
Table Of Content
- What is WildDet3D: Advancing Promptable 3D Detection in Real Scenes
- WildDet3D: Advancing Promptable 3D Detection in Real Scenes Overview
- WildDet3D: Advancing Promptable 3D Detection in Real Scenes Key Features
- How WildDet3D Works
- WildDet3D: Advancing Promptable 3D Detection in Real Scenes Use Cases
- Performance and Showcases
- The Technology Behind It
- Installation and Setup
- Download model weights
- Download checkpoint
- Clone the repository
- If you forgot --recu
- Try It Now
- Web demo in your browser
- iPhone app
- Dataset explorer
- More Real World Examples
- Why WildDet3D Matters

WildDet3D: Advancing Promptable 3D Detection in Real Scenes
Table Of Content
- What is WildDet3D: Advancing Promptable 3D Detection in Real Scenes
- WildDet3D: Advancing Promptable 3D Detection in Real Scenes Overview
- WildDet3D: Advancing Promptable 3D Detection in Real Scenes Key Features
- How WildDet3D Works
- WildDet3D: Advancing Promptable 3D Detection in Real Scenes Use Cases
- Performance and Showcases
- The Technology Behind It
- Installation and Setup
- Download model weights
- Download checkpoint
- Clone the repository
- If you forgot --recu
- Try It Now
- Web demo in your browser
- iPhone app
- Dataset explorer
- More Real World Examples
- Why WildDet3D Matters
What is WildDet3D: Advancing Promptable 3D Detection in Real Scenes
WildDet3D is a research project that can find and draw 3D boxes around objects in a single photo. You can guide it with short text like find the chair, by clicking a point, or by giving a 2D box. If you have a depth map from a phone or sensor, it can use that too for a big boost in quality.

It works across many places like rooms, streets, and outdoor scenes. It supports thousands of everyday object names. It is built to be easy to try on the web or on a phone.
WildDet3D: Advancing Promptable 3D Detection in Real Scenes Overview
WildDet3D brings open vocabulary 3D detection to real scenes. It predicts full 3D size, distance, and rotation for each object you ask for.
| Item | Details |
|---|---|
| Type | Research project for prompt based 3D object detection and a large open dataset |
| Purpose | Turn a single image into accurate 3D boxes guided by text, point, or box prompts |
| Inputs | One RGB image and optional depth map from LiDAR or other source |
| Prompts | Text query, point click, or 2D bounding box |
| Outputs | Full 3D bounding boxes with metric depth, dimensions, and six DoF orientation |
| Works Without Depth | Yes, and it gets even better when depth is present |
| Data | WildDet3D Data with over 1M images and 13.5K categories across 22 scene types |
| Demos | Web demo, iPhone app, dataset viewer, and model comparison izer |
| Model Weights | Available on Hugging Face for download |
| Status | Public website, demos live, model weights available, more code to be released |
If you want a gentle intro to 3D vision ideas, see this short explainer on Lhm 3D.
WildDet3D: Advancing Promptable 3D Detection in Real Scenes Key Features
-
Open vocabulary prompts. Ask for any object name and get 3D boxes that match your query.
-
Flexible inputs. Use a text prompt, a single click, or a 2D box. All three ways work.
-
Optional depth for a boost. If a depth map is present, the system gets a large jump in accuracy.
-
Full 3D output. Each result has distance, size, and rotation in metric units.
-
Works across many places. Trained with a very broad dataset over indoor, urban, and nature scenes.
-
Interactive use. Try it in a browser or on an iPhone with AR overlays.
How WildDet3D Works
At a high level, the system has two parts that read the image and the optional depth. These parts turn pixels and depth into strong features that carry both color and shape hints. A fusion step mixes in depth signals when they are present.
A single detector accepts your prompt. You can type a word, click a point, or draw a 2D box. The detector then predicts a final 3D box with depth, 3D size, and rotation.
If no depth is present, the model still runs in monocular mode. When depth is present, it adds clear gains across many tests.
