
Table Of Content
- Chroma 4B: Exploring End-to-End Virtual Human Dialogue Models
- What problem is it trying to solve?
- Architecture at a glance
- Setup and Installation
- Steps I followed
- VRAM usage
- Running Inference and the Voice Cloning Test
- Inputs provided
- Results - first pass
- Results - second pass with better source audio
- Final Thoughts

Chroma 4B: Exploring End-to-End Virtual Human Dialogue Models
Table Of Content
- Chroma 4B: Exploring End-to-End Virtual Human Dialogue Models
- What problem is it trying to solve?
- Architecture at a glance
- Setup and Installation
- Steps I followed
- VRAM usage
- Running Inference and the Voice Cloning Test
- Inputs provided
- Results - first pass
- Results - second pass with better source audio
- Final Thoughts
Chroma 4B is an end-to-end multimodal spoken dialogue model that processes raw user audio input, understands its content and style, and generates both text responses and personalized synthetic speech in real time. A lot is happening here, and that is why it is being framed as a virtual human. I installed Chroma 4B, tested it to see how it works, and unpacked its architecture in simple terms.
Chroma 4B: Exploring End-to-End Virtual Human Dialogue Models
What problem is it trying to solve?
Older end-to-end models in similar modality can already understand incoming speech and produce new speech by turning audio into discrete tokens like compressed code words. They use speech tokenizers for that and then use neural codecs to rebuild waveform audio. But they are not really good at keeping the exact same personal voice identity consistent. The AI often sounds generic or robotic instead of cloning your own voice properly for natural personalized chats.
