

Microsoft’s Harrier: The Untapped Multilingual Model
Microsoft has just released something very interesting. They called it Harrier, named after a bird of prey known for hovering and precision, fitting for a model built around precise semantic understanding. It is a family of three multilingual text embedding models.
The key engineering decision here is that they used a decoder-only architecture, the same architecture family as GPT and LLaMA, rather than traditional encoder-only BERT-style models that have dominated embeddings for years. Not only will I install it and test it out, I am also going to unpack the differences between these three models. I will also share where each one fits best in production.
What Microsoft’s Harrier: The Untapped Multilingual Model does
It takes any piece of text, which could be a sentence, a paragraph, or a document, and compresses it into a single dense vector of numbers. That vector captures the meaning of the text. Once you have that you can do retrieval in RAG, semantic search, clustering, classification, similarity comparison, and reranking by comparing vectors mathematically.Microsoft has shown results on MTEB, the Massive Text Embedding Benchmark. This model has performed very well and Microsoft is claiming state-of-the-art on that leaderboard. It is evaluated across dozens of tasks and languages.
If you are building multilingual applications, also see our take on cross-lingual chat systems in this multilingual guide.
To feed clean text into embeddings from scans or PDFs, pairing Harrier with a reliable OCR step helps. For that upstream stage, see our notes on choosing an OCR engine in this OCR model overview.
Install Microsoft’s Harrier: The Untapped Multilingual Model
I am using Ubuntu on an Nvidia RTX 6000 with 48 GB of VRAM. I am going with the 27 billion parameter model, and the model size on disk is close to 40 GB. Make sure you have enough free space and a compatible CUDA setup.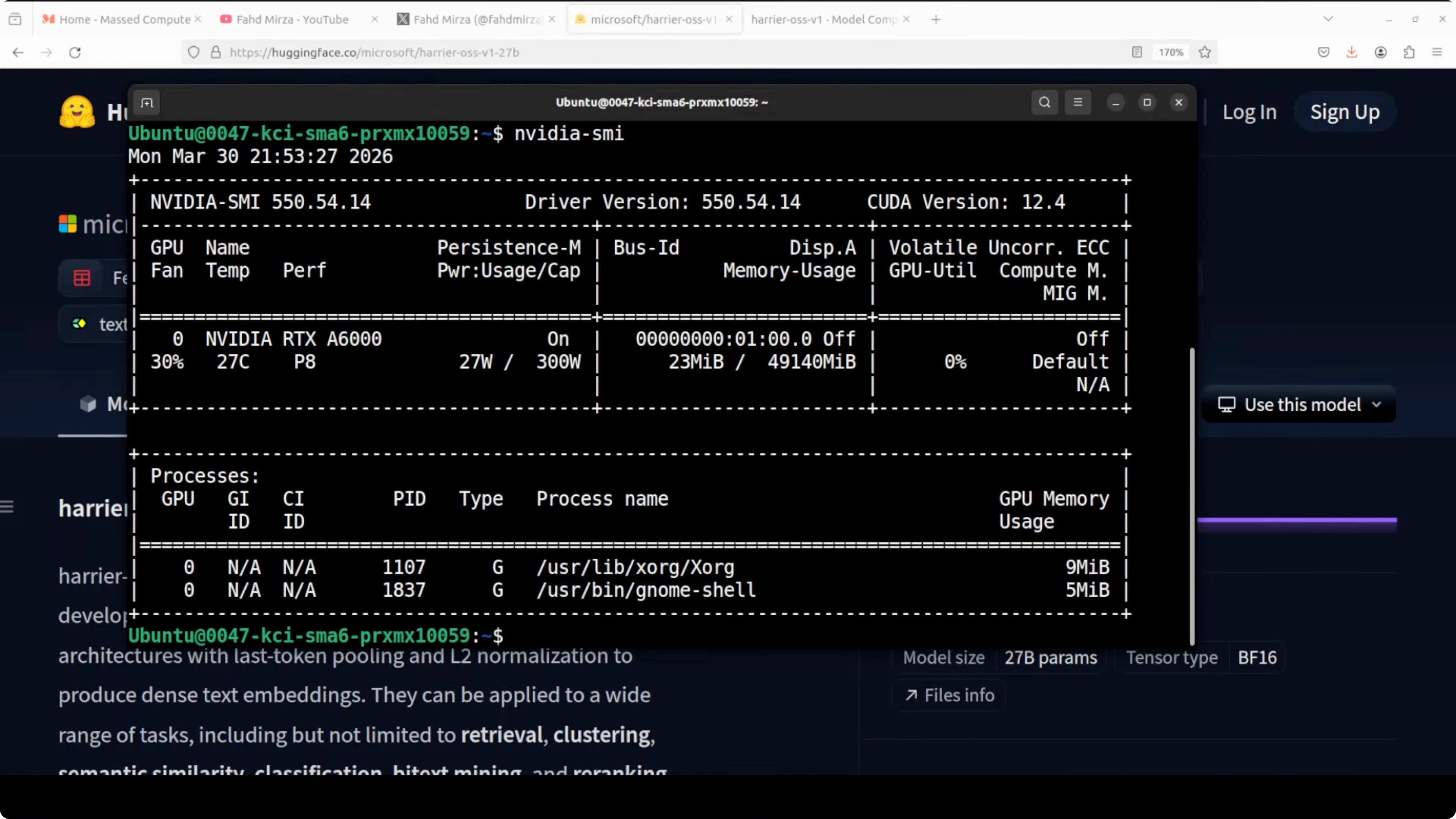
Prerequisites for Microsoft’s Harrier: The Untapped Multilingual Model
Create a fresh environment.conda create -n harrier python=3.10 -y
conda activate harrier
