
Table Of Content
- This New Model Just Beat Wan-Animate (First-Frame Perfect)
- What First Frame Preservation Means in Practice
- This New Model’s Output Pattern
- Handling Identity, Framing, and Background Motion
- Cartoon Characters and Head Turns
- Human-Object Interactions and the Xance Benchmark
- Object Interaction Cases
- How This New Model Works Under the Hood
- Why That Shift Matters
- Keeping Strict Identity While Controlling Motion
- Pose Modulation Modules
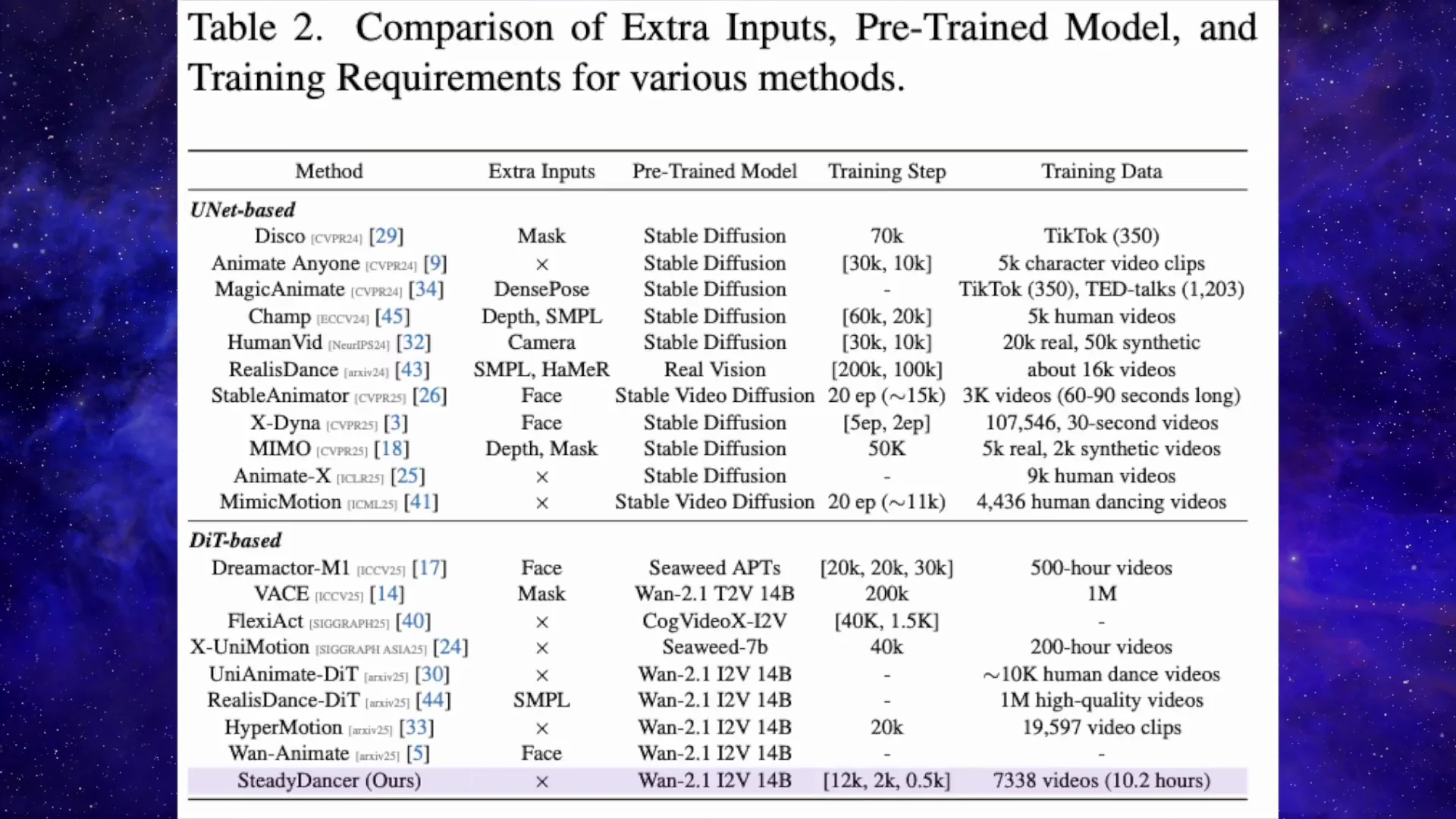
- Training Setup and Efficiency
- A Quick Comparison Snapshot
- Visual Behavior by Method
- Practical Use and Setup
- Quick Start Steps
- Why This New Model Feels Stable in Creative Workflows
- Strong Performance on Mismatched Inputs
- Pose to Object Motion
- Design Summary of This New Model
- Key Takeaways
- Comparison Table: Models and Observed Behavior
- Technical Notes for This New Model
- Visual Characteristics You Can Expect
- Input Flexibility
- Final Thoughts on This New Model

Steady Dancer vs Wan Animate: First‑Frame Faithful Animation
Table Of Content
- This New Model Just Beat Wan-Animate (First-Frame Perfect)
- What First Frame Preservation Means in Practice
- This New Model’s Output Pattern
- Handling Identity, Framing, and Background Motion
- Cartoon Characters and Head Turns
- Human-Object Interactions and the Xance Benchmark
- Object Interaction Cases
- How This New Model Works Under the Hood
- Why That Shift Matters
- Keeping Strict Identity While Controlling Motion
- Pose Modulation Modules
- Training Setup and Efficiency
- A Quick Comparison Snapshot
- Visual Behavior by Method
- Practical Use and Setup
- Quick Start Steps
