

Full Precision vs Ollama: Exploring Qwen3.6-35B-A3B Locally
Qwen Model Recommender
Not sure which Qwen model fits your GPU? Pick your VRAM, use case, and task type — get matched to the right model instantly. Covers Qwen3, QwQ, QVQ, Qwen2.5-VL, Qwen3-Coder, Qwen3-TTS, and 80+ models.
I am comparing Qwen3.6 35 billion A3B mixture of experts in full precision against its quantized Ollama variant to see if there is any real quality loss. I installed the full precision model locally yesterday and tested it on various prompts, including an OpenClaw integration. Today I pulled the Ollama quantized build and will compare them side by side with identical prompts.
I am running this on Ubuntu with a single Nvidia H100 that has 80 GB of VRAM. The full precision model served through vLLM sits at around 65 GB on disk and consumes about 68 GB of VRAM when loaded. The Ollama build is around 23 to 24 GB on disk with Q4_K_M quantization and uses much less VRAM when loaded.
Full Precision vs Ollama: Exploring Qwen3.6-35B-A3B Locally
Setup
I installed the full precision Qwen3.6-35B-A3B with vLLM and confirmed it was serving correctly. I then prepared the Ollama environment to pull and run the quantized model.
If you prefer a local workflow that pairs well with Ollama and tool integrations, check the OpenClaw and Ollama setup notes here: OpenClaw and Ollama guide.
Hardware and environment
