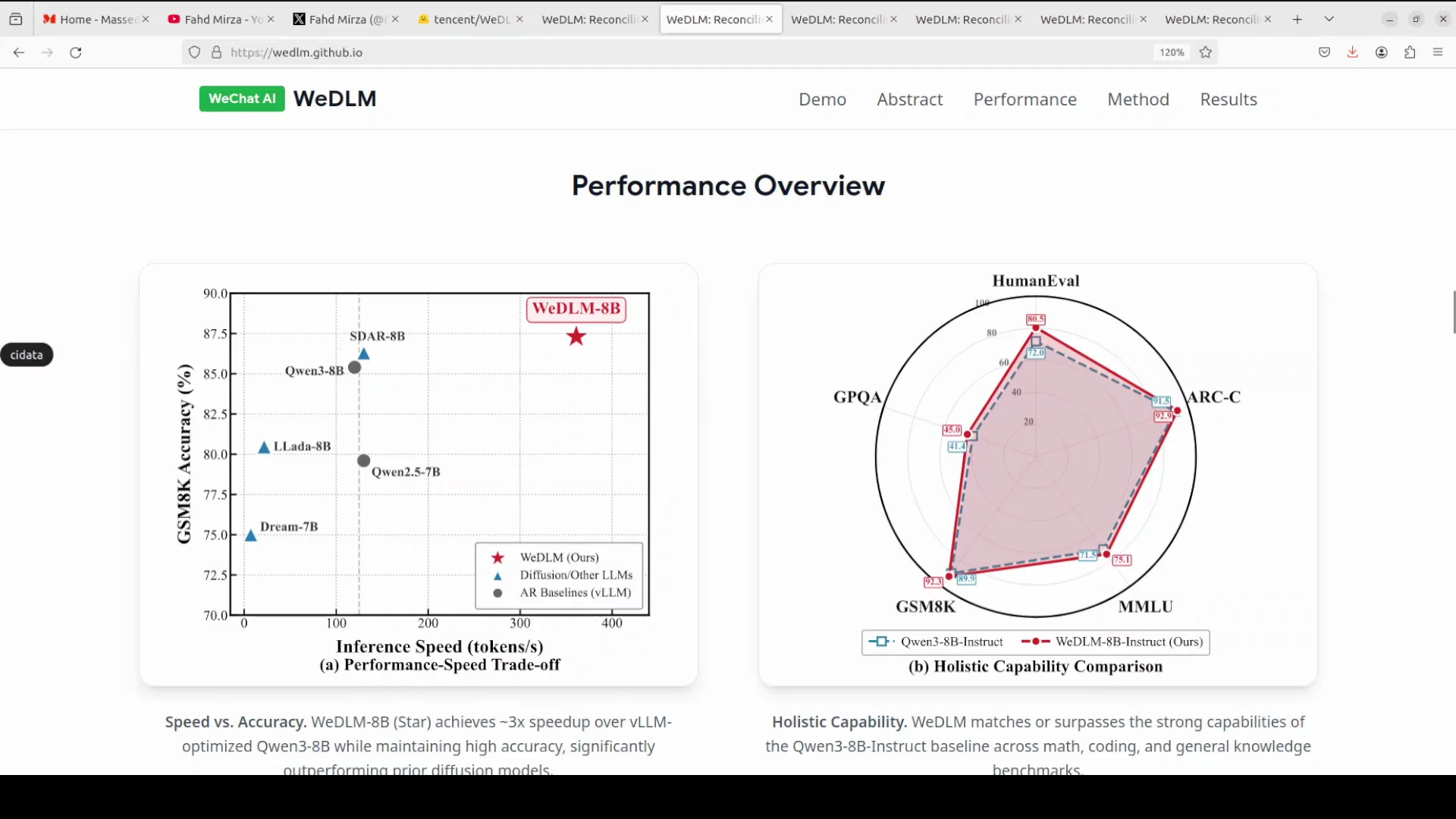
Instead of generating one word at a time like traditional language models do, diffusion LLMs predict multiple masked tokens in parallel, kind of like filling in blanks in a sentence all at once. The big promise here is speed. If you can generate multiple tokens simultaneously instead of one by one, you should be able to generate text way faster.