- Why This New Model Feels Stable in Creative Workflows
- Strong Performance on Mismatched Inputs
- Pose to Object Motion
- Design Summary of This New Model
- Key Takeaways
- Comparison Table: Models and Observed Behavior
- Technical Notes for This New Model
- Visual Characteristics You Can Expect
- Input Flexibility
- Final Thoughts on This New Model
This New Model Just Beat Wan-Animate (First-Frame Perfect)
You drop in a single image, give it a driving video, and it makes your character copy that motion. Wan Animate is powerful, but it also has issues: identity drift, odd framing, backgrounds that stay static, and faces that shift away from your original image.
Steady Dancer is the next evolution in this space. It is a human image animation model built on top of the one video backbone, redesigned around first frame preservation. That means it tries to keep the very first frame’s look locked in for the entire clip.
On benchmarks like Real East Dance Val, it hits the best FVD score in the whole table while staying very competitive or better on subject consistency, background consistency, flicker, and overall visual quality compared to models like Wan Animate, Mimic Motion, HyperMotion, and Uni Animate Dit. FVD is the metric people care about for does this look like real video.
What First Frame Preservation Means in Practice
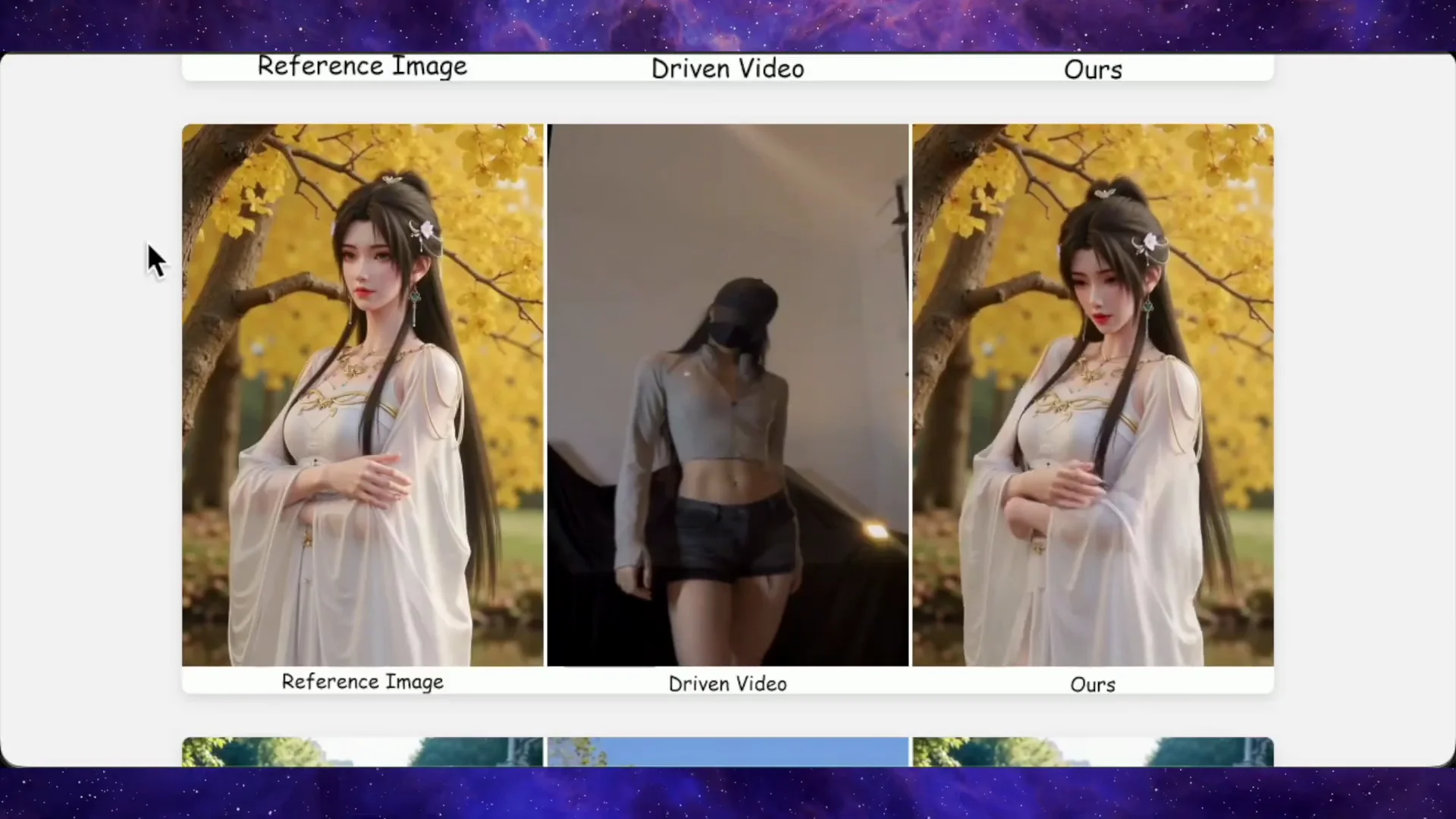
Look at the side-by-side comparisons. In one example, there is a reference image in the top left, a dance driving video next to it, and on the top right, you see Steady Dancer’s result. The character follows the motion accurately, the face stays locked, the framing feels natural, and nothing looks broken.
