
Table Of Content
- OmniASR with OmniASR-LLM 7B: Run on CPU Locally
- Why OmniASR Matters
- OmniASR - Local Installation Setup
- Step-by-step installation
- What to expect after launch
- OmniASR - Gradio Interface and First Run
- OmniASR - Multilingual Tests
- Polish
- Punjabi
- Indonesian Bahasa
- An African Language
- OmniASR - Model Architecture Overview
- OmniASR - Architecture Summary Table
- OmniASR - Performance and Practical Value
- Integration and ecosystem
- Use cases to consider
- OmniASR - Detailed Local Workflow
- 1 - Install the package
- 2 - Clone the repository
- 3 - Prepare the inference script
- 4 - Launch the pipeline
- 5 - Upload and transcribe
- OmniASR - Notes on Testing
- OmniASR - What Stands Out in Practice
- OmniASR - Broader Takeaways
- OmniASR - Practical Summary
- Quick reference - what you get
- OmniASR - Closing Notes

Install Meta OmniASR-LLM 7B on CPU: Local ASR for 1,600 Languages
Table Of Content
- OmniASR with OmniASR-LLM 7B: Run on CPU Locally
- Why OmniASR Matters
- OmniASR - Local Installation Setup
- Step-by-step installation
- What to expect after launch
- OmniASR - Gradio Interface and First Run
- OmniASR - Multilingual Tests
- Polish
- Punjabi
- Indonesian Bahasa
- An African Language
- OmniASR - Model Architecture Overview
- OmniASR - Architecture Summary Table
- OmniASR - Performance and Practical Value
- Integration and ecosystem
- Use cases to consider
- OmniASR - Detailed Local Workflow
- 1 - Install the package
- 2 - Clone the repository
- 3 - Prepare the inference script
- 4 - Launch the pipeline
- 5 - Upload and transcribe
- OmniASR - Notes on Testing
- OmniASR - What Stands Out in Practice
- OmniASR - Broader Takeaways
- OmniASR - Practical Summary