This is where Chroma is trying to help. It is positioned as the first open-source real-time model that aims for both super low latency and high fidelity voice cloning from just a short reference clip.
Architecture at a glance
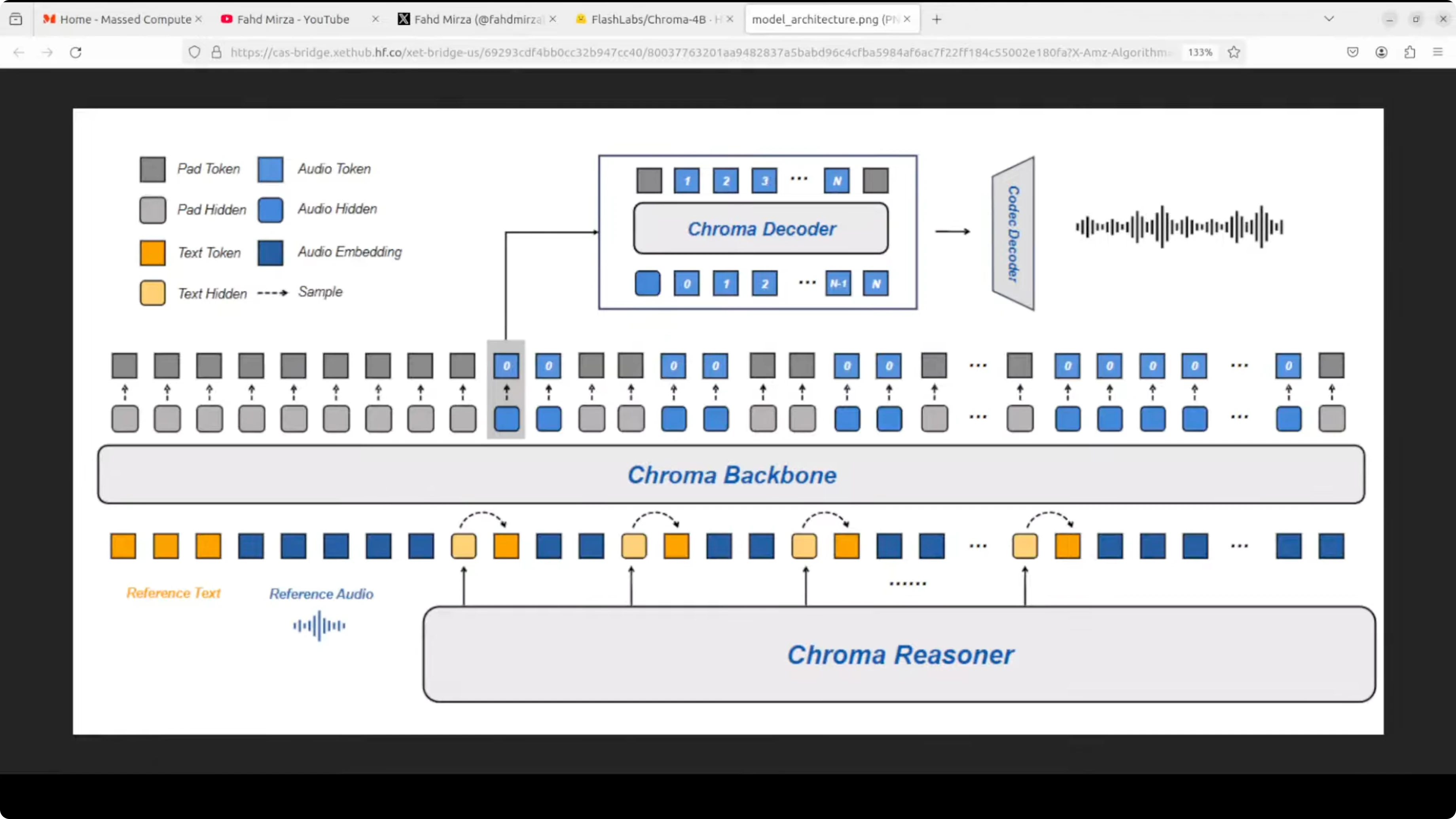
- Reasoner (Qwen-based): Takes raw audio input and outputs text plus acoustic hidden information.
- Llama-style backbone: Auto-regressively predicts coarse audio codec codes using a 1-to-2 text-to-audio token interleave trick for fast streaming.
- Tiny decoder: Fills in the finer details.
- Mini codec: Turns those codec codes back into smooth 24 kHz speech output.
