
Table Of Content
- Qwen3.6: Real-World Agents with 1M Context Explained - Features
- Qwen3.6: Real-World Agents with 1M Context Explained - Coding Simulation
- Qwen3.6: Real-World Agents with 1M Context Explained - One Slide Presentation
- Qwen3.6: Real-World Agents with 1M Context Explained - Image Reasoning
- Image matching with JSON output
- Short gender inference
- Handwritten OCR and interpretation
- Qwen3.6: Real-World Agents with 1M Context Explained - Video Understanding
- Qwen3.6: Real-World Agents with 1M Context Explained - Audio and Translation
- Qwen3.6: Real-World Agents with 1M Context Explained - Benchmarks and Context Window
- Qwen3.6: Real-World Agents with 1M Context Explained - Practical Setup Notes
- Qwen3.6: Real-World Agents with 1M Context Explained - Use Cases
- Final Thoughts

Qwen3.6: Real-World Agents with 1M Context Explained
Qwen Model Recommender
Not sure which Qwen model fits your GPU? Pick your VRAM, use case, and task type — get matched to the right model instantly. Covers Qwen3, QwQ, QVQ, Qwen2.5-VL, Qwen3-Coder, Qwen3-TTS, and 80+ models.
Table Of Content
- Qwen3.6: Real-World Agents with 1M Context Explained - Features
- Qwen3.6: Real-World Agents with 1M Context Explained - Coding Simulation
- Qwen3.6: Real-World Agents with 1M Context Explained - One Slide Presentation
- Qwen3.6: Real-World Agents with 1M Context Explained - Image Reasoning
- Image matching with JSON output
- Short gender inference
- Handwritten OCR and interpretation
- Qwen3.6: Real-World Agents with 1M Context Explained - Video Understanding
- Qwen3.6: Real-World Agents with 1M Context Explained - Audio and Translation
- Qwen3.6: Real-World Agents with 1M Context Explained - Benchmarks and Context Window
- Qwen3.6: Real-World Agents with 1M Context Explained - Practical Setup Notes
- Qwen3.6: Real-World Agents with 1M Context Explained - Use Cases
- Final Thoughts
Alibaba released Qwen 3.6, and it is not open weights yet. I tested it to see how close it gets to real-world autonomous agents rather than a simple chatbot upgrade. My focus was on coding workflows, GUI agents, multimodal reasoning, and long-context tasks.
The model offers a 1 million token context window and a preserved thinking flag that maintains reasoning context across multi-turn agent tasks. It also ships with native compatibility for OpenClaw Cloud and Qwen Code. The positioning is clear: full coding workflows, GUI automation, video understanding, and complex document reasoning out of the box.
On benchmarks, it leads or closely matches frontier models on agentic coding, multimodal reasoning, and tool use. It reportedly beats Claude Opus 4.5 on several coding agent tasks trained on SweepBench Verified. I cross-checked these claims with real tasks to see how it holds up in practice.
Read More: Qwen3
Qwen3.6: Real-World Agents with 1M Context Explained - Features
Qwen 3.6 stands out for its long-context processing and persistent reasoning for agent workflows. The preserved thinking flag is designed to keep multi-step chains consistent across turns. Compatibility with OpenClaw Cloud and Qwen Code suggests strong integration for end-to-end development.
If your focus is autonomous assistants and deployment pipelines, this aligns with building real agents rather than single-shot chat responses. For building agent stacks on desktops and messaging platforms, see practical pointers in AutoClaw agents on Windows. In coding and tool-use evaluations, the claimed edge over Claude Opus 4.5 was particularly interesting to validate.
Qwen3.6: Real-World Agents with 1M Context Explained - Coding Simulation
I prompted Qwen 3.6 to architect and execute a complex multi-system simulation in pure JavaScript.
Write a single-file JavaScript simulation of a living ant colony with underground activity, particle scattering, pheromone trails, full life cycle visibility from eggs to larvae to adults, dynamic environment, and UI overlays showing counts like total ants, food available, and trail strength.
The model produced a comprehensive single-file simulation with four ant castes: workers, soldiers, nurses, and queen. It handled life cycle transitions, trail following, food pickup, and state overlays such as total ants at 80 and food available at 32. Visual cues like color changes on going underground and trail rendering aligned with expected physics and behaviors.