Why many DLMs did not hit real speed gains
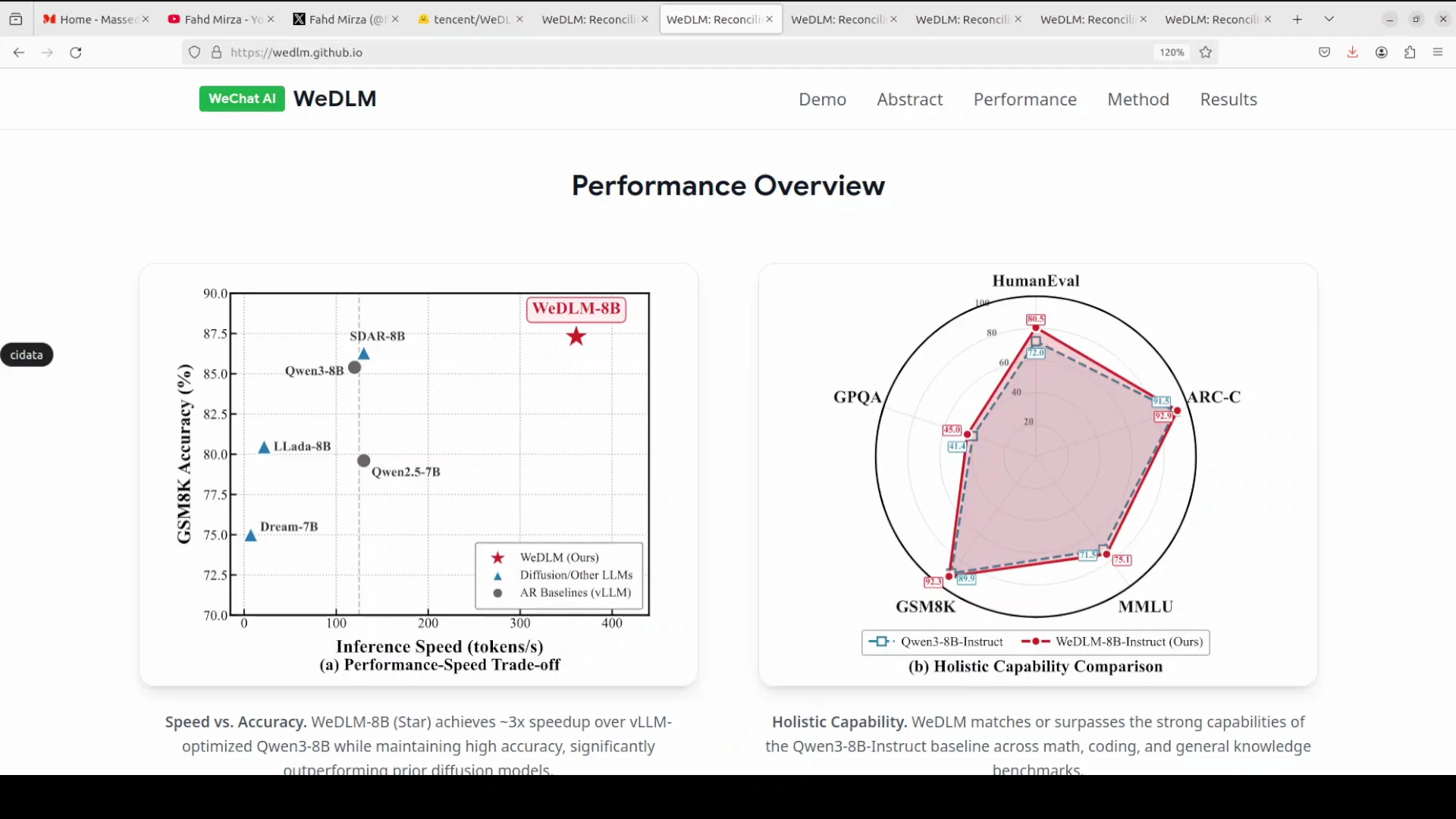
Most diffusion language models have struggled to actually deliver these speed gains in real world deployment because of technical limitations. We saw that in the Lada model. I thought it would be a big deal, and even when they released a mini version, it was not there yet.
The issue comes down to the attention mechanism. Traditional autoregressive models like GPT or Claude use causal attention where each token can only look at tokens that come before it, not after. This creates a clean left to right flow. Most diffusion language models use bidirectional attention, meaning tokens can look both forward and backward in the sequence. This breaks a crucial optimization called KV caching.
KV cache is how modern inference engines achieve blazing fast speed along with paged attention. They store previously computed attention values and reuse them instead of recalculating everything. With bidirectional attention, you cannot reuse these cached values effectively, so you end up recalculating everything over and over again. This means even though diffusion models can predict multiple tokens at once, they waste so much time on repeated calculation that they do not actually beat optimized regular LLMs.
How Tencent WeDLM-8B 10x fixes the cache problem
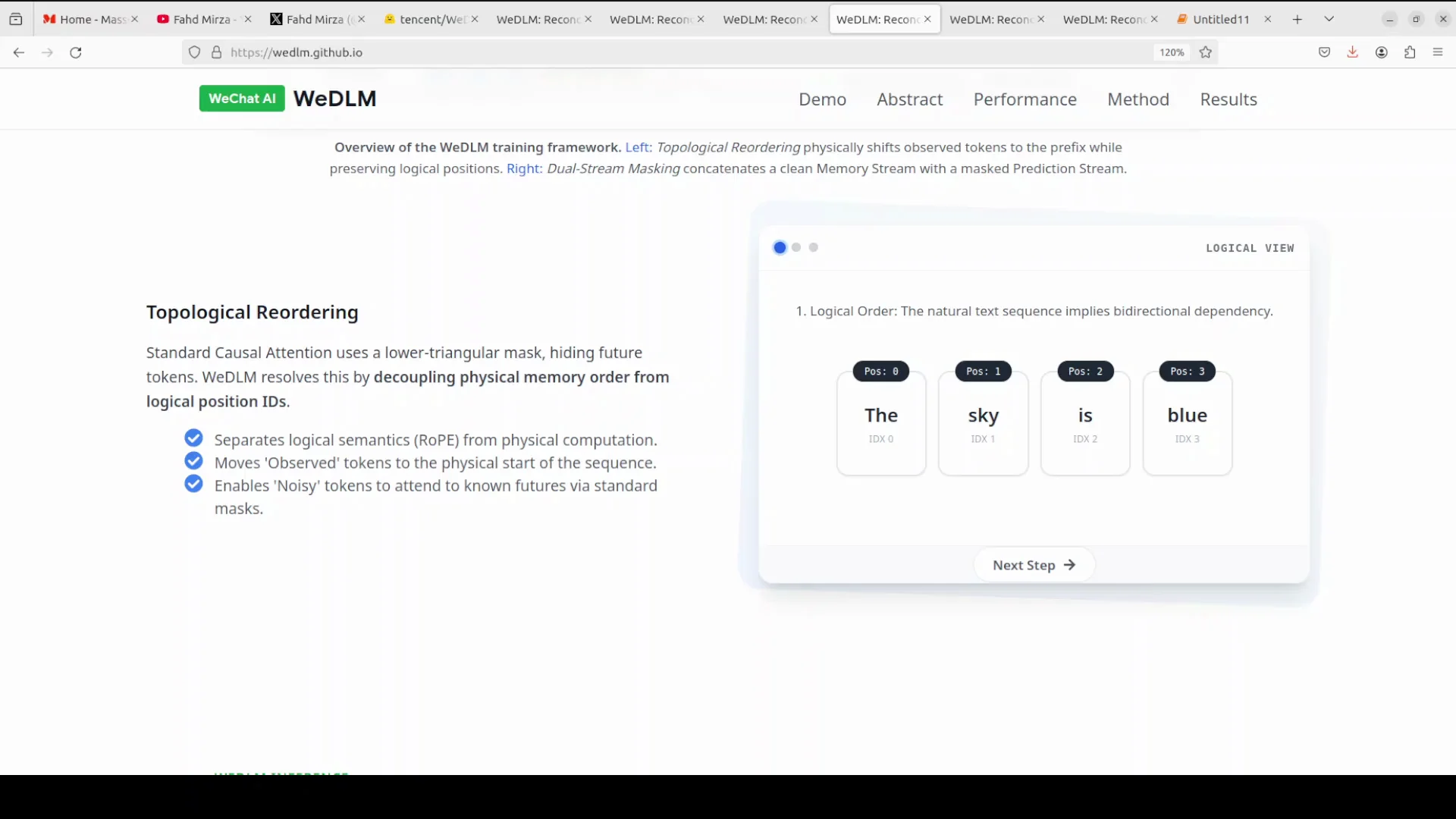
The key idea is topological reordering, and it is clever.