- Quick reference - what you get
- OmniASR - Closing Notes
OmniASR with OmniASR-LLM 7B: Run on CPU Locally
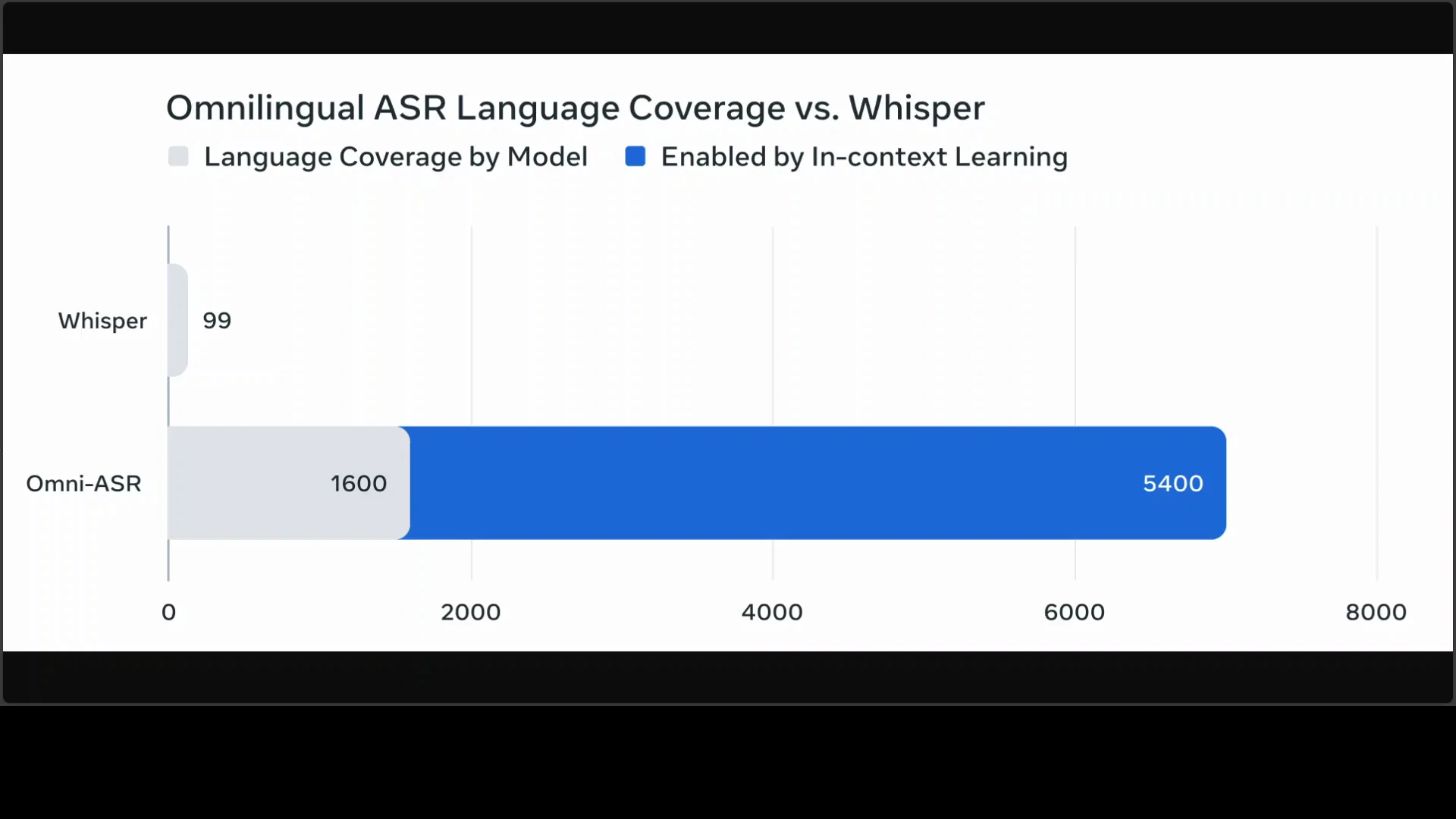
Meta has released another Omni ASR model that supports more than 1,600 languages from across the globe. This model has been anticipated for a long time and delivers well. It represents a pinnacle of the omnilingual ASR suite, an open-source framework designed to provide state-of-the-art automatic speech recognition, including 500 previously untranscribed low resource languages.
In this guide, I install it locally and cover setup, testing, architecture, and other practical details. One of the most important points is that this model is Apache 2 licensed, which means you can use it commercially and customize it for your own use case.
Why OmniASR Matters
- Supports 1,600 plus languages, including 500 low resource languages that were previously untranscribed.
- Open-source and Apache 2 licensed for commercial use and customization.
- Lightweight and small enough to run on CPU.
- Practical to install and test locally across Ubuntu, macOS, and Windows.
OmniASR - Local Installation Setup
The model is lightweight and small enough to run entirely on CPU. I used an Ubuntu system, but you can install it on macOS or Windows.
The installation is straightforward. All you need is Python and a few commands to set up the package, clone the repository, and launch the interface.
Step-by-step installation
- Install the package
- Run pip install omnilingual ASR
- This installs the required components.
- Clone the repository
- Clone the omnilingual ASR repository to your local machine.

- Use the provided inference script
- The repository includes a script for inference.
