

VoxCPM2: Free TTS Model Cloning Voices and Speaking 30 Languages
VoxCPM2 (also called VALL-E X CPM 2) is an open-source text-to-speech model that speaks 30 languages, clones voices, and can design a new voice from a plain-text description. I ran it locally on an Ubuntu server with a single NVIDIA A6000 (48 GB VRAM), and it has been improving with every iteration. The appeal is simple: no reference audio is required for voice design, and you can get strong results by just describing the voice you want.
I have been tracking this project since day zero across versions and forms, and this release raises the bar in speed, flexibility, and multilingual coverage. It can clone a voice from a short audio clip, control emotion, pace, and expression, and it also includes an ultimate cloning mode for near-perfect replication. It needs no language tags for multilingual synthesis, and it outputs studio-quality audio that we will assess based on local tests.
For more context and related projects across speech, explore our TTS coverage here: our TTS posts.
Install VoxCPM2 locally
I set this up on Ubuntu with Conda, a clean Python environment, and a Gradio demo for quick testing. The first launch downloads model weights automatically, so give it a moment on initial run.
Create a fresh environment.
conda create -n voxcpm2 python=3.10 -y
conda activate voxcpm2
Clone the code and install requirements. If you are working directly with the model on Hugging Face, the resource is here: https://huggingface.co/openbmb/VoxCPM2.
git clone https://github.com/openbmb/VoxCPM2.git
cd VoxCPM2
pip install -r requirements.txt
Launch the demo.
python app.pyOn first run, the model assets download and the Gradio app starts on localhost, typically at port 7860. On the A6000, GPU memory use hovered around 45 GB in my session.
