
Table Of Content
- What is StdGEN?
- StdGEN Overview:
- Key Features of StdGEN
- Core Technology Behind StdGEN
- Semantic-aware Large Reconstruction Model (S-LRM)
- Differentiable Multi-layer Semantic Surface Extraction
- Additional Enhancements
- Performance and Benchmarking
- StdGEN Method Overview
- Step 1: Input Image Processing
- Step 2: 3D Reconstruction via S-LRM
- Step 3: Semantic Decomposition
- Step 4: Part-wise Refinement
- How to Use StdGEN on HuggingFace?
- **Step 1: Upload a Reference Image**
- **Step 2: Generate Multi-view Images**
- **Step 3: Reconstruct the 3D Character**
- Conclusion

StdGEN: Semantic-Decomposed 3D Character Generation from Single Images
Table Of Content
- What is StdGEN?
- StdGEN Overview:
- Key Features of StdGEN
- Core Technology Behind StdGEN
- Semantic-aware Large Reconstruction Model (S-LRM)
- Differentiable Multi-layer Semantic Surface Extraction
- Additional Enhancements
- Performance and Benchmarking
- StdGEN Method Overview
- Step 1: Input Image Processing
- Step 2: 3D Reconstruction via S-LRM
- Step 3: Semantic Decomposition
- Step 4: Part-wise Refinement
- How to Use StdGEN on HuggingFace?
- **Step 1: Upload a Reference Image**
- **Step 2: Generate Multi-view Images**
- **Step 3: Reconstruct the 3D Character**
- Conclusion
In this article, I will introduce StdGEN, a pipeline designed to generate semantically decomposed, high-quality 3D characters from a single image. This method is useful for various applications, including virtual reality, gaming, and filmmaking.
Previous approaches, which face challenges in decomposability, quality, and optimization time, StdGEN provides detailed 3D character generation with separate semantic components, such as the body, clothes, and hair, within just three minutes.
What is StdGEN?
StdGEN is an AI-based tool that converts a single reference image into a structured 3D character. It processes the image through three stages: generating an A-pose image, creating multi-view renders, and reconstructing a semantically-aware 3D model. StdGEN helps in 3D character creation for animation, gaming, and virtual environments.