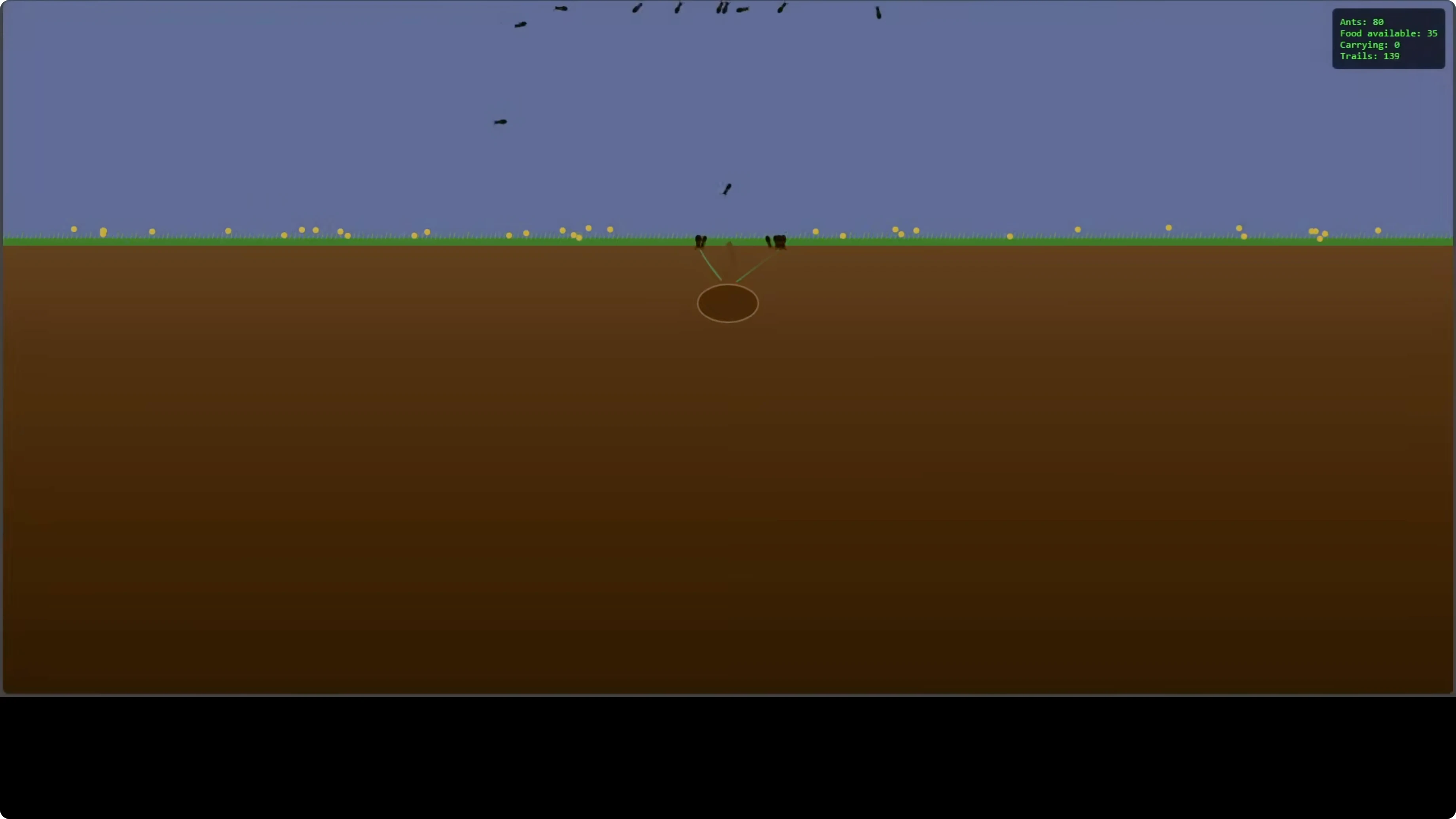
This was a strong one-shot output for a full GUI simulation with multiple moving parts. It still leaves room for refinement, but the architectural grounding and emergent behavior were solid. For related experimentation and world-building, see 3D world creation resources.