If your UI loads but the model panel disappears or login/setup loops during local testing, check this fix for common environment issues: resolve setup or login glitches.
Quick results on text-to-speech
I tested plain text-to-speech with no reference audio, no control structure, just a sentence to synthesize. It generated quickly compared with the prior VALL-E X CPM version, which felt a bit slow. One-shot quality looked strong for a generic prompt.
Voice design from a description
The model can design a new voice using only a description written in natural language. I asked for a deep, dramatic movie trailer voice and let it synthesize from scratch. The result matched the style very closely and showed strong timbre control.
Voice cloning and emotion control
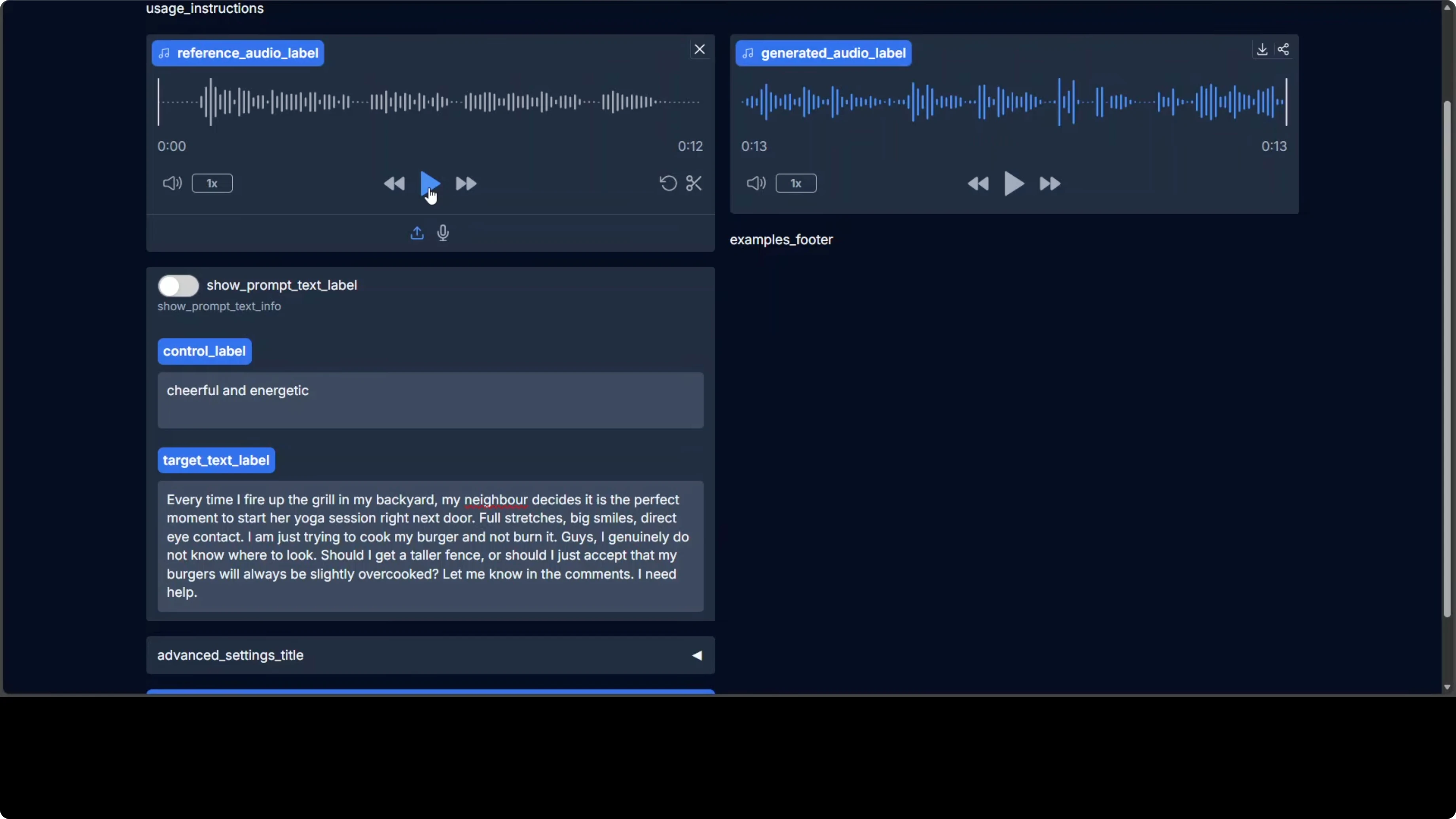
Voice cloning works from short reference audio and lets you condition for emotion, pace, and expression. My first attempt aimed for a cheerful, energetic tone, but the output sounded monotone and missed the emotion target. A second attempt with a higher-quality reference recording improved the result significantly.
The takeaway is straightforward: better reference audio yields better cloning quality. Low-bitrate or compressed samples hold the system back, while clean references help the model lock onto timbre and prosody more accurately. Keep your prompts concise and avoid background noise in your references for best results.
To build robust production pipelines around TTS, consider a backup plan for synthesis outages or model load failures. You can learn the pattern here: add a fallback model to your stack.
Multilingual synthesis
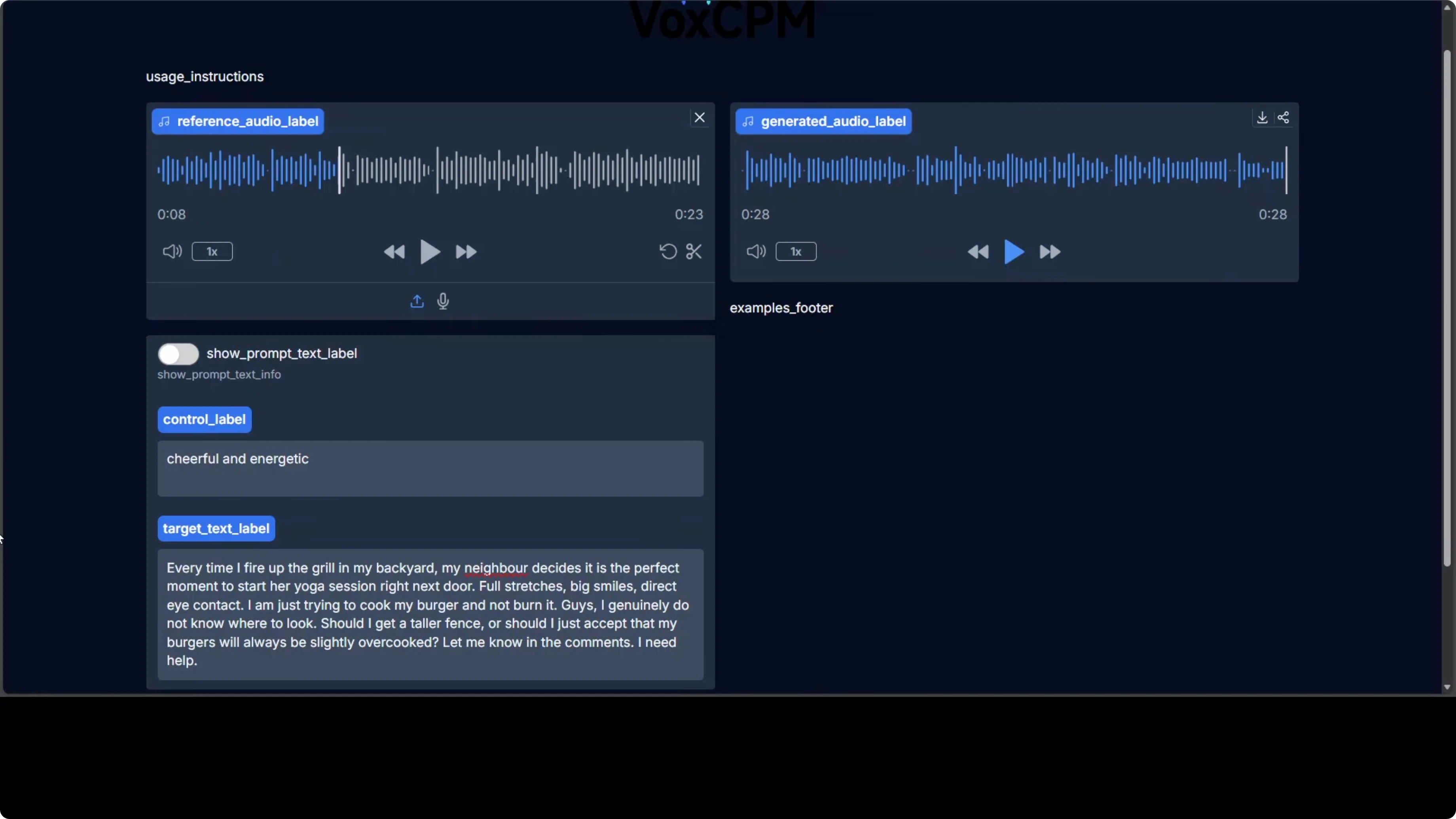