- I modified it slightly to add a simple Gradio interface on top.
- Launch the pipeline
- From the repository directory, run the pipeline script to start a Gradio interface in your browser.
What to expect after launch
- A browser tab opens with a simple interface for uploading audio.
- You can choose a language for transcription.
- You can upload local audio files and run transcriptions directly.
OmniASR - Gradio Interface and First Run
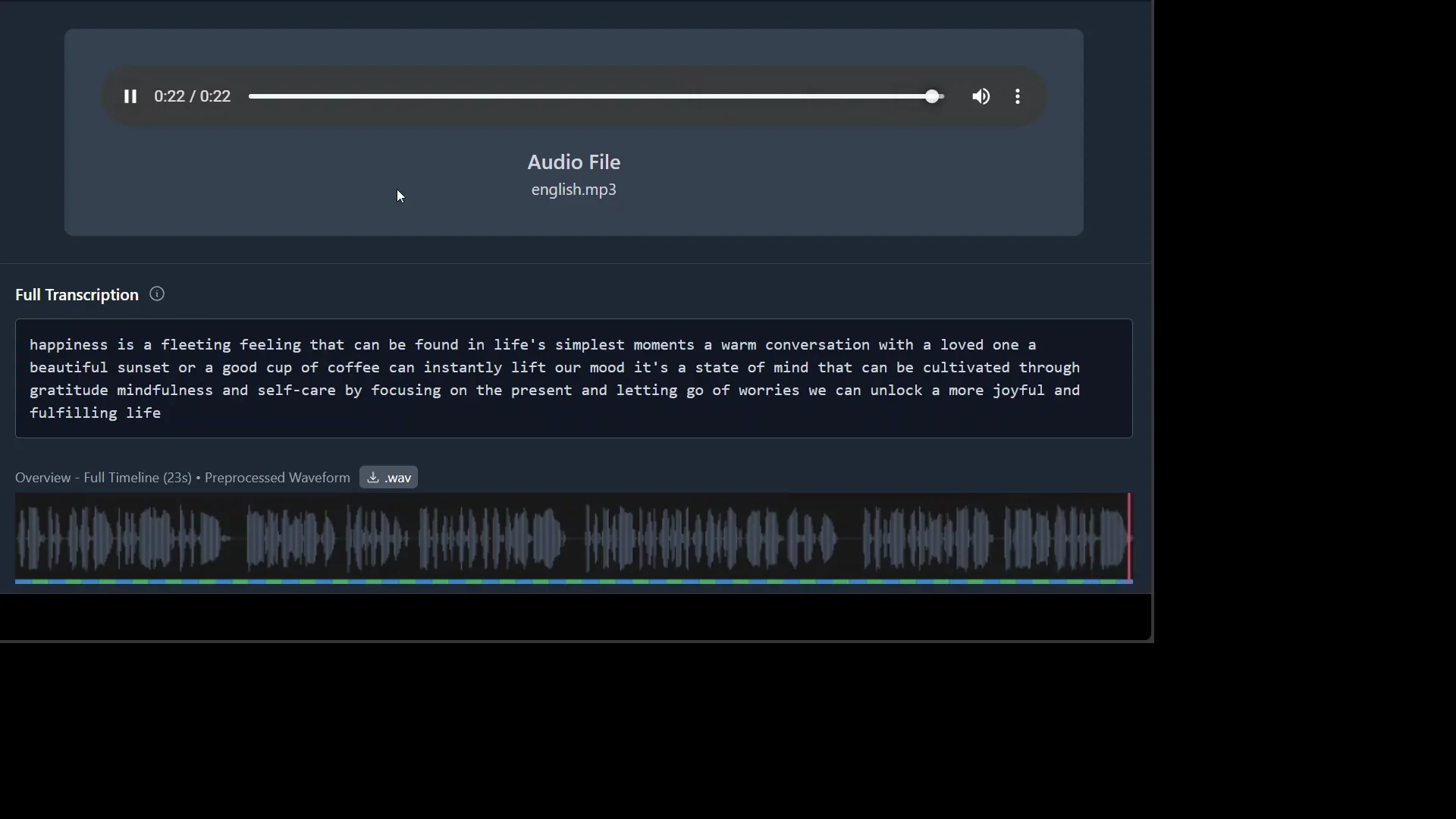
I uploaded an audio file from my local system to test transcription. I started with English and selected the transcription language as English. I played the audio before transcription:
- Happiness is a fleeting feeling that can be found in life's simplest moments. A warm conversation with a loved one, a beautiful sunset, or a good cup of coffee can instantly lift.
I ran the transcription and waited for completion. After the model finished, I played back the transcribed content:
- Happiness is a fleeting feeling that can be found in life's simplest moments. A warm conversation with a loved one, a beautiful sunset, or a good cup of coffee can instantly lift our mood. It's a state of mind that can be cultivated through gratitude, mindfulness, letting go of can unlockful and fulfilling life.
The result looked accurate for the most part. It was a strong first pass.
OmniASR - Multilingual Tests
The next step was to try a few languages beyond English. The model supports a global range of languages, and I wanted to see how it performs across different regions.
Polish
I tested a Polish audio sample. I left the assessment of precise meaning to native speakers, but the model processed the input as expected.