Topological reordering with causal attention
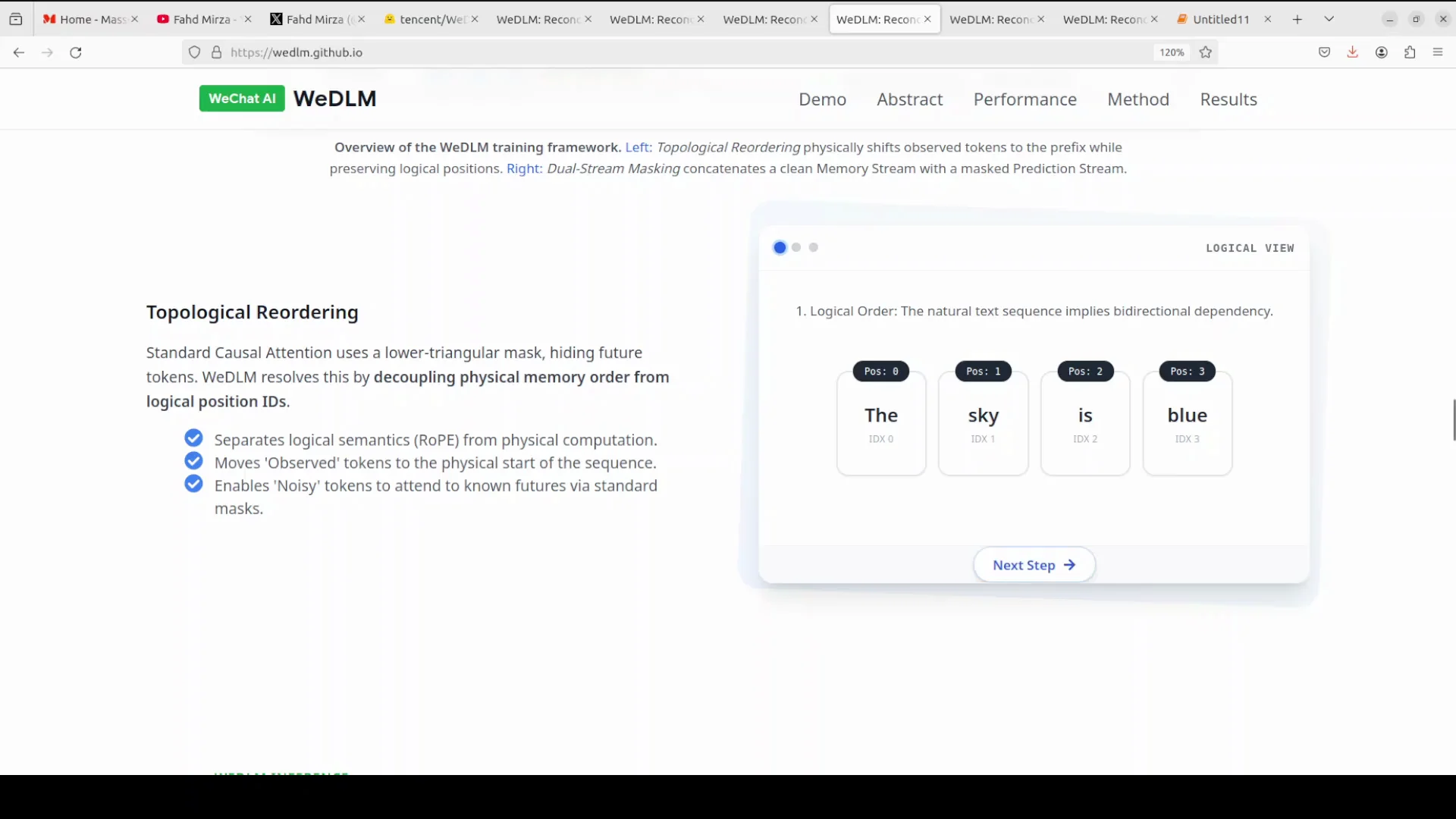
- Keep using standard causal attention, the same left to right attention that makes KV cache work, while still doing parallel mask recovery like a diffusion model.
- Normally the logical order of tokens is fixed: word 1, word 2, word 3, and so on. VDLM physically moves all the known tokens to the front of the sequence while preserving their logical positions through positional embeddings.
- If you know words like 1, 3, and 5, you physically arrange them at the start, then put the masked words after.
- With causal attention, the masked tokens can see all the known tokens that came before them in the physical arrangement, but the strict causal mask is still intact.
This means KV cache works perfectly and you get all the efficiency benefits of standard autoregressive inference while still doing parallel generation. That is huge.
Installing Tencent WeDLM-8B 10x locally
I used an Ubuntu system with one Nvidia RTX 6000 GPU with 48 GB of VRAM.
