
Memclawz: 3-Speed Memory for OpenClaw Agents
OpenClaw Error Fixer
Paste any OpenClaw error and get the exact fix instantly — cause, steps, copy-ready commands, and related guides.
The claw march continues and today I am covering an idea I consider one of the best startup or open-source contribution opportunities I have seen in the OpenClaw ecosystem in the last 24 hours. Things are changing fast and this gap is obvious once you notice it. First I will describe the problem, then the tool that points to the right solution.
The problem is that every AI assistant you have used shares the same flaw. They wake up every session with no memory of what they were doing before. You were mid-task yesterday, and today the agent has no idea any of that happened.
OpenClaw’s built-in memory search takes around 50 milliseconds and only does semantic search. It misses exact keyword matches, it does not auto-index new memory files, and your daily logs pile up forever with no compaction. Every session restart is a clean slate, which breaks the idea of a personal assistant that works for you continuously.
If your instance goes silent during a session, see not responding for quick fixes.
Why Memclawz: 3-Speed Memory for OpenClaw Agents matters
This is where I stumbled upon MemClawz, a community-built skill that tries to fix persistent memory for OpenClaw.
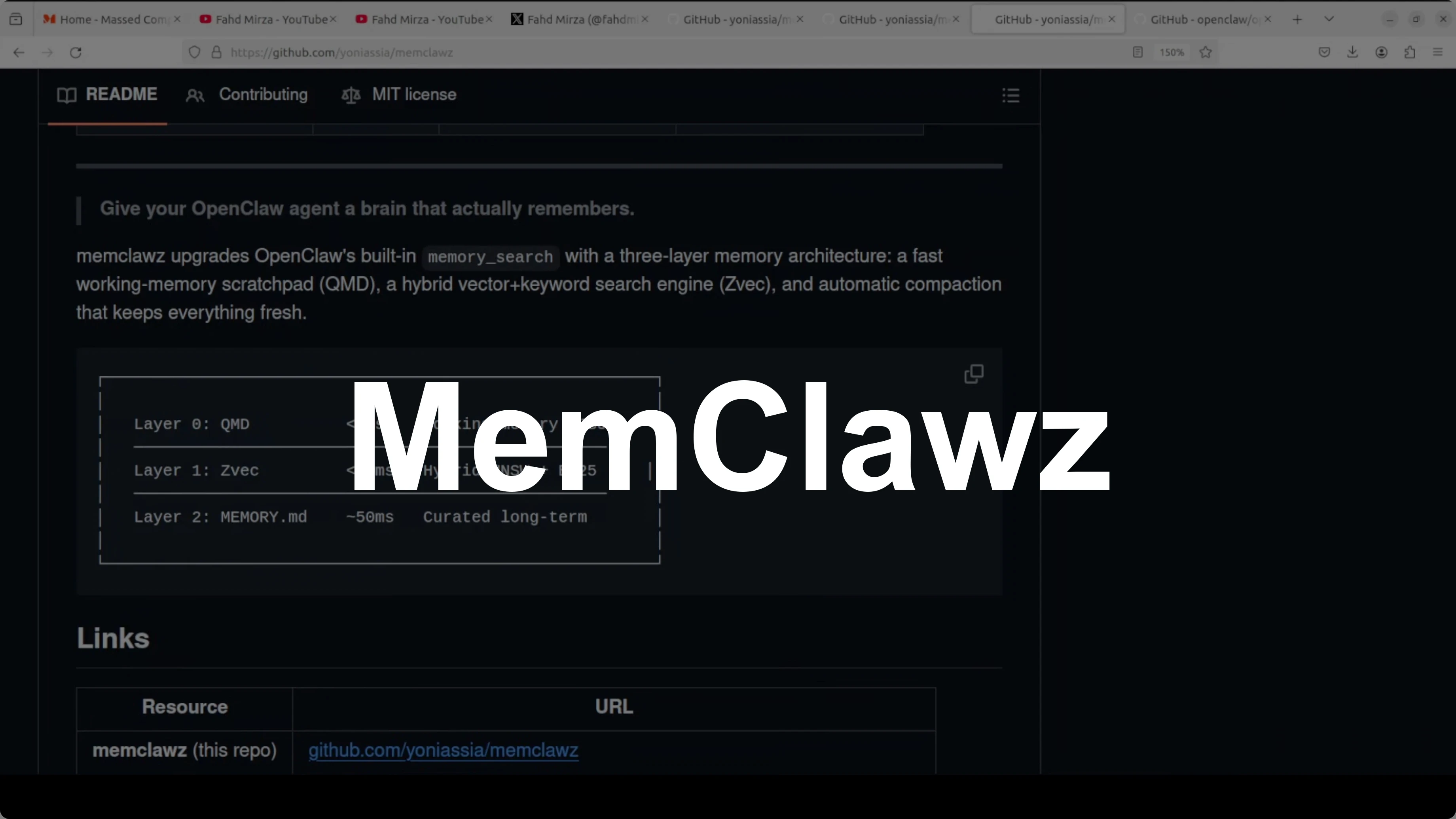
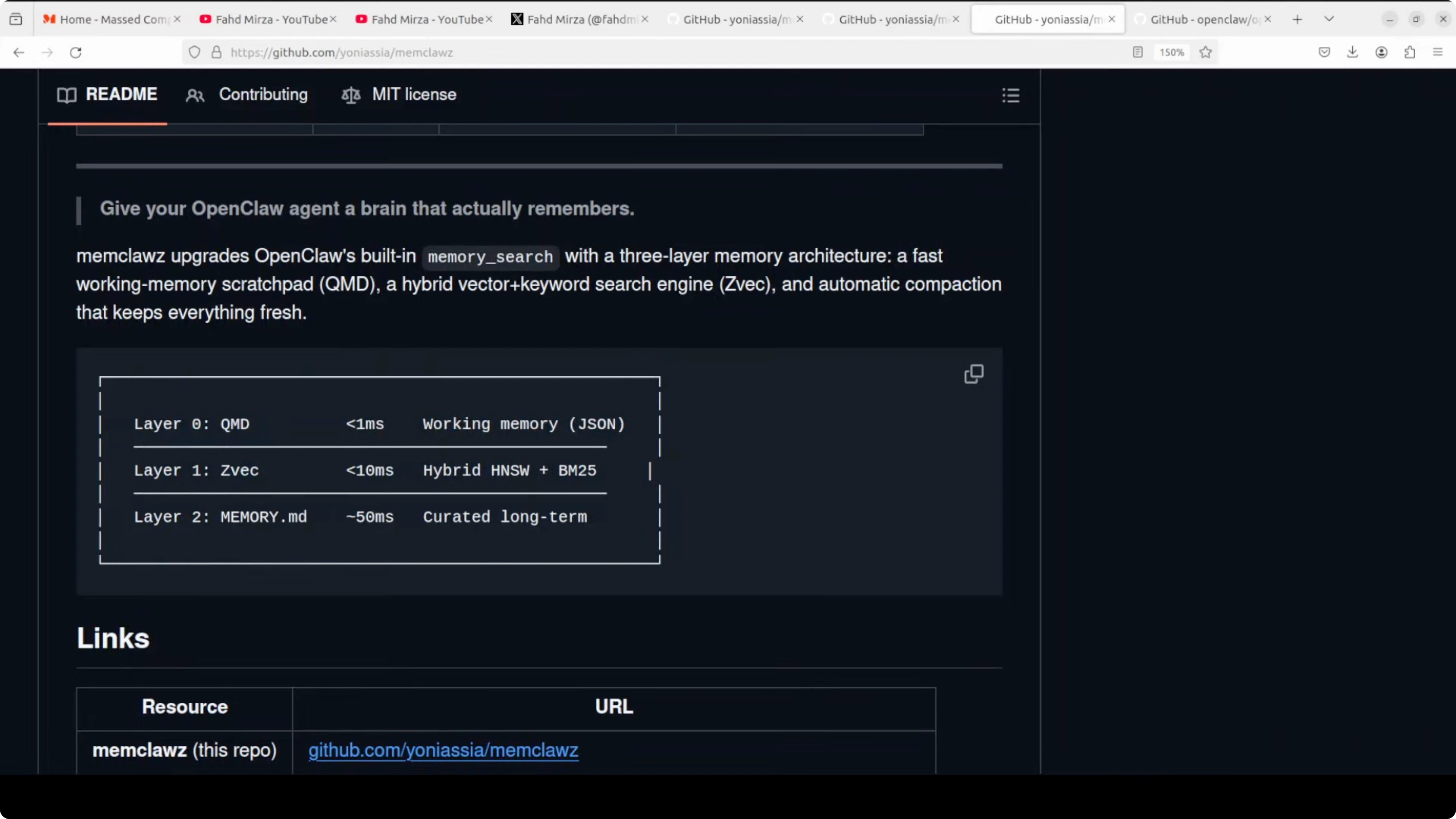
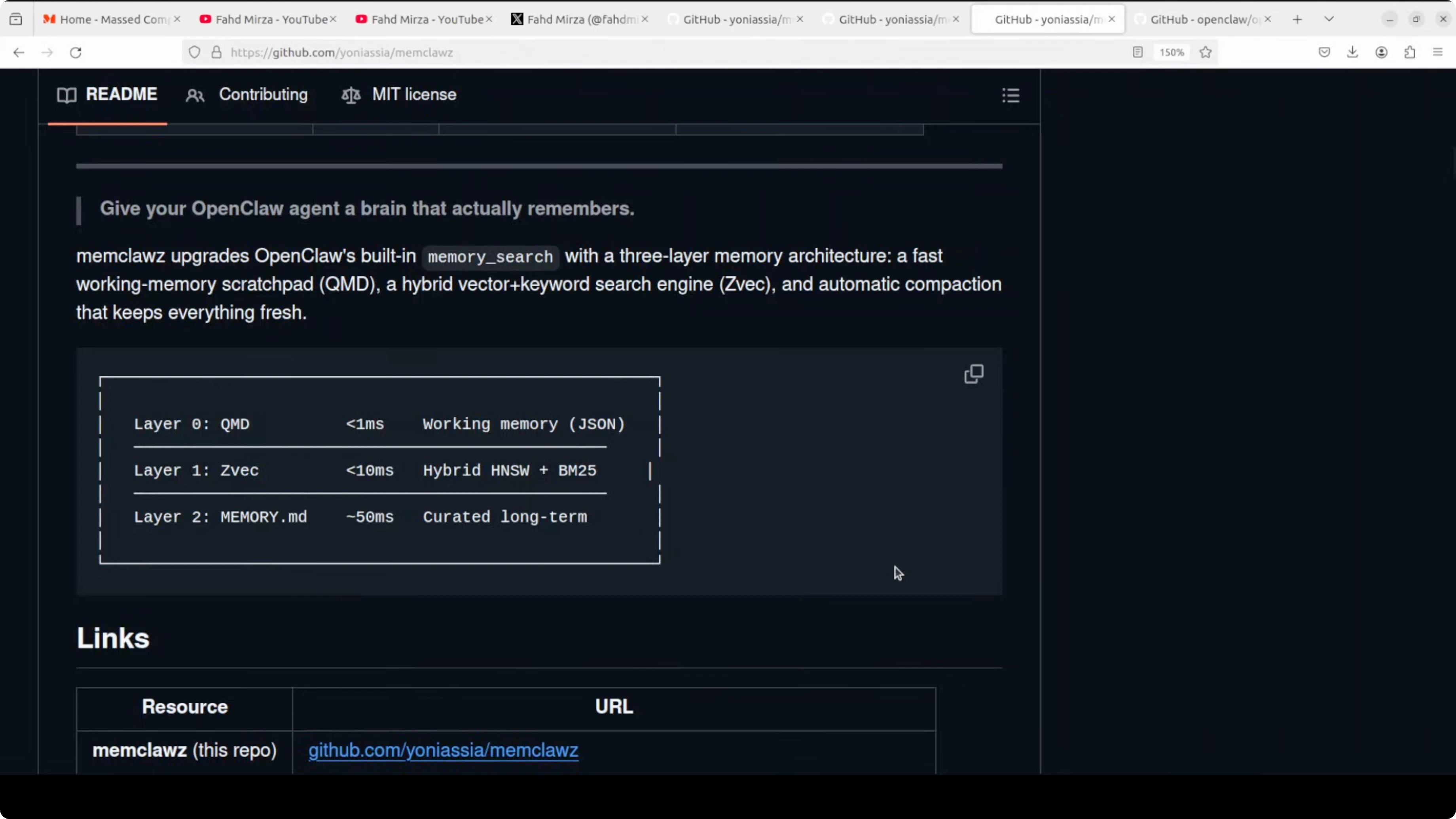
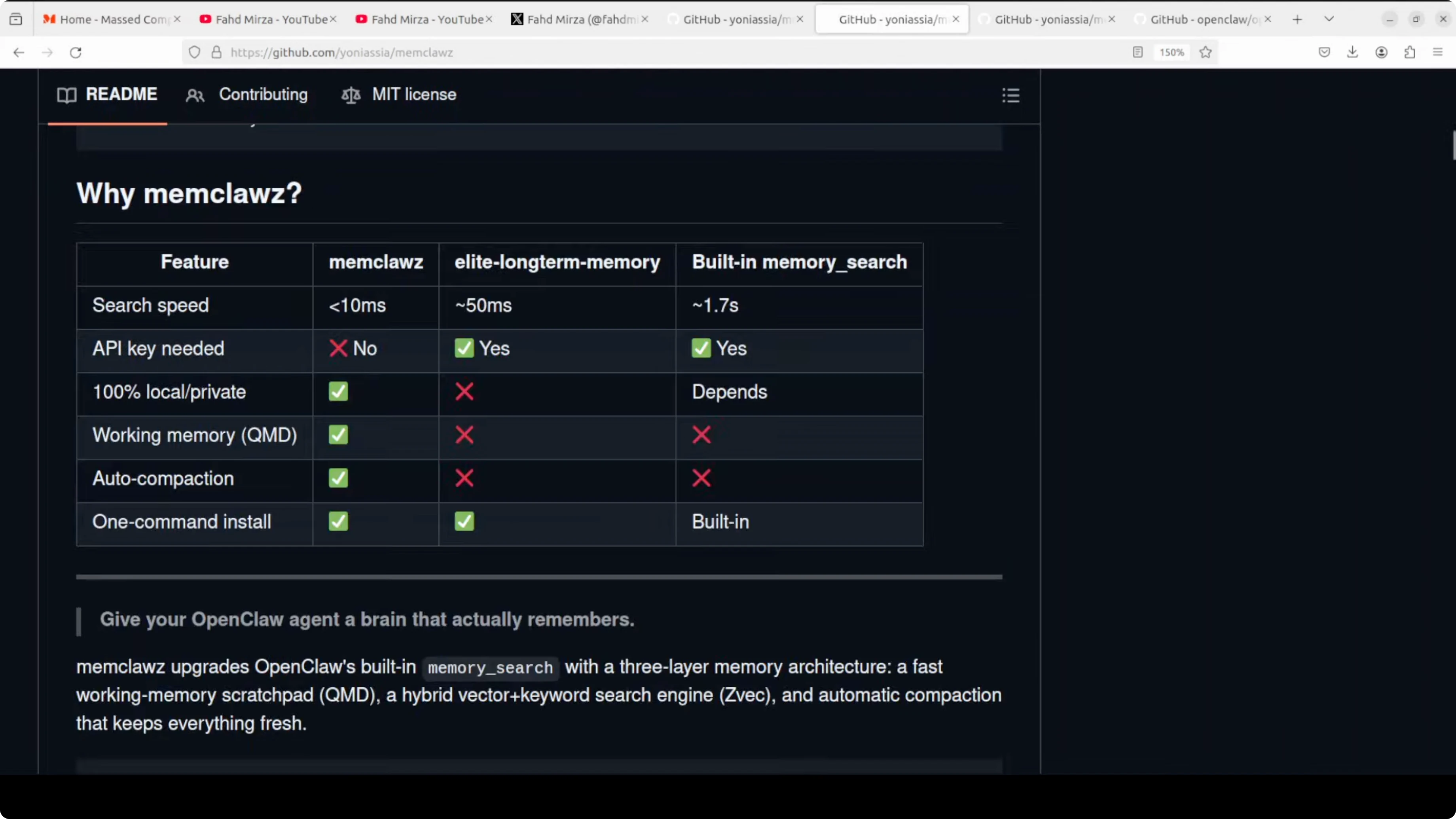
The architecture is clever and, conceptually, it is exactly what OpenClaw needs. It adds three layers on top of OpenClaw’s built-in memory, plus background maintenance.