Install PyTorch with CUDA and core libraries.
pip install --upgrade pip
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121
pip install transformers accelerate sentencepiece huggingface_hub bitsandbytes
Verify that your GPU is visible.
python -c "import torch; print(torch.cuda.is_available(), torch.cuda.get_device_name(0))"
Download Microsoft’s Harrier: The Untapped Multilingual Model
You can optionally download the weights locally. This keeps a cached copy for offline or repeat runs.python -c "from huggingface_hub import snapshot_download; snapshot_download(repo_id='microsoft/harrier-oss-v1-27b', local_dir='harrier-oss-v1-27b', local_dir_use_symlinks=False)"
Encode text with Microsoft’s Harrier: The Untapped Multilingual Model
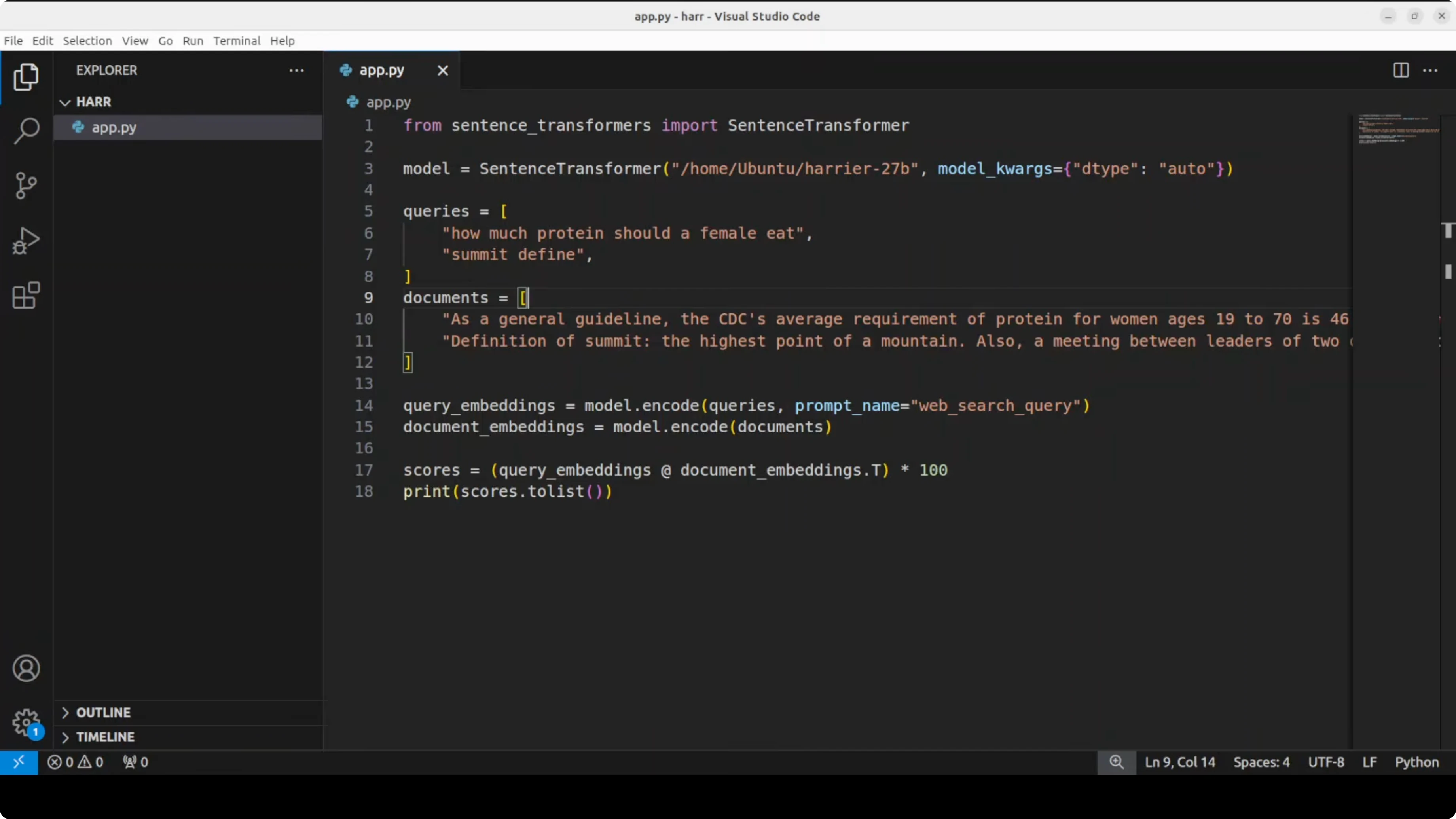
The example below encodes queries and documents, then scores them by dot product. It shows the basic pattern for retrieval and semantic search.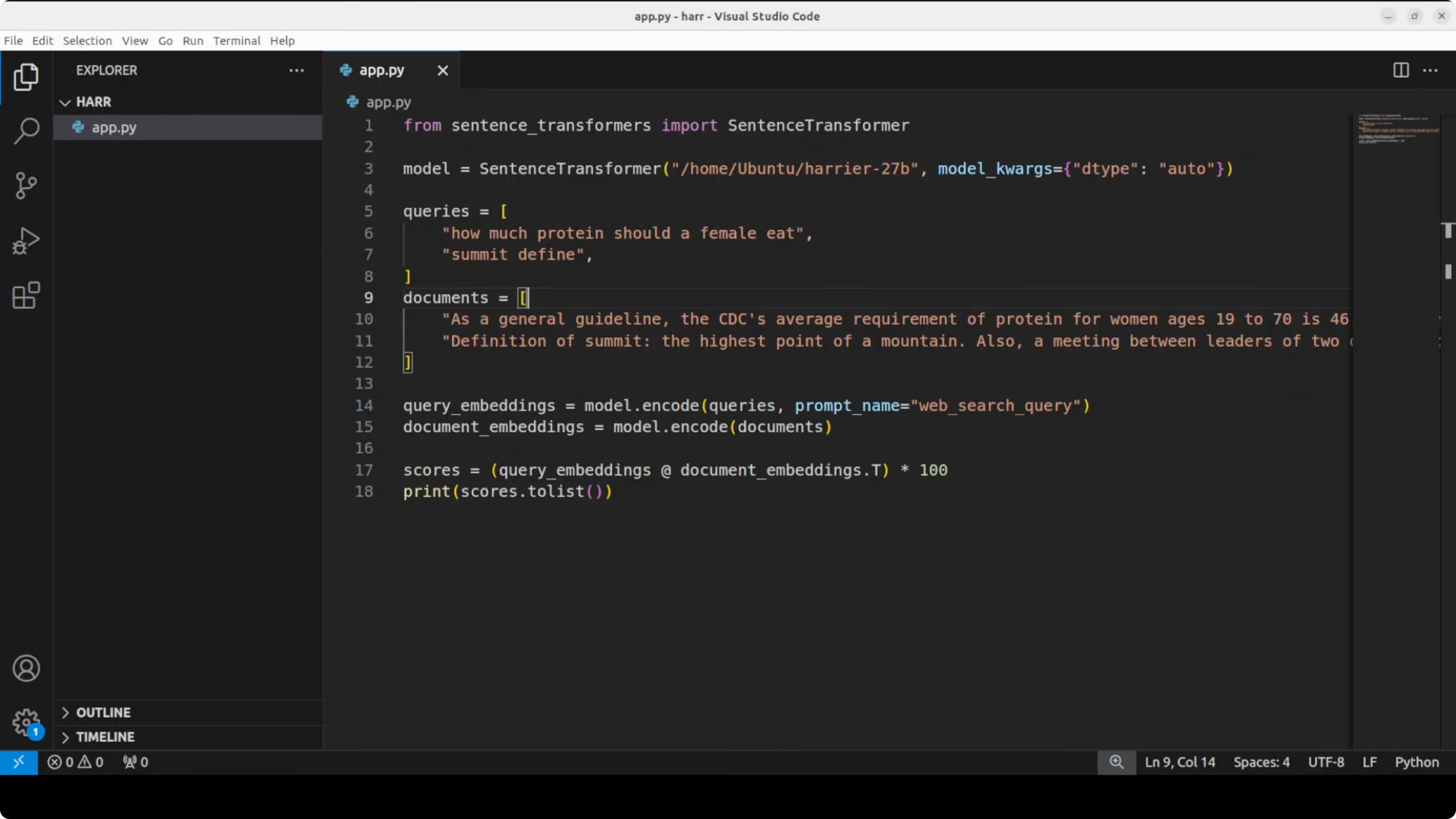
import torch
import torch.nn.functional as F
from transformers import AutoTokenizer, AutoModel
model_id = "microsoft/harrier-oss-v1-27b"
tokenizer = AutoTokenizer.from_pretrained(model_id, use_fast=True)
# For large models on 48 GB VRAM, prefer bfloat16 and device_map='auto'
model = AutoModel.from_pretrained(
model_id,
torch_dtype=torch.bfloat16,
device_map="auto"
)
def mean_pool(last_hidden_state, attention_mask):
mask = attention_mask.unsqueeze(-1).type_as(last_hidden_state)
masked = last_hidden_state * mask
summed = masked.sum(dim=1)
counts = mask.sum(dim=1).clamp(min=1e-9)
return summed / counts
def encode_texts(texts):
batch = tokenizer(
texts,
padding=True,
truncation=True,
max_length=32768,
return_tensors="pt"
)
for k in batch:
batch[k] = batch[k].to(model.device)
with torch.no_grad():
out = model(**batch)
emb = mean_pool(out.last_hidden_state, batch["attention_mask"])
emb = F.normalize(emb, p=2, dim=1)
return emb.float().cpu()
queries = [
"How much protein should a female eat?",
"Define summit"
]
docs = [
"As a general guideline, the average requirement of protein for women ages 19 to 70 is 46 g per day.",
"A summit is the highest point of a hill or mountain."
