
How Ming-Omni-TTS Blends Your Emotion, Voice, and Music at 1 place?
The emerging lab Inclusion AI from China has just released Ming-Omni-TTS. I tested it out and I am going to tell you all about it. We have been covering their Ring, Ling, and Ming models for quite some time and they seem quite promising.
Not there yet, but I think this is going to be a big deal in 2026. They have released two variants of this model.
There is a small 1.5 billion and then there is a larger one 16.8 billion which seems like a mixture of expert model.
This is a text to speech model which is developed for unified audio generation meaning it can produce speech, environmental sounds and music together in a single output rather than handling each separately.
It also gives you a fine grain control over how speech sounds including rate, pitch, volume, emotion and dialect. It comes with over 100 built-in voices plus ability to create new voices from natural language description.
How Ming-Omni-TTS Blends Your Emotion, Voice, and Music at 1 place?
I would love to get it installed locally. I have actually tried for 2 to three hours. At the moment, it's not working.
It was just released. Maybe there are some issues. They also have their GitHub repo which is not of much use.
This is one huge weakness of this company that still their models are not that straightforward to get installed. There are multiple components scattered all over the place which you have to knit together and it takes hours and hours to get it fixed and installed. This is one area they badly need to improve.
Access and setup
This is a demo I am using from modelscope.cn. It's a Chinese website but I already have an account and I have some credits.
If you don't want to use ModelScope, you can go to Hugging Face and try using the space, which breaks a lot by the way.
Try the Ming-Omni-TTS demo on Hugging FaceEmotion control in TTS
From the drop-down, I selected Emotion and used their TTS model first. This is where I am giving the sentence. It is all in Chinese, so I translated it in my browser to English.
I uploaded one of my own audio, cloned that audio with some emotion, and the sentence should be spoken. The original audio in my own voice was: Joy is found in simple moments of gratitude and true contentment comes when we truly value the small blessings we already have in life. The resultant was: This is the best day of my life.
I think this was pretty good. This is what is very impressive about Inclusion AI: the quality of the models.
I'm sure that once they resolve installation issues and address more of the global community, that is going to be a big thing.
Pushing for romantic nuance
I selected another voice and another sentence. The original was: Happiness is a fleeting feeling that can be found in life's simplest moments. A warm conversation with a loved one. A beautiful sunset.
The resultant was: I love you so much it aches. I wish you were here right now. It is a romantic sentence full of longing, but I couldn't see the emotion here.
I made it more expressive: My heart races every time. The generated audio said: My heart races every time I see your name. I am so deeply in love with you.
Not really. It's not there yet. I reloaded the page to reset the context, but it stayed flat and it didn't catch that nuanced emotion at all.
Dialects and zero-shot cloning
You can select some of the dialects, mainly geared towards Chinese, and then some style or just basic TTS. There is also a zero shot TTS where you provide an audio and the text and it should be able to do it. This is only English and Chinese by the way, nothing else.
I used a different voice and tested with a poor-quality sample: You've hit me four times now. It got stuck and could not clear up the bad audio.
It seems it cannot take care of bad audio quality. Your audio quality should be decent enough.
Multi-speaker podcast test
I tested a podcast-style scene with two speakers. The first speaker was me and the second was an AI-generated female voice. I uploaded both audios and generated the dialogue.