Setup steps
- Install the requirements.
- Clone the repo and install from source.
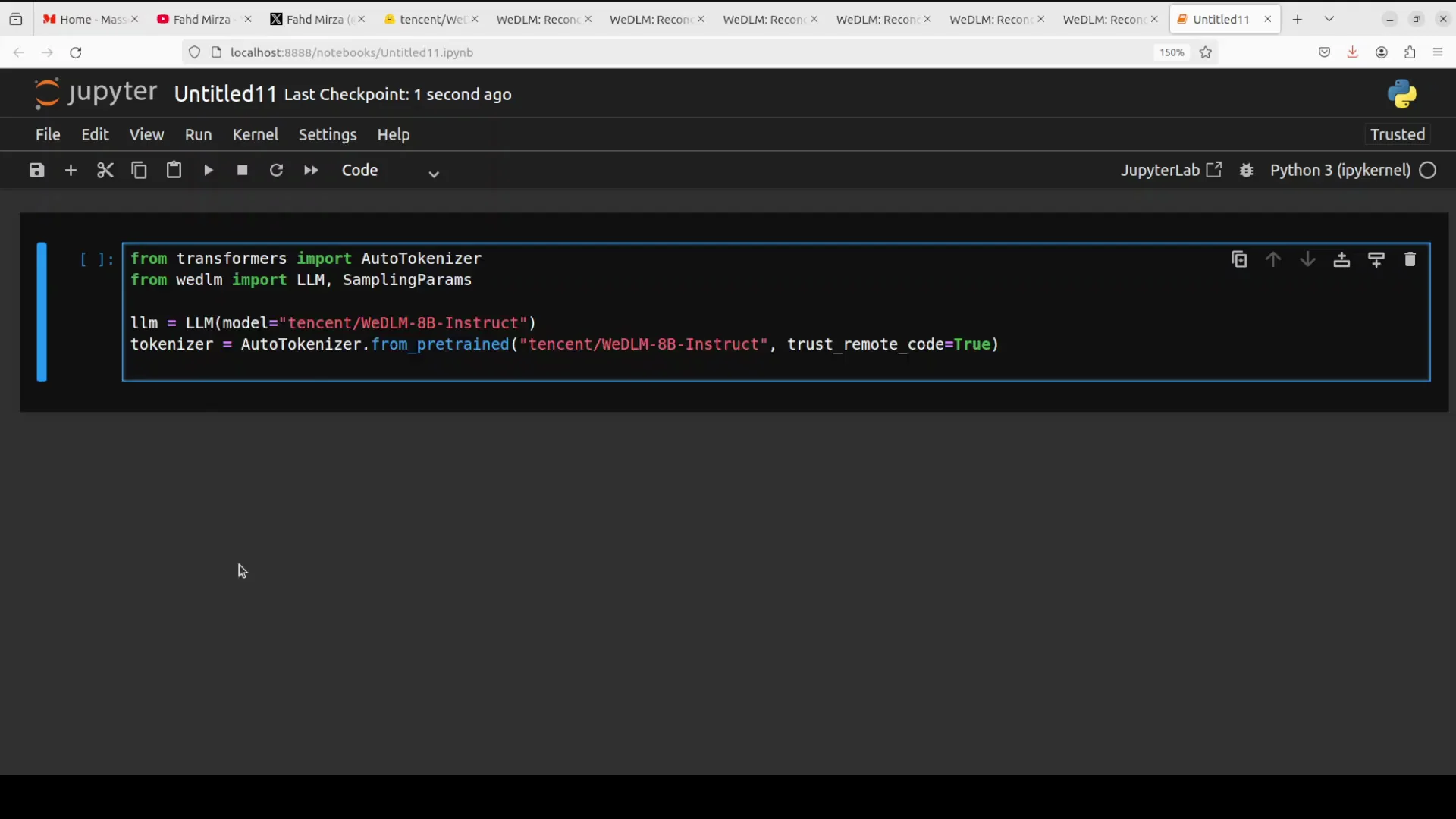
- Launch Jupyter Notebook.
- Grab the model and tokenizer from Hugging Face.
- Run inference.