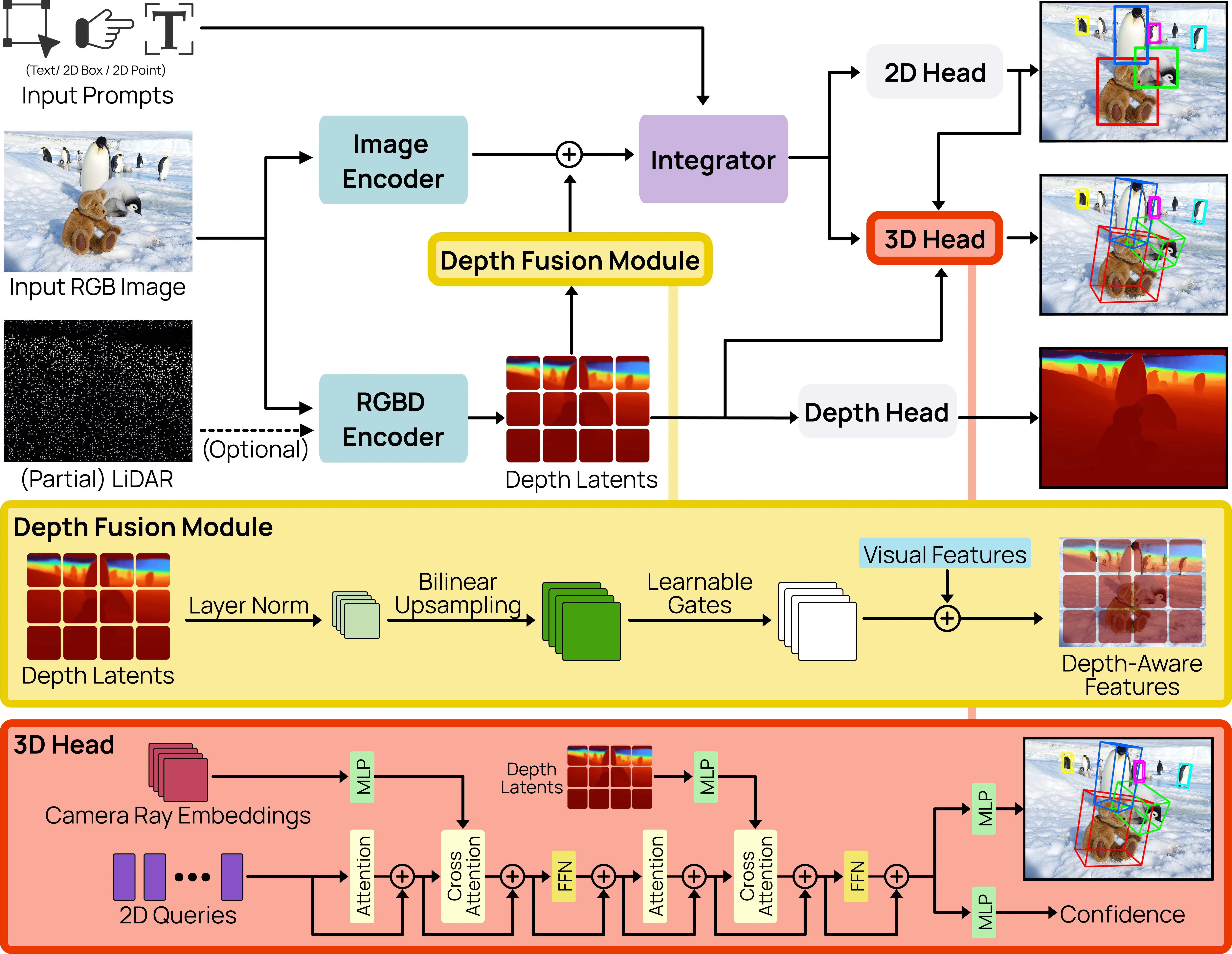
If you like learning about shape learning tools, this friendly guide on Dora 3D Shape Auto Encoder gives helpful context.