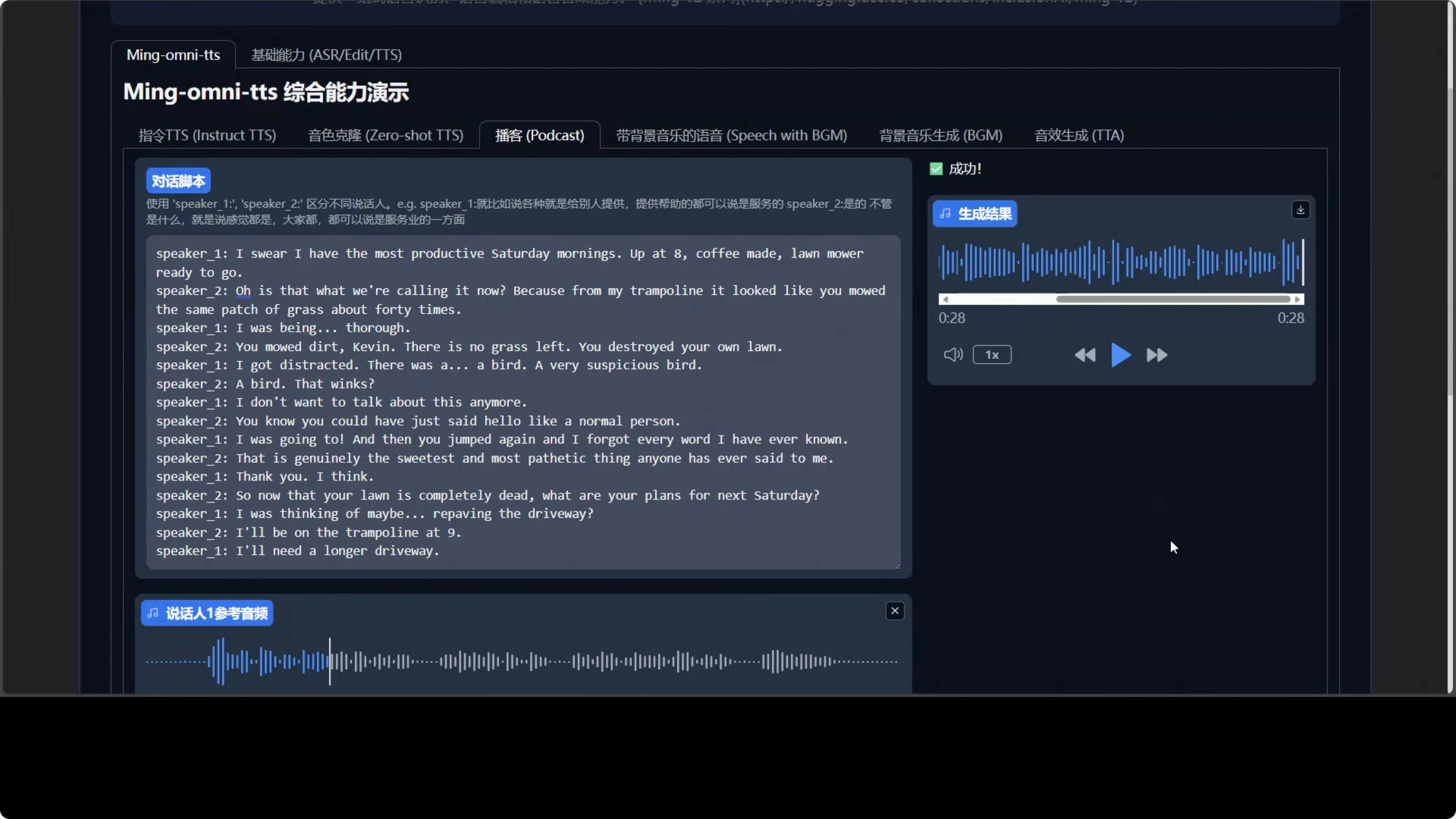
Here is what it produced: I swear I have the most productive Saturday mornings. Apart. That winks. I don't want to talk about this anymore. You know, you could have just said hello like a normal person. I was going to. And then you jumped again and I forgot every word I have ever known.