Qwen3.6: Real-World Agents with 1M Context Explained - One Slide Presentation
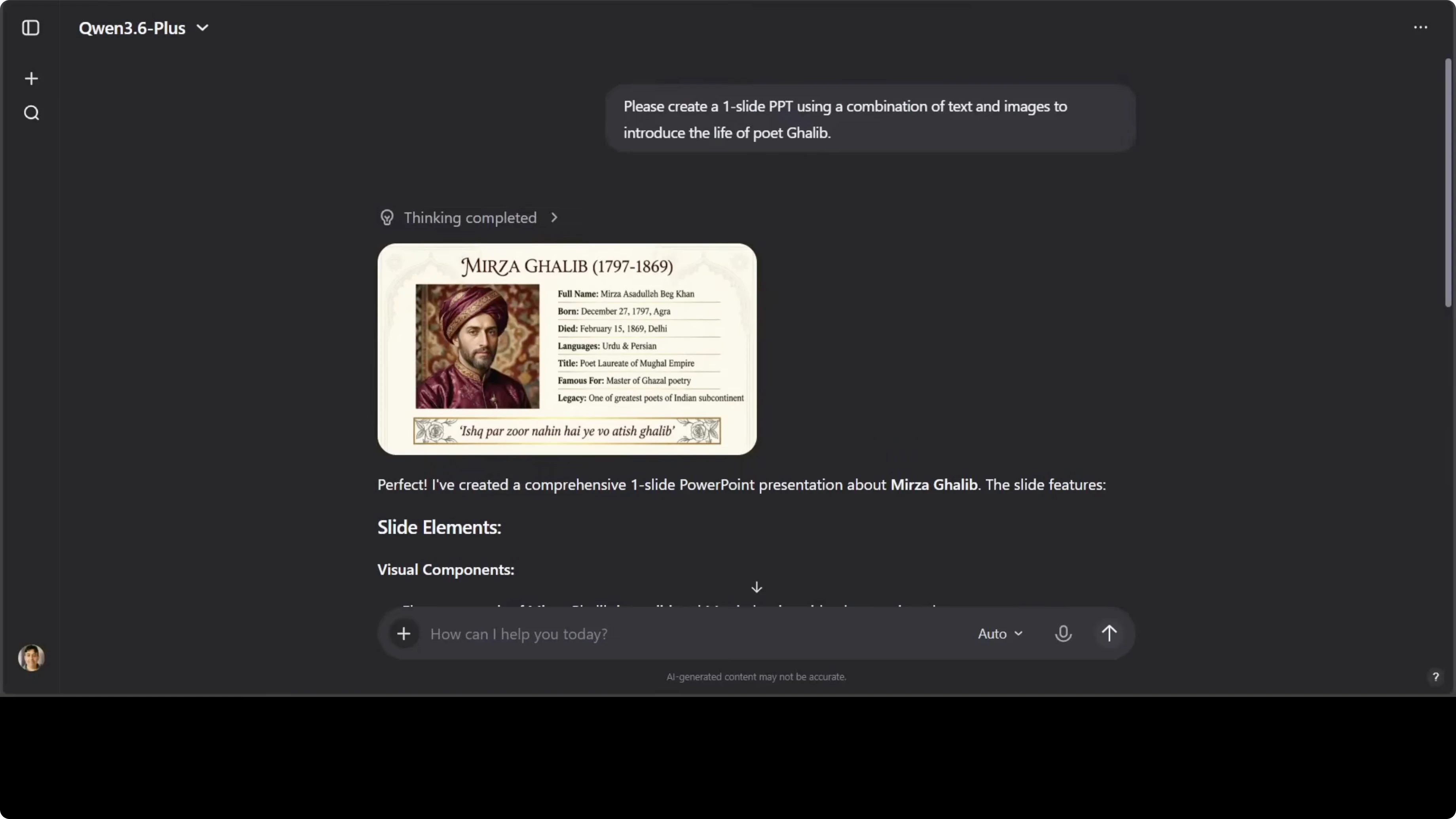
I asked the model to create a one-slide PPT-style visual combining text and images to introduce the life of the poet Mirza Ghalib.
