
Table Of Content
- Cohere Transcribe: model overview
- Features in practice
- Known limitations
- Local setup for Cohere Transcribe: Accurate Local ASR for 14 Languages
- Environment
- Hugging Face access
- Inference with Cohere Transcribe: Accurate Local ASR for 14 Languages
- Batch transcription
- Notes on multilingual testing
- Performance and practical tips for Cohere Transcribe
- Use cases
- Final thoughts

Cohere Transcribe: Accurate Local ASR for 14 Languages
Table Of Content
- Cohere Transcribe: model overview
- Features in practice
- Known limitations
- Local setup for Cohere Transcribe: Accurate Local ASR for 14 Languages
- Environment
- Hugging Face access
- Inference with Cohere Transcribe: Accurate Local ASR for 14 Languages
- Batch transcription
- Notes on multilingual testing
- Performance and practical tips for Cohere Transcribe
- Use cases
- Final thoughts
Cohere just released its Transcribe model. It is a 2 billion parameter automatic speech recognition model under the Apache 2 license built on a conformer architecture. I installed it locally and tested it across multiple languages.
The core idea is simple. You pass in audio and get back text. Performance is solid across a broad set of European languages and several Asian languages.
If you are comparing local ASR backends, you may also want to see a multilingual option in our notes on an omnilingual ASR approach.
Cohere Transcribe: model overview
The model converts the raw audio waveform into a Mel spectrogram. A Mel spectrogram is a visual representation of sound that splits audio into frequency bands over time. It is easier for a neural network to process than raw samples.
That spectrogram is fed into a conformer encoder. Conformers combine transformers for long range context with convolutions for local pattern sensitivity. This mix works well for phoneme level details and long form audio.
The encoder output goes to a lightweight transformer decoder that emits text tokens one by one. The design keeps inference fast for its size. It also supports built-in chunking for long audio.
Features in practice
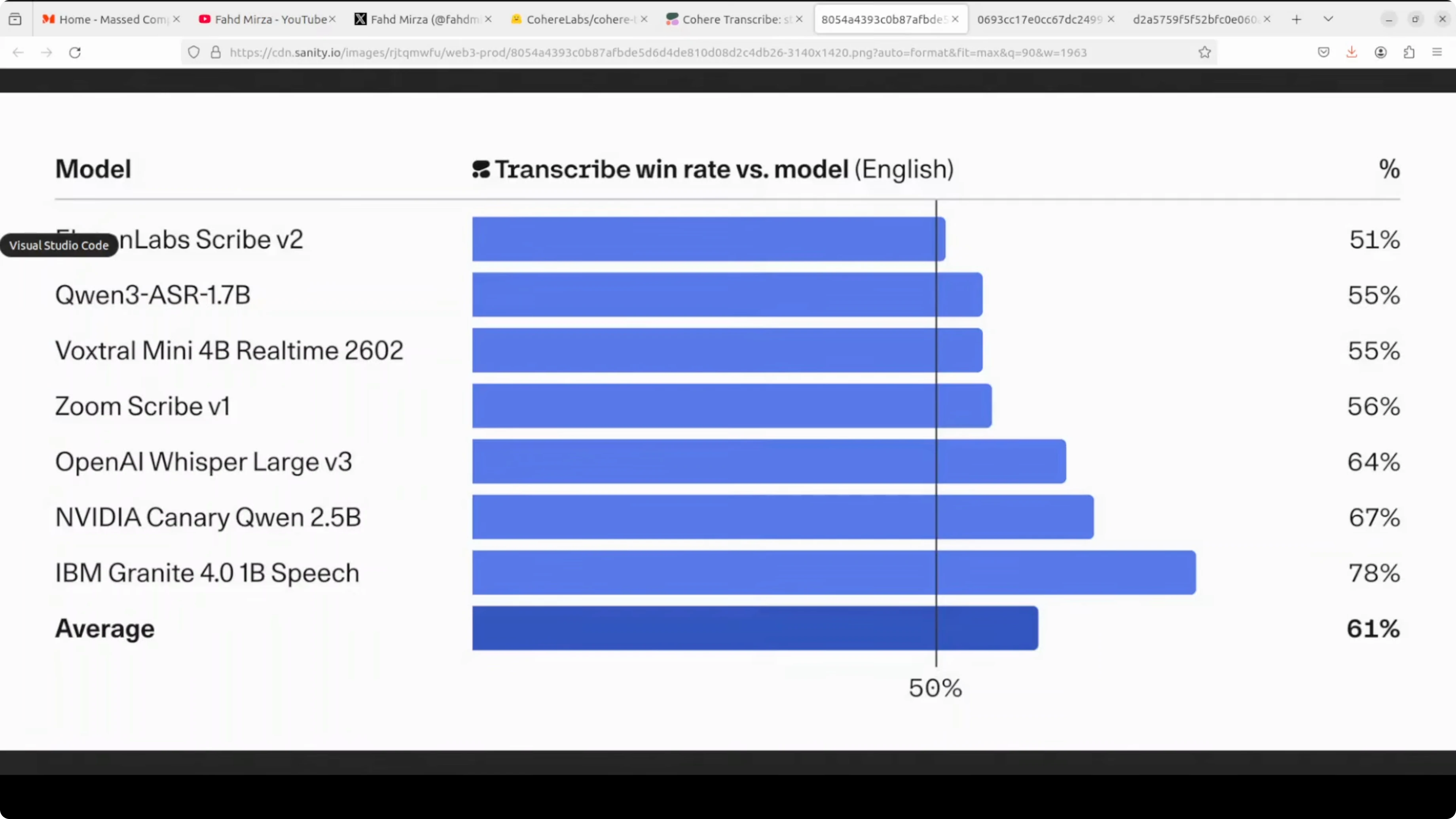
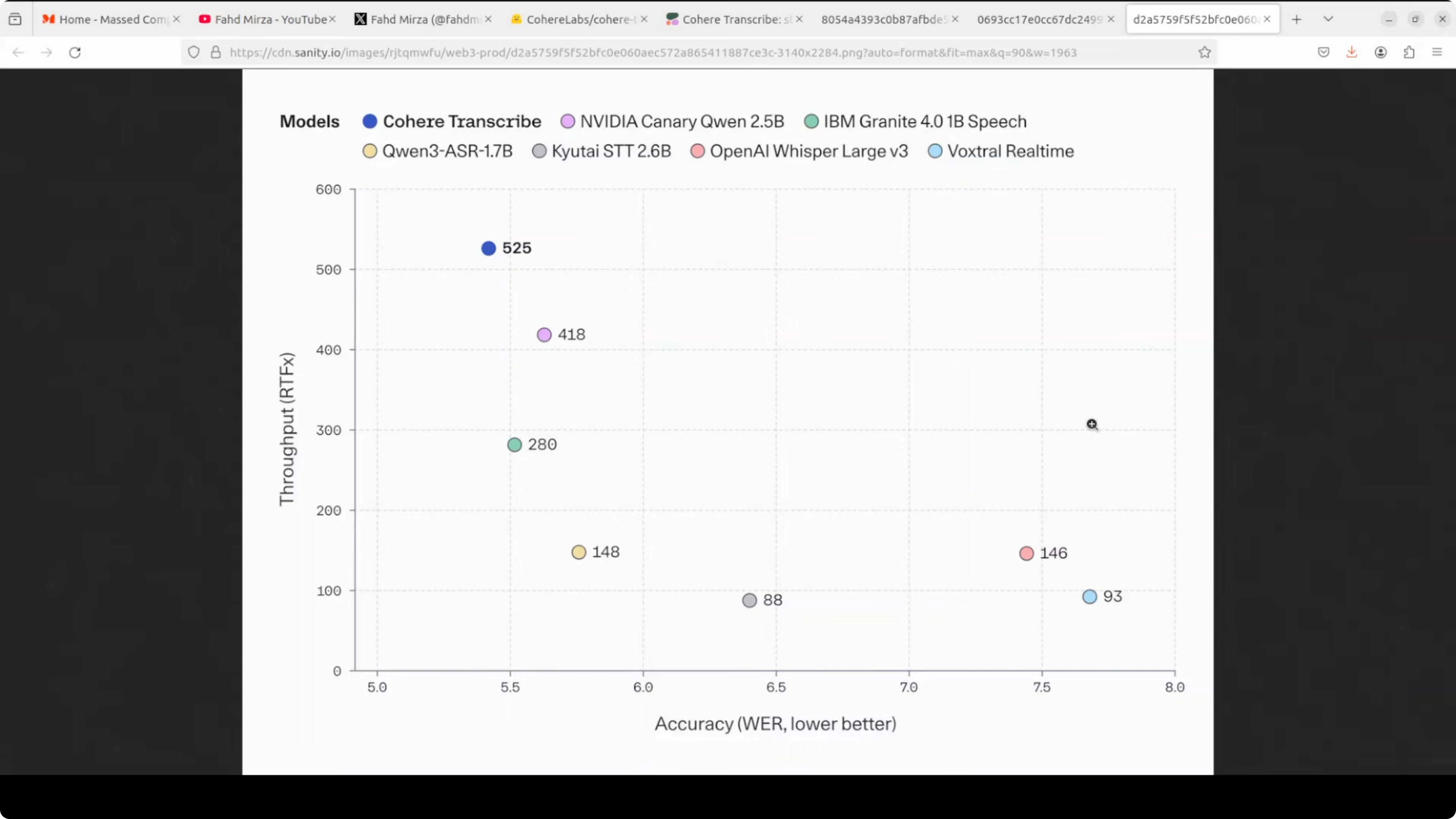
Parameter count sits at roughly 2B. It supports 14 languages spanning Arabic, Dutch, English, French, German, Greek, Japanese, Korean, Polish, Portuguese, Spanish, Vietnamese and more in that range. Throughput is up to around three times faster than other ASR models of similar size.