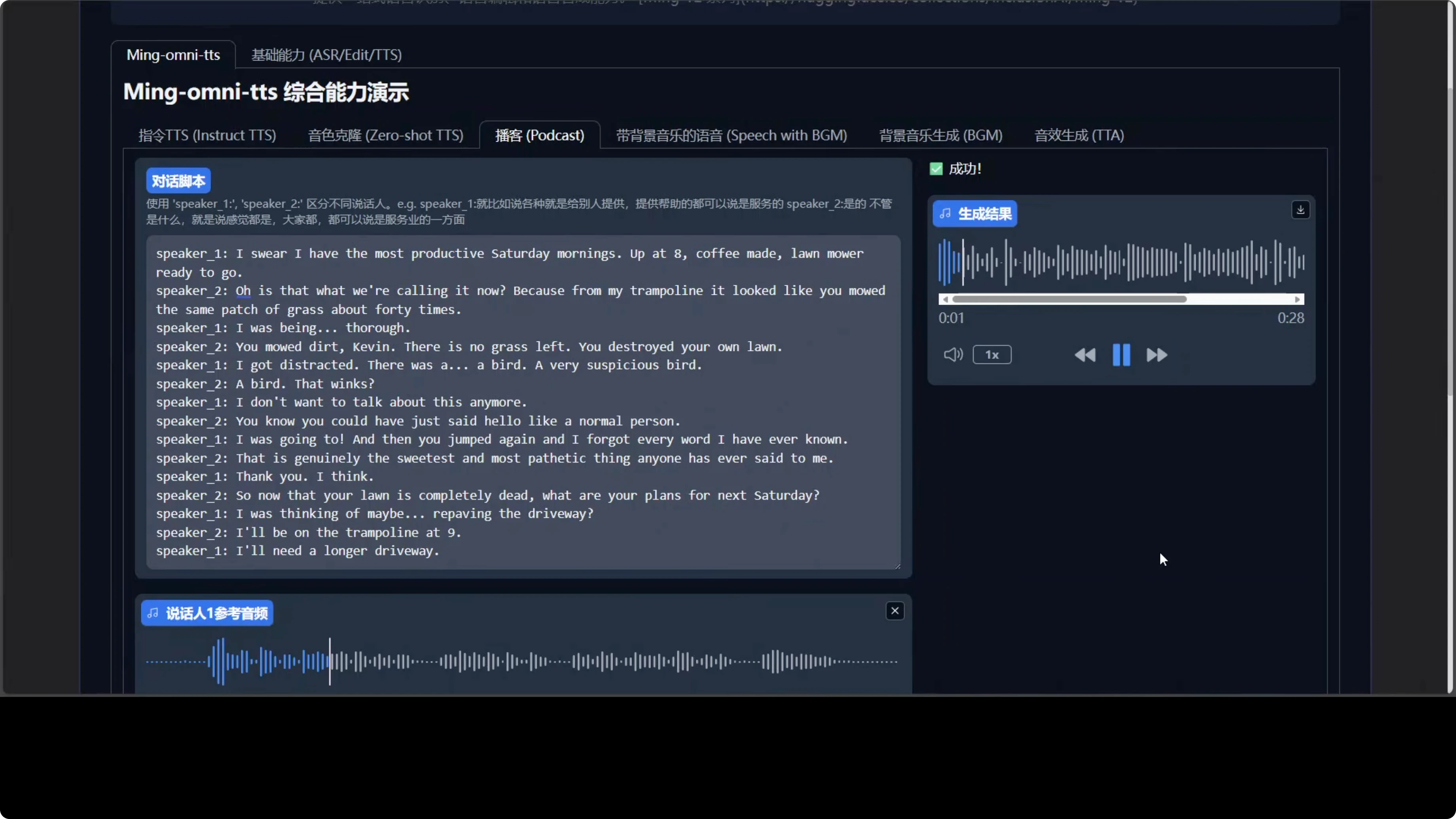
That is genuinely the sweetest and most pathetic thing anyone has ever said to me. Thank you. I think so. Now that your lawn is completely dead, what are your plans for next Saturday? I was thinking of maybe repaving the driveway. I'll be on the trampoline at 9:00. I'll need a longer driveway.
Because my dialogue was long, it shrunk it to about 28 seconds. I shortened the text and tried again. Here is the next result:
I swear I am being very productive right now. Very focused. Very professional. Fad, you have mowed the same patch of dirt six times. I got distracted by a bird. A bird that winks. I don't want to talk about it.
You could have just said hello. You know, I forgot every word I have ever known. That is the most pathetic and sweetest thing anyone has said to me. I'll take it.
The voice cloning of the male version was not there and it made mistakes mixing and matching both. Maybe in the next version or with the larger version this will improve. The speaker turns are not bad at all and the second audio is pretty good.