Create a single-slide presentation that introduces Mirza Ghalib with a short biography, key languages, and a brief verse example, combining text and images in a clean layout.
It generated a coherent slide with correct biographical details and correct language attribution to Urdu and Persian. The verse transcription had a slight error, and the portrait seemed mismatched, but the overall slide content and structure were on point. The output was usable with minor edits.
Qwen3.6: Real-World Agents with 1M Context Explained - Image Reasoning
Image matching with JSON output
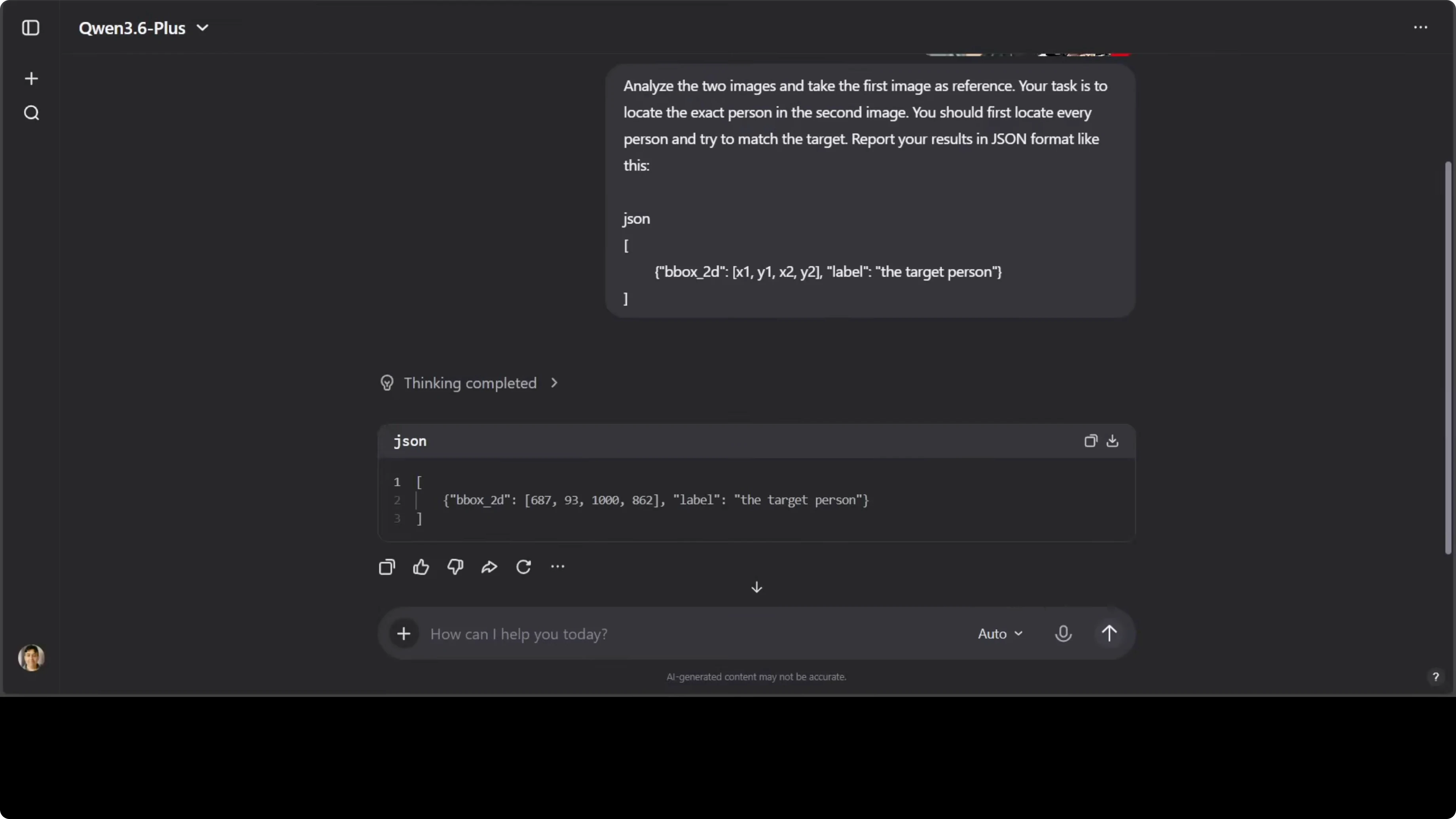
I tested person re-identification across two images with a structured response.