The license is Apache 2. Built-in chunking handles long files automatically without manual windowing. It is released as a gated model on Hugging Face.
If you are evaluating multiple local speech stacks, we also covered another strong ASR line in our overview of GLM-based ASR options.
Known limitations
Language detection is not included. Timestamps and speaker diarization are not provided. The model can hallucinate text on pure silence, which is clearly called out in the model card.
Local setup for Cohere Transcribe: Accurate Local ASR for 14 Languages
I ran this on Ubuntu with an Nvidia RTX 6000 48 GB GPU. VRAM use during inference stayed just under 5 GB in my tests. The setup is straightforward.
Environment
Create and activate a virtual environment.
python3 -m venv .venv
source .venv/bin/activate
python -V
pip install --upgrade pipInstall core dependencies. Torch and Torchaudio versions should match your CUDA runtime.
pip install torch torchaudio transformers huggingface_hub soundfileHugging Face access
The model is gated. Visit the Cohere Transcribe model page and accept the terms on your Hugging Face account.
Log in from your terminal so the download can proceed.
huggingface-cli loginPaste your user access token when prompted. The CLI will store credentials for future pulls.
Inference with Cohere Transcribe: Accurate Local ASR for 14 Languages
Here is a minimal Python pipeline that runs transcription on GPU if available. It uses chunking to process longer files.
from transformers import pipeline
import torch
asr = pipeline(
task="automatic-speech-recognition",
model="CohereLabs/cohere-transcribe-03-2026",
torch_dtype=torch.float16 if torch.cuda.is_available() else torch.float32,
device=0 if torch.cuda.is_available() else -1
)
audio_path = "path/to/audio.wav"
result = asr(audio_path, chunk_length_s=30)
print(result["text"])The model does not do language detection. Set the target language explicitly if your stack or processor supports it via generation kwargs.
result = asr(
audio_path,
chunk_length_s=30,
generate_kwargs={"language": "en"} # e.g., "ar", "de", "fr", "ja", "ko", "pl", "pt", "es", "vi"
)
print(result["text"])Batch transcription
For folders of files, iterate through paths and write out text files per audio. This keeps memory steady and reuses a single pipeline instance.
import os
from pathlib import Path
in_dir = Path("path/to/audio_dir")
out_dir = Path("transcripts")
out_dir.mkdir(parents=True, exist_ok=True)
for p in sorted(in_dir.glob("**/*")):
if p.suffix.lower() not in {".wav", ".mp3", ".flac", ".m4a"}:
continue
r = asr(str(p), chunk_length_s=30)
(out_dir / (p.stem + ".txt")).write_text(r["text"], encoding="utf-8")Long recordings benefit from chunking. You can experiment with chunk_length_s values like 20 to 60 seconds to balance speed and accuracy on your hardware.
Notes on multilingual testing
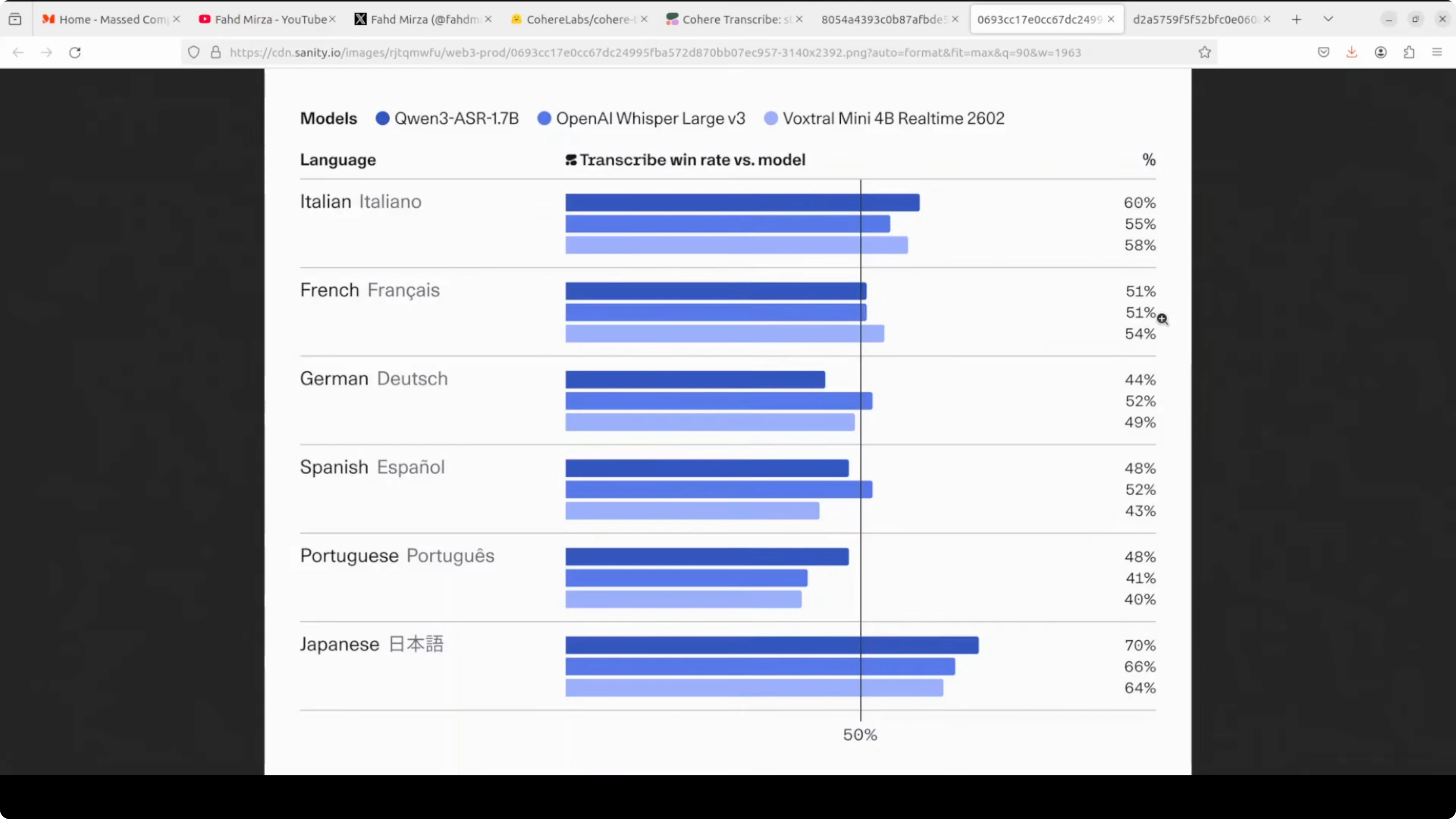