]
q_emb = encode_texts(queries)
d_emb = encode_texts(docs)
# Dot product similarity matrix: shape [num_queries, num_docs]
scores = q_emb @ d_emb.T
print(scores)If VRAM is tight, try 8-bit loading.
from transformers import AutoTokenizer, AutoModel
import torch
model = AutoModel.from_pretrained(
model_id,
load_in_8bit=True,
device_map="auto"
)Model sizes in Microsoft’s Harrier: The Untapped Multilingual Model
There are three flavors. The 270 million parameter model produces 640 dimensional embeddings and is suited for edge or CPU constrained deployments where speed matters more than accuracy. The 6 billion parameter model steps up to 1024 dimensions as a middle ground for production RAG pipelines, but it will feel underwhelming if you need peak quality.The 27 billion parameter model is in a completely different league. It outputs 5376 dimensional embeddings and reports an MTEB score around 74.3. All three share a generous 32k token context window.
When you plan for reliability in production, consider a fallback strategy so queries are never dropped. A simple approach is described in this fallback model pattern.
If you are balancing cost with a smaller general model in the stack, see the notes on a compact 7B class model here: Clara 7B model overview.
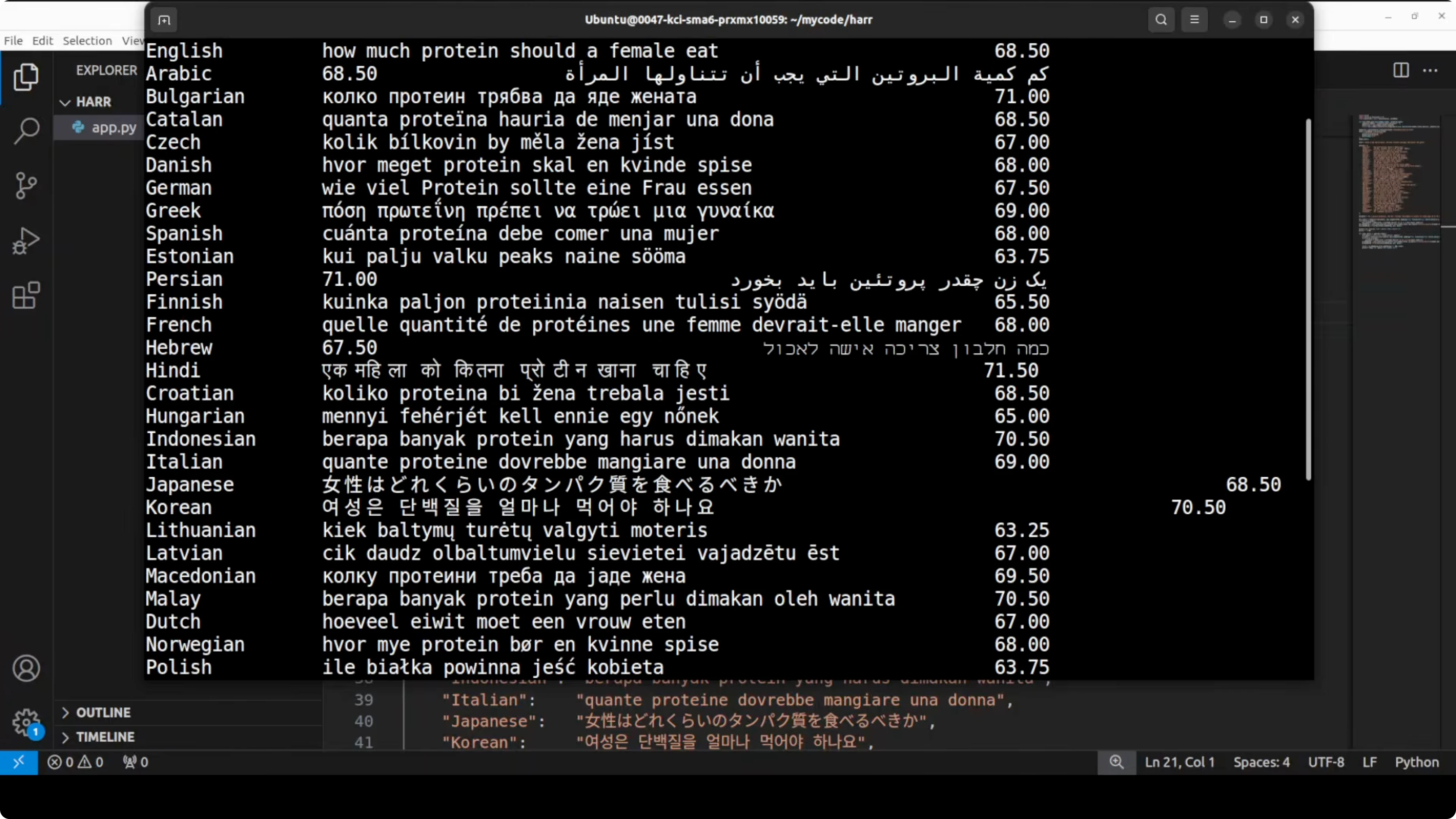
Multilingual support in Microsoft’s Harrier: The Untapped Multilingual Model
All three support 40 plus languages, including Arabic, Chinese, Vietnamese, and many European and Indo-Asian languages. The intent is that the same question, expressed in different languages, should map close to the correct English document in embedding space. Scores are very strong for most of these languages, with only a small dip for some low-resource ones like Estonian and Lithuanian.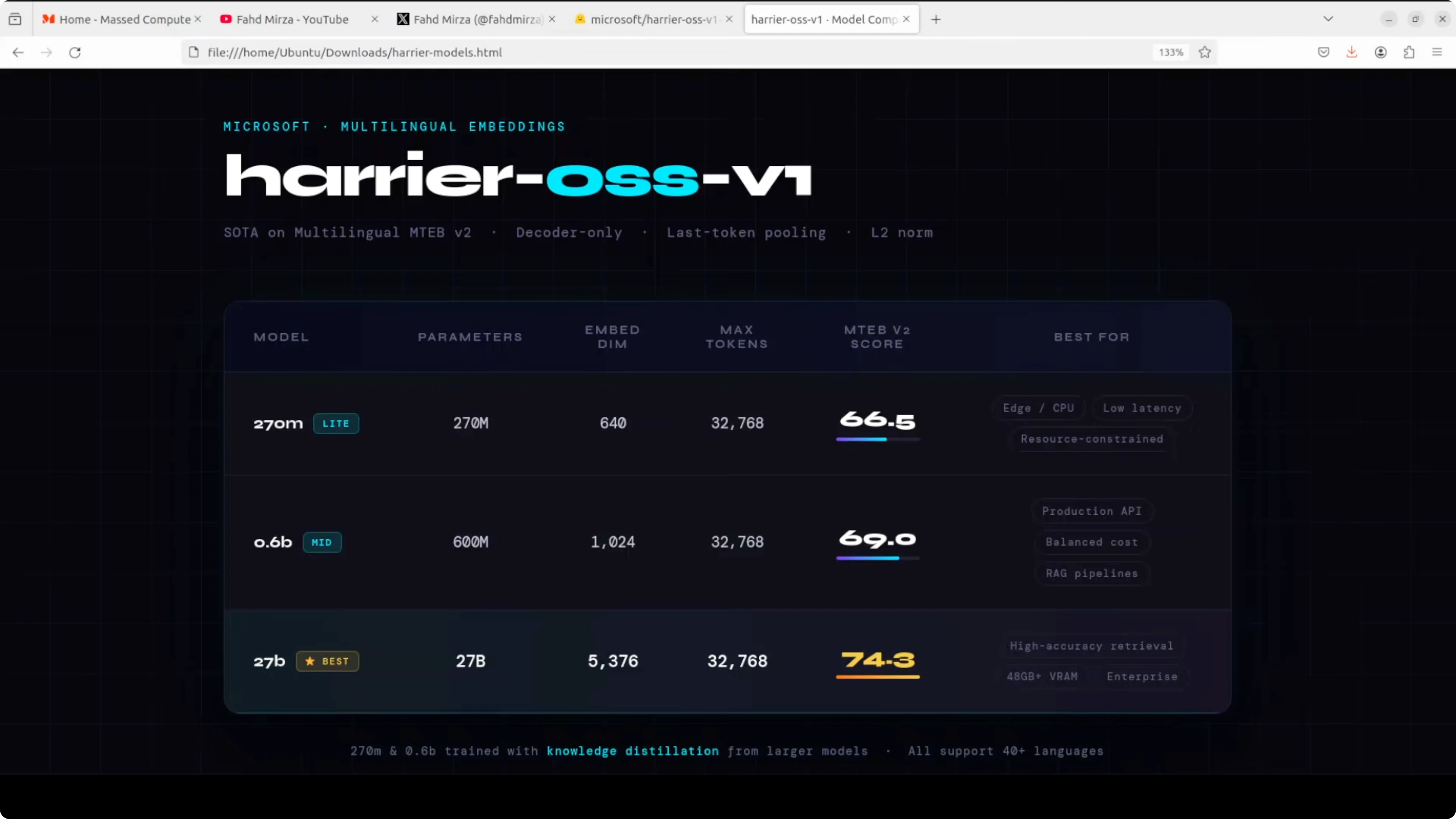
Coverage is heavily represented by European languages, with some Southeast Asian languages present. African languages felt sparse in the initial sweep, and it would be good to include more of them in future releases. Cross-lingual consistency remains the highlight.
