
Kani TTS 2: Open Source Fastest Text to Speech
Kani TTS 2 is here. In last year, I covered the first version of Kani TTS and the model was quite promising. In this new version, the creators have focused on accents and dialects.
It is an open-source text to speech model featuring frame level position encodings. It is specifically optimized for ultra low latency realtime conversations like chat bots and virtual assistants.
I am using an Ubuntu system with one GPU card, Nvidia RTX 6000 with 48 GB of VRAM, but you do not need that much VRAM or even a GPU. You can easily run it on your CPU. VRAM usage during my tests stayed around 2.566 GB when fully loaded onto the GPU.
Kani TTS 2: Open Source Fastest Text to Speech overview
The installation of Kani TTS 2 is quite simple. I created a virtual environment and installed Kani TTS along with a Gradio interface and a specific transformers version.
I then ran a small Python script based on what they provided in the Hugging Face card to download and run the model.
The first thing it does is load all the accents in English. The model then loads and runs on the local system.
I accessed it at localhost port 7860.
Setup
Create a virtual environment.
Activate the virtual environment.
Install Kani TTS with pip.
Install Gradio and the required transformers version.
Run the Python script to download and start the model.
Open localhost:7860 to use the interface.
python -m venv .venv
source .venv/bin/activateAccents and dialects
I tried a few of the speakers. The model list included locations like Liverpool, Oakland, New York, and Glasgow. You can also clone your own voice by uploading embeddings in JSON format with 128 floating point numbers.
Available Speakers
| Speaker |
|---|
| 🇺🇸 Frank from Boston |
| 🇺🇸 Jermaine from Oakland |
| 🏴 Rory from Glasgow |
| 🏴 Baddy from Liverpool |
| 🇺🇸 Chelsea from New York |
| 🇺🇸 Andrew from San Francisco |