WildDet3D: Advancing Promptable 3D Detection in Real Scenes Use Cases
-
Web demo. Upload a photo, type a category, and see 3D boxes right away.
-
iPhone app. Use ARKit and LiDAR to get live 3D boxes that stick to the scene.
-
AR headsets. View boxes in passthrough mode and query by category.
-
Robotics. Send 3D boxes to a robot arm controller for grasp planning.
-
Video tracking. Track an object over time with zero shot setup.
-
Research and teaching. Compare models side by side and explore a huge dataset.
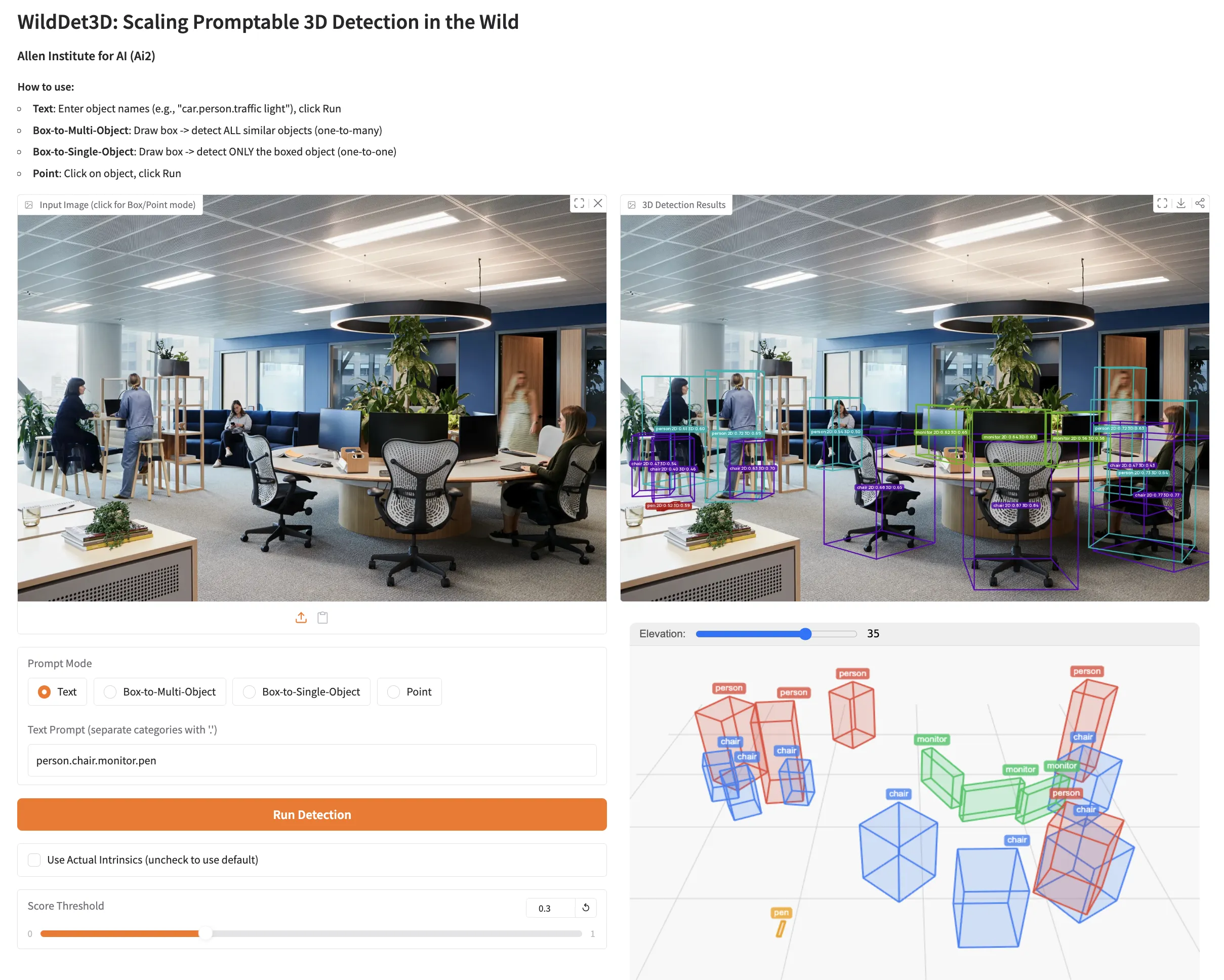
Performance and Showcases
WildDet3D shows strong results across many tests. On the open world WildDet3D Bench, it reports 22.6 and 24.8 AP3D dist with text and box prompts. On Omni3D, it reports 34.2 and 36.4 AP3D with text and box prompts.