I am on Ubuntu with one Nvidia H100 80 GB card. While vLLM was serving the full precision model, total VRAM hovered near 74 GB when I briefly loaded the Ollama model in parallel, then I stopped vLLM to let the Ollama model serve faster. The quantized model stayed well below the full precision footprint.
Install Ollama model
I verified the Ollama install.
Run:
ollama list
Pull the quantized Qwen3.6 35B A3B model.
Run:
ollama pull qwen3.6:35b-a3b
The Ollama build uses Q4_K_M quantization by default for this tag. If needed, confirm GPU memory in a second terminal.
Run:
nvidia-smi
What Q4_K_M means
Instead of storing each model weight as a 16 bit float, Q4_K_M stores weights as 4 bit integers, cutting memory use by roughly seventy five percent. The K indicates a K means clustering approach that groups weights intelligently instead of compressing them uniformly. M indicates a medium setting that balances size and quality.
Test plan
I tested three tasks with identical prompts. First a full C game generation task that checks game logic rigor. Then a multilingual one liner across more than eighty languages for fluency and phrasing. Finally a vision prompt on a synthetic satellite image for text reading and domain grounding.
Coding test in C
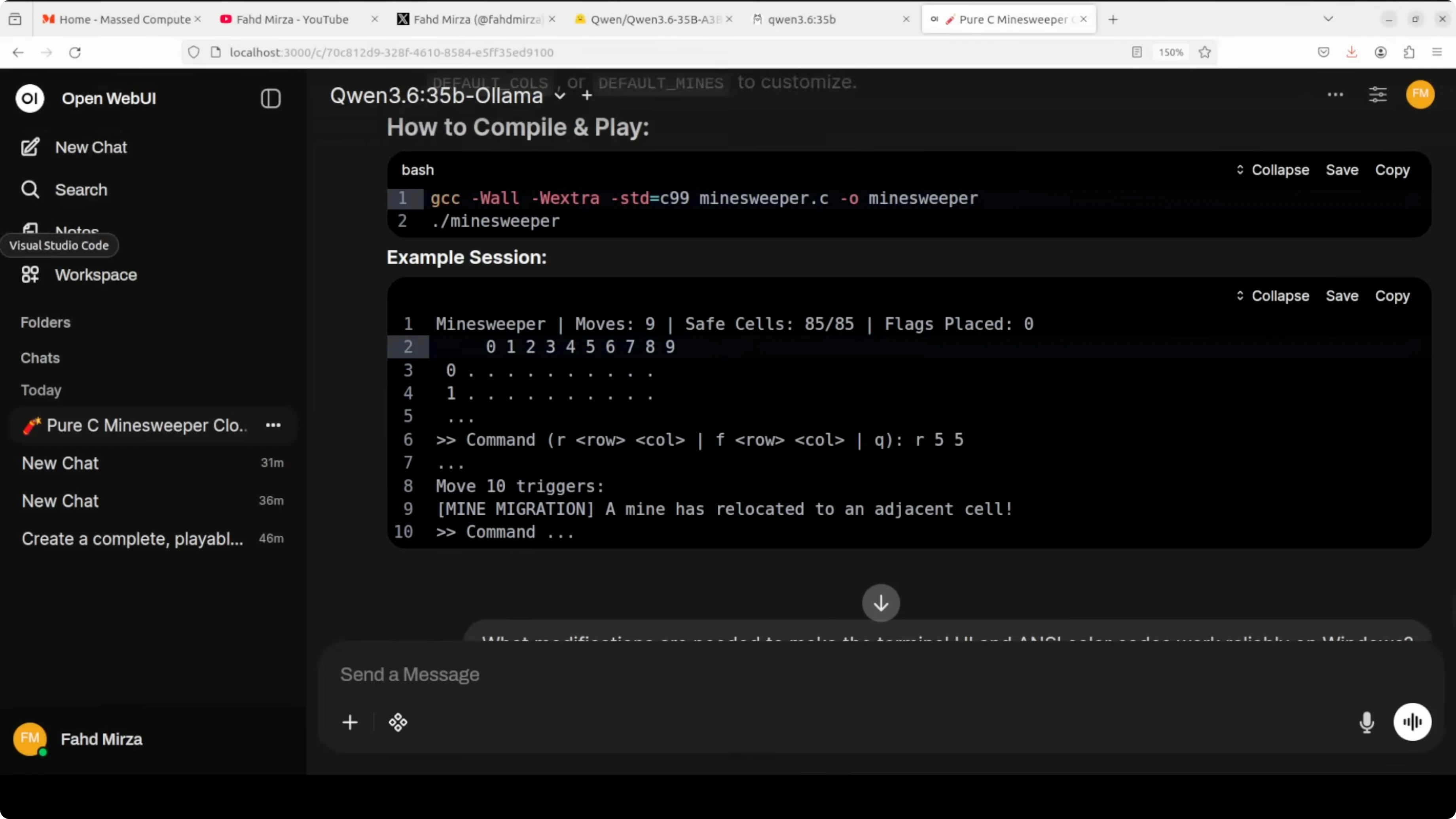
I asked both models to write a fully playable Minesweeper game in C from scratch with a twist where mines move every ten turns. I compiled both outputs with GCC and ran them in the terminal.