Compared to various other models, this architecture is relatively simple, and through that simplicity it aims to extract as much quality as possible.
Setup and Installation
I used an Ubuntu system with an NVIDIA RTX A6000 (48 GB VRAM) and checked how much it consumes during inference.
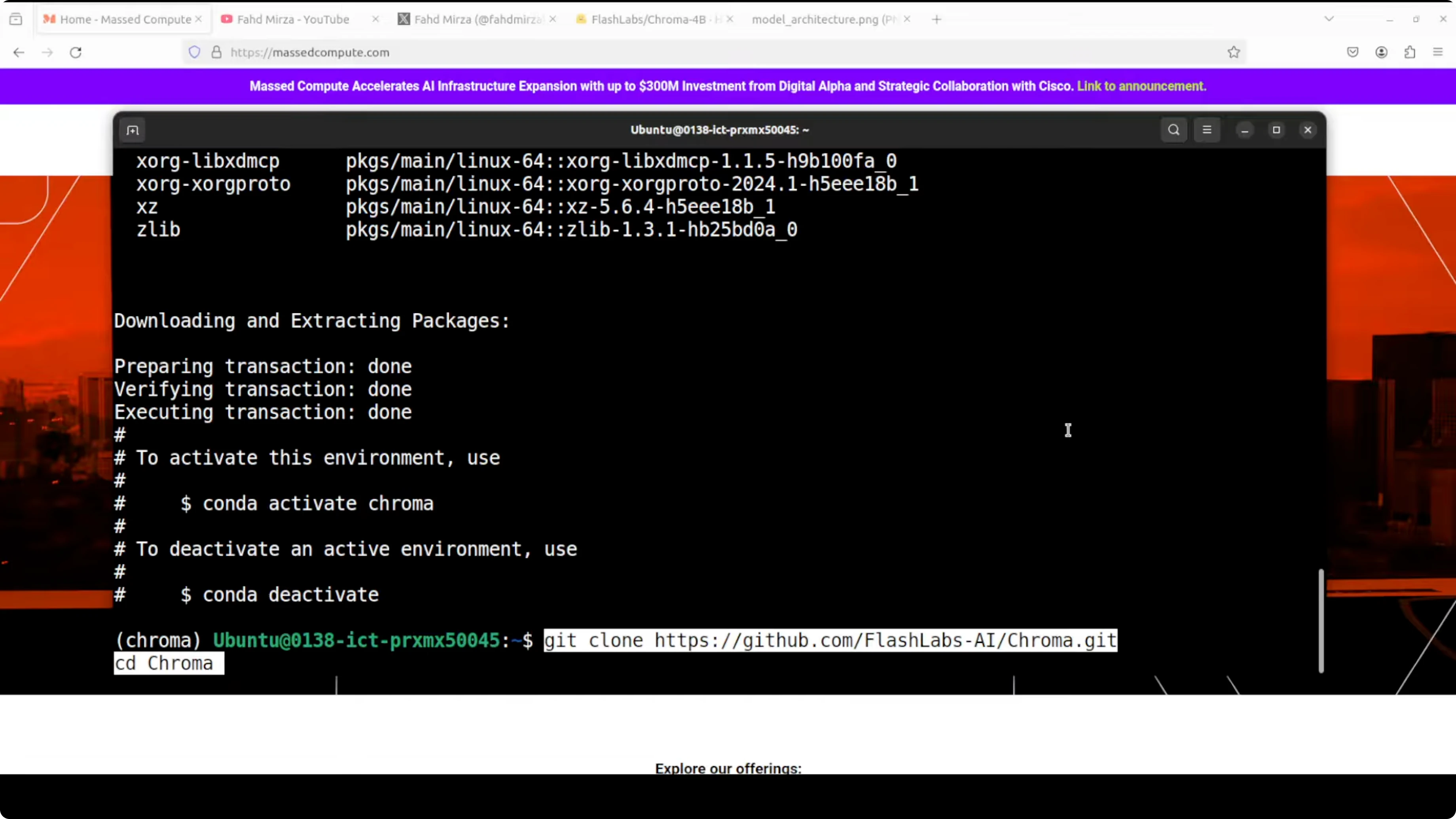
Steps I followed
- Created a virtual environment.
- Cloned the Chroma repository.
- Installed all prerequisites.
- Launched a Jupyter notebook.
- Downloaded the model.
- Note: It is a gated model on Hugging Face. You need to accept the terms and conditions and log in to Hugging Face with your read token.