In zero shot tests it reaches 40.3 and 48.9 ODS on Argoverse 2 and ScanNet. Adding depth at test time brings an average gain of about plus 20.7 AP across settings.

Showcase 1 — WildDet3D Video Demo This clip is the WildDet3D Video Demo. It shows how a single image and a prompt can produce clean 3D boxes in many scenes. Watch for results with and without depth cues.
Showcase 2 — WildDet3D iPhone Demo This is the WildDet3D iPhone Demo. It runs on device using ARKit with LiDAR so you can point your phone and see 3D boxes attached to real objects. You can also type a category or draw a box to guide it.
Showcase 3 — WildDet3D Dataset Viewer Here you can explore the WildDet3D Dataset Viewer. Browse over a million images and see verified 3D boxes across many categories and scenes. It is great for learning and quick checks.
Showcase 4 — WildDet3D Model Comparison izer Use the WildDet3D Model Comparison izer to compare predictions side by side. See how this model stacks up against other methods across the full benchmark. It makes model study easy.
The Technology Behind It
The model uses a prompt friendly detector that unifies text, point, and box inputs. A depth fusion step brings in shape cues when a depth map is given. A final 3D head predicts distance, size, and rotation.
The team also built WildDet3D Data. It has over 1M images, 13.5K categories, and 3.7M 3D boxes from 22 scene types. Labels are human checked to keep quality high.