Testing Tencent WeDLM-8B 10x
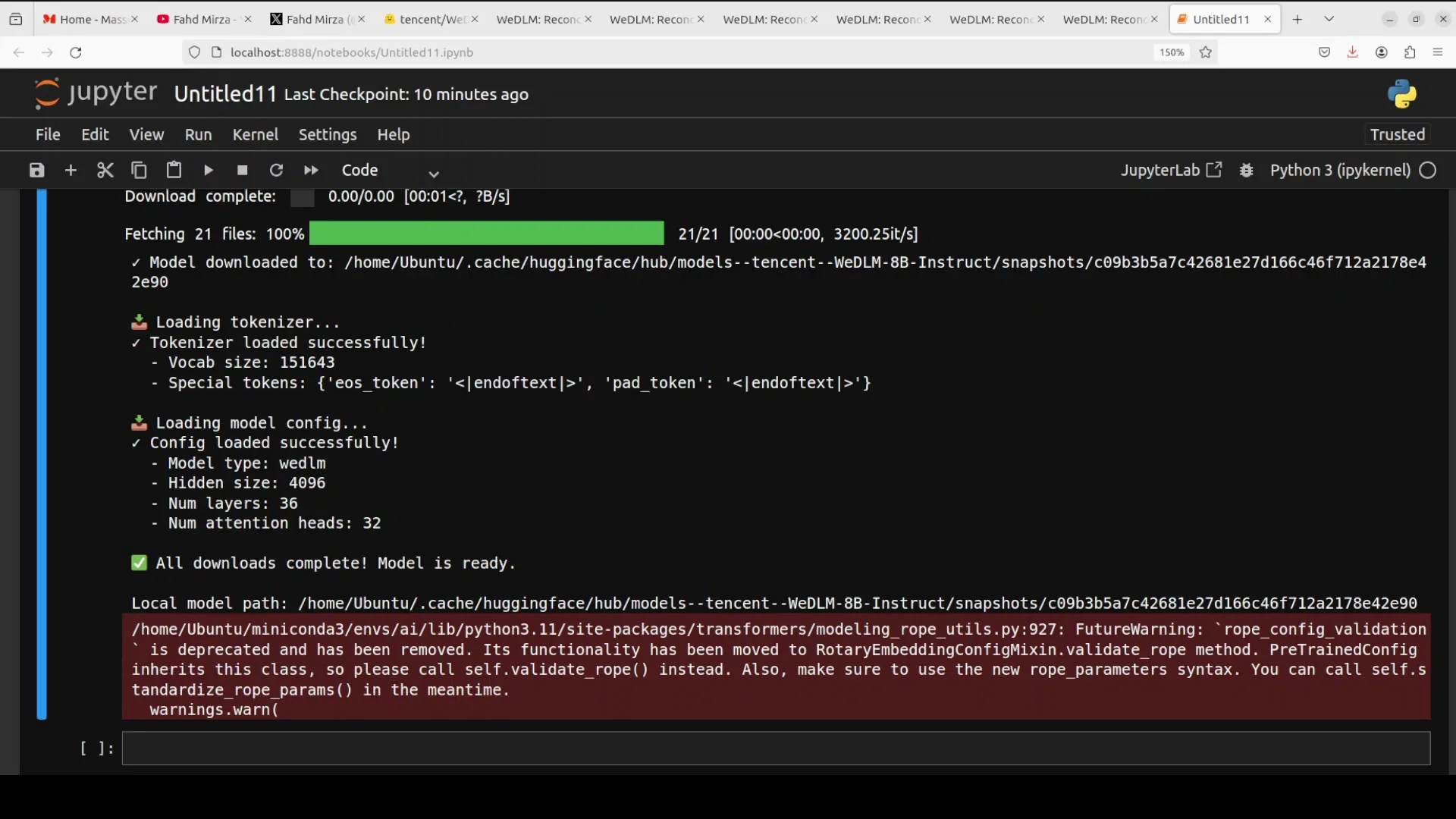
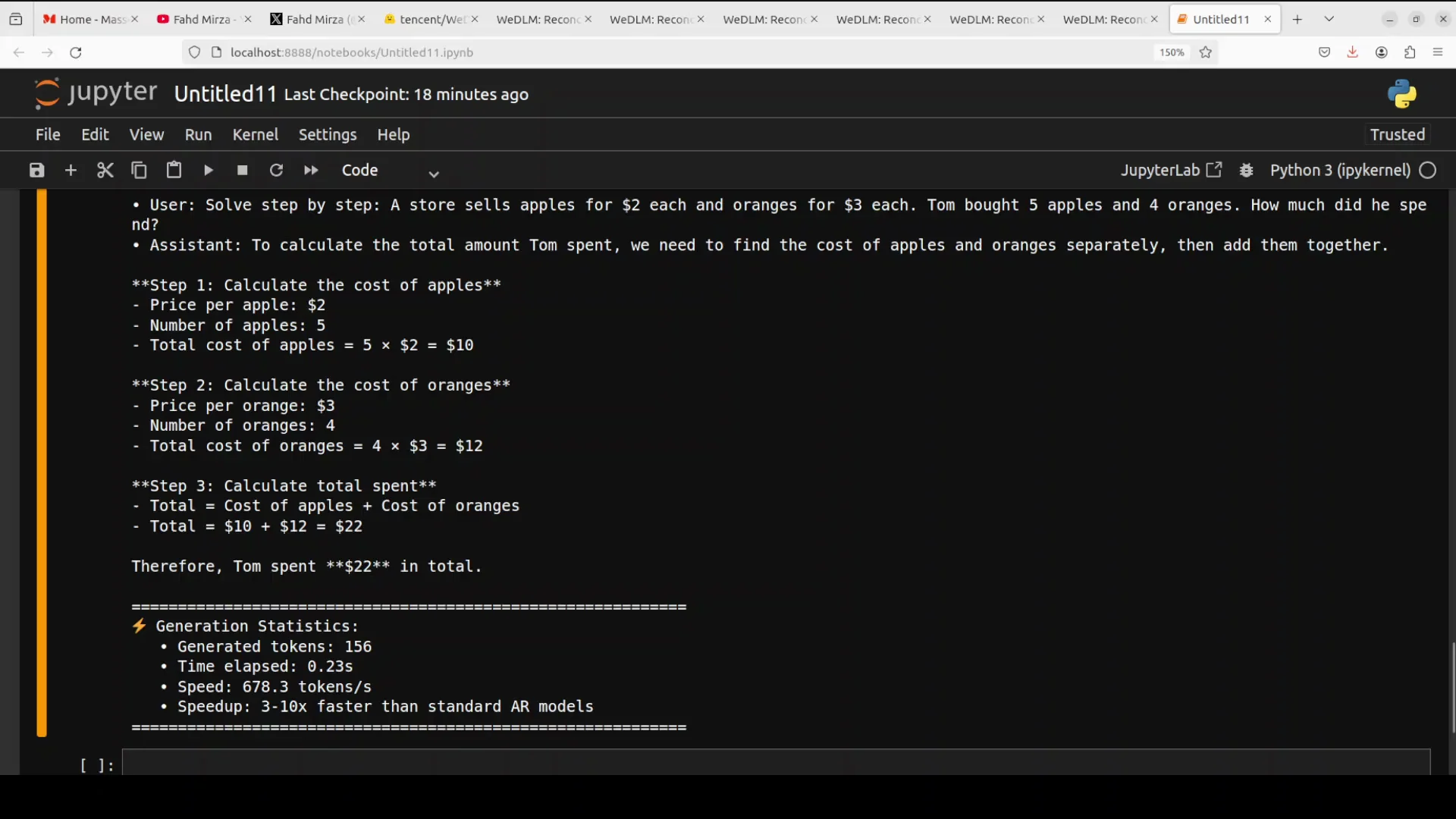
I used a chain-of-thought style prompt asking it to solve a problem step by step, and printed the time and tokens per second.