I ran a comprehensive pass over local files across the 14 supported languages. This included Arabic, a range of European languages, and Southeast Asian Vietnamese, as well as Korean, Spanish, Polish, Portuguese, Japanese, Dutch, French, German, Greek and English. Transcriptions looked strong across the board given the stated constraints.
For downstream summarization or Q&A on these transcripts entirely local to your machine, pairing with a compact local LLM works well. You can see how we set up a lightweight stack in our notes on running a local M-series model.
Performance and practical tips for Cohere Transcribe
Model weights load quickly for a 2B parameter ASR. Inference sat around 5 GB of VRAM on my GPU while chunking through long files. CPU inference works but is slower.
Avoid feeding long stretches of silence. Trim intros and tails to reduce the chance of stray tokens. If you need timestamps or diarization, add a downstream aligner or speaker embedding step in your pipeline.
If you plan to route transcripts into an automated workflow, local agents can orchestrate chunking, retries, and post-processing. For a hands-on example of agentic automation on-device, see how we built a local controller in our local AI agent walkthrough.
Use cases
On-device meeting notes for sensitive conversations fit well due to the Apache 2 license and local deployment. Media captioning in editorial pipelines benefits from fast throughput and long context chunking. Customer support call archives can be processed offline for keyword search and training.
Multilingual content teams can transcribe interviews across Arabic, European languages, and East Asian languages in a single workflow. Developers can feed transcripts into local models for summarization, topic extraction, and tagging without sending data to external services. Audio creators can stitch this into a local studio stack for podcast production and chaptering.
If you work with audio generation too, you can pair transcription for editing and indexing with a local music tool. Our notes on a local music generator show how to keep creative workflows on-device in this music generator build.
Final thoughts
Cohere Transcribe brings a conformer based, 2B parameter ASR under Apache 2, with strong multilingual accuracy and fast inference. It skips language detection, timestamps, and diarization, and can emit stray text on silence, but the model card states this clearly. For local multilingual speech-to-text with long audio handling, it is a capable option for production pipelines and private workloads.
Subscribe to our newsletter
Get the latest updates and articles directly in your inbox.

Related Posts

8 Best Claude Code Plugins in 2026 (You Need to Know)
8 Best Claude Code Plugins in 2026 (You Need to Know)

7 Best Claude Code Skills (You Need to Know)
7 Best Claude Code Skills (You Need to Know)

Claude Code Desktop IDE Features (You Need to Know)
Claude Code Desktop IDE Features (You Need to Know)