Below that, they run the same image and driving video through Human Vid, HyperMotion, Mimic Motion, and Wan Animate. Human Vid and HyperMotion fall apart with low-quality textures and warped bodies, while Mimic Motion and Wan Animate do better but show artifacts and inconsistencies once you compare frame by frame.
In another example, Wan Animate pushes the character back in the frame so she looks tiny compared to the original composition. Mimic Motion keeps the framing but changes the face, so you are no longer animating the person you started with. Steady Dancer keeps both the framing and the original identity intact.
This New Model’s Output Pattern
Across the rest of the demos, the pattern repeats. They show a simple image on the left, a driving video in the middle, and the output on the right. In the Steady Dancer output, the face is steady from start to end. The motion is close to one-to-one with the driving clip.
Even the camera movement feels natural instead of being artificially zoomed or cropped. Wan Animate tends to animate only the character while leaving the background static. Steady Dancer can bring the whole scene to life, including subtle background motion, which makes the shot feel real.
Handling Identity, Framing, and Background Motion
They test with a Chinese movie character image driven by a male dancer in the street. The animated output keeps the movie character’s identity while copying the dance cleanly with no clear glitches or odd body distortions.
Another stress test uses a slightly side-angled female face as the reference and a full front-facing dance as the driving video. Steady Dancer matches the motion and keeps the face shape and identity very close to the reference. That is the zone where many models start to break.
