
Table Of Content
- What is Hunyuan OCR?
- Hunyuan OCR Overview
- Benchmarks at a glance
- Why it matters
- Key Features
- End to end OCR model
- Lightweight with high performance
- Native-resolution visual encoder
- Adaptive token collector and compression
- Fast inference and low VRAM use
- XDRoPE for layout alignment and temporal sequences
- Unified multitask capabilities
- Massive multilingual data pipeline
- Four-stage pre-training and fine-tuning
- Designed for deployment
- How to Use Hunyuan OCR
- Step-by-step guide for the hosted demo
- Tips for better results
- Moving from demo to local or server use
- Architecture and Training Details
- Model components
- Long-context processing
- Instruction alignment and RL
- Multilingual and Multidomain Strength
- Language coverage
- Data diversity
- Performance Highlights
- Benchmarks and tasks
- Practical outcomes
- Deployment Notes
- Inference engine and memory
- Throughput and latency
- Operational simplicity
- Hunyuan OCR Summary
- Conclusion

Hunyuan OCR Outperforms PaddleOCR & DeepSeek (Open Source)
Table Of Content
- What is Hunyuan OCR?
- Hunyuan OCR Overview
- Benchmarks at a glance
- Why it matters
- Key Features
- End to end OCR model
- Lightweight with high performance
- Native-resolution visual encoder
- Adaptive token collector and compression
- Fast inference and low VRAM use
- XDRoPE for layout alignment and temporal sequences
- Unified multitask capabilities
- Massive multilingual data pipeline
- Four-stage pre-training and fine-tuning
- Designed for deployment
- How to Use Hunyuan OCR
- Step-by-step guide for the hosted demo
- Tips for better results
- Moving from demo to local or server use
- Architecture and Training Details
- Model components
- Long-context processing
- Instruction alignment and RL
- Multilingual and Multidomain Strength
- Language coverage
- Data diversity
- Performance Highlights
- Benchmarks and tasks
- Practical outcomes
- Deployment Notes
- Inference engine and memory
- Throughput and latency
- Operational simplicity
- Hunyuan OCR Summary
- Conclusion
A new OCR model has arrived that focuses entirely on reading and understanding text in images. Hunyuan OCR is open source, widely accessible, and it has set a new high bar for OCR accuracy and capability. In public benchmarks and practical tests, it consistently places first across core OCR tasks, multilingual recognition, and OCR-driven question answering.
The model weights are available on Hugging Face and GitHub. You can try it for free through a hosted demo and inspect the code and checkpoints for local or server deployment.
What is Hunyuan OCR?
Hunyuan OCR is an end to end OCR vision-language model designed to perform the entire OCR pipeline in a single forward pass. It detects and reads text, understands document structure, answers questions about the content, and translates, all within one model.
It is built on Hunyuan’s native multimodal architecture. The system brings together a visual encoder and a lightweight language model with an adapter, trained jointly to align vision and language. This design avoids the cumulative errors that often appear in multi-stage OCR stacks and makes deployment simpler.
Hunyuan OCR Overview
Hunyuan OCR stands out for its strong benchmark results, multilingual breadth, and practical deployment profile. The table below summarizes the essentials.
| Aspect | Summary |
|---|---|
| Type | End to end OCR vision-language model |
| Open source availability | Weights and code on Hugging Face and GitHub |
| Parameter scale | About 1B parameters in total |
| Language coverage | 130+ languages |
| Training data scale | About 200M image-text pairs |
| Context length | Up to 32k tokens for long documents |
| Key modules | Visual encoder, lightweight language model, MLP adapter, adaptive token collector, XDRoPE positional system |
| Core tasks | Text spotting, document parsing, OCR-based QA, information extraction, image-to-text translation, video subtitle extraction |
| Aspect ratio support | Arbitrary ratios at native resolution without text distortion |
| Inference | vLLM-based engine, fast, low VRAM footprint |
| Benchmark status | Leads across OCR, translation, information extraction, and multi-scene OCR tasks |
| Access | Free interactive demo hosted on Hugging Face |
Benchmarks at a glance