- The model size on disk is over 14 GB.
- Loaded the model and prepared for inference.
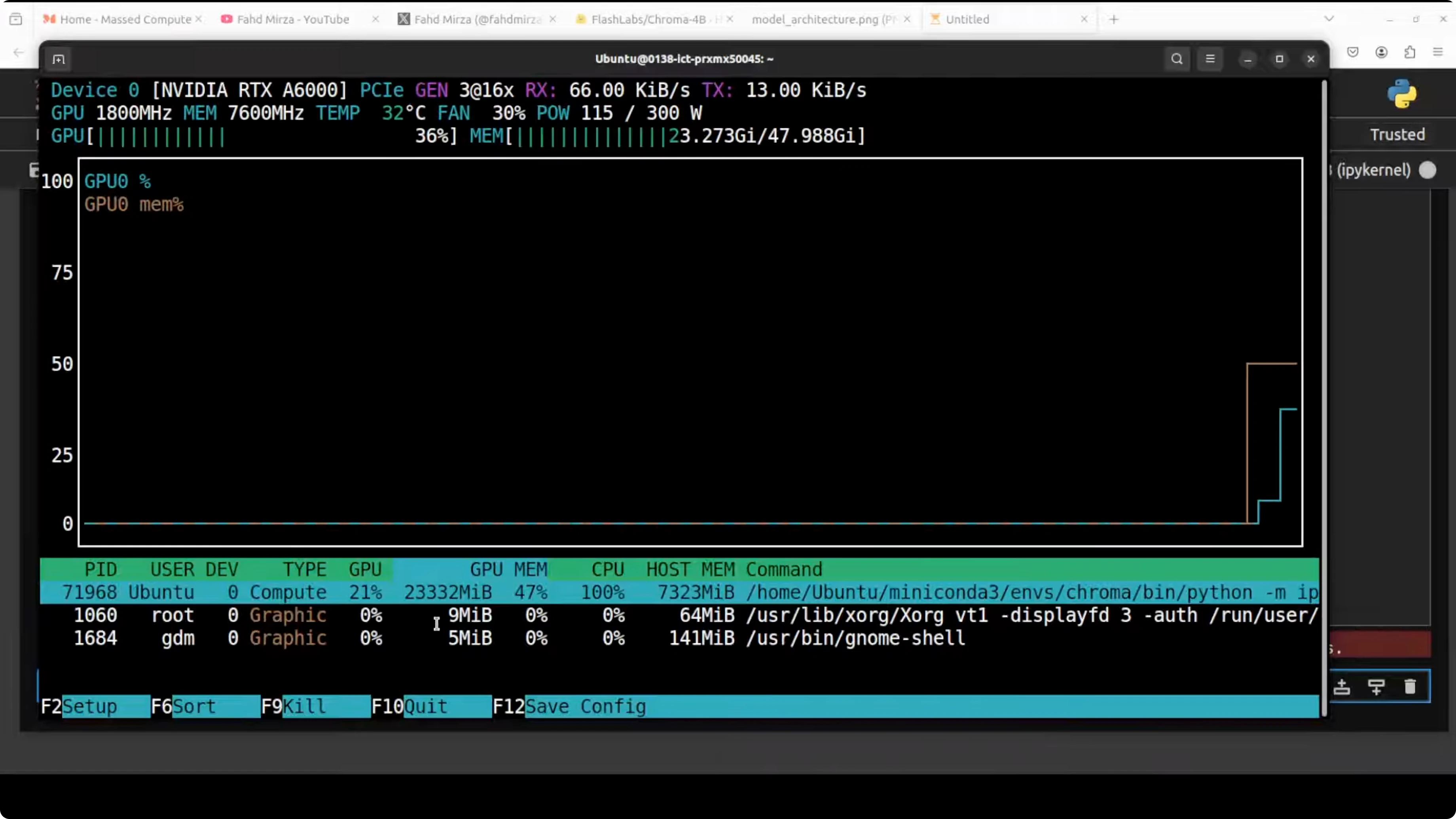
VRAM usage
- During inference, VRAM consumption was over 23 GB.
Running Inference and the Voice Cloning Test
Inputs provided
- A system prompt.
- An example input audio prompt (a short reference clip in my voice).
- A text prompt containing a long sentence with pauses, breaks, and expressions.
- A speaker name set to my own voice.
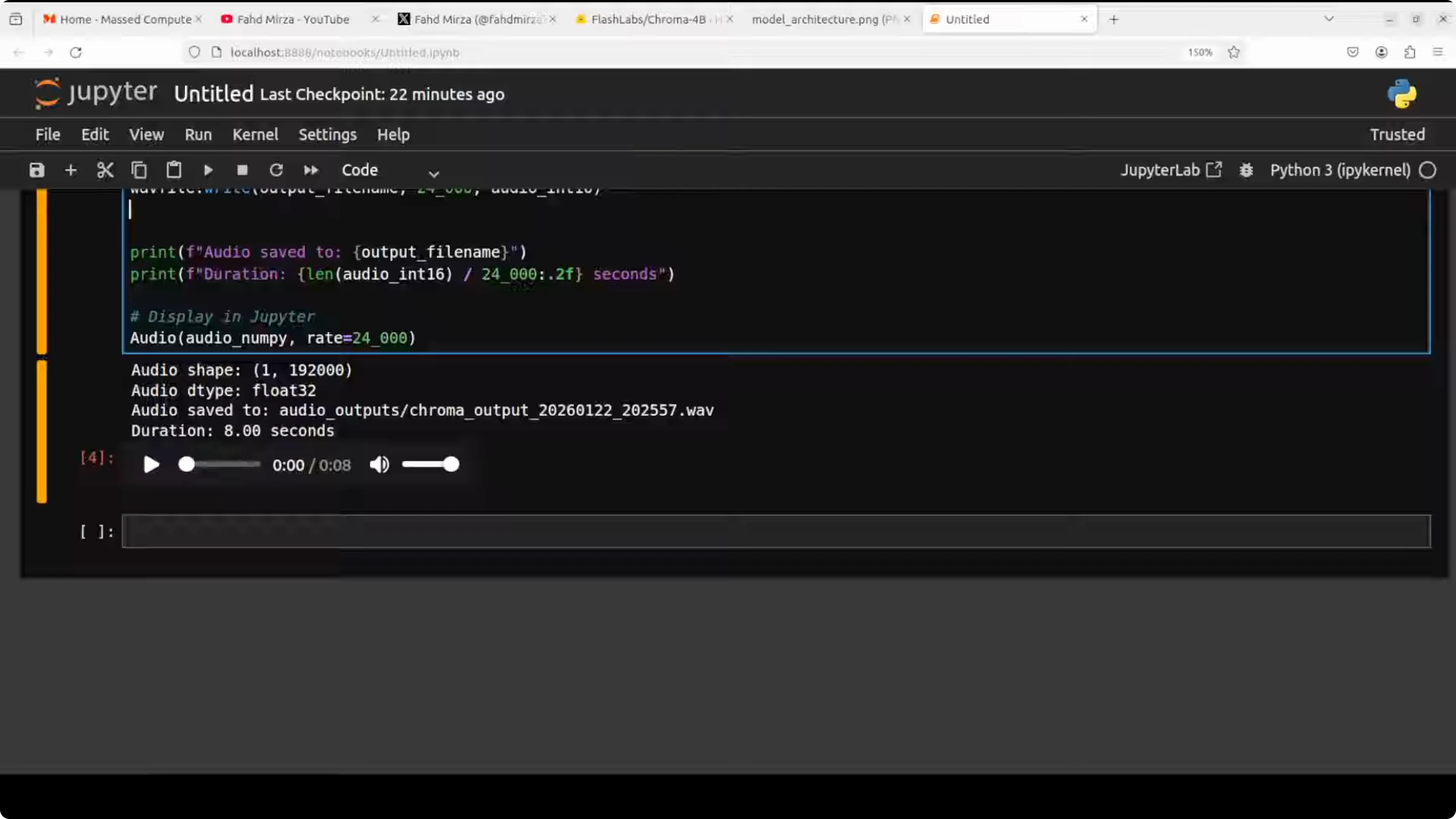
- The model processes the inputs based on hyperparameters, generates the output audio, and saves it for playback.