VoxCPM2 supports 30 languages, from English, French, and Spanish to Arabic, Japanese, Hindi, and multiple Chinese dialects. No language tags are needed; type in your language and the model infers it. In local tests, cloning quality across Arabic, Polish, Hindi, German, Chinese, Spanish, Portuguese, and Japanese was strong, and it can produce stylized voices such as an anime-inspired delivery.
If you are validating pronunciation and accent fidelity, native speaker reviews help benchmark strengths and gaps. The system handles cross-lingual cloning well, and speed remained comfortable across runs. Expect variation based on reference audio quality, target text complexity, and phoneme coverage.
If you are pairing TTS with document understanding, you may also need fast, accurate text extraction. For that piece, see our pick for the best OCR choice in production workflows.
Architecture overview
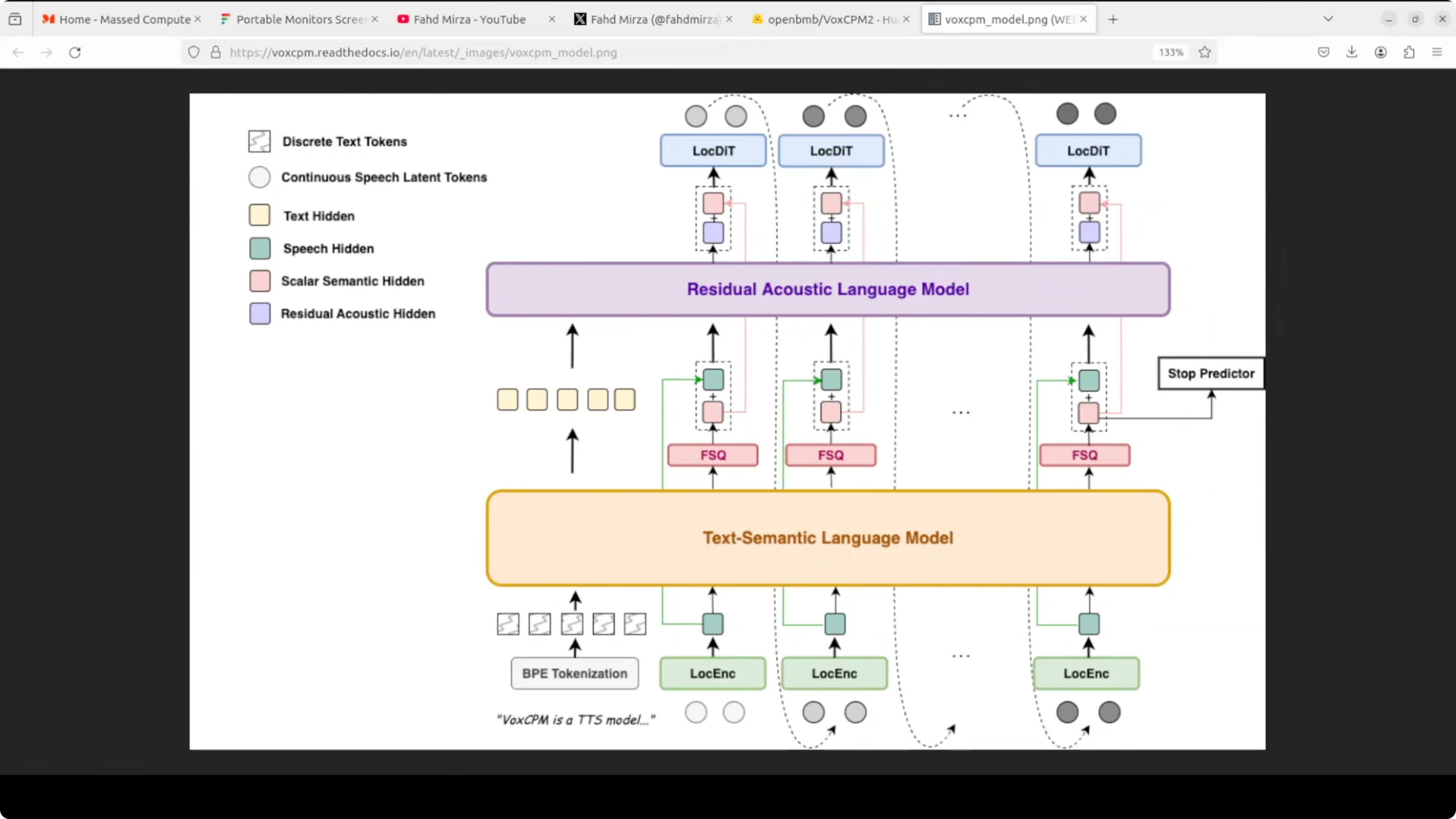
Under the hood, VoxCPM2 follows a tokenizer-free diffusion autoregressive design. It combines a local encoder, a text language model, a reference audio language model, and a diffusion transformer on top of a MiniCPM 4 backbone. The model has around 2 billion parameters trained on over 2 million hours of multilingual speech.
This stack explains its strong multilingual coverage and design-by-description capability. The diffusion component refines acoustic details, while the language models align content and style across text and audio tokens. The absence of fixed tokenizers reduces brittleness for non-English scripts and varied phonetics.
If you are comparing compute footprints or looking for compact text models to pair with TTS for content generation, see this overview of a 7B-parameter model for reference.
Usage tips
Keep reference clips short, clean, and representative of the desired timbre and cadence. Emotional control works better when the target text leaves room for expressive variation and punctuation cues.