Background music with speech
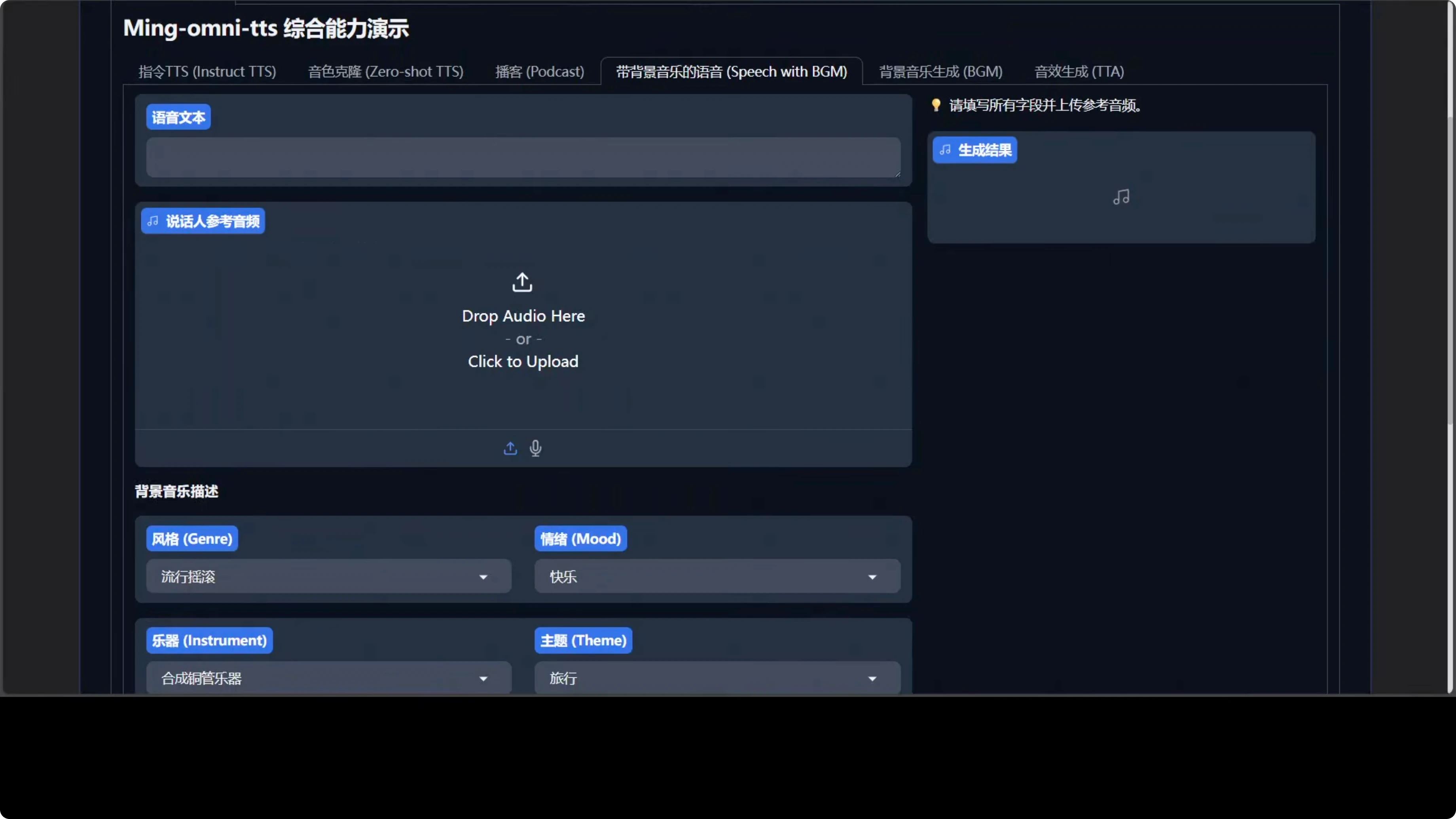
This is where you give any text and optionally any audio. I selected the same female voice as earlier.
I set genre to pop rock, mood to happy, instrument to something like synthesizer brass, and theme to travel. I clicked on BGM and generated. Here is what it said:
The city never sleeps. Every light in every window tells a story.
Yeah, it's okay and not bad. It can generate background music with speech or just background music if you like.
Final thoughts
The models are quite promising. They need to polish them, remove rough edges, and make installation easier and workable. Make it more global oriented.
The demos and the instructions should be in English. More language inclusion would be good, but starting from English is the right first step.
Subscribe to our newsletter
Get the latest updates and articles directly in your inbox.

Related Posts

8 Best Claude Code Plugins in 2026 (You Need to Know)
8 Best Claude Code Plugins in 2026 (You Need to Know)

7 Best Claude Code Skills (You Need to Know)
7 Best Claude Code Skills (You Need to Know)

Claude Code Desktop IDE Features (You Need to Know)
Claude Code Desktop IDE Features (You Need to Know)