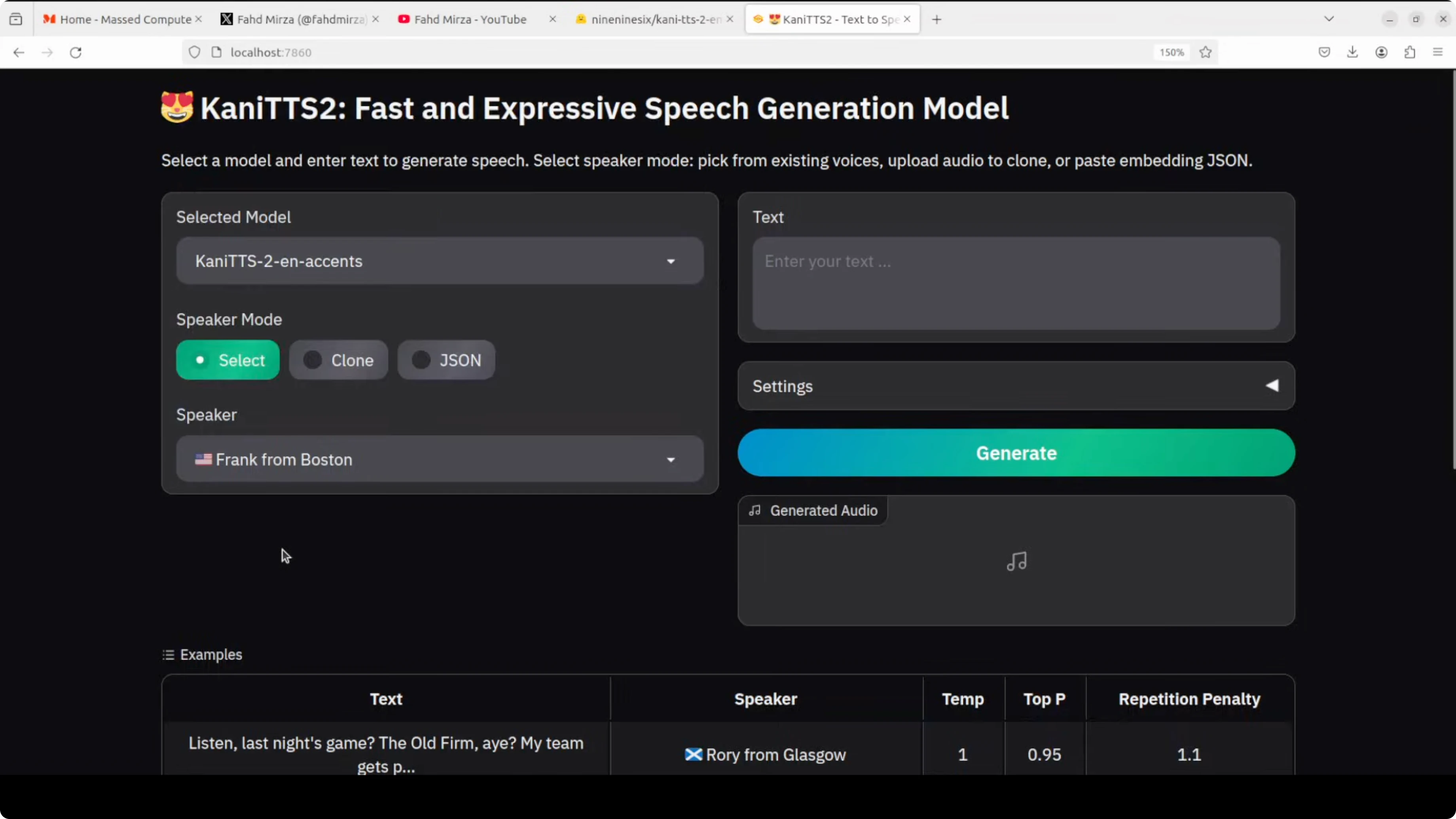
Boston test
I started with Frank from Boston. The sentence I used would require a thick accent that drops Rs, heavy on wicked and local grit. I generated the audio and played the result.
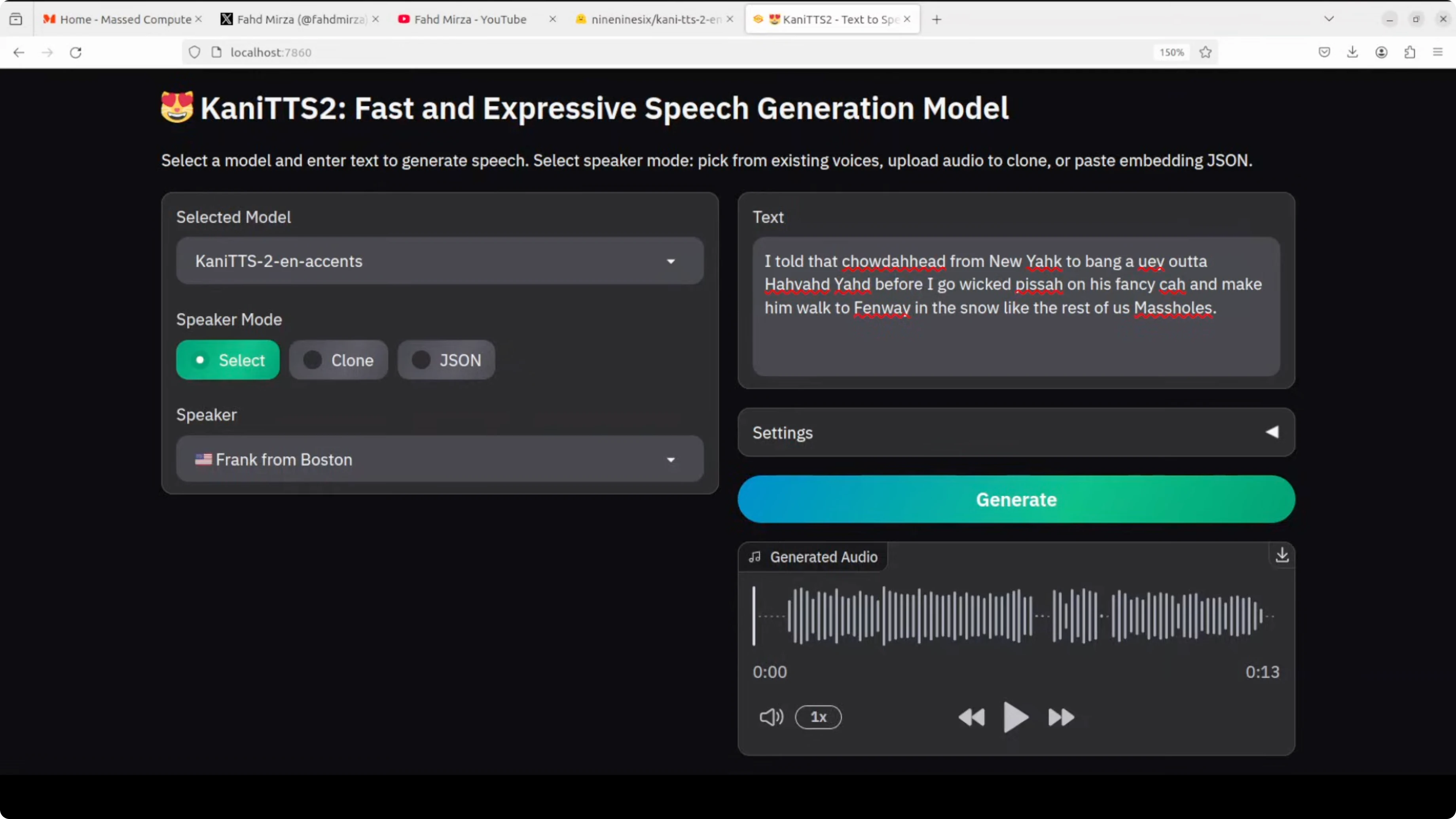
"New York to bang a UAB. I told that shouty head from New York to bang a UA habad yad before I go wicked pissa on his fancy car and make him walk to Fenway in the snow like the rest of us mash holes."
New York test
Next I went with Chelsea from New York. I aimed for key New York accent triggers like coffee, everyday chaos, pizza slices, and that impatient, witty city energy. It took about 30 seconds to generate on my setup.
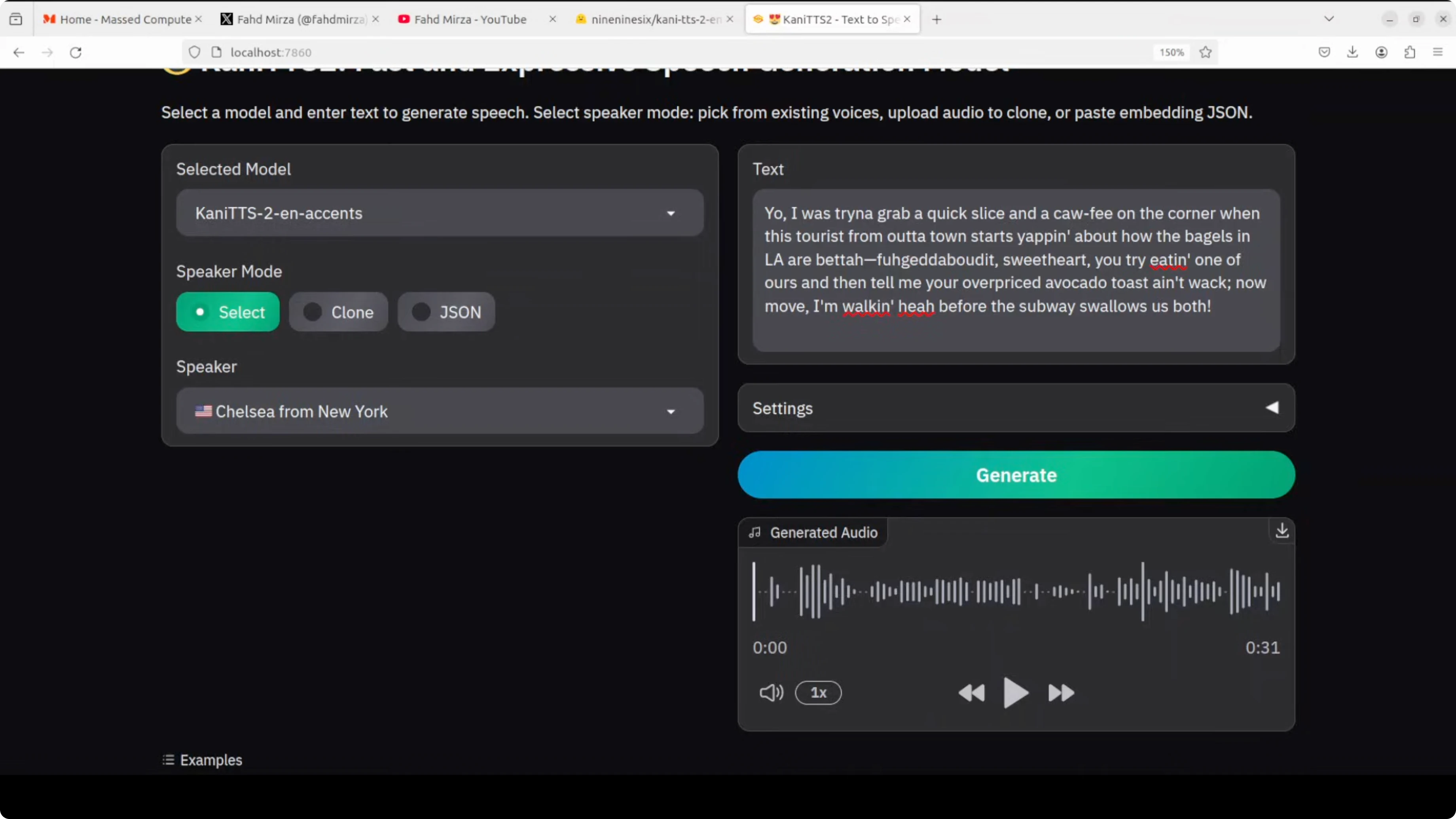
"Yo, I was trying to grab a quick slice and a coffee on the corner when this tourist from out of town starts yapping about how the bagels in LA are better. Eat it, sweetheart. You try eating one of ours and then tell me you’re overpriced. Avocado toast ain’t whack. Yo, move. I’m walking here. Before the subway swallows us."