They show a case where the driving video is a full body dance, but the reference image is a half-body shot. Steady Dancer animates the visible upper body from that same framing, does not zoom out, and still holds facial similarity.
Cartoon Characters and Head Turns
It handles cartoon characters almost as well as real people. Give it a cartoon portrait and a human dance video, and the cartoon follows the motion with clean limbs and stable identity instead of melting into abstract shapes.
One of the hardest tests is when the character turns their head away and then back toward the camera. Many methods change the face or drift toward a new identity after the turn. Here, the face before and after stays close to the first frame, which shows that first frame preservation works in practice.
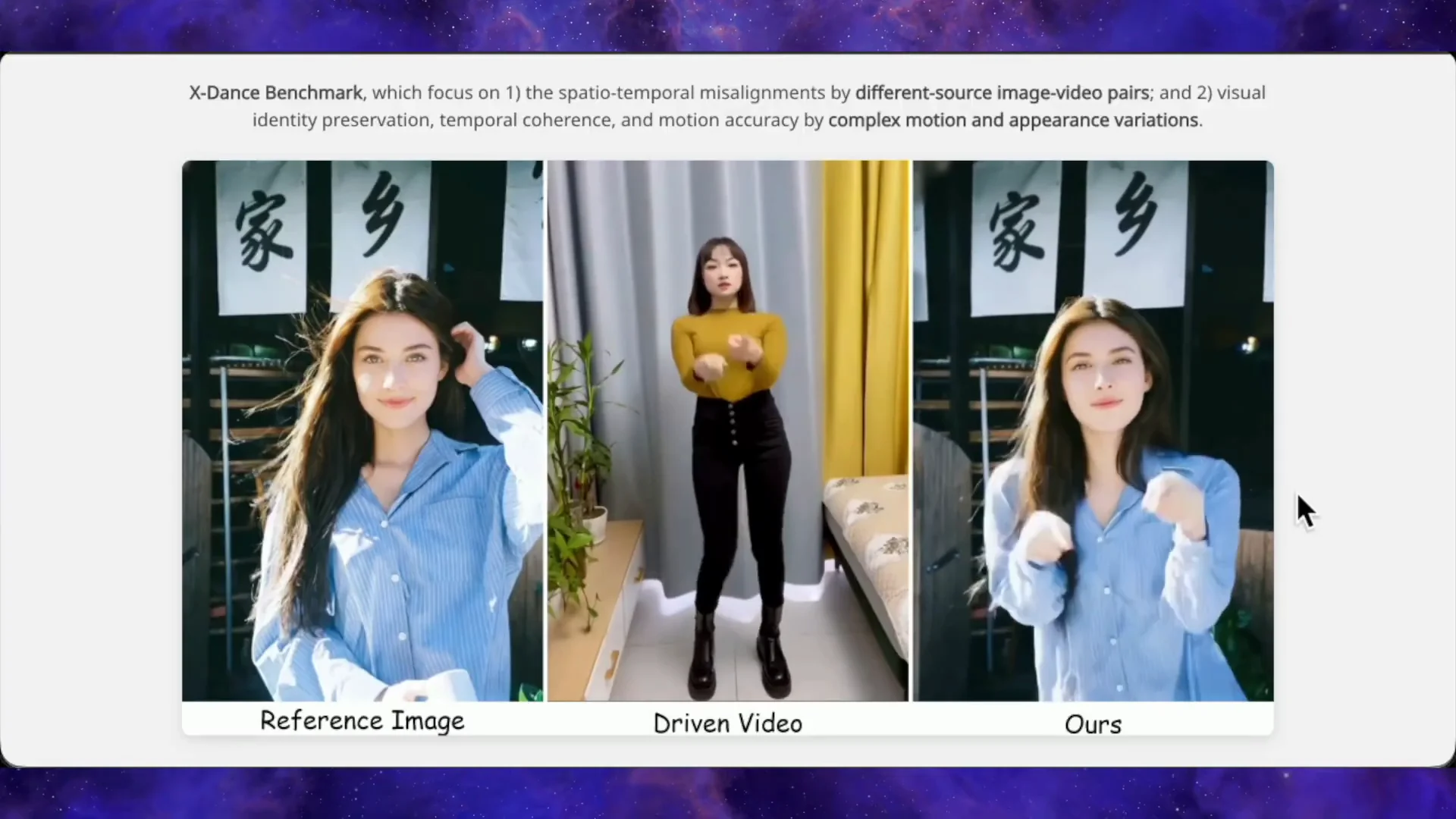
Human-Object Interactions and the Xance Benchmark
It does something many models miss: human-object interactions driven by pose or skeleton cues. The authors introduce a benchmark called Xance where they pair mismatched reference images and driving videos. They use different body types, anime characters, half-body crops, motion blur, and occlusions to stress test spatial misalignment and start gap transitions. Competing models usually fail here.
Object Interaction Cases
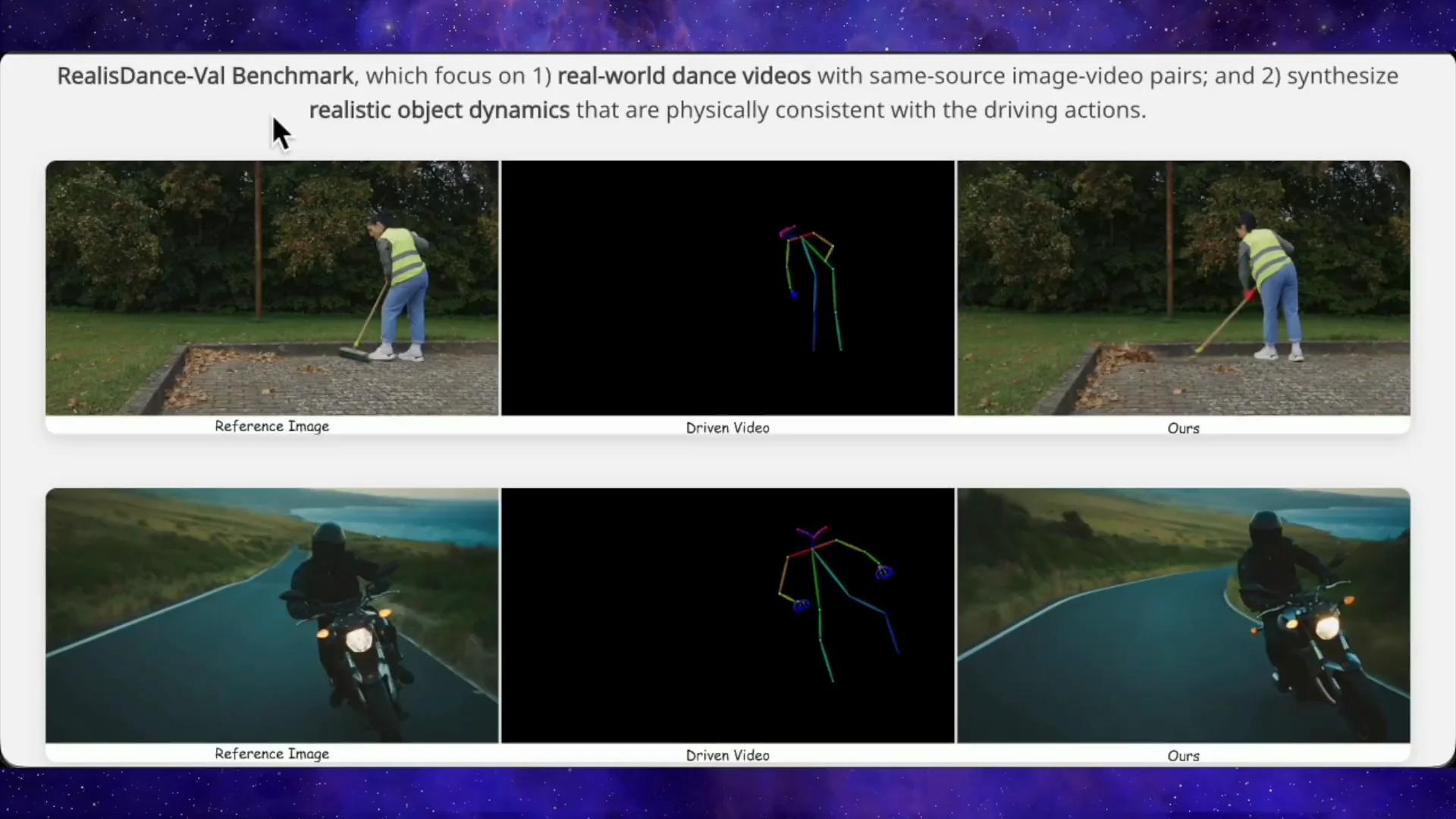
In their examples, Steady Dancer can take a skeleton video of someone sweeping and a static image of a man holding a broom. The output shows him sweeping while leaves fly away, which means the model is inferring object motion from the human pose.