- Consistently tops OCR leaderboards against popular systems such as PaddleOCR and DeepSeek OCR.
- Strong results on OmniDoc-style evaluations, multi-scene OCR benchmarks, and translation-oriented OCR tests.
- Leads in information extraction and OCR-based question answering.
Why it matters
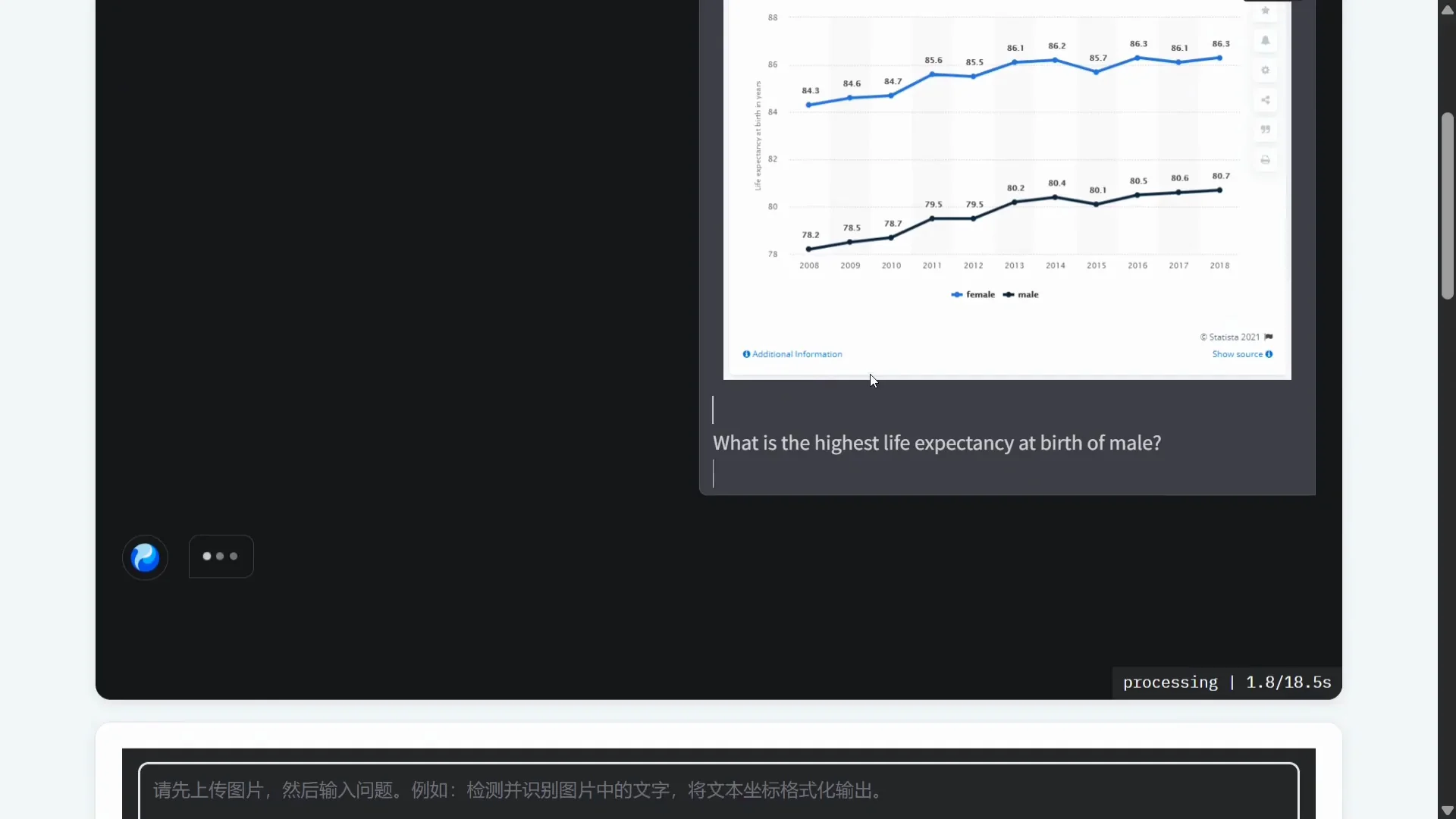
- One pass OCR reduces error accumulation.
- Native-resolution vision processing preserves fine text details.
- Low VRAM needs make local deployment practical on consumer GPUs.
Key Features