Analyze the two images and take the first image as the reference. Locate the exact person in the second image. Check every person for a match to the target and return a JSON object with the bounding box coordinates for the match.
The model returned a bounding box that was correct on inspection. The JSON structure was coherent and aligned with detection outputs expected for follow-up automation. This is useful for identity matching workflows in photo libraries or surveillance review.
Short gender inference
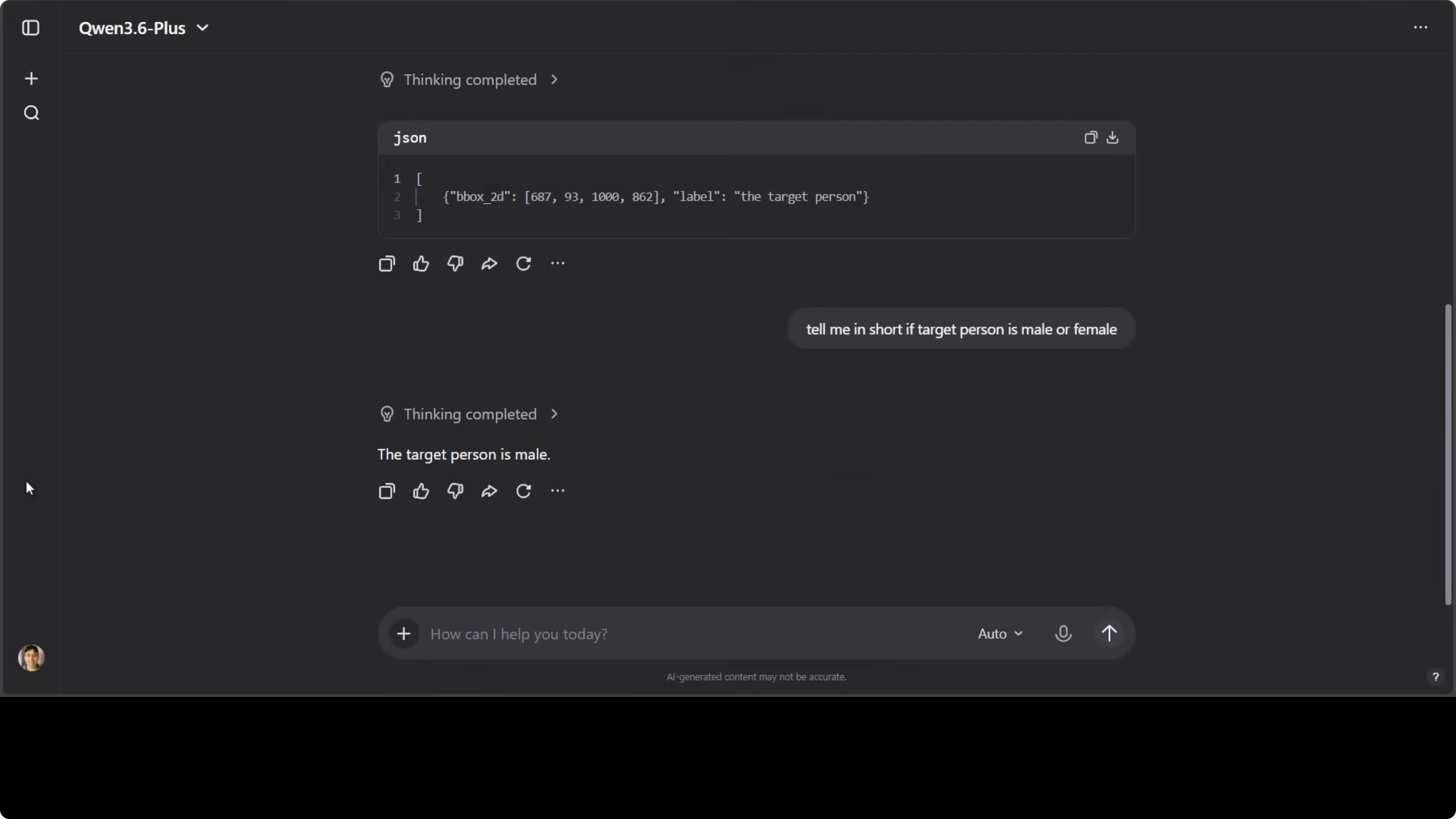
I pushed a follow-up classification.