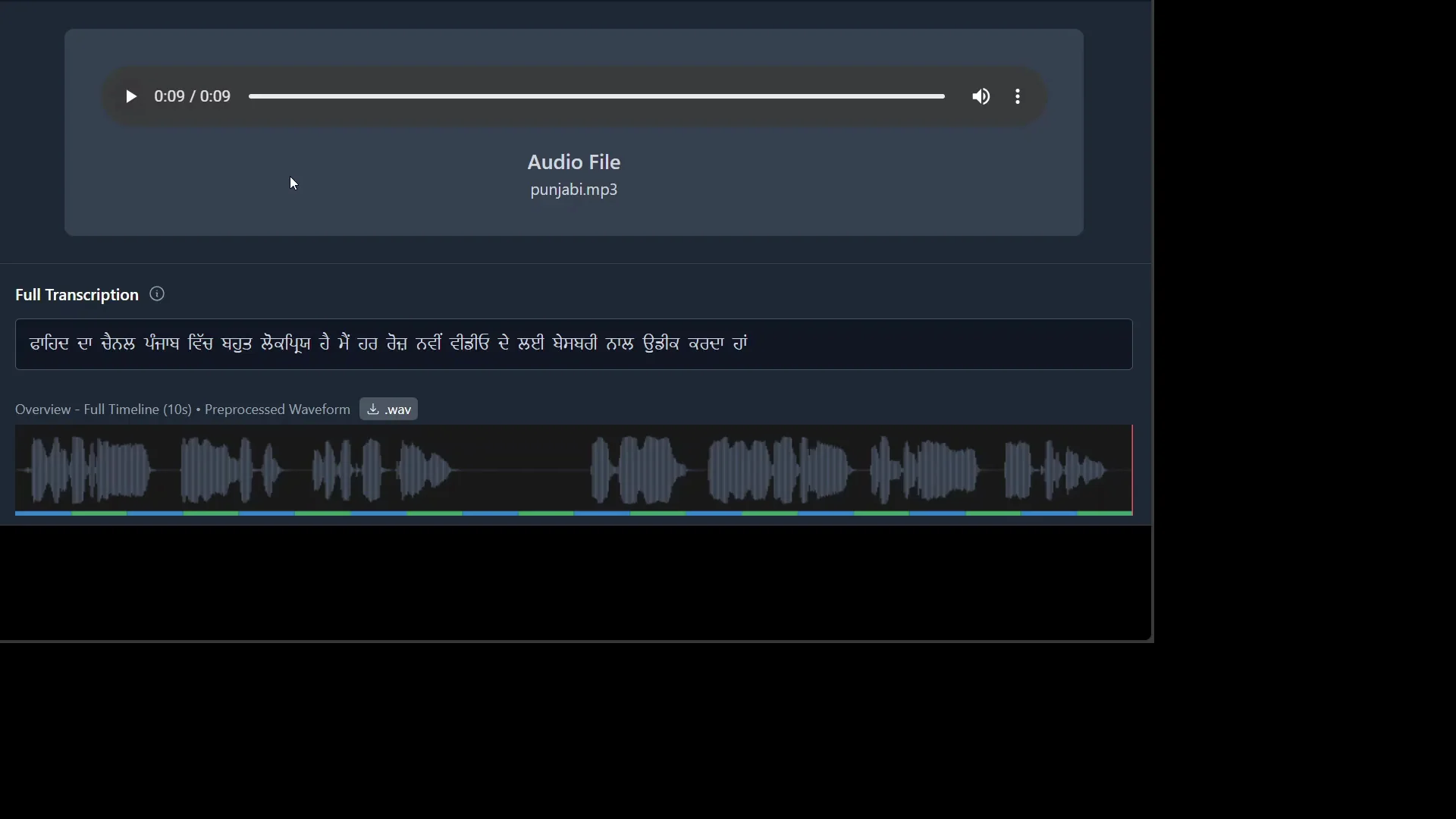
Punjabi
I tested Punjabi next, which is referred to as a regional language in both India and Pakistan and is one of the most widely spoken languages in the world. I attempted a simple Punjabi input. The goal was to verify the model’s ability to handle the script and phonetics. It worked for the test case.
Indonesian Bahasa
I tried an Indonesian Bahasa clip next and ran the transcription. The sample included a simple greeting such as Hello. The natural reply would be sama sama. This reinforced that the model handles omnilingual input well.
An African Language
I finished with an African language sample that included the word asante. The model handled it properly.