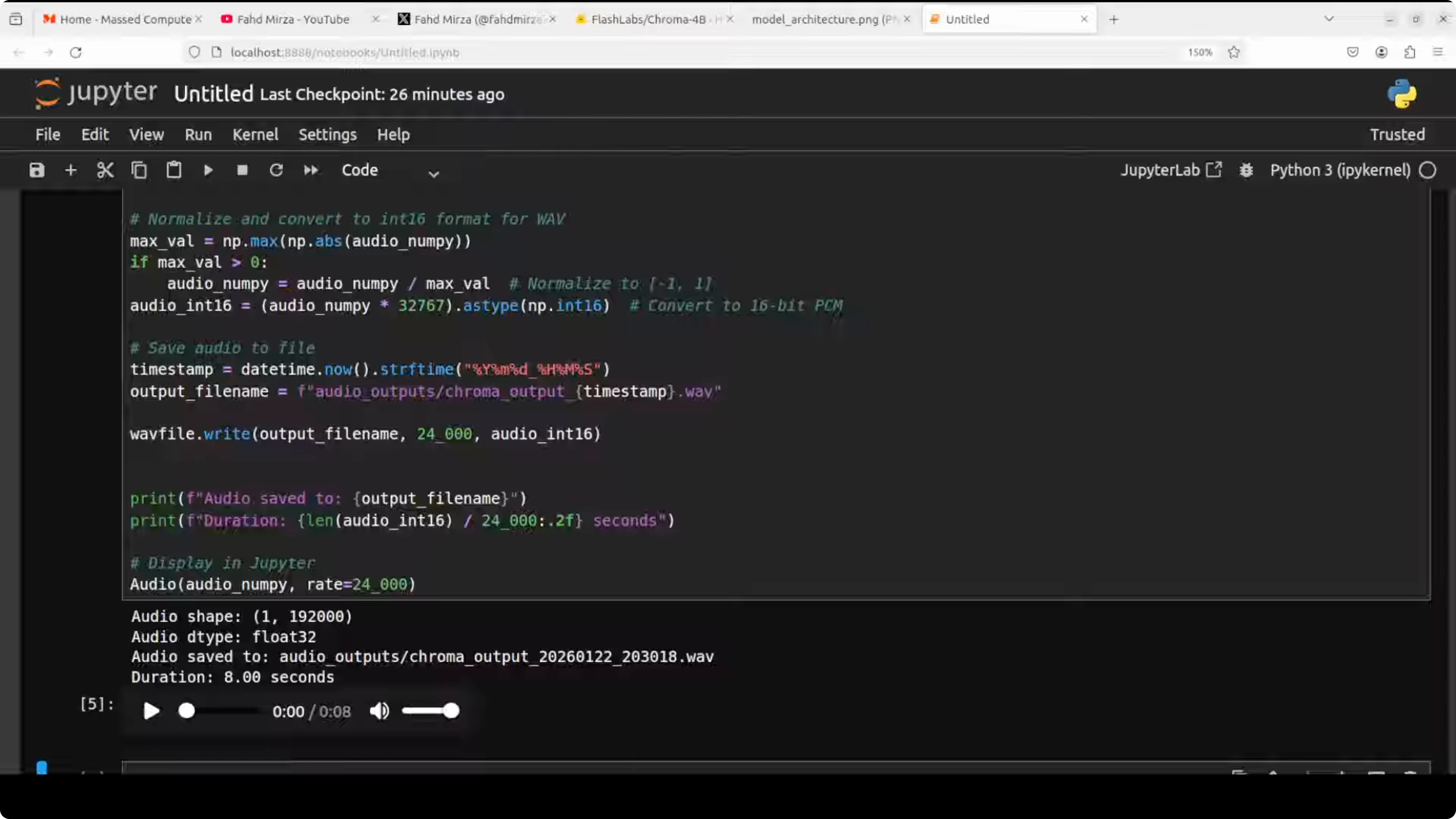
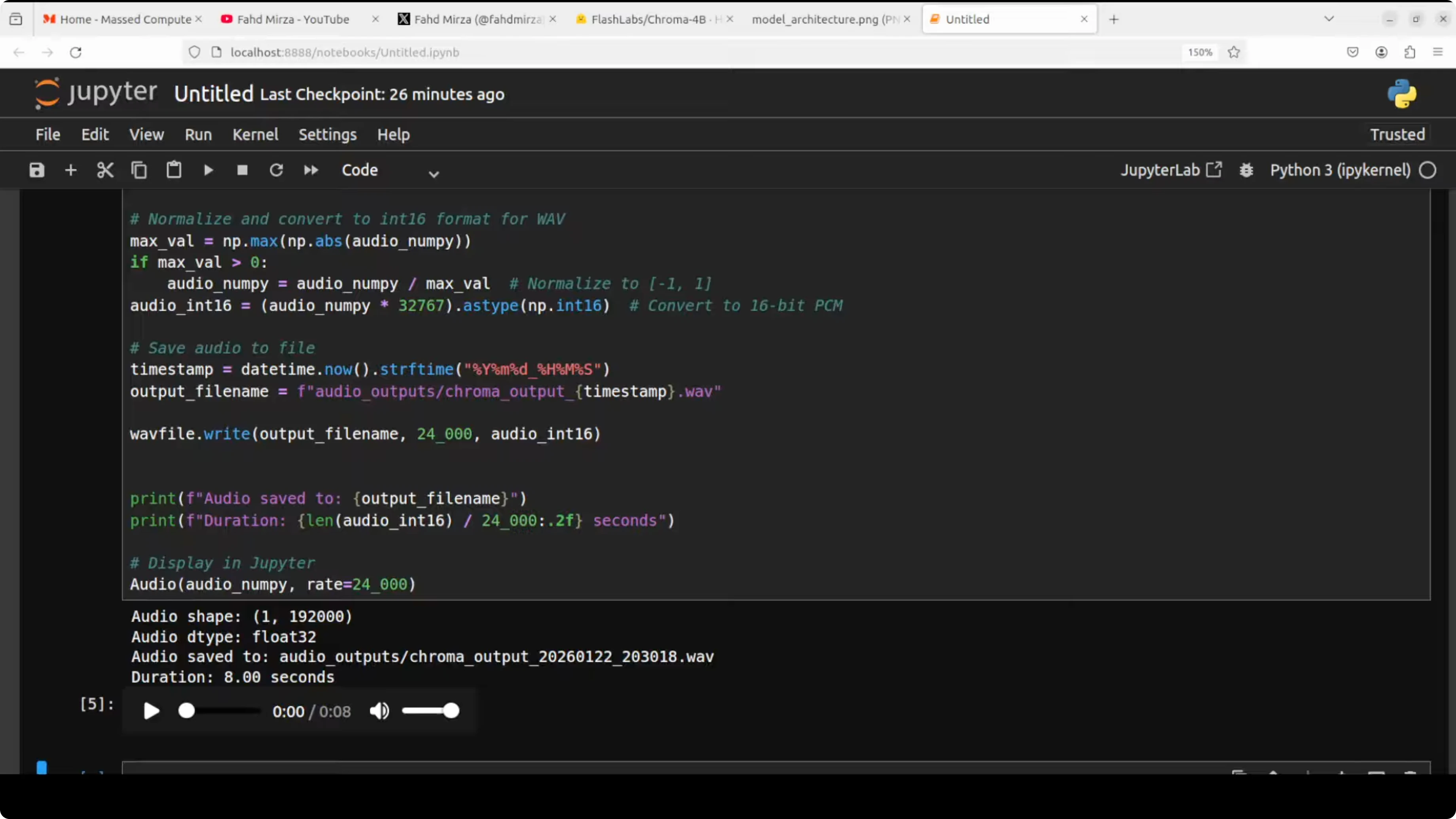
Results - first pass
- Content accuracy: The response described taco ingredients and steps.
- Voice cloning quality: It responded correctly, but the cloning did not match my voice well. There were hints of my voice, but not convincingly so. Example output included:
- "How make a ta... You'll need some ingredients like corn tortillas, ground beef or chicken, cheese, lettuce, tomatoes, onion."
- My take: I have seen better clones. The reference audio quality might have limited the results.