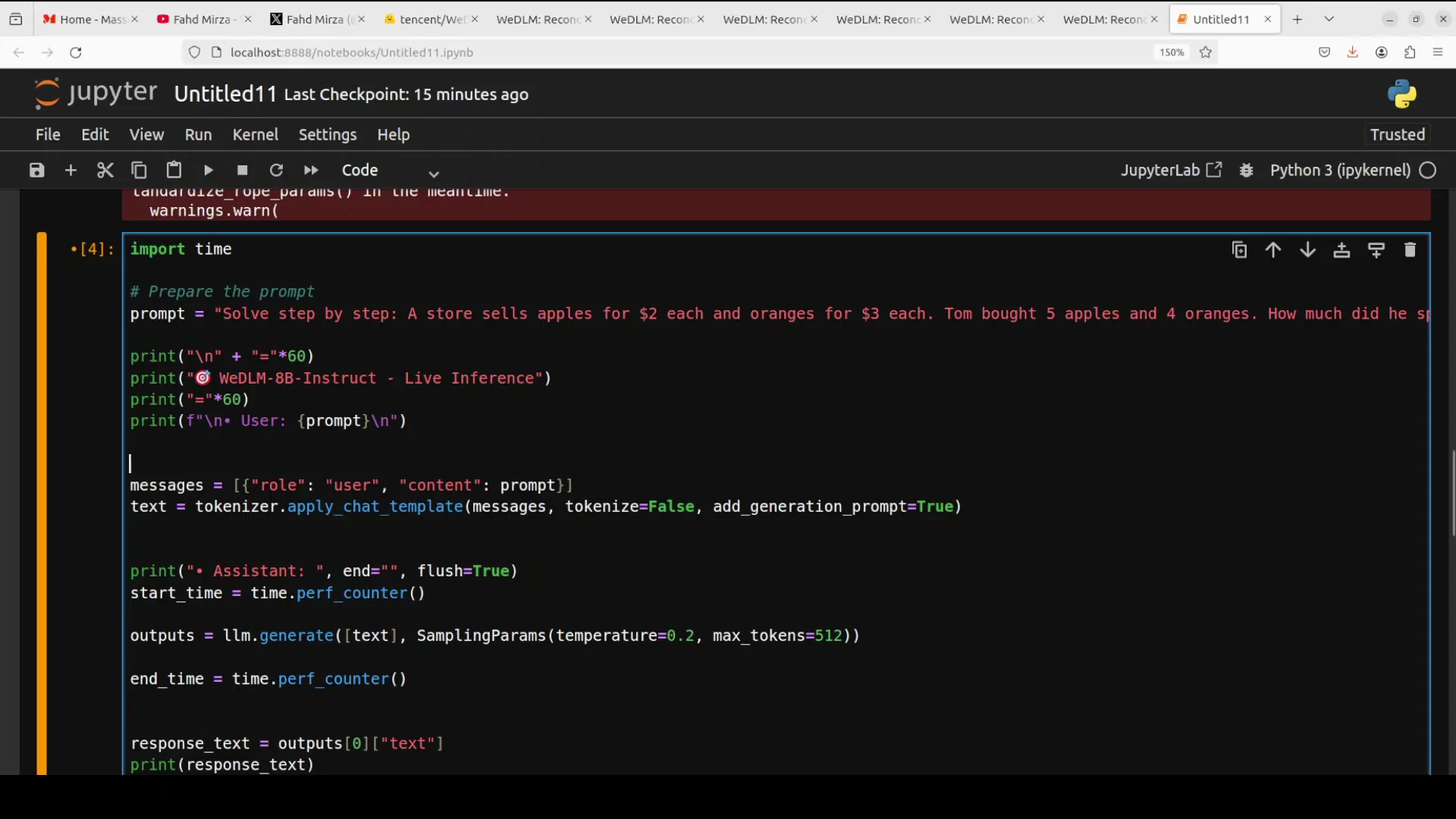
- The answer came back fast and correct in about 22 to 23 seconds.
- Speed was more than 3 to 10 times faster in my tests.
- VRAM consumption was close to 17 GB, which is fine for this GPU.
Dynamic sliding window in Tencent WeDLM-8B 10x
In my opinion, dynamic sliding window is one more innovation here because it makes it truly efficient.