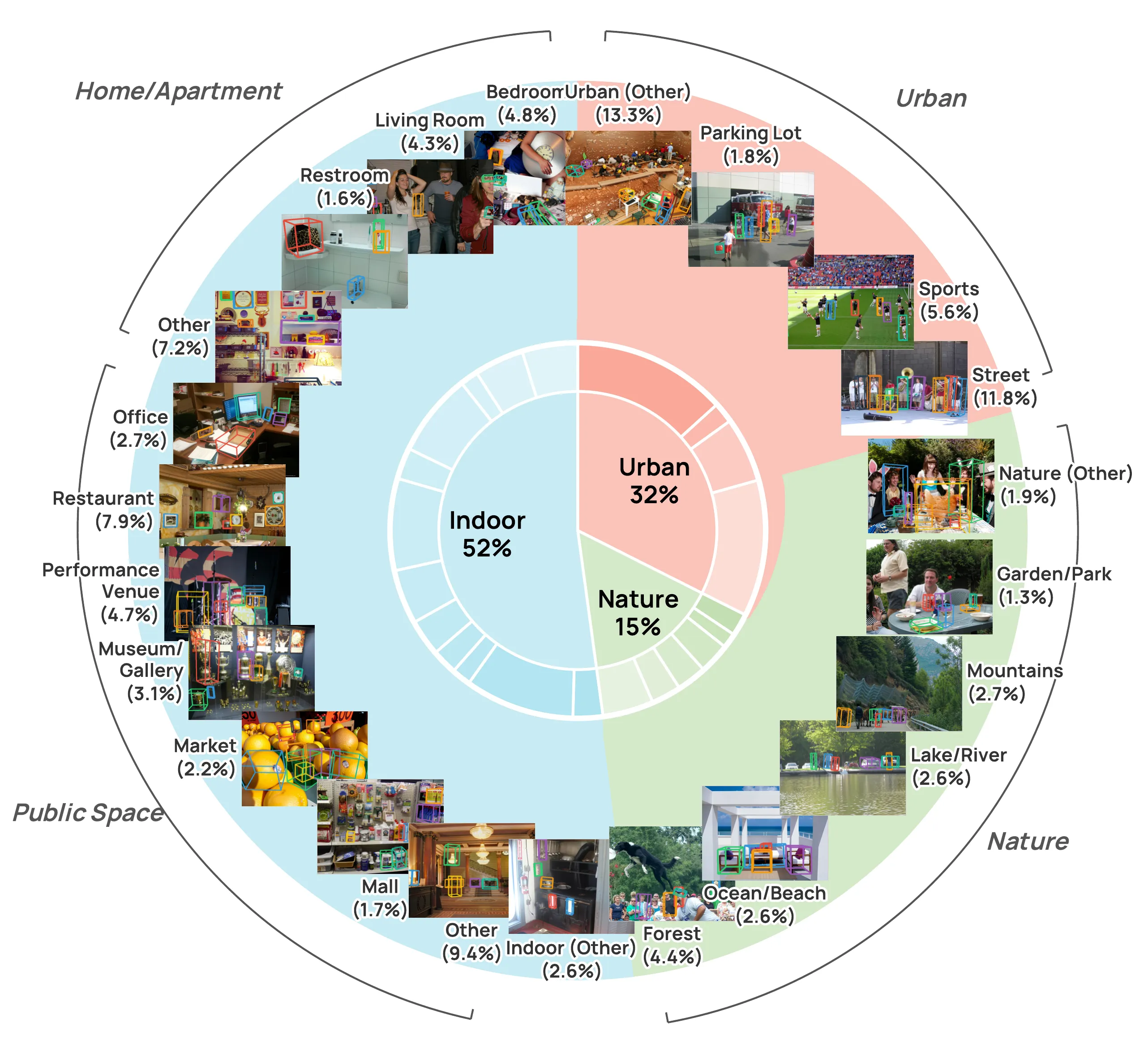
For another fun 3D method that turns simple inputs into 3D outputs, you might enjoy this clear read on the Diffsplat 3D Model Generator.
Installation and Setup
Here are the exact steps shared by the project to get model weights and clone the code.
Download model weights
# Download checkpoint
pip install huggingface_hub
huggingface-cli download allenai/WildDet3D wilddet3d_alldata_all_prompt_v1.0.pt --local-dir ckpt/Clone the repository
git clone --recurse-submodules https://github.com/allenai/WildDet3D.git
cd WildDet3D
# If you forgot --recuTip. The team notes that more code for inference and training will be released. Keep an eye on the GitHub page for updates.
Try It Now
Web demo in your browser
- Open the web demo on Hugging Face Spaces.
- Upload a photo from your computer.
- Type a text prompt like cup or draw a 2D box on the object.
- Press run and view the 3D boxes with depth and size.
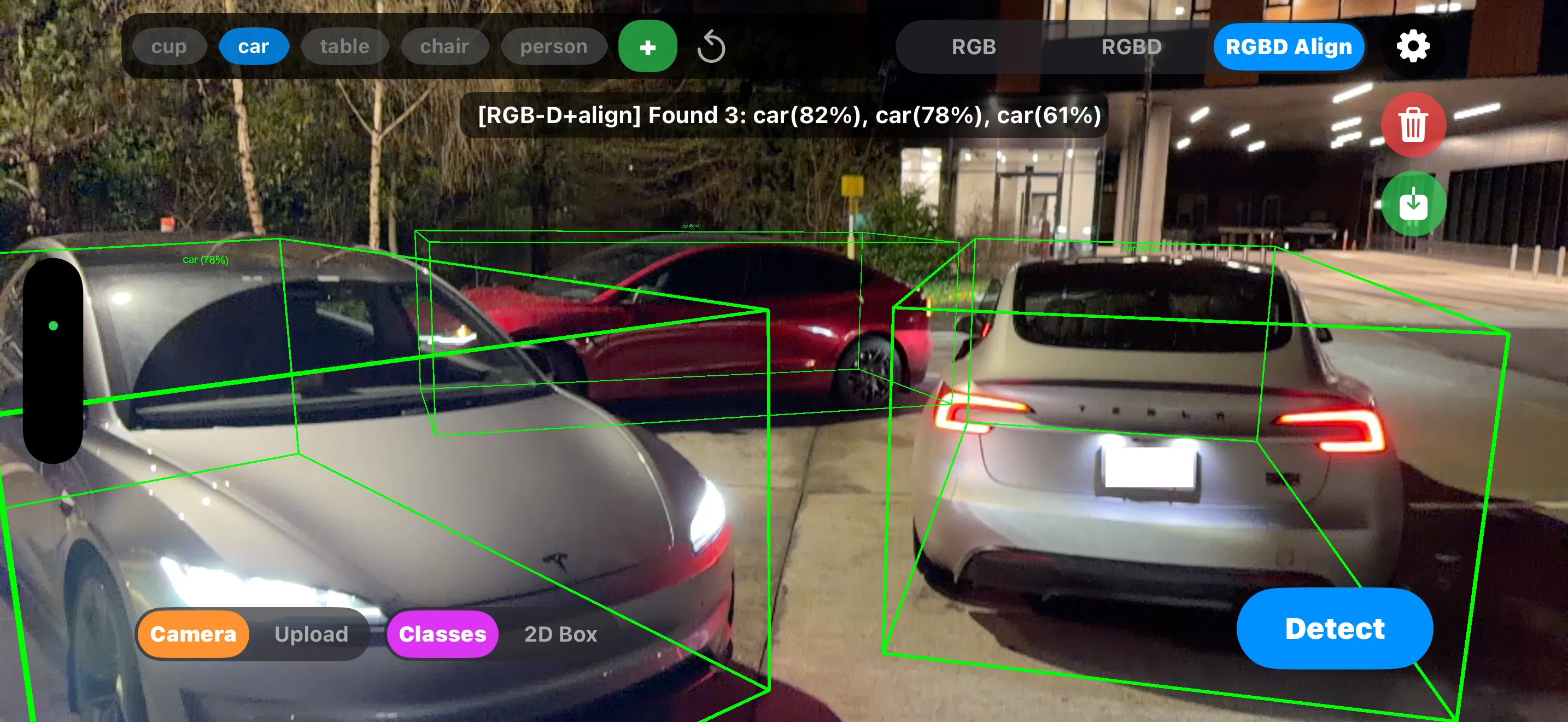
iPhone app
- Install the app build from the project page.
- Point your phone at the scene and let ARKit with LiDAR gather depth.
- Type a query or draw a box to guide the model. Watch boxes stick to the scene in real time.
Dataset explorer
- Open the dataset viewer from the website.
- Browse images across homes, streets, and nature scenes.
- Click to see 3D boxes and labels for each object category.
More Real World Examples
The system works in homes, offices, streets, and outdoor spots like parks or cafes. Text prompts can find chairs in a living room, cars on the road, or signs on a sidewalk. The same model can also lift 2D boxes into full 3D boxes.

If you want to compare design choices across 3D tools, a nice companion read is this guide on learning 3D with splats and this simple note on Lhm 3D.
Why WildDet3D Matters
It brings text and point based 3D detection into one clear workflow. This means faster iteration for apps in AR, robotics, and content creation. With the large dataset, it also covers far more categories than past 3D sets.
It works even when depth is not there, then gets a strong lift when depth is added. This makes it useful for both phones and pro hardware. You can start simple and grow over time.
Image source: WildDet3D: Advancing Promptable 3D Detection in Real Scenes
Subscribe to our newsletter
Get the latest updates and articles directly in your inbox.

Related Posts
Relit-LiVE: Enhancing Videos by Learning Environment Together
Relit-LiVE: Enhancing Videos by Learning Environment Together
CausalCine: Real-Time Video Narratives with Autoregression
CausalCine: Real-Time Video Narratives with Autoregression

DreamX-World: The Future of Interactive World Models
DreamX-World: The Future of Interactive World Models