For multilingual runs, write text naturally in the target language and avoid mixing scripts in a single sentence. If you run into environment or UI flakiness during setup, a clean conda environment and strict dependency pinning usually resolves it, and this guide can help diagnose edge cases: fix environment-related UI issues.
Use cases
Audiobook narration can benefit from voice design for character voices and consistent timbre across chapters. Localization teams can clone a source brand voice and render scripts across multiple languages without manual retakes.
Interactive voice agents can combine a cloned persona with emotion control for more engaging prompts and responses. Accessibility projects can create clear, expressive voices tailored for long-form listening in education or public services.
Final thoughts
VoxCPM2 brings three pillars together: describe-a-voice synthesis, controllable cloning, and broad multilingual support. The new iteration runs faster than before, outputs studio-quality audio, and benefits dramatically from good reference material.
If you work across TTS, ASR, and document understanding, pair this with strong OCR and a fallback plan for model reliability. For deeper TTS coverage and adjacent tools, explore our TTS library and related production guides like adding a fallback model and choosing a proven OCR component.
Subscribe to our newsletter
Get the latest updates and articles directly in your inbox.

Related Posts

8 Best Claude Code Plugins in 2026 (You Need to Know)
8 Best Claude Code Plugins in 2026 (You Need to Know)

7 Best Claude Code Skills (You Need to Know)
7 Best Claude Code Skills (You Need to Know)

Claude Code Desktop IDE Features (You Need to Know)
Claude Code Desktop IDE Features (You Need to Know)