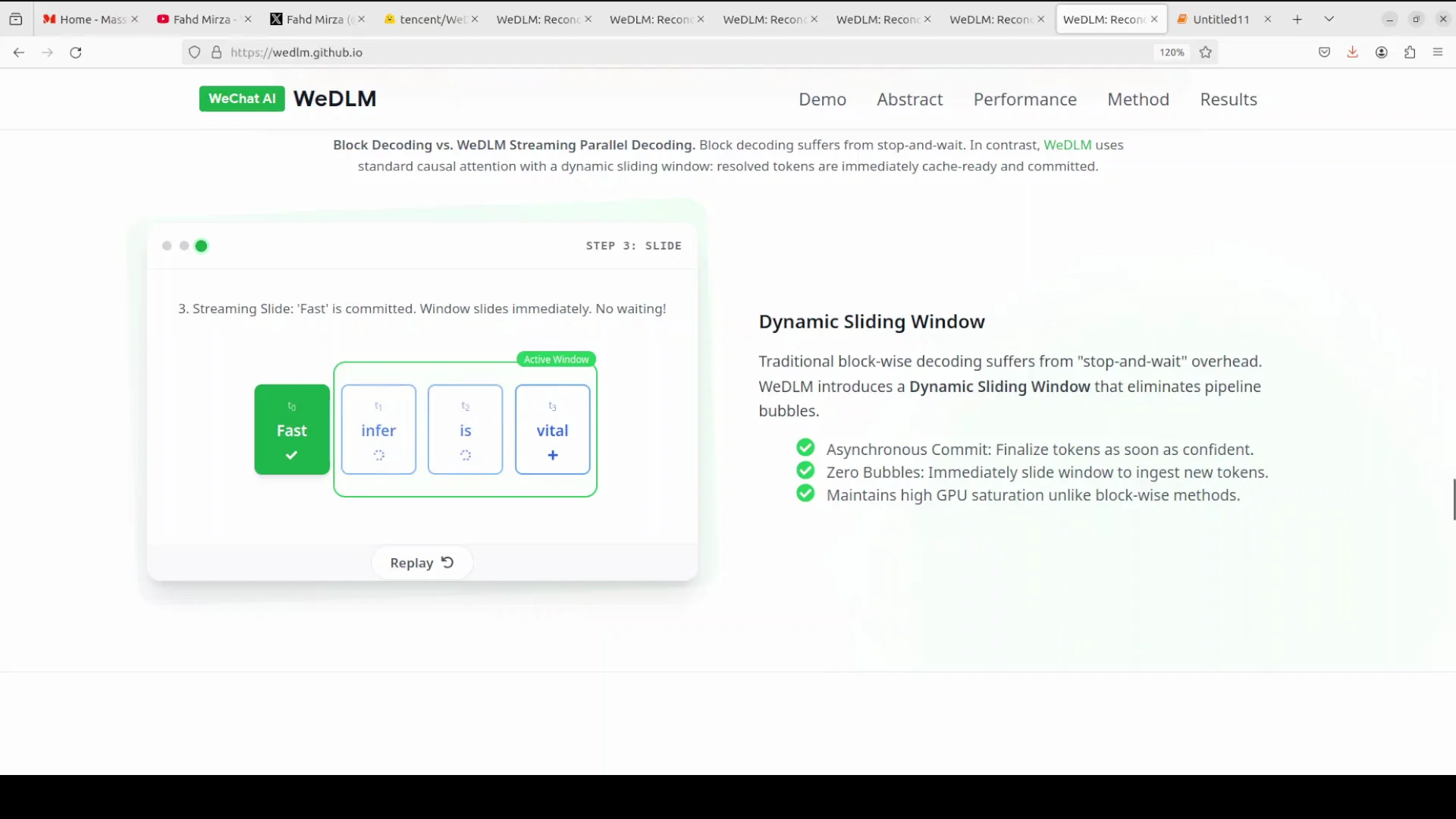
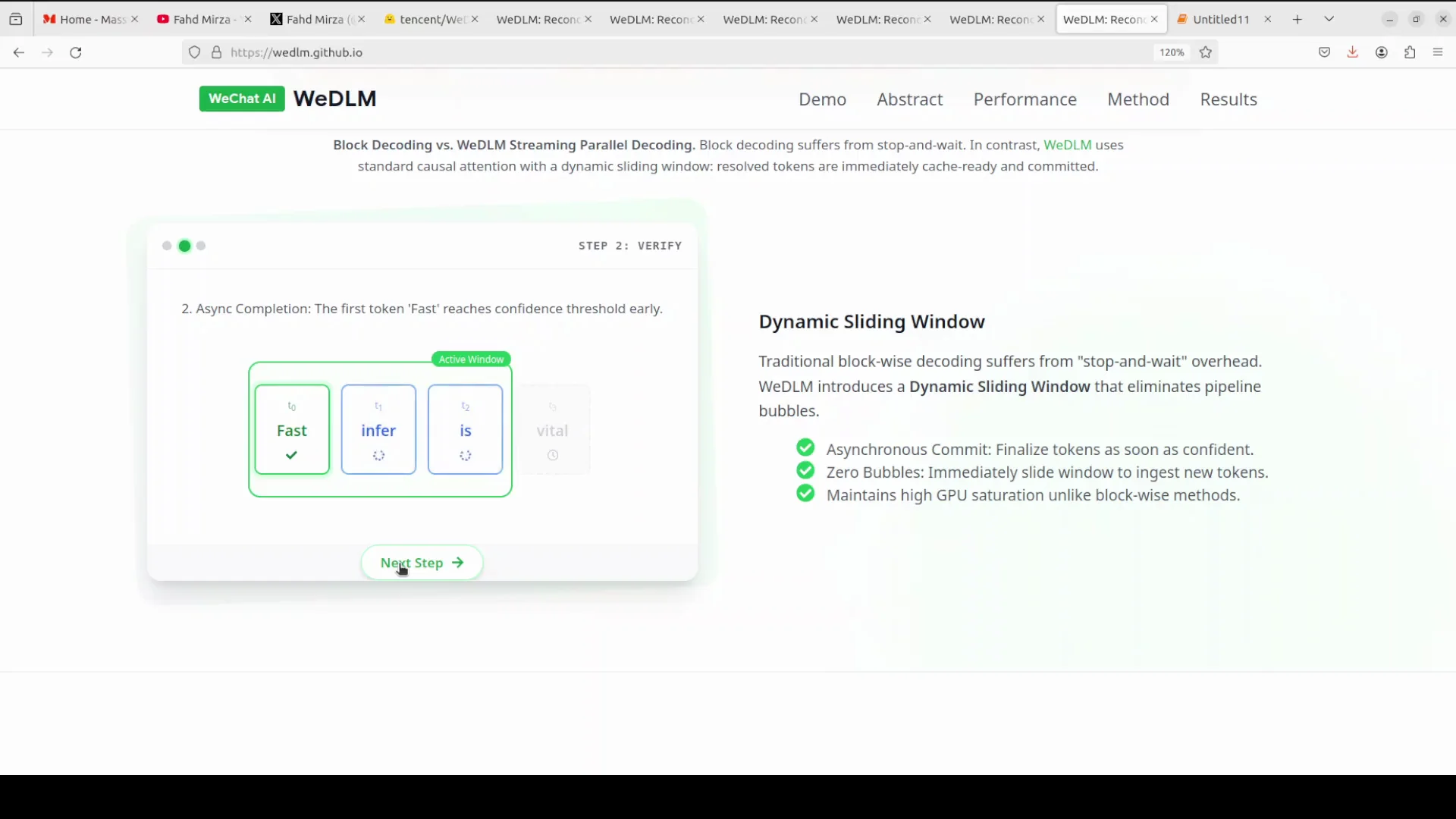
Streaming instead of block generation
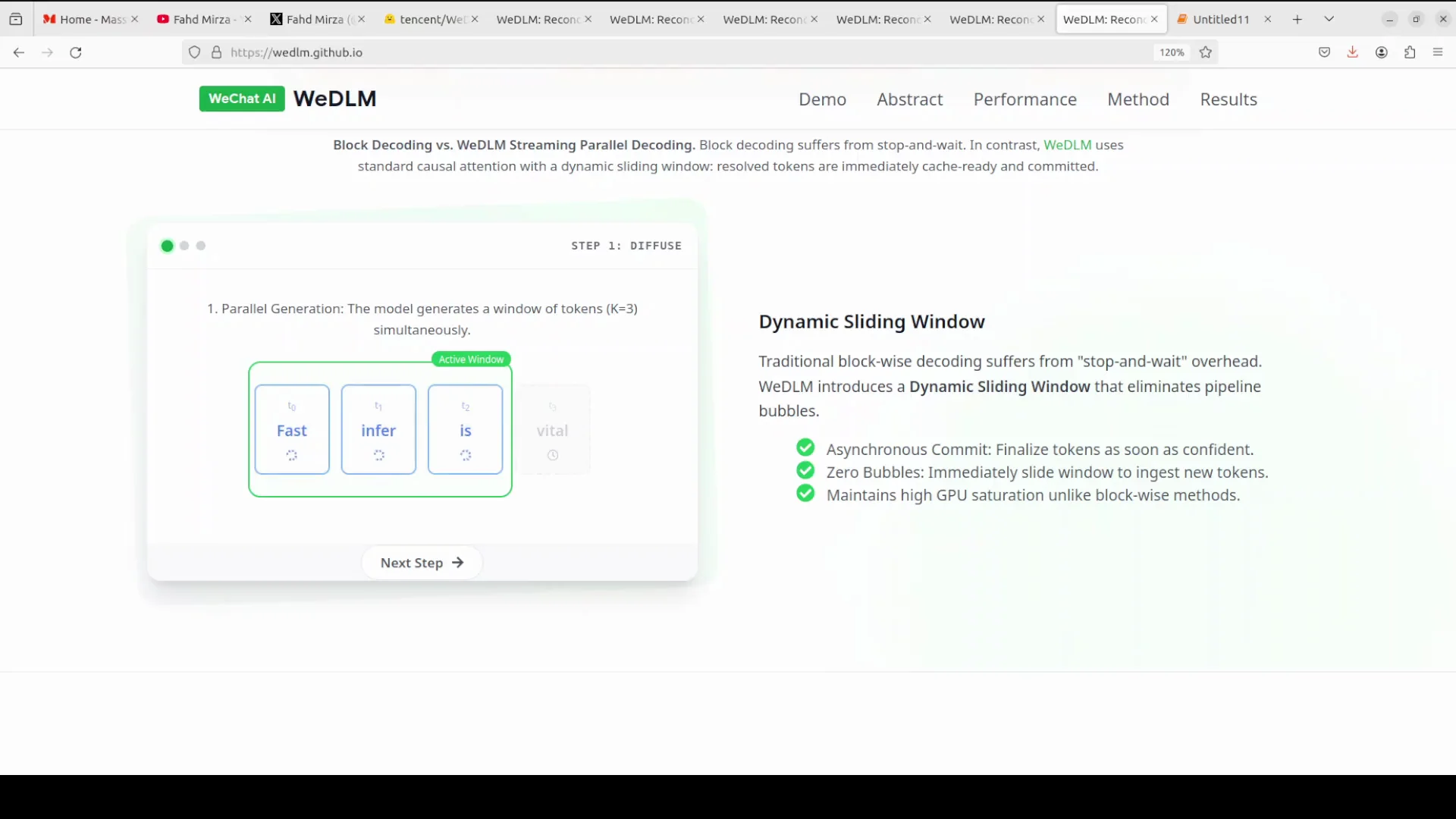
Instead of traditional block based diffusion methods that generate a fixed number of tokens and then wait for all of them to be finalized before moving to the next block, creating idle GPU time, VDLM uses a streaming approach.
- Work on a fixed window of, say, 16 masked tokens at once.
- As soon as one token becomes confident enough, commit it immediately to the output.
- Slide the window forward to include a new masked token so there is no stop and wait behavior.
- Apply a distance penalty that encourages tokens closer to already generated text to resolve first, prompting natural left to right generation.
This keeps the GPU constantly busy with a steady stream of work, and it makes it faster and efficient. We just saw the speed improvement.
Final Thoughts
A lot is happening here, and I am excited about it. It seemed like diffusion based language models were mostly theory, but now they can genuinely outperform optimized autoregressive systems in production. Tencent’s approach with causal attention, topological reordering, and a dynamic sliding window shows how diffusion LLMs can deliver real speed gains without sacrificing the practical benefits of KV caching and paged attention.
Subscribe to our newsletter
Get the latest updates and articles directly in your inbox.

Related Posts

8 Best Claude Code Plugins in 2026 (You Need to Know)
8 Best Claude Code Plugins in 2026 (You Need to Know)

7 Best Claude Code Skills (You Need to Know)
7 Best Claude Code Skills (You Need to Know)

Claude Code Desktop IDE Features (You Need to Know)
Claude Code Desktop IDE Features (You Need to Know)