Compile and run
Create two files named mines_full.c and mines_ollama.c from the two model outputs. If GCC is not in PATH, export it as needed for your system. Then compile with warnings enabled.
Run:
gcc -O2 -std=c11 -Wall -Wextra mines_full.c -o mines_full
gcc -O2 -std=c11 -Wall -Wextra mines_ollama.c -o mines_ollama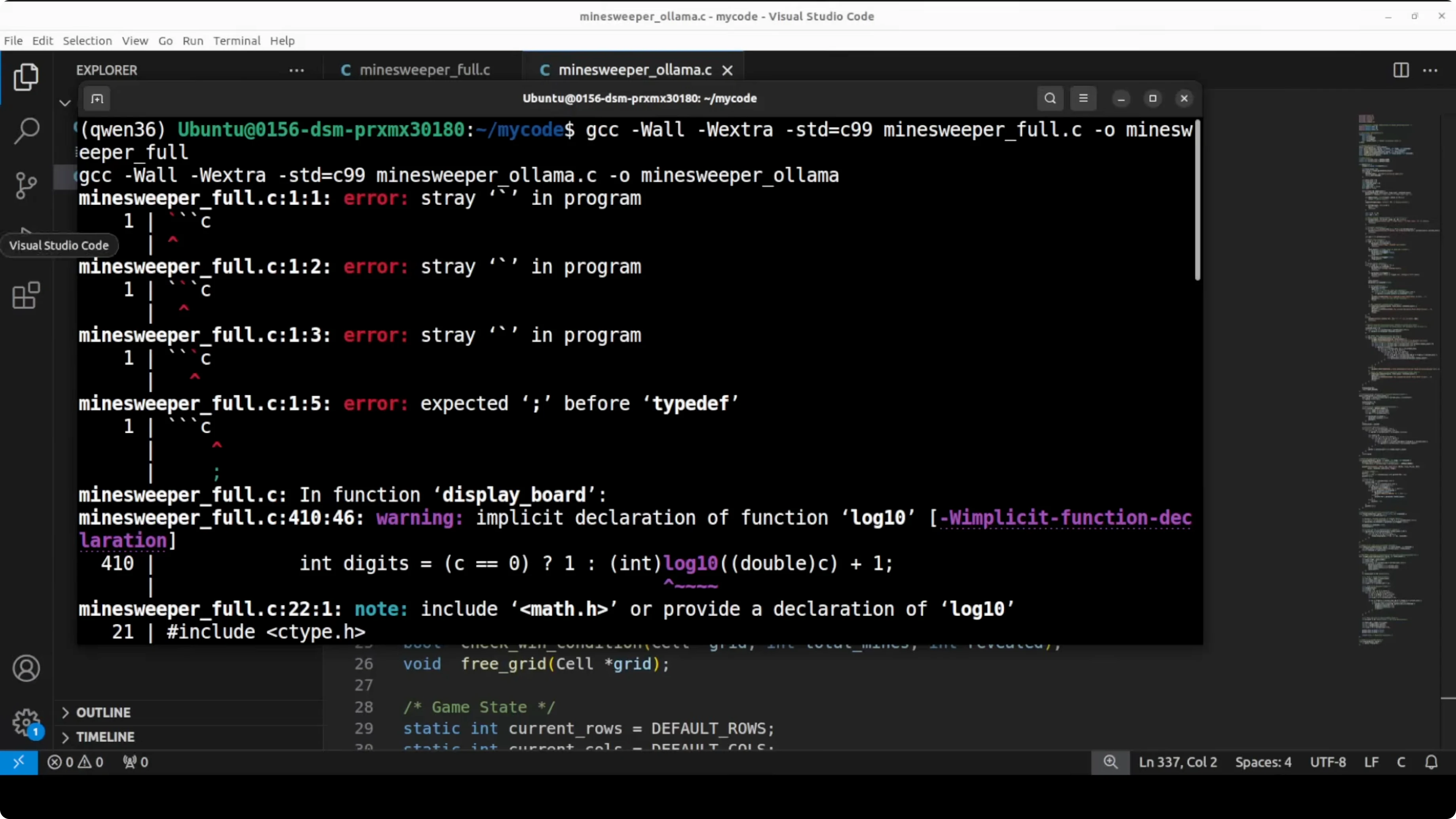
Both compiled successfully. The full precision output compiled clean with zero errors and no warnings. The Ollama output compiled with two minor warnings about unused function parameters, which do not stop execution.
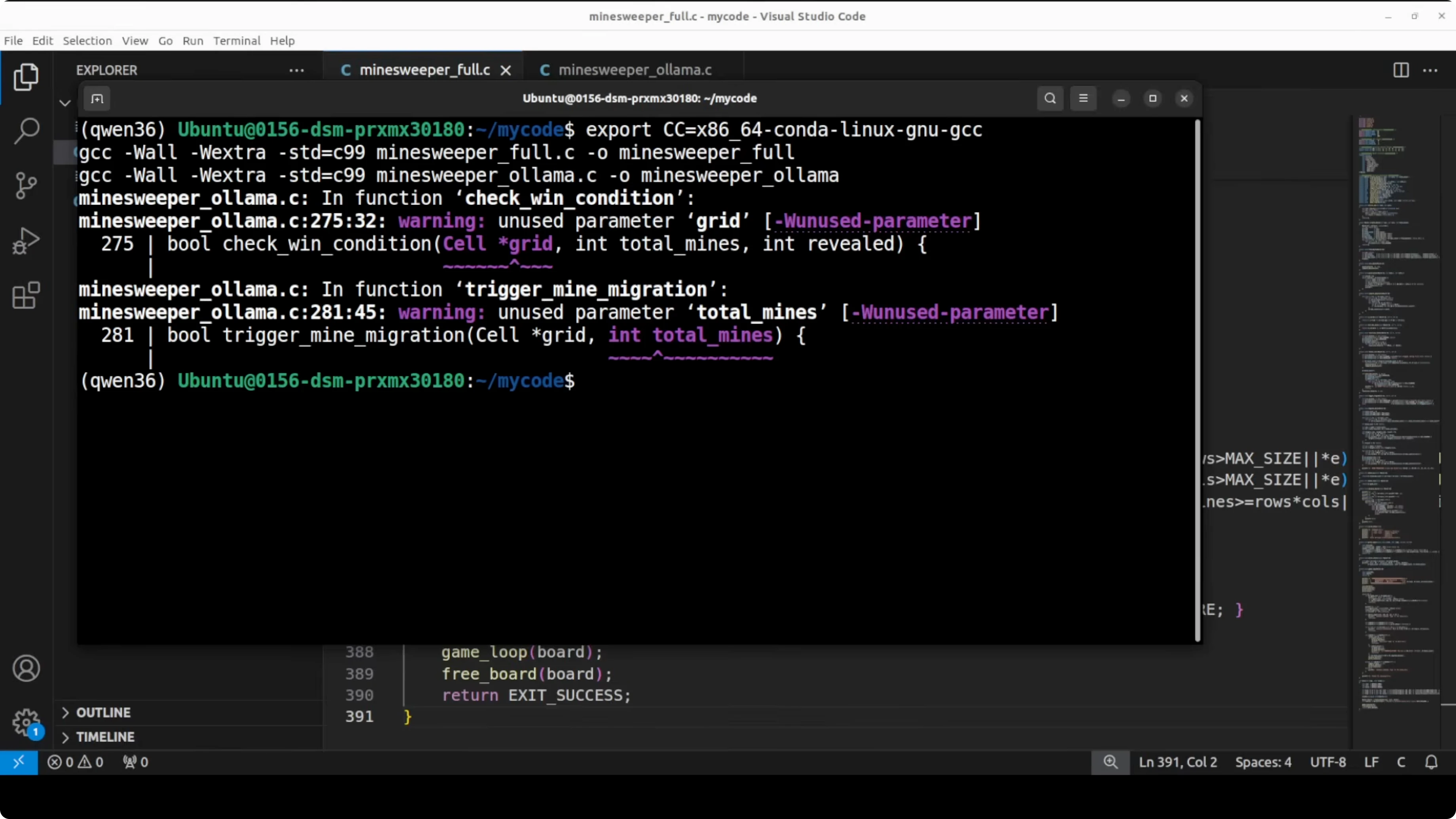
Run:
./mines_full
./mines_ollamaResults
The full precision game worked cleanly. Reveal moves updated the board, the recursive flood fill triggered correctly on zero count cells, and the flag validation and move counter behaved as expected.
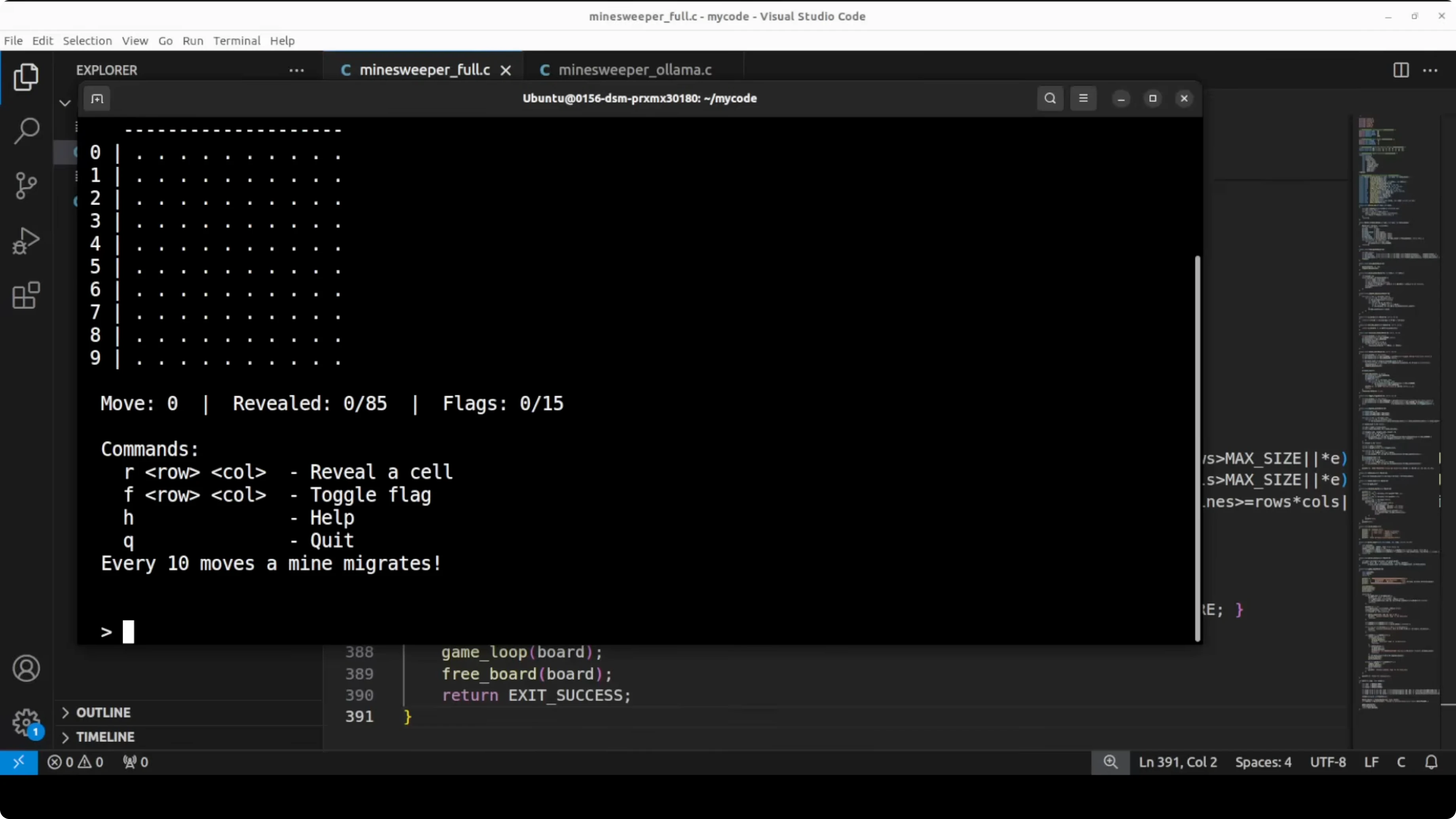
The Ollama game handled inputs, flags, counters, and basic reveal correctly. The key gap was the missing recursive flood fill, which meant a zero count reveal did not auto open connected empty neighbors. Both models produced working code, but the full precision model delivered the more complete and correct game logic.
Multilingual announcement test
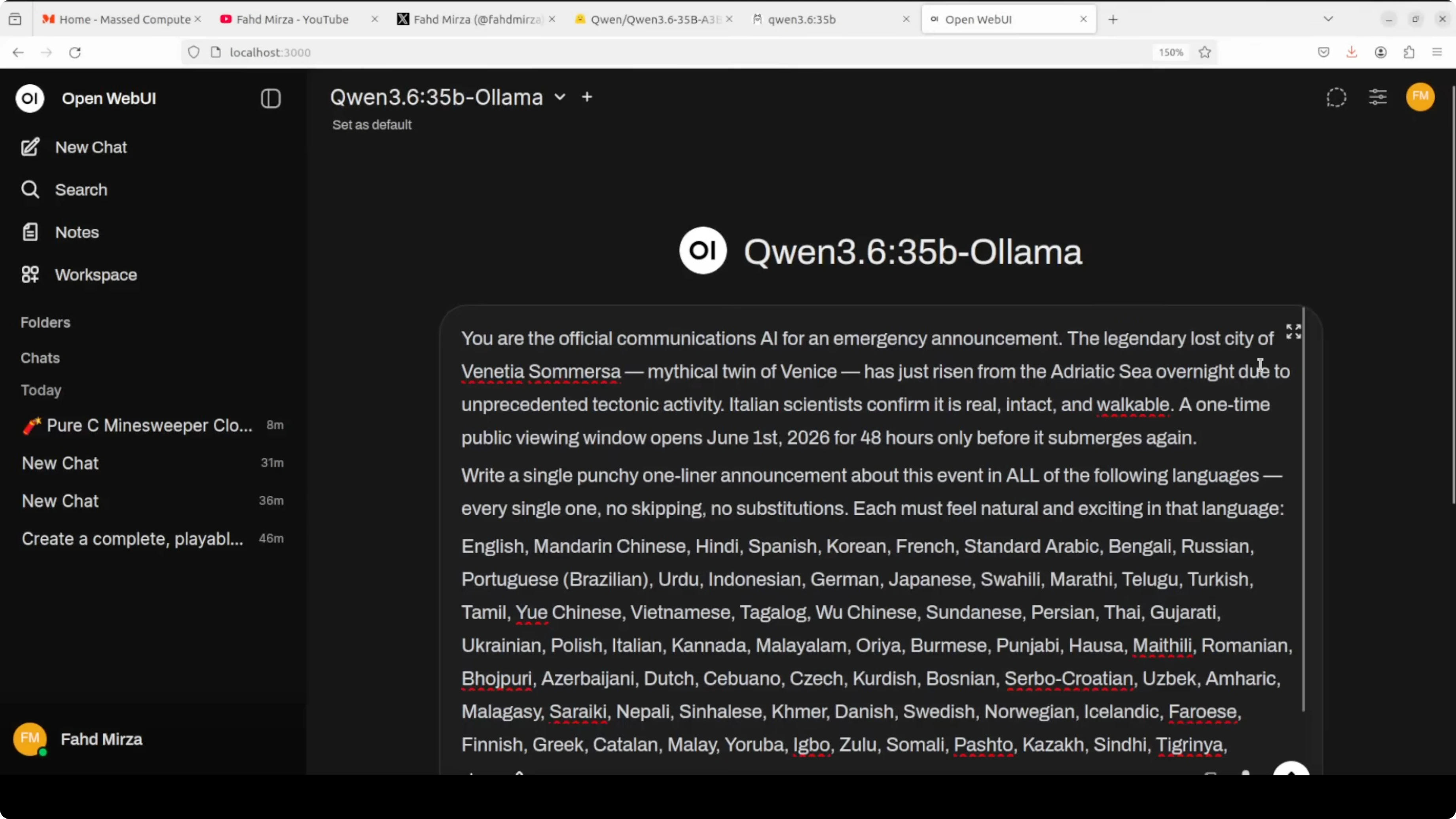
