
Table Of Content
- What is HunyuanOCR?
- HunyuanOCR Overview
- Architecture at a Glance
- HunyuanOCR Overview Table
- Key Features
- How to Use HunyuanOCR
- Prerequisites
- Step by Step Setup
- Tips for First Runs
- First Results: Structured Document With LaTeX
- Multilingual Text Extraction
- Hindi
- Arabic
- Polish
- Invoice Question Answering
- Handwriting With Crossed Out Words
- Flowchart Explanation
- Reported Benchmarks
- Historical Newspaper
- Blueprint and Floor Plan Reading
- Performance and Resource Use
- Practical Capabilities Observed
- Strong Areas
- Edge Cases and Caveats
- Step by Step Guide: Running OCR Locally
- Troubleshooting
- Why the Architecture Matters
- Reported Benchmarks Summary
- Use Cases That Fit Well
- What I Would Watch Next
- Conclusion

HunyuanOCR: Free Local OCR ,Here's how to install
Table Of Content
- What is HunyuanOCR?
- HunyuanOCR Overview
- Architecture at a Glance
- HunyuanOCR Overview Table
- Key Features
- How to Use HunyuanOCR
- Prerequisites
- Step by Step Setup
- Tips for First Runs
- First Results: Structured Document With LaTeX
- Multilingual Text Extraction
- Hindi
- Arabic
- Polish
- Invoice Question Answering
- Handwriting With Crossed Out Words
- Flowchart Explanation
- Reported Benchmarks
- Historical Newspaper
- Blueprint and Floor Plan Reading
- Performance and Resource Use
- Practical Capabilities Observed
- Strong Areas
- Edge Cases and Caveats
- Step by Step Guide: Running OCR Locally
- Troubleshooting
- Why the Architecture Matters
- Reported Benchmarks Summary
- Use Cases That Fit Well
- What I Would Watch Next
- Conclusion
Chinese research labs have poured serious effort into optical character recognition recently. After releases like DeepSeek OCR and Qwen-VL, HunyuanOCR arrived with a bold claim: strong accuracy, compact size, and a clean end to end design that runs locally.
In this article, I walk through the core architecture, installation, and hands on tests across multiple languages, invoices, handwriting, flowcharts, historical print, and blueprints. I also summarize the benchmarks reported by the authors and share practical notes on speed, memory usage, and edge cases I observed.
I ran HunyuanOCR on Ubuntu with a single Nvidia RTX A6000 with 48 GB VRAM. The model stayed lightweight in memory and felt snappy in real use.
What is HunyuanOCR?
HunyuanOCR is an open source OCR and document understanding model with about 1 billion parameters. It is designed as a single end to end system that reads text, understands layout, and produces structured output without external layout detectors, cropping, or post processing.
It combines a native resolution vision encoder, an adaptive connector that compresses visual tokens, and a compact language model with a positional method called XTRope. The result is a model that keeps image geometry intact, focuses on text rich regions, and follows page structure across complex layouts.
The authors have shared a simple script in the model card that performs OCR on a local image and prints the text. In local tests, the model downloaded in four shards, ran quickly, and consumed modest VRAM.
HunyuanOCR Overview
HunyuanOCR targets practical OCR tasks: plain text extraction, multilingual reading, layout sensitive pages, and light vision-language prompting like asking questions about an invoice or explaining a flowchart. It also handles long receipts, dense documents, and multi column pages without resizing images to a fixed aspect ratio.
Here is a concise overview of what I used and observed.