OmniASR - Model Architecture Overview
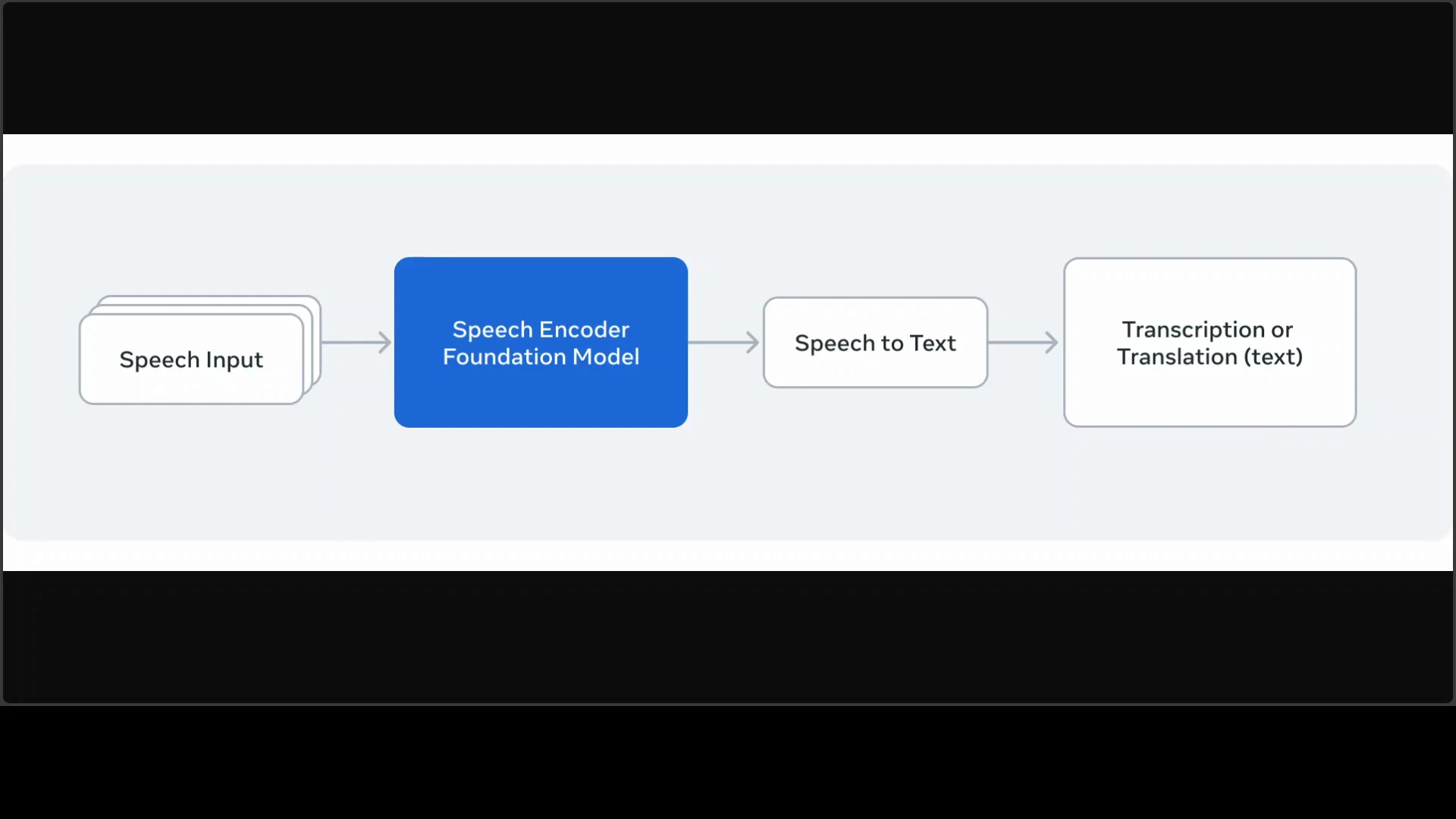
The architecture is simple and effective. Omni ASR LLM 7 billion uses a hybrid encoder-decoder design that combines a massively scaled self-supervised wav2vec 2 encoder with an LLM-inspired transformer decoder. It is the first 7 billion parameter instantiation of this encoder for speech tasks.
The wav2vec encoder is pre-trained on vast untranscribed multilingual audio data, about 4.3 million hours across 1,600 plus languages. It extracts rich semantic representations from raw waveforms using a convolutional feature extractor, followed by a transformer layer with grouped query attention and rotary positional embeddings for efficiency.
From there, it feeds into a traditional autoregressive transformer that maps the encoded, contextualized speech to text. A notable innovation is the model’s zero-shot generalization via in-context learning, which borrows ideas from LLM training approaches. The overall setup is thoughtfully designed for broad multilingual coverage.
OmniASR - Architecture Summary Table
| Component | Description |
|---|---|
| Model name | OmniASR-LLM 7B |
| Design | Hybrid encoder-decoder |
| Encoder | Self-supervised wav2vec 2 |
| Decoder | LLM-inspired transformer |
| Parameters | 7 billion |
| Pretraining data | ~4.3 million hours of untranscribed multilingual audio |
| Languages | 1,600 plus |
| Low resource coverage | 500 previously untranscribed languages |
| Feature extractor | Convolutional feature extractor |
| Attention | Grouped query attention |
| Positional embeddings | Rotary positional embeddings |
| Decoding | Autoregressive transformer |
| Inference | CPU capable |
| License | Apache 2 |
OmniASR - Performance and Practical Value
The reported benchmarks are impressive. The broad multilingual focus is the key strength. Support for 1,600 plus languages, including 500 previously untranscribed low resource languages, makes this model suitable for applications where coverage matters more than anything else.