End to end OCR model
Hunyuan OCR executes the full OCR workflow within a single model pass. This avoids handoffs between separate detectors, recognizers, and parsers.
- Text spotting
- Document parsing
- Information extraction
- OCR-based question answering
- Image to text translation
This integrated approach improves consistency and simplifies deployment and maintenance.
Lightweight with high performance
The model totals about 1B parameters. It combines a visual transformer, a lightweight language model, and an MLP adapter into a compact yet strong system.
- High accuracy across diverse OCR tasks
- Competitive speed during inference
- A balance of quality and resource use suitable for production
Native-resolution visual encoder
The visual encoder operates at native resolution and supports arbitrary aspect ratios. Input images do not need to be forced into a fixed shape that distorts text.
- Robust handling of 16:9, 9:16, 4:3, 1:1, and other ratios
- Better long-text recognition due to preserved character shapes
- Improved performance on low-quality or compressed documents
Adaptive token collector and compression
An adaptive module compresses high-resolution visual tokens while preserving text-dense regions. It removes visual redundancy and forms compact sequences for the language model.
- Keeps critical text details
- Reduces computation and memory
- Enables longer contexts without losing important content
Fast inference and low VRAM use
Optimizations across the visual and language stacks enable quick responses with modest GPU memory. This profile supports local testing and production serving without high-end hardware.
- Efficient token compression
- Practical batch sizes on consumer GPUs
- Smooth handling of long pages and multi-page inputs
XDRoPE for layout alignment and temporal sequences
Hunyuan OCR applies a multi-dimensional positional scheme, often described as XDRoPE, to align tokens with complex layouts. It also extends to temporal sequences for subtitles.
- Strong understanding of page structure
- Cross-page reasoning for multi-page documents
- Processing of time-aligned content such as video subtitles
Unified multitask capabilities
A single checkpoint covers a wide range of OCR tasks:
- Text spotting and recognition
- Document layout parsing
- OCR-based question answering
- Information extraction
- Image-to-text translation
- Video subtitle extraction
This unification removes the need to stitch together different systems for each task.
Massive multilingual data pipeline
The training pipeline covers more than 130 languages and uses large-scale paired data.
- About 200M image-text pairs
- Nine domain categories to cover varied content types
- Rich synthetic paragraphs to balance real-world data
- Realistic wrapping and lighting to improve robustness
- Automatic QA generation to support OCR-based Q&A
Multilingual scope and diverse data sources help the model read and reason across scripts, fonts, and layouts.
Four-stage pre-training and fine-tuning
The training strategy builds alignment, long-context strength, and instruction following.
- Vision-language alignment
- Full multimodal joint learning
- 32k long context training
- Instruction-aligned SFT
Additional reinforcement learning with variable rewards targets both exact-answer and open-ended tasks.
- RLVR for tasks that require precise answers
- LM-as-judge for open-ended responses
Designed for deployment
Hunyuan OCR is prepared for real-world serving with a vLLM-based inference engine and careful token compression.
- Optimized for speed and memory
- Small GPU footprint relative to its accuracy level
- Suitable for consumer-grade GPUs and cloud hosts
How to Use Hunyuan OCR
Step-by-step guide for the hosted demo
- Open the hosted Hunyuan OCR demo on Hugging Face.
- Upload an image that contains text, a document page, a form, a chart, or subtitles.
- Enter a prompt that describes what you want, such as reading a section, extracting fields, translating text, or answering a question about the content.
- Submit the request to receive the result. You can repeat with different prompts or images to test other capabilities.
- Try multilingual inputs and complex layouts to assess recognition and reasoning across languages and page structures.
Tips for better results
- Provide clear prompts, especially for structured extraction or translation.
- For multi-page documents, indicate the target page or section to focus the answer.
- For subtitles or time-based content, specify the time range if needed.
Moving from demo to local or server use
- Download model weights from Hugging Face or GitHub.