- System used: Ubuntu, Nvidia RTX A6000 48 GB
- Model size: about 1 billion parameters
- Components: native resolution ViT, adaptive MLP connector, 0.5B parameter language head with XTRope
- Shards: model downloaded in four parts
- Typical VRAM in my runs: about 3 GB
- Capabilities: OCR, multilingual text extraction and translation, layout understanding, document question answering
- Design: pure end to end OCR with no external layout detection or post processing
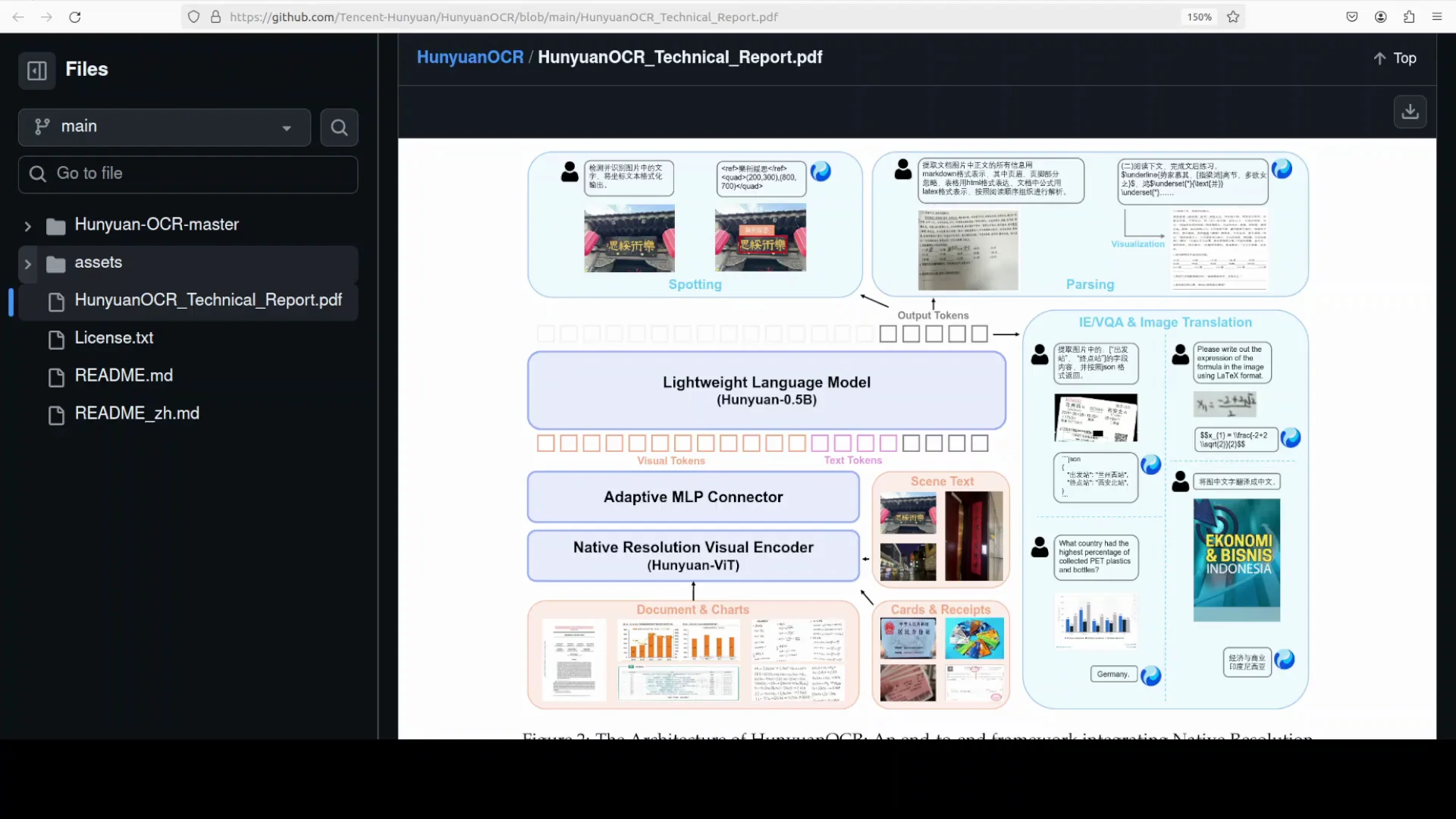
Architecture at a Glance
HunyuanOCR uses three key stages arranged end to end.