The permissive Apache 2 license is another advantage. You can use it commercially and customize it to fit your needs.
Integration and ecosystem
- Compatible with the fairseq 2 toolkit and the PyTorch ecosystem.
- Can be integrated into a wide range of pipelines.
- Works with scripting or lightweight web interfaces like Gradio.
Use cases to consider
- Real-time transcription.
- Accessibility tools at a global scale.
- Multilingual processing across a wide variety of languages and dialects.
OmniASR - Detailed Local Workflow
Below is the flow I followed, step by step, matching the order shown above.
1 - Install the package
- Run pip install omnilingual ASR to install the core package and dependencies.
- Confirm the installation finishes without errors.
2 - Clone the repository
- Clone the omnilingual ASR repository locally.
- Move into the cloned directory.
3 - Prepare the inference script
- Use the provided inference script.
- I added a minimal Gradio interface on top to make testing easier in the browser.
4 - Launch the pipeline
- From the repository directory, run the pipeline to launch a Gradio interface.
- A browser window opens with an upload field and a language selector.
5 - Upload and transcribe
- Upload an audio file from your local system.
- Select the language for transcription.
- Start with English or choose a non-English language you want to test.
- Run the transcription and review the output.
OmniASR - Notes on Testing
I began with English. The initial audio sample read:
- Happiness is a fleeting feeling that can be found in life's simplest moments. A warm conversation with a loved one, a beautiful sunset, or a good cup of coffee can instantly lift.
The model generated:
- Happiness is a fleeting feeling that can be found in life's simplest moments. A warm conversation with a loved one, a beautiful sunset, or a good cup of coffee can instantly lift our mood. It's a state of mind that can be cultivated through gratitude, mindfulness, letting go of can unlockful and fulfilling life.
I then moved to other languages in quick succession.
- Polish: processed successfully, with accuracy best judged by native speakers.
- Punjabi: tested with a simple input; it worked for the purpose of validation.
- Indonesian Bahasa: included a simple greeting such as Hello, with the natural reply being sama sama.
- An African language: included the word asante and processed correctly.
OmniASR - What Stands Out in Practice
- The model runs on CPU and remains responsive for short clips.
- The interface can be made accessible through a minimal web front end.
- The multilingual handling is the core strength, and it shows in quick tests.
OmniASR - Broader Takeaways
Meta remains active in speech recognition and continues to refine Omni ASR. This is not the first release in the Omni ASR series. The work is evolving, with improvements in coverage and capabilities.
The combination of a robust encoder, an LLM-inspired decoder, and training across millions of hours of multilingual audio gives this model strong multilingual range. Zero-shot generalization via in-context learning helps the model adapt to inputs across languages and contexts without manual per-language tuning.
OmniASR - Practical Summary
- If you want a local, CPU-friendly ASR model with broad language coverage, this is a strong option.
- The Apache 2 license allows commercial deployment and customization.
- Integration with fairseq 2 and PyTorch makes it straightforward to add to existing workflows.
- Gradio offers a quick way to validate results in the browser.
Quick reference - what you get
- 1,600 plus languages supported.
- 500 previously untranscribed low resource languages included.
- Hybrid encoder-decoder architecture with wav2vec 2 and a transformer decoder.
- Pretrained on about 4.3 million hours of multilingual audio.
- Grouped query attention and rotary positional embeddings for efficient modeling.
- Autoregressive decoding for transcription.
- Apache 2 licensed, with practical integration paths.
OmniASR - Closing Notes
Meta is still there, and this release is a strong entry. The multilingual focus is the main highlight. The license is permissive, the setup is straightforward, and local testing is easy.
The Omni ASR line has been released before and continues to evolve. This iteration pushes broader coverage with practical deployment in mind.
Subscribe to our newsletter
Get the latest updates and articles directly in your inbox.

Related Posts

8 Best Claude Code Plugins in 2026 (You Need to Know)
8 Best Claude Code Plugins in 2026 (You Need to Know)

7 Best Claude Code Skills (You Need to Know)
7 Best Claude Code Skills (You Need to Know)

Claude Code Desktop IDE Features (You Need to Know)
Claude Code Desktop IDE Features (You Need to Know)