Tell me in short if the target person is male or female.
It responded correctly with male for the target. This short classification often trips models, but Qwen 3.6 handled it cleanly. It is still advisable to treat such attributes with caution depending on policy constraints.
Handwritten OCR and interpretation
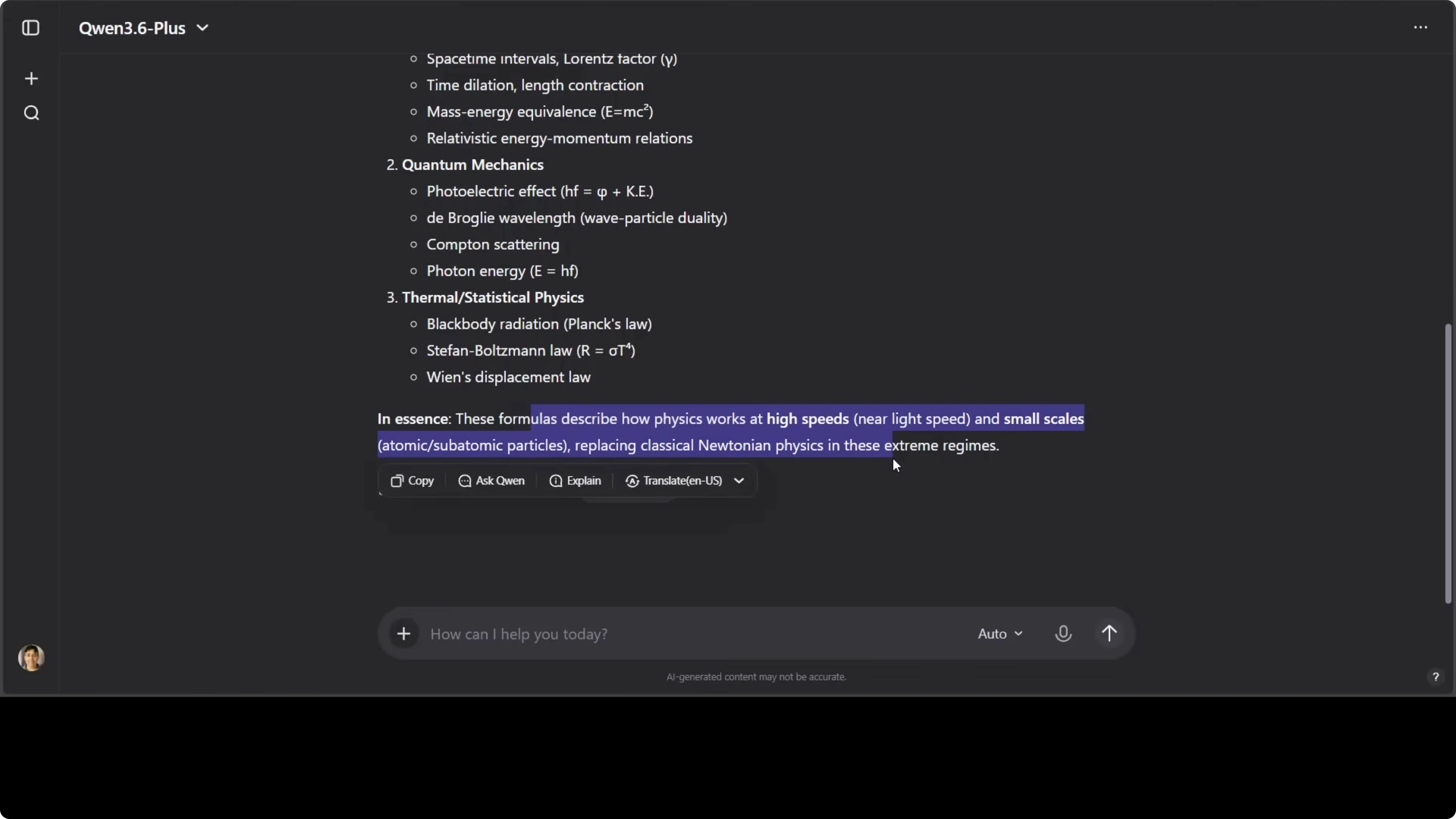
I tested OCR and concept recognition on a handwritten physics equation combined with math notation.