They repeat that with a man shoveling snow, a footballer interacting with a ball, and a man working battle ropes on the beach. Steady Dancer controls the human body accurately and generates plausible object motion and deformation. Other methods freeze the objects or break them into shapes that do not match the action.
They show that you can drive outputs using a stick figure skeleton video instead of a real person. As long as the pose is reasonable, the result looks like a natural video where your reference character performs that action.
All of this makes it feel usable for real creative workflows, not just for dance clips.
How This New Model Works Under the Hood
At its core, Steady Dancer is built on top of Juan 2.1’s imagetovideo foundation model. That is a 14 billion parameter diffusion transformer that already knows how to generate video from a starting frame.
The team made a key design change. They switched from the old reference-to-video approach to a true imagetovideo setup that locks in your first frame and does not change it.
Why That Shift Matters
Most animation models, including the original Wan Animate, use a reference-to-video paradigm. They try to bind your character’s appearance onto the motion you give them. That sounds fine in theory, but in practice it is loose.
If your reference image and driving pose do not match well in body proportions, camera angle, or starting position, the model guesses. You end up with identity drift, face changes, and jumps at the start of the video.
Steady Dancer reverses that logic. It treats your reference frame as fixed, generates the entire video starting from that exact frame, and forces every subsequent frame to stay consistent with it. It is stricter and gives stable identity.