- Serve with the vLLM-based engine for fast inference.
- Allocate sufficient VRAM for your target batch size and document length.
Architecture and Training Details
Model components
- Visual encoder operating at native resolution
- Lightweight language model tuned for OCR tasks
- MLP adapter bridging vision and language features
- Adaptive token collector to compress high-resolution tokens
- XDRoPE positional mechanism for layout and temporal alignment
These parts work together to read, structure, and interpret text-heavy inputs of varying size and layout.
Long-context processing
Training includes long-context sequences up to 32k tokens, which supports large documents and multi-page reasoning.
- Reduced truncation in lengthy documents
- Better continuity across sections and pages
- Stronger performance on structured and unstructured long texts
Instruction alignment and RL
Instruction tuning helps the model follow prompts for extraction, translation, and Q&A. Reinforcement learning introduces reward signals tailored to the type of task.
- Exact-answer supervision for deterministic outputs
- Judged scoring for open-ended outputs
- Balanced training for a broad set of OCR tasks
Multilingual and Multidomain Strength
Language coverage
- 130+ languages across scripts and writing systems
- Flexible processing of mixed-language documents
- Robust handling of multilingual pages and annotations
Data diversity
- Nine domain categories to widen coverage
- Synthetic and real-world images to balance variety and realism
- Automatic QA pairs to ground OCR-driven question answering
This breadth supports recognition and reasoning across forms, receipts, reports, signage, charts, and more.
Performance Highlights
Benchmarks and tasks
- Leads across OCR benchmarks in recognition accuracy
- Strong results in multi-scene OCR evaluations
- Top-tier results in translation-centric OCR tests
- State-of-the-art information extraction from images and documents
Practical outcomes
- Accurate reading of small fonts, curved text, and varied typography
- Reliable structure extraction for layout-heavy documents
- Strong OCR-based question answering over charts, tables, and forms
These gains show up in both benchmark scores and real tasks.
Deployment Notes
Inference engine and memory
- vLLM-based inference for speed
- Token compression to keep memory use in check
- Supports consumer GPUs for local testing and production
Throughput and latency
- Fast responses for single-page and multi-page inputs
- Scales with batch size and context length choices
- Works well with modern GPU instances and on-prem setups
Operational simplicity
- A single model covers many OCR tasks
- Less glue code than multi-stage pipelines
- Easier scaling and maintenance
Hunyuan OCR Summary
- End to end OCR model that completes spotting, parsing, extraction, Q&A, and translation in one pass.
- Open source, with weights available on Hugging Face and GitHub.
- About 1B parameters with a visual encoder, a lightweight language model, and an MLP adapter.
- Native-resolution vision processing for arbitrary aspect ratios with no text distortion.
- Adaptive token collector to compress high-resolution tokens while preserving text-dense regions.
- XDRoPE positional scheme for layout alignment, cross-page reasoning, and subtitle sequences.
- 130+ languages trained over about 200M image-text pairs across nine domains.
- Long-context training up to 32k tokens for large documents.
- Instruction alignment and reinforcement learning with variable rewards.
- vLLM-based inference, optimized token compression, and low VRAM needs.
- State-of-the-art performance across OCR recognition, translation, and information extraction.
- Unified multitask coverage in a single checkpoint.
Conclusion
Hunyuan OCR sets a new standard for practical OCR. It outperforms popular systems such as PaddleOCR and DeepSeek OCR across key benchmarks, handles multilingual and long-document scenarios, and runs efficiently. With open weights, a free hosted demo, and a deployment-friendly design, it is well positioned for real-world OCR tasks across recognition, parsing, extraction, Q&A, translation, and subtitles.
Subscribe to our newsletter
Get the latest updates and articles directly in your inbox.

Related Posts

8 Best Claude Code Plugins in 2026 (You Need to Know)
8 Best Claude Code Plugins in 2026 (You Need to Know)

7 Best Claude Code Skills (You Need to Know)
7 Best Claude Code Skills (You Need to Know)

Claude Code Desktop IDE Features (You Need to Know)
Claude Code Desktop IDE Features (You Need to Know)