Working memory in Memclawz
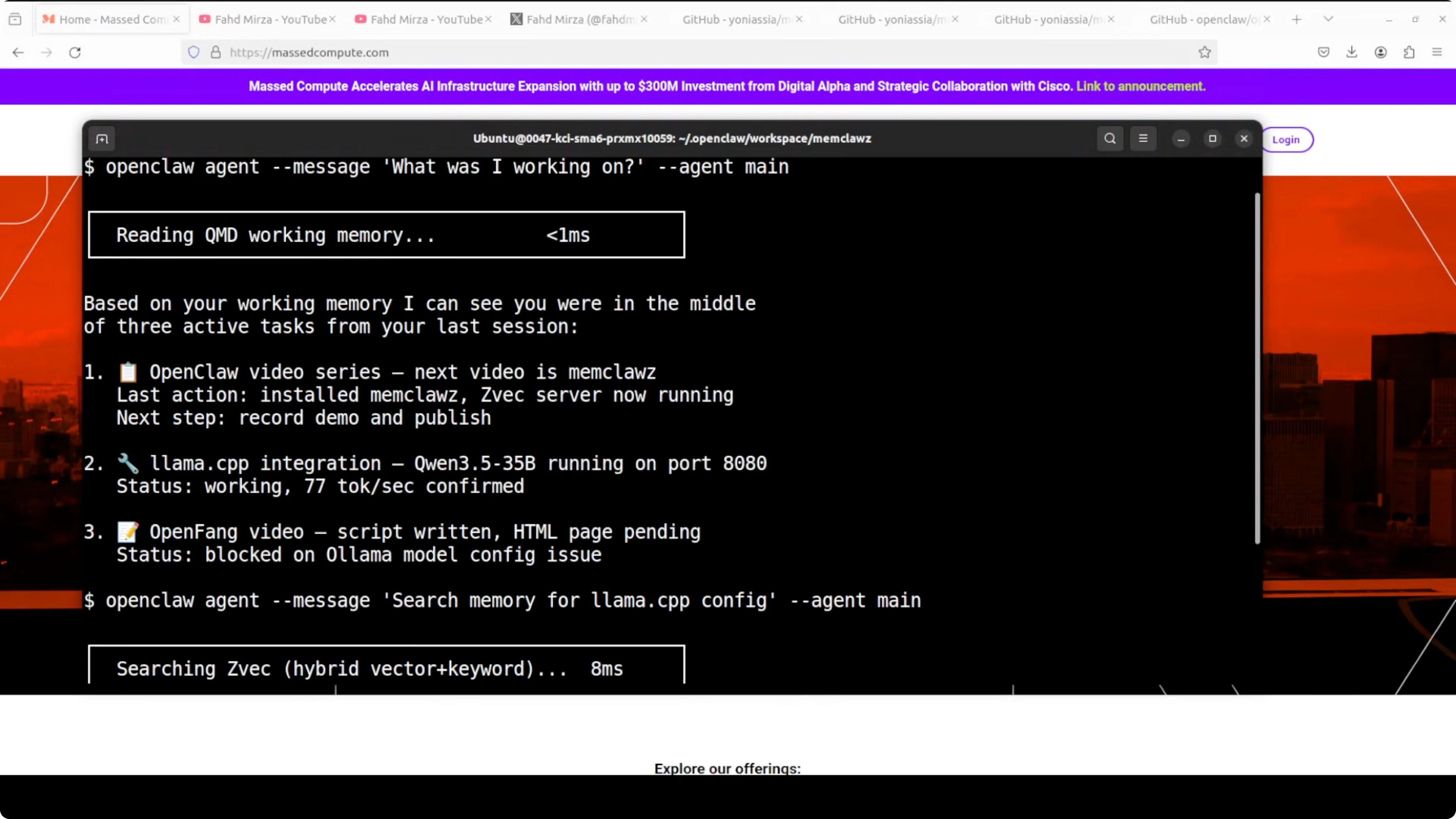
The first layer is a JSON scratchpad called current.json that survives session restarts and loads in under 1 millisecond.