Keeping Strict Identity While Controlling Motion
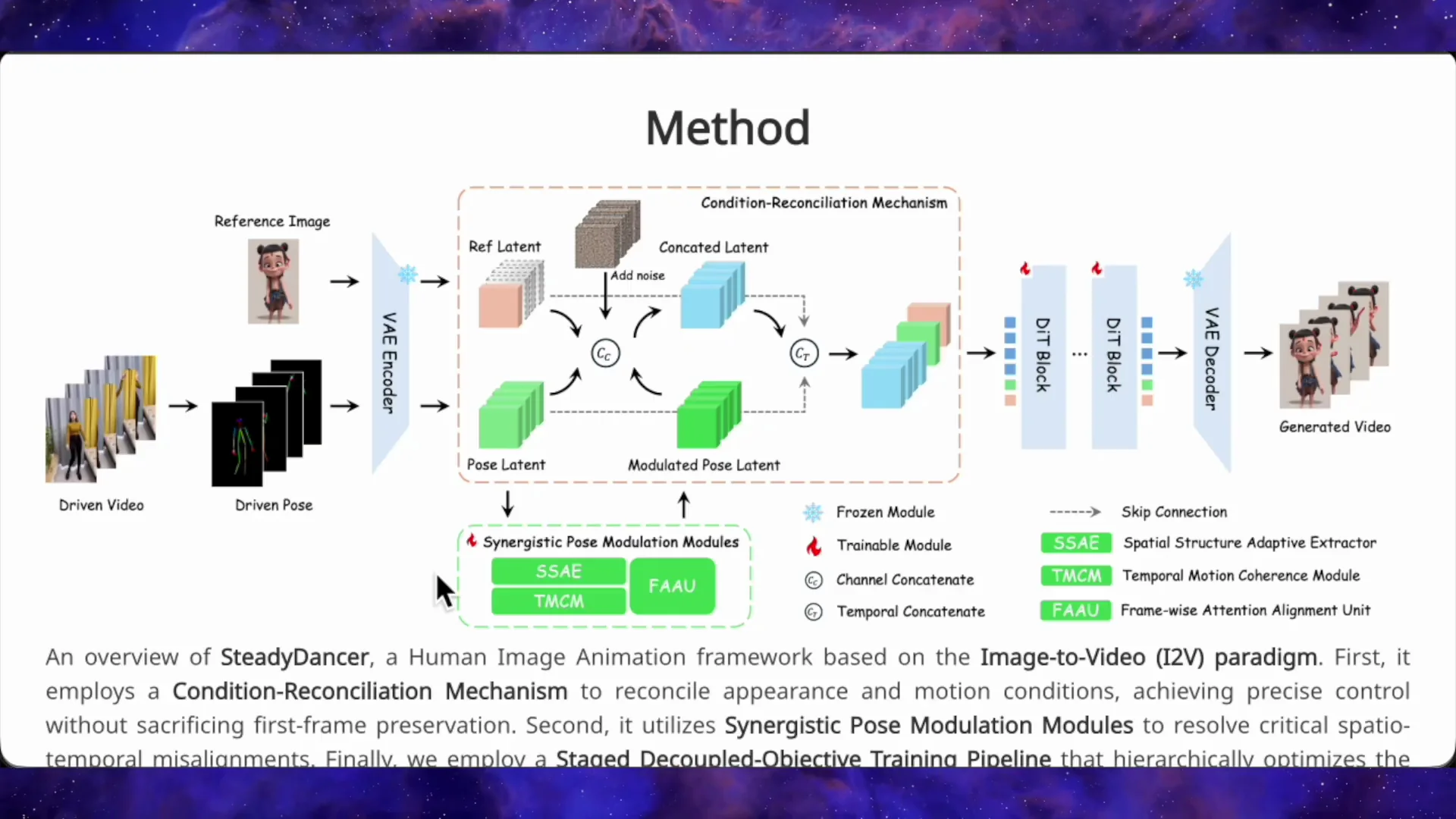
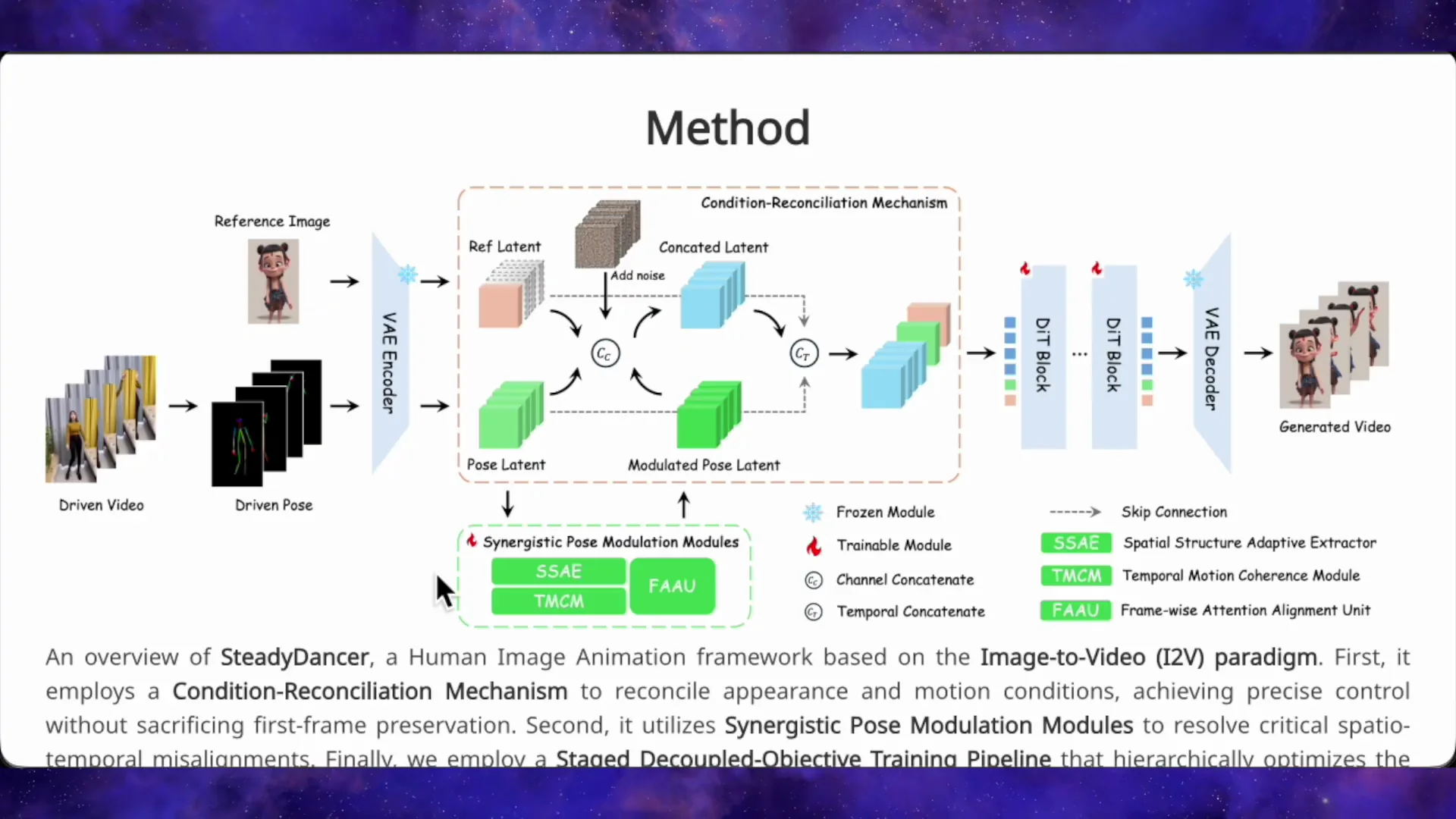
Strict identity control makes motion control hard because the pose has to adapt to the image instead of the image adapting to the pose. To solve that, the team added a condition reconciliation mechanism. They keep the appearance signal and the motion signal separated rather than merging them.
They use channel-wise separation so the model can see both clearly. They inject pose conditioning in a lightweight way using low refined tuning so they do not damage pre-trained video generation quality. They augment the input by feeding in extra copies of the first frame’s image and the first frame’s pose, plus richer semantic context. Those steps keep the model anchored to the starting appearance.
Pose Modulation Modules
Real images and driving videos rarely align well, so they built pose modulation modules to bridge the gap:
- Spatial structure adaptive refiner: reshapes pose features to match your character’s body proportions.
- Temporal motion coherence module: smooths jittery or noisy pose sequences over time to avoid flicker.
- Lightweight attention alignment unit: checks frame by frame to keep pose and appearance aligned.
These components align here is my image with here is the motion I want, especially when those two do not fit naturally.
Training Setup and Efficiency
The training uses a small, high-quality data set of about 7,300 short dance clips totaling around 10 hours of footage. The training runs for roughly 14 a.5 thousand steps on eight H800 GPUs. It is lighter than competing models that need 50,000 to 200,000 steps and larger data sets.
This efficiency matters for iteration and reproducibility. It suggests careful conditioning, data curation, and architectural choices rather than brute force scaling.
A Quick Comparison Snapshot