Extract the handwritten text and briefly describe the physics concept in the note.
The model identified modern physics topics like special relativity, quantum mechanics, and thermal statistical physics. The short summary aligned with the notations in the image. It handled noisy handwriting reasonably well.
Qwen3.6: Real-World Agents with 1M Context Explained - Video Understanding
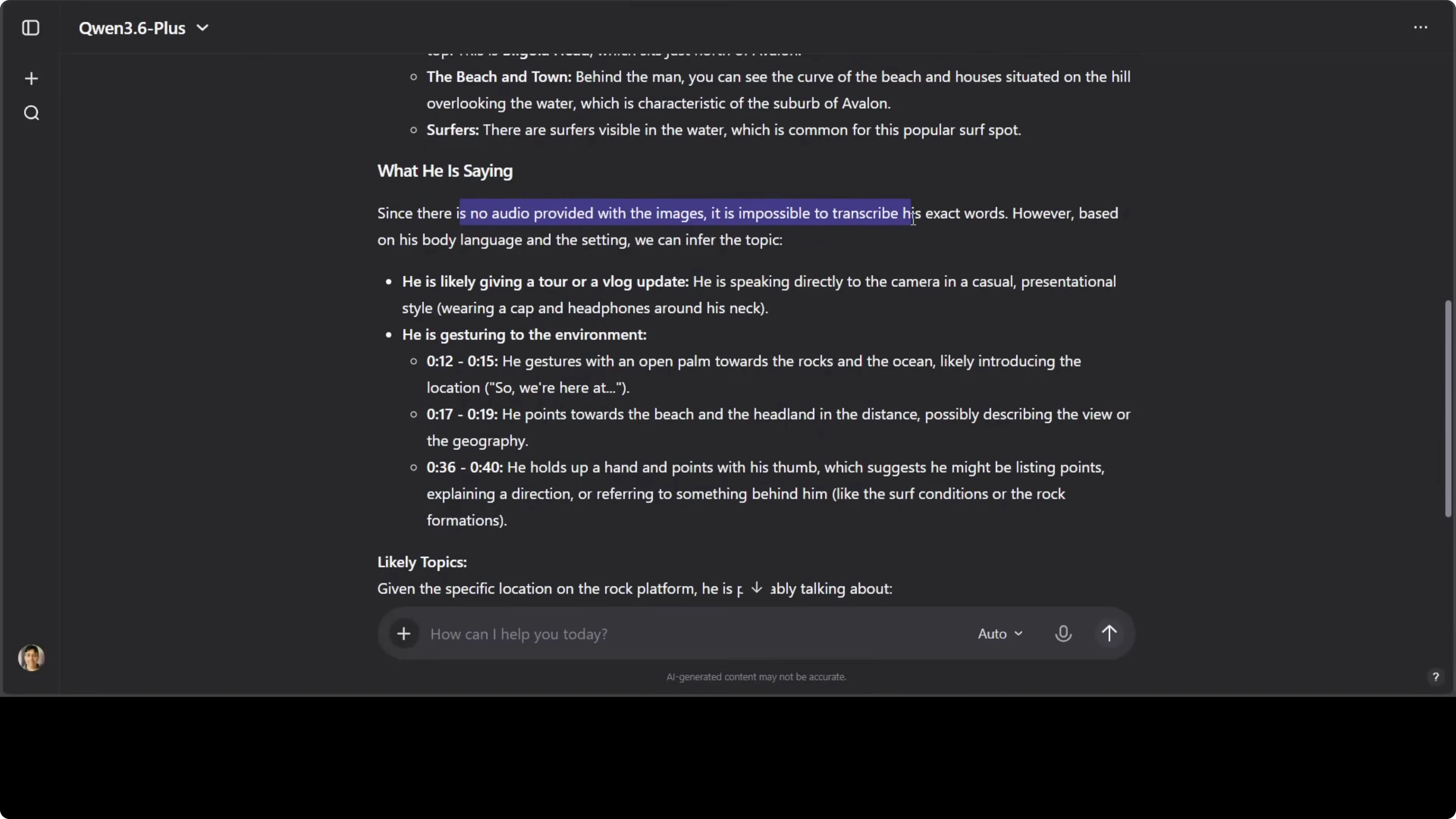
I provided a short vlog-style video clip and asked for location identification and speech transcription.