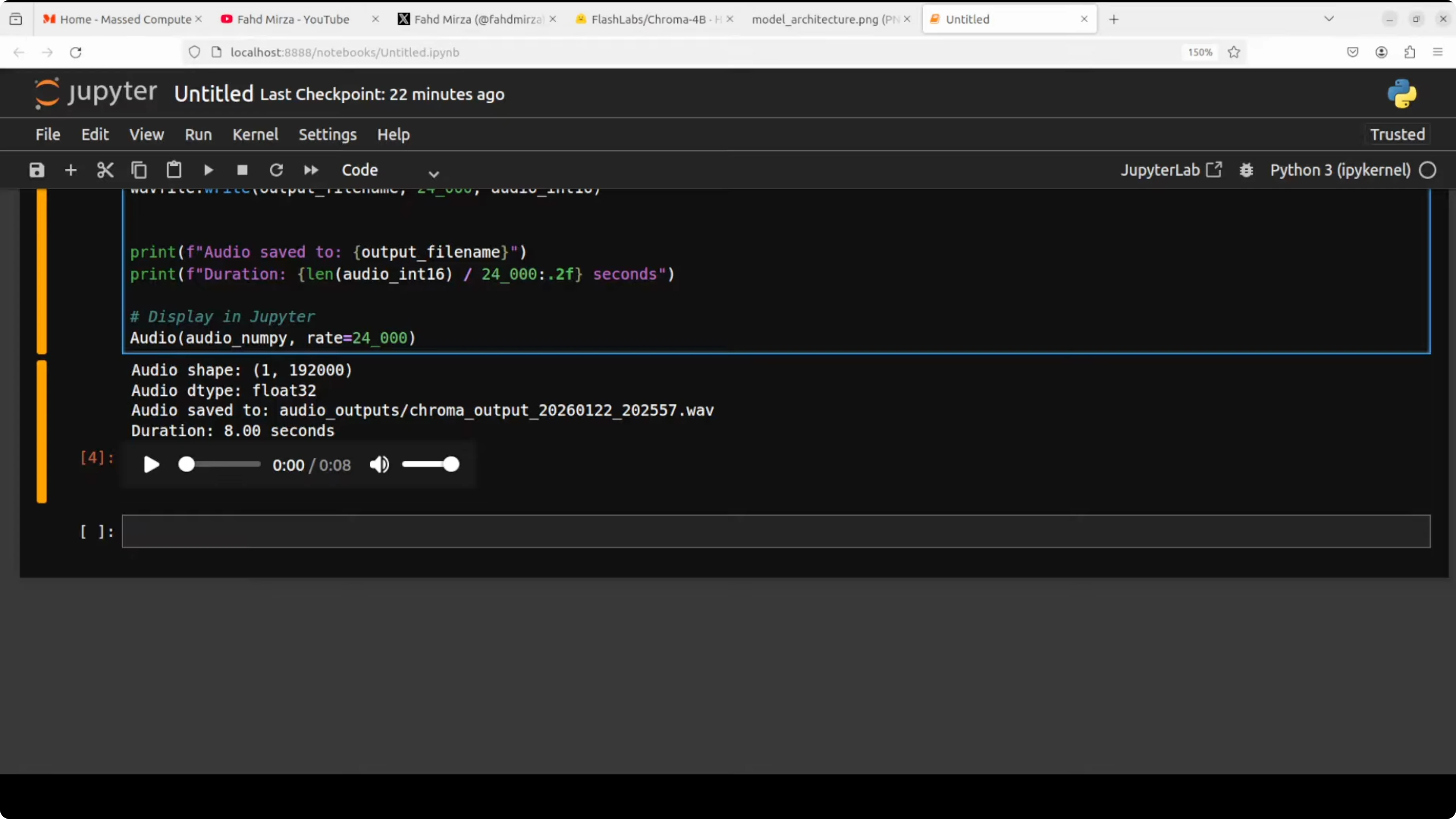
Results - second pass with better source audio
- Source audio example: "Happiness is a fleeting feeling that can be found in life's simplest moments. A warm conversation with a loved one, a beautiful sunset, or a good cup of coffee can instantly lift our mood."
- Outcome: Using the same text prompt with a higher-quality source clip, the taco response again did not convincingly match the source voice.
Final Thoughts
Chroma 4B delivers an end-to-end setup with real-time speech generation and a simple, practical architecture. The content response was fine, but in my tests the voice cloning did not meet current expectations. As of January 2026, there are free open-source models that produce stronger cloning from short references. Good effort overall, and I hope the next version improves cloning quality.
Subscribe to our newsletter
Get the latest updates and articles directly in your inbox.

Related Posts

8 Best Claude Code Plugins in 2026 (You Need to Know)
8 Best Claude Code Plugins in 2026 (You Need to Know)

7 Best Claude Code Skills (You Need to Know)
7 Best Claude Code Skills (You Need to Know)

Claude Code Desktop IDE Features (You Need to Know)
Claude Code Desktop IDE Features (You Need to Know)