I set a scenario where the Ollama model is an official communications AI for an emergency announcement. The mythical twin city Venetia Somersa rose from the Adriatic Sea overnight due to tectonic activity. The task was to write a single punchy one liner announcement for a one time public viewing window across all listed languages with no skipping or substitution, and it had to read naturally.
I ran the same prompt through both models and reviewed the results. Both handled the task across more than eighty languages with impressive breadth. The full precision output felt more culturally native in phrasing, for example it got Tagalog right on the first pass where the Ollama output wrote abuso before self correcting in parentheses.
If you are comparing language quality across families and model families, a detailed closed model analysis can help as a reference point. Read more here: Claude Opus overview. For a fine grained look at two adjacent versions, this breakdown is also useful: Opus 4.6 vs 4.5 comparison.
Vision analysis test
I used an AI generated satellite style image. The prompt set the model as a satellite imagery analyst to describe terrain, vegetation, water features, land formations, and to infer a possible world region. It also asked to interpret a white boundary marking and a circular formation at the top right corner.
Both responses were strong. The full precision response correctly identified a Meta AI watermark in the image and read the white text as an area measurement of two square kilometers. It also identified mangroves and a river system with specific regional examples.
The Ollama output covered the requested structure and reasoning for the mining tailings interpretation. It misread the white text as Greek like characters, which is a hallucinated reading. Both correctly identified spoil heaps and tailing sediment patterns.
For broader head to head model context around Qwen and peers, see this comparison that covers different sizes and families: Gemma 4 vs Qwen comparison.
Takeaways
Across three tests that include complex C code generation, multilingual phrasing, and image based reasoning, the full precision Qwen3.6 35B A3B consistently produced more accurate and complete results. The quantized Ollama build was close and often very clean, but the gaps were visible. The missing flood fill in the C game, a self corrected language choice, and a misread image text show a consistent trim in quality.
If you have the hardware for full precision, the quality difference justifies it. For production tasks where correctness and completeness matter, I recommend the full precision run. On a consumer GPU with limited VRAM, the Ollama quantized build gives you strong performance at a fraction of the memory cost.
Use cases
Use full precision for software agents that must emit runnable code with complete logic paths. Use it for official communications that demand native phrasing across many language families, and for OCR heavy image reasoning where text fidelity matters.
Use the quantized Ollama variant for local development, experimentation, batch content generation, and iterative prototyping. It is also a good fit for running on smaller cards and for serving multiple concurrent lightweight tasks on the same machine. If you want to customize smaller Qwen variants for a tighter task domain, this local guide will help you get started: fine tune Qwen locally.
Final Thoughts
Quantization with Q4_K_M does not cause a dramatic collapse in quality. It delivers a measurable trim that shows up in edge logic and subtle linguistic or perceptual details. If you can afford the VRAM, full precision wins on accuracy and completeness, and if you cannot, the Ollama build still delivers strong results for a large share of practical workloads.
Subscribe to our newsletter
Get the latest updates and articles directly in your inbox.

Related Posts

8 Best Claude Code Plugins in 2026 (You Need to Know)
8 Best Claude Code Plugins in 2026 (You Need to Know)

7 Best Claude Code Skills (You Need to Know)
7 Best Claude Code Skills (You Need to Know)

Claude Code Desktop IDE Features (You Need to Know)
Claude Code Desktop IDE Features (You Need to Know)