Identify the location shown in the video and summarize what the speaker is saying.
The model described northern beaches near Sydney but guessed Avalon Beach instead of Avoca Beach. It stated there was no audio provided and based its answer on video frames, suggesting it did not extract audio from the clip in this run. Gesture and scene descriptions were accurate, but the specific beach identification was wrong.

Qwen3.6: Real-World Agents with 1M Context Explained - Audio and Translation
I tested multilingual audio transcription and language identification.
Extract the transcript from the multilingual audio and identify the languages spoken.
The output showed signs of hallucination for language identification in this sample. Transcription quality varied by segment and language. This area still needs improvement, especially for short, code-switched clips.
I then ran a multilingual translation pass.
Translate this sentence into multiple languages: "Let peace prevail everywhere for everyone."
Most translations looked correct with a few mistakes in low-resource languages. Native speaker review is still recommended for production-quality localization. Qwen 3.6 is capable here, but quality depends on the target language.
Qwen3.6: Real-World Agents with 1M Context Explained - Benchmarks and Context Window
On agentic coding, tool use, and multimodal reasoning, Qwen 3.6 either leads or is close to top-tier models in reported tests. It beats Claude Opus 4.5 on several coding-agent tasks on SweepBench Verified according to the published numbers. For model-to-model comparisons, see this Claude Opus comparison and the full breakdown of Claude Opus 4.6.
The 1M token context enables full document suites, long codebases, and multi-turn memory for agents. The preserved thinking flag helps maintain chain integrity across steps. Combined with OpenClaw Cloud and Qwen Code compatibility, it fits into practical agent pipelines and coding workflows.
Qwen3.6: Real-World Agents with 1M Context Explained - Practical Setup Notes
If you plan to build autonomous assistants with messaging or desktop control, look into agent runners and orchestration. A helpful starting point is setting up controllable bots with AutoClaw agents on Windows. Qwen 3.6’s tool use and long-context benefits show up when paired with such frameworks.
For iterative coding tasks, keep prompts modular and reference previous artifacts explicitly. For multimodal chains, specify output schemas like JSON for bounding boxes, transcripts, or event logs. This reduces ambiguity and supports post-processing.
Qwen3.6: Real-World Agents with 1M Context Explained - Use Cases
Long-form document analysis for contracts, research papers, and policy archives benefits from the 1M context window. The model can keep track of cross-references, citations, and revisions across many pages. Pair it with schema-constrained outputs for reliable summaries and extraction.
Agentic coding with iterative refinement works well for scaffolding projects and executing test-driven edits. You can ask it to write end-to-end scripts, then request targeted fixes and feature additions while preserving prior reasoning. The preserved thinking flag helps sustain multi-step plans.
Multimodal review pipelines for images, handwritten notes, and short videos are feasible with structured prompts. Use it for OCR of forms, image matching, and initial video scene descriptions. Always validate sensitive attributes and consider human-in-the-loop for critical reviews.
Final Thoughts
Qwen 3.6 feels designed for real-world agents that carry context across complex, multi-turn tasks. Coding simulations, structured image reasoning, and document-heavy workflows are strong, while video geolocation and certain multilingual audio cases still need work. Open weights are not out yet, but the current capabilities already make it a serious candidate for agentic development stacks.
Subscribe to our newsletter
Get the latest updates and articles directly in your inbox.

Related Posts

8 Best Claude Code Plugins in 2026 (You Need to Know)
8 Best Claude Code Plugins in 2026 (You Need to Know)

7 Best Claude Code Skills (You Need to Know)
7 Best Claude Code Skills (You Need to Know)

Claude Code Desktop IDE Features (You Need to Know)
Claude Code Desktop IDE Features (You Need to Know)