Your agent wakes up, reads that file, and instantly knows what it was working on, what decisions were made, what tasks are active, and what the next steps are.
This turns restart from forgetful to instant context resume for the current workflow.
ZVec in Memclawz
The second layer is ZVec from Alibaba, a hybrid vector plus keyword search engine running locally, built on Alibaba’s Proxima search engine.
It searches all your memory files fast, combining semantic similarity and exact keyword matching. This closes the gap that pure semantic search leaves wide open.
Fallback in Memclawz
The third layer is OpenClaw’s existing memory search as a fallback.
On top of all that, there is an auto-indexing watcher that keeps the search index current within 60 seconds of new memory being written.
There is also an auto-compaction script that archives completed tasks to daily logs automatically.
The result is simple. Context resume after restart goes from broken to instant, search latency for working memory drops from 50 milliseconds to under 1 millisecond, and memory maintenance goes from manual to automatic.
That is exactly the behavior an assistant needs.
If you run into WebSocket closures during setup, see disconnected 1006 to diagnose it fast.
Caution on Memclawz:
My recommendation today is not to use MemClawz in production.
It is riddled with bugs, looks abandoned, and shows real hardware and operating system limitations.
The idea is right though, and OpenClaw needs a robust version of this.
If your automation stack throws a bot-related Node.js issue while testing memory skills, check Nodejs error for a targeted fix.
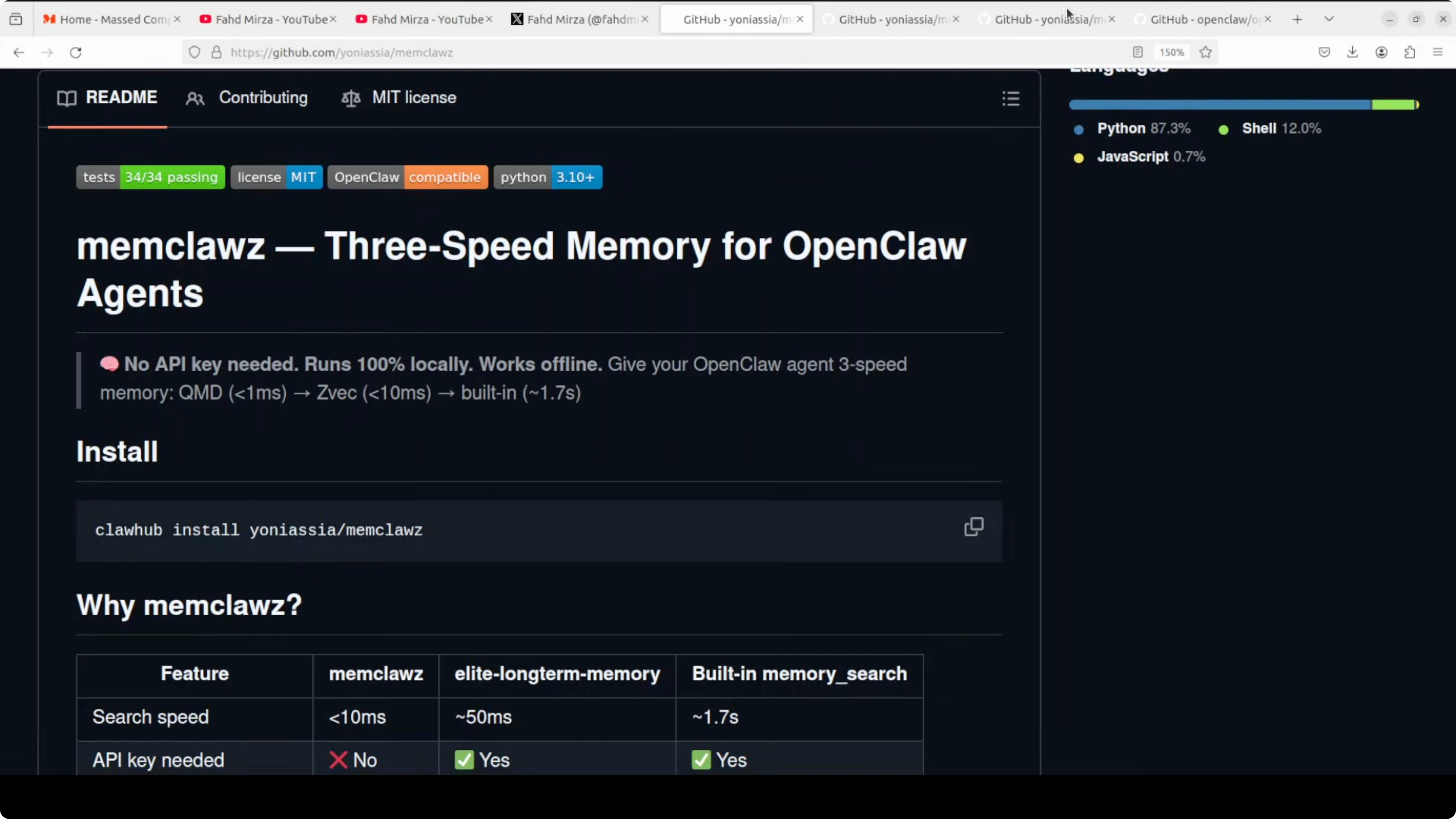
Setup for Memclawz
I tested on Ubuntu with an NVIDIA RTX 6000 48 GB VRAM using a local model. OpenClaw was already installed and running a Qwen model. Here is the flow I used.
Check that OpenClaw is installed and running:
openclaw status
Go to the OpenClaw workspace directory:
cd /path/to/openclaw/workspace
Clone the MemClawz repository:
git clone https://github.com/yoniassia/memclawz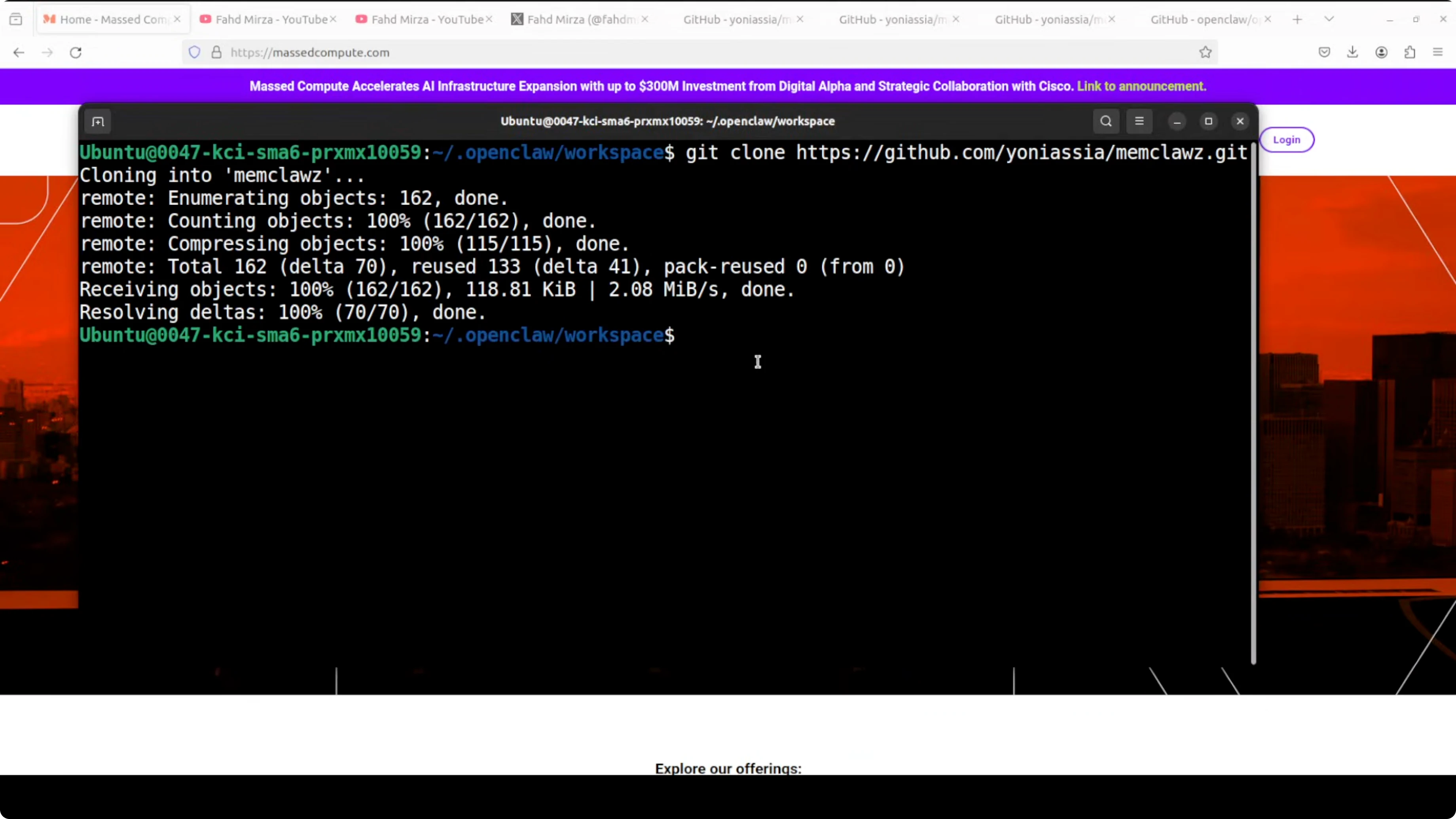
Enter the project directory and follow its first-run instructions:
cd memclawz
# run the project's init or first-run script per its README
You may see some errors and warnings during initial runs. Ignore them for now if the service proceeds and indexes memory, as this prototype is unstable. The core behavior to look for is persistent working memory on restart and sub-10 millisecond full-memory search.
Explore the code here: MemClawz on GitHub.
If you are evaluating model backends alongside OpenClaw, see Gemini 3 and 3.1 Pro for current capability notes.
Why build Memclawz