Read More: Account Setup Login Model Disappear Error Antigravity
Resource notes for Microsoft’s Harrier: The Untapped Multilingual Model
The 27B model saturates a large portion of a 48 GB GPU during inference. Expect high VRAM consumption and plan for memory efficient loading if needed. Keep around 40 GB of disk space for the local snapshot.Use cases for Microsoft’s Harrier: The Untapped Multilingual Model
Multilingual RAG where users ask in their native language and the system retrieves English or mixed-language sources. Enterprise semantic search that needs accurate intent matching across departments and countries. Content deduplication and clustering at scale with consistent embeddings across languages.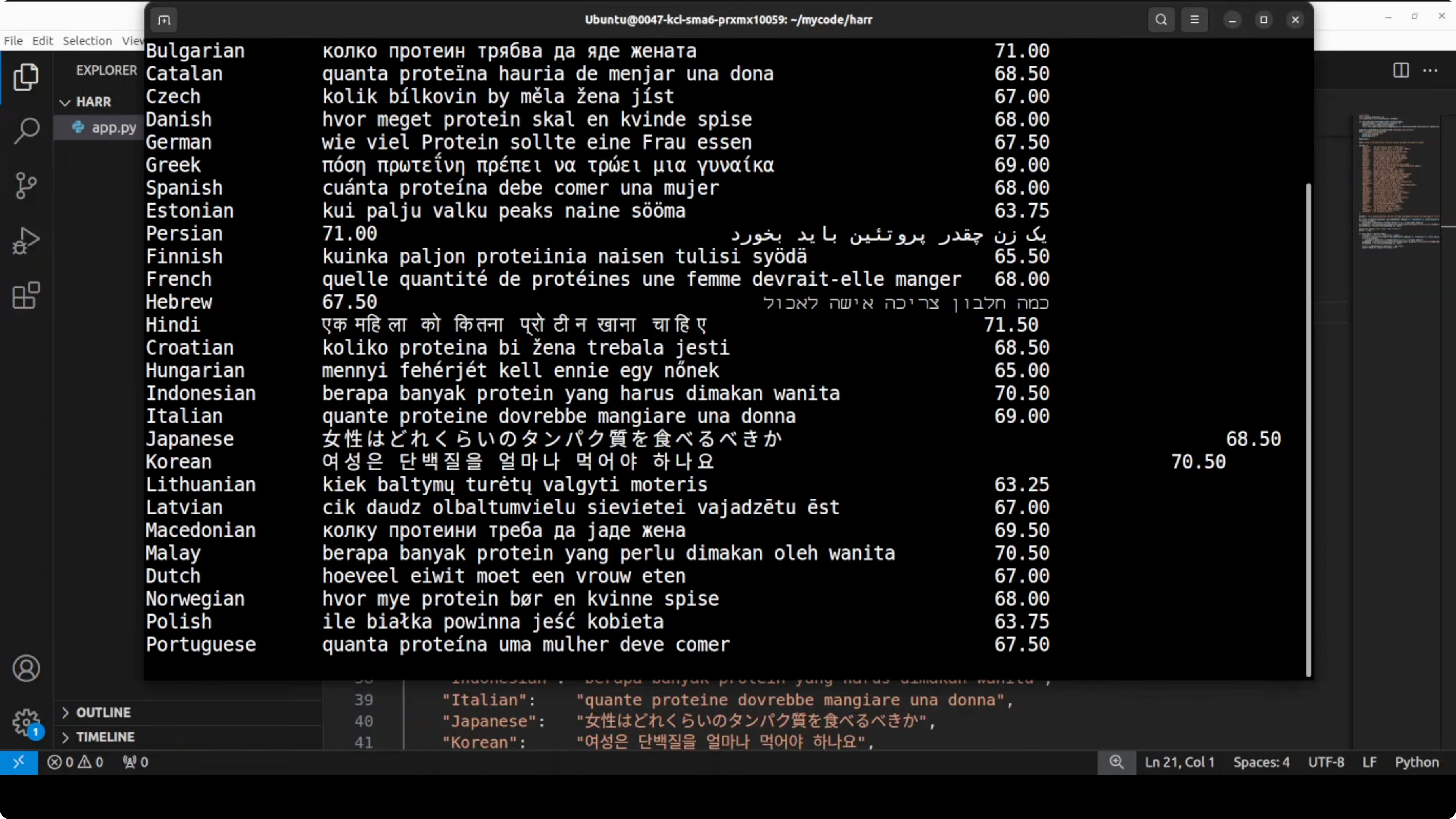
Cross-lingual classification and tagging where label space stays stable but the input language varies. Reranking for retrieval pipelines when you need robust final ordering on tough queries. Similarity-based routing that picks the right tool or knowledge base by comparing query vectors to capability centroids.
Final thoughts on Microsoft’s Harrier: The Untapped Multilingual Model
Harrier shifts embeddings to a decoder-only approach and delivers strong quality on MTEB. The 27B variant stands out for accuracy, while the 270M and 6B cover speed and cost-sensitive scenarios. With support for 40 plus languages and a 32k context window, it is a strong fit for multilingual RAG, search, and clustering at production scale.Subscribe to our newsletter
Get the latest updates and articles directly in your inbox.

Related Posts

8 Best Claude Code Plugins in 2026 (You Need to Know)
8 Best Claude Code Plugins in 2026 (You Need to Know)

7 Best Claude Code Skills (You Need to Know)
7 Best Claude Code Skills (You Need to Know)

Claude Code Desktop IDE Features (You Need to Know)
Claude Code Desktop IDE Features (You Need to Know)