Glasgow test
Then I tried Kum from Glasgow. I loaded up Glaswegian essentials like a casual greeting, intensifiers, football rivalry, a classic dismissal, and that signature cheeky no holds bar local humor about drinking, football, and neighbors. This is great for highlighting the accent’s rhythm.
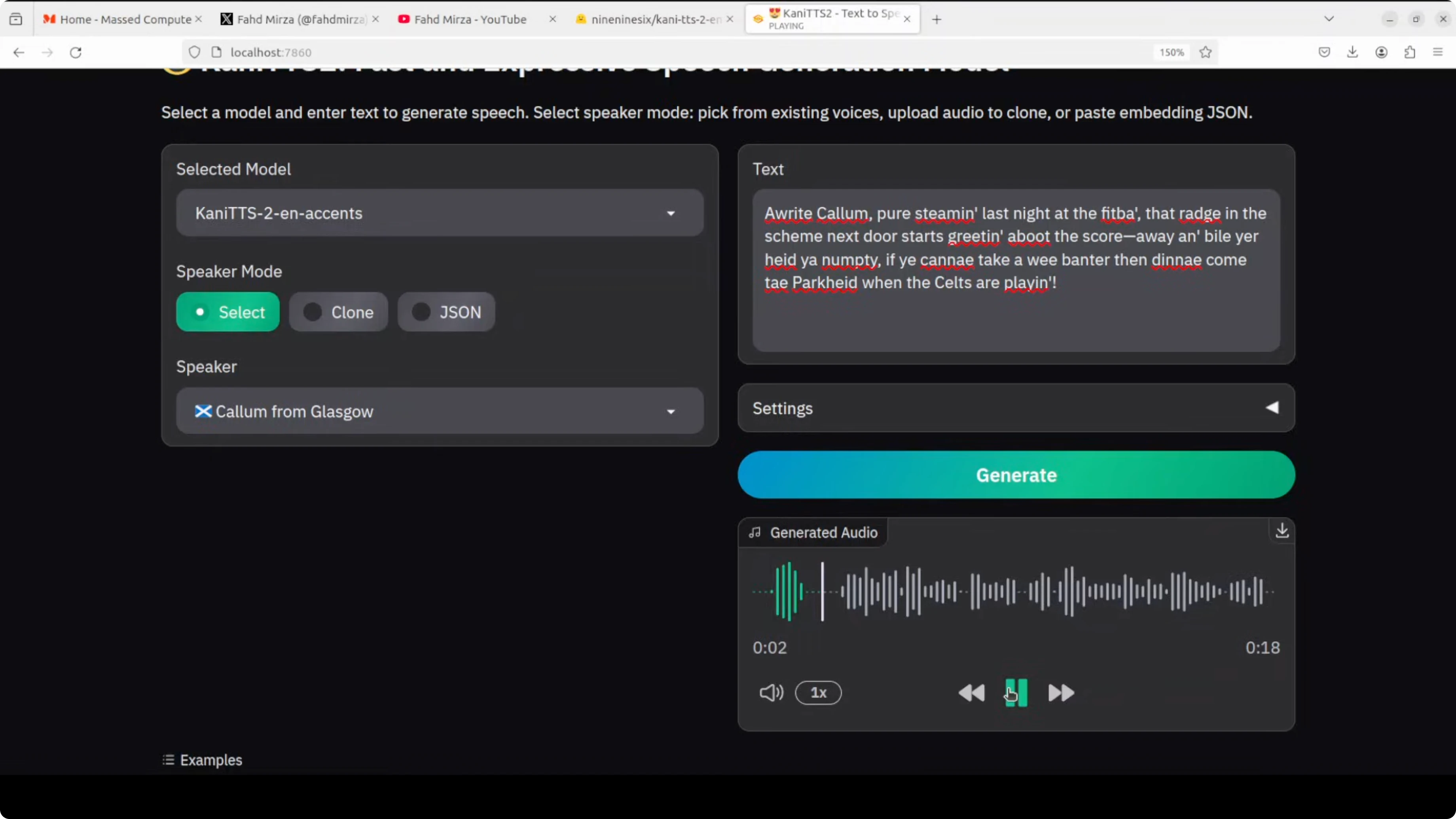
"All right, Callum pure steaming last night at the fit bet that Raj in the scheme next door starts screaming to boot the score away and by all year if you can take banter then D come to park when the cells are playing well yeah."
Voice cloning
I tried a quick cloning. I uploaded my own audio and extracted the embedding.
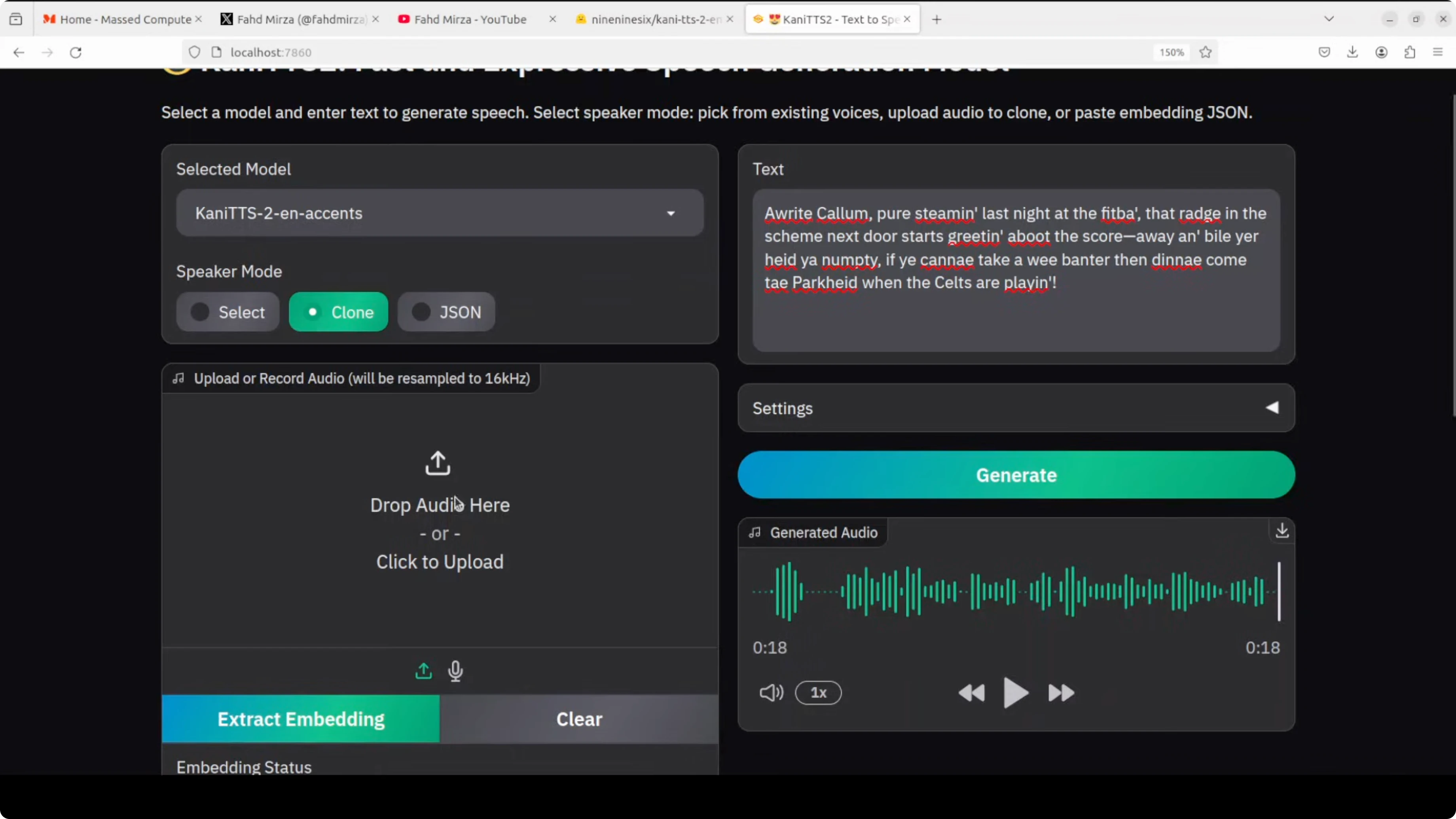
"Joy is found in simple moments of gratitude and true contentment comes when we truly value the small blessings we already have in life."