- Native resolution vision transformer
- Preserves the original aspect ratio of the input image
- Slices the image into patches while keeping full global attention
- Avoids distortions on long or dense documents
- Adaptive MLP connector
- Compresses thousands of visual tokens into a compact sequence
- Emphasizes text heavy regions and suppresses empty background
- Lightweight language model with XTRope
- About 0.5B parameters
- Positional method that tracks horizontal text flow, vertical layout, width, and even time
- Helps with reading order on complex pages and timing for subtitles
The result is a single pass OCR pipeline that keeps the data flow simple. There is no separate layout model or cropping routine. Everything happens in one model.
HunyuanOCR Overview Table
| Item | Details |
|---|---|
| Model name | HunyuanOCR |
| Type | Open source OCR and document understanding |
| Total parameters | About 1B |
| Vision backbone | Native resolution ViT with global attention |
| Connector | Adaptive MLP compressor |
| Language head | ~0.5B parameters with XTRope positional method |
| End to end | Yes - no external layout detector or post processing |
| Multilingual | Yes - handled Hindi, Arabic, Polish in tests |
| Typical VRAM in tests | About 3 GB |
| Download | Four shards |
| Tested OS and GPU | Ubuntu, Nvidia RTX A6000 48 GB |
| Tasks covered in tests | Text extraction, language identification, translation, invoice Q&A, handwriting, flowchart explanation, historical print, blueprint reading |
Key Features
-
End to end OCR pipeline
- No layout detector, cropping, or manual post processing
- Keeps reading order and layout intact
-
Native resolution encoding
- Maintains aspect ratio for long receipts and dense pages
- Preserves fine detail and reduces distortion
-
Adaptive token compression
- Focuses capacity on text heavy regions
- Reduces sequence length without discarding content
-
Language model with XTRope
- Tracks horizontal and vertical layout and width
- Handles multi column pages and subtitle timing
-
Multilingual support
- Read Hindi, Arabic, and Polish during testing
- Output included translation in some cases
-
Practical document reasoning
- Answered questions on invoices
- Explained flowcharts
- Interpreted floor plans and measurements
-
Compact and fast
- Around 1B parameters
- Low VRAM needs and quick responses in local runs
How to Use HunyuanOCR
Prerequisites
- System
- Ubuntu or a similar Linux environment
- Nvidia GPU recommended for speed
- Dependencies
- torch
- transformers
- accelerate
- Optional: gradio for a simple UI
- Hardware
- I ran it on an RTX A6000 48 GB
- VRAM usage in my tests was about 3 GB
Step by Step Setup
- Install Python dependencies
- Install torch and transformers
- If you see a missing accelerate error at runtime, install accelerate
- Get the provided script
- The model card includes a ready to run script that performs OCR on an image path
-
Configure the script
- Set the model name provided in the model card
- Provide a local image path
- Keep a simple system prompt if needed
- The script will tokenize, run inference with default hyperparameters, and print text
-
Run inference
- First run will download the model in four shards
- Expect quick inference once the weights are cached
-
Optional UI
- You can wrap the script with a simple Gradio interface
- File upload and a short prompt field are enough for testing images and questions
Tips for First Runs
- Keep an eye on VRAM during the first few large images
- If the runtime complains about missing accelerate, install it and re run
- For long or complex documents, leave the native resolution behavior intact to preserve layout fidelity
First Results: Structured Document With LaTeX
I started with a document containing LaTeX expressions and paragraphs. The model produced clean Markdown with correct numbering and hierarchy. Formatting held up well, and the reading order matched the source.
Speed was strong for a 1B parameter model. The first run included downloads, but subsequent runs were fast.
Multilingual Text Extraction
Hindi
I asked the model to extract all text and identify the language. It returned the text and language correctly. I do not read Hindi, but visual inspection showed minimal errors.
Arabic
On an Arabic image, the model returned the text and added a translation without being prompted for translation. This behavior was consistent across multiple runs. Output quality looked solid on visual checks.
Polish
A Polish image also came back clean. Text segmentation and accents looked correct, and line breaks followed the document reasonably well.
Invoice Question Answering
I passed an invoice image and asked for the amount due. The model returned 400 dollars promptly. For simple structured queries on invoices, the system felt reliable and quick.
Handwriting With Crossed Out Words
I tested a handwritten note with crossed out words. The model extracted most of the text but added extra numeric tokens that looked like coordinates or line references. Regenerating yielded the same pattern.