If you want a meaningful contribution or a startup idea in the OpenClaw ecosystem, build this memory layer properly. Build the working memory that survives restart, hybrid retrieval with both vector and keyword search, automatic compaction, and near-instant search on active context. Swap in any modern vector store as needed.
After working with OpenClaw and its variants, this problem is not a nice-to-have. It is the single biggest limitation of assistants running today. An agent that forgets everything after every session is just an expensive autocomplete.
The moment you solve persistent memory properly, you get fast retrieval, durable working memory, compaction, and hybrid search that compounds value over time. Every conversation makes it smarter about you. Every task it completes becomes context for the next one.
Final thoughts
Someone is going to build Memclawz: 3-Speed Memory for OpenClaw Agents properly for the ecosystem. It could be you, and it will matter immediately for anyone trying to rely on an assistant day to day. Fix memory, and you turn a tool people try into an assistant they trust.
Subscribe to our newsletter
Get the latest updates and articles directly in your inbox.

Related Posts

8 Best Claude Code Plugins in 2026 (You Need to Know)
8 Best Claude Code Plugins in 2026 (You Need to Know)

7 Best Claude Code Skills (You Need to Know)
7 Best Claude Code Skills (You Need to Know)

Claude Code Desktop IDE Features (You Need to Know)
Claude Code Desktop IDE Features (You Need to Know)