StdGEN Overview:
| Detail | Description |
|---|---|
| Name | StdGEN - Semantic-Decomposed 3D Character Generation |
| Purpose | AI-based tool for generating semantically decomposed 3D characters |
| Official Website | stdgen.github.io/ |
| Paper | arxiv.org/abs/2411.05738 |
| GitHub Repository | github.com/hyz317/StdGEN |
| Demo | huggingface.co/spaces/hyz317/StdGEN |
Key Features of StdGEN
- Semantic Decomposability – The method separates different elements like body, clothing, and hair.
- Efficiency – Generates a fully detailed 3D character in three minutes.
- High Quality – Ensures superior geometry, texture, and decomposability compared to existing methods.
Core Technology Behind StdGEN
Semantic-aware Large Reconstruction Model (S-LRM)
At the heart of StdGEN is S-LRM, a transformer-based model designed to reconstruct geometry, color, and semantics from multi-view images. Unlike traditional approaches, S-LRM processes the input in a feed-forward manner, making it both effective and efficient.
Differentiable Multi-layer Semantic Surface Extraction
To obtain high-quality meshes, a multi-layer surface extraction scheme is applied. This scheme works with hybrid implicit fields reconstructed by S-LRM, ensuring precise semantic decomposition.
Additional Enhancements
- Multi-view Diffusion Model – Generates high-fidelity multi-view images for enhanced character reconstruction.
- Iterative Multi-layer Surface Refinement Module – Improves the final 3D character model’s overall quality.
Performance and Benchmarking
Extensive experiments highlight StdGEN's effectiveness in generating 3D anime characters. The results show that StdGEN outperforms previous methods significantly in terms of:
- Geometry Quality – Produces highly detailed and accurate 3D models.
- Texture – Ensures realistic and visually appealing textures.
- Semantic Decomposability – Achieves superior separation of different elements in the character model.
StdGEN Method Overview
Step 1: Input Image Processing
- A single reference image serves as the input.
- Multi-view diffusion models generate RGB and normal maps from the given image.
Step 2: 3D Reconstruction via S-LRM
- S-LRM processes the generated multi-view images.
- It reconstructs color, density, and semantic fields.
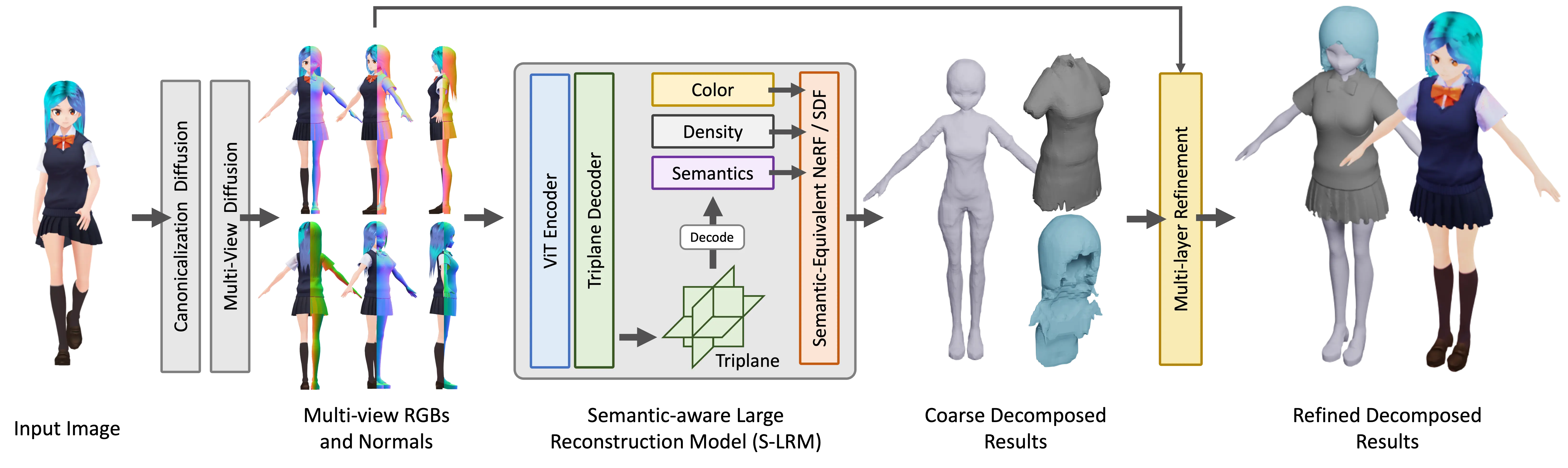
Step 3: Semantic Decomposition
- The method separates different character components, such as clothing and hair.
Step 4: Part-wise Refinement
- The model refines each decomposed component to ensure high quality.
- The final result is a detailed, semantically structured 3D character.