The toning is not good at all, and that was the same case in the previous version. TTS is fine and accents and dialects are fine, but cloning is not.
JSON embeddings
I pasted a 128 dimensional speaker embedding vector in JSON mode. It represents voice characteristics like timbre and accent style and conditions the model on a specific voice profile.
The goal was to have the model use that embedding plus the entered text to synthesize expressive speech that mimics the intended speaker’s accent and dialect traits. We designed a custom voice with these embeddings. That worked, but cloning quality remains the weak spot.
Specs and training
This model is Apache 2 licensed. It has achieved an RTF of around 0.2 on high-end GPUs like the Nvidia RTX 5080 and uses less than 3 GB of VRAM as observed.
It focuses heavily on capturing diverse accents and dialects with greater naturalness and fidelity in English speech. It uses a two-stage pipeline where a backbone LLM derived from Liquid AI’s LFM2 350 million model generates semantic and acoustic tokens. It is paired with Nvidia’s efficient nano codec for high quality 22 kHz audio synthesis and it was trained for around 10,000 hours of data in just 6 hours.
Final thoughts
Kani TTS 2 pushes forward on accents and dialects with strong results across locations like Boston, New York, and Glasgow. Latency and resource usage are attractive for realtime assistants, and the Apache 2 license is a plus. Cloning still needs significant improvement.
Subscribe to our newsletter
Get the latest updates and articles directly in your inbox.

Related Posts

8 Best Claude Code Plugins in 2026 (You Need to Know)
8 Best Claude Code Plugins in 2026 (You Need to Know)

7 Best Claude Code Skills (You Need to Know)
7 Best Claude Code Skills (You Need to Know)

Claude Code Desktop IDE Features (You Need to Know)
Claude Code Desktop IDE Features (You Need to Know)