The following comparison reflects the outcomes described in the demos and benchmark notes:
- Metric results:
- FVD: best score on Real East Dance Val.
- Subject consistency: competitive or better.
- Background consistency: competitive or better.
- Flicker: competitive or better.
- Visual quality: competitive or better.
- Compared models:
- Wan Animate
- Mimic Motion
- HyperMotion
- Uni Animate Dit
- Human Vid
Visual Behavior by Method
-
Steady Dancer:
- Strong identity preservation anchored to the first frame.
- Accurate pose tracking with natural framing.
- Background motion present and coherent.
- Stable face during head turns and across long sequences.
- Handles cartoons, half-body references, and skeleton-driven inputs.
-
Wan Animate:
- Can push subjects back in frame.
- Background often remains static.
- Identity can drift.
-
Mimic Motion:
- Better than weak baselines but can change the face while keeping framing.
-
HyperMotion and Human Vid:
- Texture quality drops.
- Bodies can warp under challenging poses.
Practical Use and Setup
From a practical standpoint, the code and model weights are up on GitHub. You can run it locally with the right hardware resources.
- VRAM needs:
- At least 24 GB of VRAM to load the model.
- A 32 GB card like a 4090 is ideal for smooth, high-resolution generations.
- Expected variants:
- Quantized or distilled versions may appear later and run on less memory, with some quality trade-off for speed.
Quick Start Steps
Use these steps as a simple checklist based on the details provided:

- Get the code and model weights from GitHub.
- Prepare a single reference image and a driving video or a stick figure skeleton video.
- Ensure a GPU with at least 24 GB VRAM, with 32 GB recommended for higher resolutions.
- Expect future quantized or distilled builds that trade some quality for lower memory and faster runs.