Here's a step-by-step guide on how to use StdGEN on the Hugging Face platform to generate 3D characters from a single image.
How to Use StdGEN on HuggingFace?
StdGEN is a tool designed to convert a single image into a semantically decomposed 3D character. The process involves three main steps: converting a reference image to an A-pose image, generating multi-view images, and reconstructing the final 3D model.
Step 1: Upload a Reference Image
- Open the StdGEN demo on Hugging Face.
- In the "Reference Image to A-pose Image" section, click the "Click to Upload" button or drag and drop an image.
- You can also choose from the sample images provided at the bottom of the section.
- Set the Seed Value (optional) to control the randomness of the generated A-pose image.
- Click the "Convert" button to process the image.
After processing, an A-pose version of the character will appear in the second section.
Step 2: Generate Multi-view Images
- The generated A-pose image will automatically be placed in the "Multi-view Generation" section.
- If needed, you can also upload an A-pose image manually.
- Choose a sample A-pose image if you prefer using a predefined character.
- Set a Seed Value (optional) for better control over the output.
- Click "Generate Multi-view Images" to create different viewing angles of the character.
This step is essential for reconstructing a 3D model with accurate details.
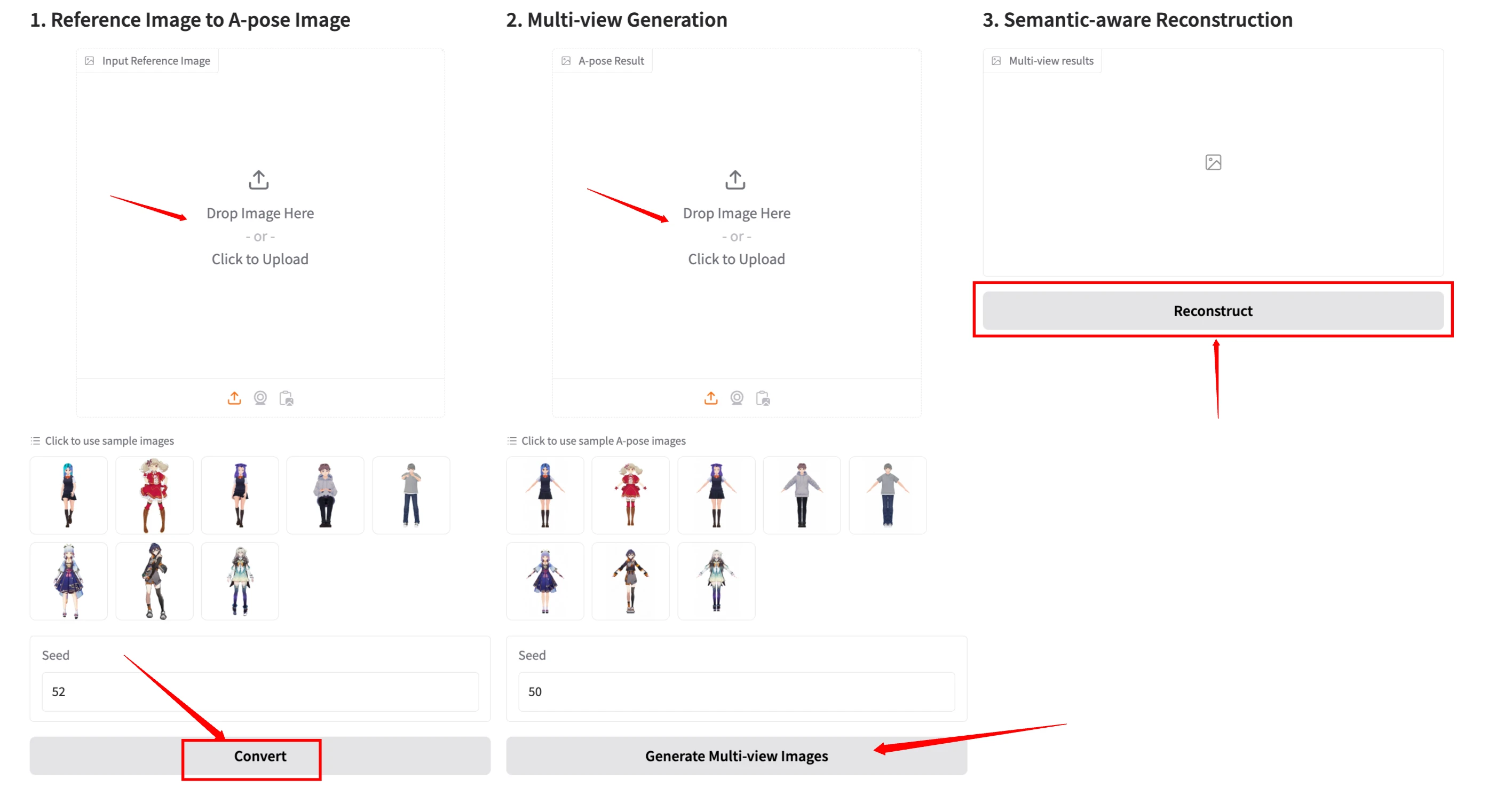
Step 3: Reconstruct the 3D Character
- The generated multi-view images will be used for the final 3D reconstruction.
- In the "Semantic-aware Reconstruction" section, review the uploaded multi-view images.
- Click "Reconstruct" to generate a 3D model with distinct body parts (hair, clothes, body, etc.).
Once completed, the reconstructed 3D model will be available for further customization or export.
Conclusion
StdGEN sets a new standard in 3D character generation by providing a fast, high-quality, and semantically decomposed output from just a single image. This technology paves the way for broader applications in virtual environments, gaming, and digital content creation.
Subscribe to our newsletter
Get the latest updates and articles directly in your inbox.

Related Posts

8 Best Claude Code Plugins in 2026 (You Need to Know)
8 Best Claude Code Plugins in 2026 (You Need to Know)

7 Best Claude Code Skills (You Need to Know)
7 Best Claude Code Skills (You Need to Know)

Claude Code Desktop IDE Features (You Need to Know)
Claude Code Desktop IDE Features (You Need to Know)