- Positives
- Core text recognition was acceptable
- Limitation observed
- Extra coordinate like numbers appeared in the output
- This noise repeated across attempts
For clean handwriting, I expect stronger results. For messy notes with edits, you may need manual cleanup after extraction.
Flowchart Explanation
I asked the model to read a flowchart with a small comedic slant and explain it step by step. It returned a structured summary that captured the decisions and branches and described the flow in a coherent way. Reading order and node relationships were preserved.
Reported Benchmarks
While that test was running, I reviewed the authors benchmarks. For its size, the numbers look strong.
-
OmniDocBench
- Score: 94.1
- Higher than models 4 to 8 times larger, including Qwen 3
-
Real world text spotting
- Score reported: 70.9
- Outperformed several commercial cloud OCR APIs in their tests
-
OCRBench VQA
- Score: 860
- Described as best in class under 3B parameters
-
Text image translation
- Score: 85.6
- Reported to exceed Gemini 1.5 Pro and others in their comparison
Notes:
- These results come from the authors materials
- Task definitions and exact setups matter, so treat them as directional rather than absolute
In my flowchart test, the model output aligned with the strengths implied by those numbers. It read the structure and offered a clear explanation that matched the content.
Historical Newspaper
I gave the model a very old newspaper scan and asked for the date and country. It returned the date correctly even though the print was hard to read. It did not provide the country initially, but on a follow up prompt, it responded with USA.
- Strength seen
- Date detection from degraded print
- Mixed result
- Country identification needed a follow up and remained uncertain
Historical scans often include noise, broken glyphs, and uneven contrast. The model held up well on the primary field and needed a nudge for the ancillary field.
Blueprint and Floor Plan Reading
I shared a blueprint style image with misspellings and artifacts. The model inferred that it was a floor plan, identified labeled areas, and extracted measurements from the layout. It even corrected some misspellings in its explanation, then summarized the layout and the purpose of each area.
This was a good stress test because the input contained visual noise and textual errors. The model still produced a usable description with functional labels and dimensions.
Performance and Resource Use
-
Model size and shards
- About 1B parameters
- Downloaded in four shards in my runs
-
VRAM footprint
- Around 3 GB during inference with the test images I used
-
Speed
- Fast on an RTX A6000
- Quick responses for both OCR and light question answering
-
Stability
- No crashes or slowdowns once dependencies were installed
- The only setup friction was a missing accelerate package on first run
For everyday workstations with a modern GPU, HunyuanOCR should run comfortably. The compact footprint is a strong practical advantage.
Practical Capabilities Observed
Strong Areas
- Clean OCR on standard documents
- Multilingual reading with correct language ID
- Inline translation on some languages
- Invoice Q&A with accurate numeric extraction
- Flowchart explanation with correct reading order
- Floor plan interpretation with functional labels and measurements
- Markdown style formatting on structured text pages
Edge Cases and Caveats
-
Handwriting with edits
- Extracted core text, but added extra numeric tokens that looked like coordinates
- Regenerating did not remove the noise in my tests
-
Historical scans
- Primary fields like dates were read well
- Secondary fields like country may need a follow up prompt
-
UI wrapper
- A quick Gradio wrapper is easy to set up, but ensure you restart the backend if you halt the model mid session
Step by Step Guide: Running OCR Locally
Follow these steps to reproduce my local setup.