Why This New Model Feels Stable in Creative Workflows
The model consistently animates identity, framing, and scene context without odd zooms or crops. It carries motion one-to-one with the driver where possible, keeps faces aligned to the first frame, and adds background movement that fits the shot.
It sustains identity during head turns and deals well with half-body references driven by full-body motions. It also adapts to cartoons, keeping limbs clean and the character’s look consistent.
Strong Performance on Mismatched Inputs
The Xance benchmark pairs mismatched references and driving clips across body types, crops, blur, occlusions, and style differences. That stresses spatial alignment and starting transitions. The examples show that Steady Dancer:
- Aligns poses to diverse bodies with the spatial structure adaptive refiner.
- Smooths time-series pose noise with temporal motion coherence.
- Keeps appearance and pose aligned with the attention alignment unit.
Pose to Object Motion
In tests with sweeping, shoveling, ball handling, and battle ropes, the model infers object motion from human pose. Objects move and deform as expected. Competing methods often freeze the objects or distort them.
Design Summary of This New Model
The system is built on a 14 billion parameter diffusion transformer, trained to generate video from a starting frame. The first frame preservation approach anchors identity and framing.
The condition reconciliation mechanism keeps appearance and motion signals separate. Channel-wise separation, lightweight pose injection via low refined tuning, and first frame augmentation help keep the generator steady while following external motion.
Pose modulation modules adapt the driver’s pose to the subject’s proportions, filter temporal noise, and keep pose-appearance alignment stable.
Key Takeaways
- First frame preservation secures identity and framing across the whole clip.
- Pose control remains strong due to condition reconciliation and pose modulation.
- Performance is strong across benchmarks and visual comparisons.
- It runs with manageable compute relative to many peers.
- Code and weights are available, and the hardware footprint is clear.
Comparison Table: Models and Observed Behavior
| Model | Identity Stability | Framing | Background Motion | Texture/Body Integrity | Notes from Comparisons |
|---|---|---|---|---|---|
| Steady Dancer | High | Natural | Present | Strong | Best FVD on Real East Dance Val, strong across consistency metrics |
| Wan Animate | Moderate | Can push subject back | Often static | Moderate | Artifacts appear on closer inspection |
| Mimic Motion | Moderate | Keeps framing | Mixed | Moderate | Can change face identity |
| HyperMotion | Low | Mixed | Mixed | Weak | Low-quality textures, warped bodies in hard cases |
| Human Vid | Low | Mixed | Mixed | Weak | Breaks on harder motion |
| Uni Animate Dit | Competitive | Mixed | Mixed | Competitive | Included in benchmark comparisons |
Technical Notes for This New Model
- Backbone: imagetovideo diffusion transformer with 14 billion parameters.
- Paradigm: imagetovideo with first frame preservation, not reference-to-video.
- Conditioning: appearance and motion separated with channel-wise design.
- Injection: pose added via lightweight low refined tuning.
- Augmentation: extra copies of first frame image and pose, plus richer semantic context.
- Pose modulation: spatial structure adaptive refiner, temporal motion coherence module, attention alignment unit.
- Training data: around 7,300 short dance clips, about 10 hours total.
- Training schedule: roughly 14 a.5 thousand steps on eight H800 GPUs.
- Relative cost: much lighter than runs needing 50,000 to 200,000 steps and larger data sets.
Visual Characteristics You Can Expect
- Faces that match the first frame across long sequences.
- Motion that follows the driving video closely.
- Camera behavior that feels natural, without forced zooms or crops.
- Backgrounds that move in ways that fit the scene.
- Stability across head turns and identity-sensitive angles.
- Support for cartoons with stable shapes and features.
Input Flexibility
- Single image plus a driving video.
- Skeleton stick figure driving video for pose-only control.
- Half-body inputs animated at the same framing while respecting the original composition.
Final Thoughts on This New Model
Steady Dancer addresses identity drift, framing issues, static backgrounds, and face shifts by locking appearance to the first frame and adapting pose to match it. The comparisons show stronger subject consistency and natural scene motion.
The technical choices support strict identity control while maintaining responsive motion. Training remains efficient, and the system is available to run with clear VRAM guidance. Quantized or distilled versions could lower the memory bar with a known trade-off in quality.
The result is stable, clear motion transfer from a single reference image, consistent identity across time, and outputs that align with real shot behavior.
Subscribe to our newsletter
Get the latest updates and articles directly in your inbox.

Related Posts

8 Best Claude Code Plugins in 2026 (You Need to Know)
8 Best Claude Code Plugins in 2026 (You Need to Know)

7 Best Claude Code Skills (You Need to Know)
7 Best Claude Code Skills (You Need to Know)

Claude Code Desktop IDE Features (You Need to Know)
Claude Code Desktop IDE Features (You Need to Know)