-
Prepare the environment
- Use Ubuntu with an Nvidia GPU and up to date drivers
- Ensure Python and pip are installed
-
Install Python packages
- Install torch and transformers
- If accelerate is missing during the first run, install accelerate
-
Fetch the model script
- The model card provides a small script that:
- Accepts a model name
- Loads an image from a local path
- Applies a system prompt if needed
- Runs inference and prints the decoded text
- The model card provides a small script that:
-
Run the script
- Point it to your image file
- The first run downloads four model shards
- Subsequent runs are much faster
-
Check the output
- Verify formatting and reading order
- For invoices or forms, try asking direct questions
- For multilingual text, ask for language identification and translation
-
Optional UI in a few steps
- Add a Gradio upload box for images
- Add a text field for instructions like extract text and identify language
- Display the output in a text area
-
Monitor resources
- Expect about 3 GB of VRAM usage during typical OCR
- Keep large batch sizes low if you are tight on memory
Troubleshooting
-
Missing accelerate
- Symptom: runtime error mentioning accelerate
- Fix: install accelerate and re run
-
Slow first run
- Cause: downloading model shards
- Fix: wait for the initial download to complete
-
Unexpected tokens in handwriting
- Symptom: extra numeric tokens that look like coordinates
- Workaround: post process to remove numeric noise or re prompt for plain text only
-
Layout anomalies
- Symptom: mismatched reading order on irregular layouts
- Tip: keep native resolution intact and avoid external resizing
Why the Architecture Matters
The model’s three stage design aligns with the observed behavior in complex documents.
-
Native resolution helps with:
- Long receipts and narrow columns
- Fine glyphs in dense prints
- Mixed font sizes on one page
-
Adaptive compression helps with:
- Focusing on text heavy patches
- Reducing sequence length while keeping content
-
XTRope in the language head helps with:
- Following reading order across columns
- Handling vertical and horizontal flows
- Interpreting timed text like subtitles
Keeping the pipeline end to end avoided errors that usually come from brittle pre or post processing steps. I did not have to run a separate detector or a cropper, and the model still respected layout.
Reported Benchmarks Summary
The authors reported strong results relative to model size. Here is a clean summary of the numbers they shared.
| Benchmark | Score | Notes |
|---|---|---|
| OmniDocBench | 94.1 | Higher than models 4 to 8 times larger, including Qwen 3 |
| Real world text spotting | 70.9 | Outperformed several commercial cloud OCR APIs in their tests |
| OCRBench VQA | 860 | Described as best in class under 3B parameters |
| Text image translation | 85.6 | Reported to exceed Gemini 1.5 Pro and others |
As with any benchmark, setup and datasets matter. The on device results I saw for layout reading and multilingual extraction are consistent with strong benchmark claims.
Use Cases That Fit Well
- Batch OCR of documents where layout matters
- Multilingual text extraction from images and scans
- Financial documents like invoices where numeric Q&A is needed
- Technical pages with formula snippets and structured Markdown
- Flowcharts and diagrams that require explanatory text
- Floor plans or blueprints with labeled areas and measurements
If you often process PDFs and images locally and want a compact model that respects structure and reading order, HunyuanOCR is a good fit.
What I Would Watch Next
- Handwriting without numeric noise
- A post processing filter could help strip spurious tokens
- Noisy historical scans
- Additional denoising or contrast normalization might improve secondary fields
- Fine grained table extraction
- The model already handles table like content well; a small downstream parser could convert it to CSV or JSON reliably
Conclusion
HunyuanOCR brings a clean end to end approach to local OCR with a compact 1B parameter footprint. The native resolution vision encoder, adaptive connector, and XTRope language head work together to preserve layout, follow reading order, and handle complex pages without extra detectors or post processing.
Installation is straightforward with torch, transformers, and accelerate. The provided script makes first runs simple, and a light Gradio wrapper turns it into a quick testing UI. On an RTX A6000, VRAM usage hovered around 3 GB and inference felt fast.
In hands on tests, the model handled Hindi, Arabic, and Polish, answered questions on an invoice, explained a flowchart, extracted dates from a historical newspaper, and interpreted a floor plan with labels and measurements. The main limitation I saw was extra numeric noise on messy handwriting, which is manageable with cleanup.
Given the size, speed, and accuracy observed, HunyuanOCR is one of the strongest open source options you can run locally today for OCR and document understanding.
Subscribe to our newsletter
Get the latest updates and articles directly in your inbox.

Related Posts

8 Best Claude Code Plugins in 2026 (You Need to Know)
8 Best Claude Code Plugins in 2026 (You Need to Know)

7 Best Claude Code Skills (You Need to Know)
7 Best Claude Code Skills (You Need to Know)

Claude Code Desktop IDE Features (You Need to Know)
Claude Code Desktop IDE Features (You Need to Know)