
Table Of Content
- What is LongLive?
- Overview of LongLive
- Key Features of LongLive
- How LongLive works?
- Causal AR design with KV refresh
- Attention scheme and long-range coherence
- Training–inference alignment and streaming
- How to use LongLive
- Prerequisites
- Step-by-step setup
- Running single-prompt inference
- Running interactive multi-prompt inference
- Performance and hardware observations
- Results and observations
- Single-prompt runs
- Human-focused prompts
- Interactive multi-scene stitching
- Non-human object test
- FAQs
- Conclusion

NVIDIA LongLive: Real-Time Interactive Long Video
Table Of Content
- What is LongLive?
- Overview of LongLive
- Key Features of LongLive
- How LongLive works?
- Causal AR design with KV refresh
- Attention scheme and long-range coherence
- Training–inference alignment and streaming
- How to use LongLive
- Prerequisites
- Step-by-step setup
- Running single-prompt inference
- Running interactive multi-prompt inference
- Performance and hardware observations
- Results and observations
- Single-prompt runs
- Human-focused prompts
- Interactive multi-scene stitching
- Non-human object test
- FAQs
- Conclusion
NVIDIA has released LongLive, a frame-level autoregressive model built for real-time, interactive long video generation. It avoids slow diffusion pipelines and attention-limited designs by adopting a causal approach customized for minute-long sequences and responsive prompting.
In this article, I walk through the local setup I used, explain the core design choices, run the provided inference scripts, and share results across single-prompt, multi-prompt, and object-focused tests. I also include VRAM observations, performance notes, and practical guidance on prompts, scene stitching, and output handling.
What is LongLive?
LongLive is a 1.3B-parameter video generator designed to produce coherent, minute-scale videos with interactive controls. It operates frame by frame, maintaining temporal consistency through a causal AR (autoregressive) design. Instead of brute-force diffusion or global attention that degrades with length, it keeps inference responsive with mechanisms tuned for streaming and prompt changes.
The model was tuned for stability across long sequences (approx. 32 GPU-days), can run locally, and supports both single-prompt and multi-prompt workflows. On a single H100 GPU, it can target multiple minutes of video at around 20–25 frames per second, with the ability to adjust prompts across segments.
Overview of LongLive
| Item | Details |
|---|---|
| Model type | Frame-level autoregressive (causal AR) |
| Parameters | ~1.3B |
| Base model | VAN 2.1 (text-to-video) |
| Adaptation | LoRA (weights frozen + low-rank fine-tuning) |
| Intended usage | Real-time, interactive long video generation |
| Target duration | Up to ~4 minutes on a single H100 |
| Inference speed | ~20–25 FPS on H100 (per the provided guidance) |
| Training/inference alignment | Streaming-long tuning for stable long-form performance |
| Prompting modes | Single prompt and interactive multi-prompt (JSONL) |
| Hardware tested | A100/H100 for long videos |
| VRAM consumption (observed) | ~20–40 GB depending on sequence and cache growth |
Key Features of LongLive
-
Causal frame-level generation:
- Produces videos one frame at a time, preserving temporal structure over long sequences.
- Keeps inference responsive and compatible with interactive inputs.
-
KV refresh for prompt changes:
- A mechanism to refresh cached states when the prompt shifts, aiding smooth transitions without breaking coherence.
-
Attention strategy for long-range consistency:
- Short-window attention combined with a frame-level synchronization that maintains global coherence while keeping runtime fast.
-
Streaming-long tuning:
- Aligns the model’s training with how it’s used at inference time, improving stability for minutes-long outputs.
-
Efficient fine-tuning:
- LoRA adaptation over a VAN 2.1 base, enabling a compact release and manageable downloads.
-
Practical throughput:
- On a single H100, you can aim for multi-minute outputs at ~20–25 FPS; local generation typically runs at practical speeds for minute-scale content.
-
Local workflow:
- Ships with inference scripts, supports single-prompt and multi-prompt JSONL scene stitching, and organizes outputs into predictable directories.
Before exploring the architecture, I initiated the local setup on Ubuntu with an H100 (80 GB VRAM). While the model itself is ~1.3B parameters, long video generation requires KV caching, so A100/H100-class GPUs are recommended for the longest sequences. During generation, I monitored VRAM as the cache built up.
How LongLive works?
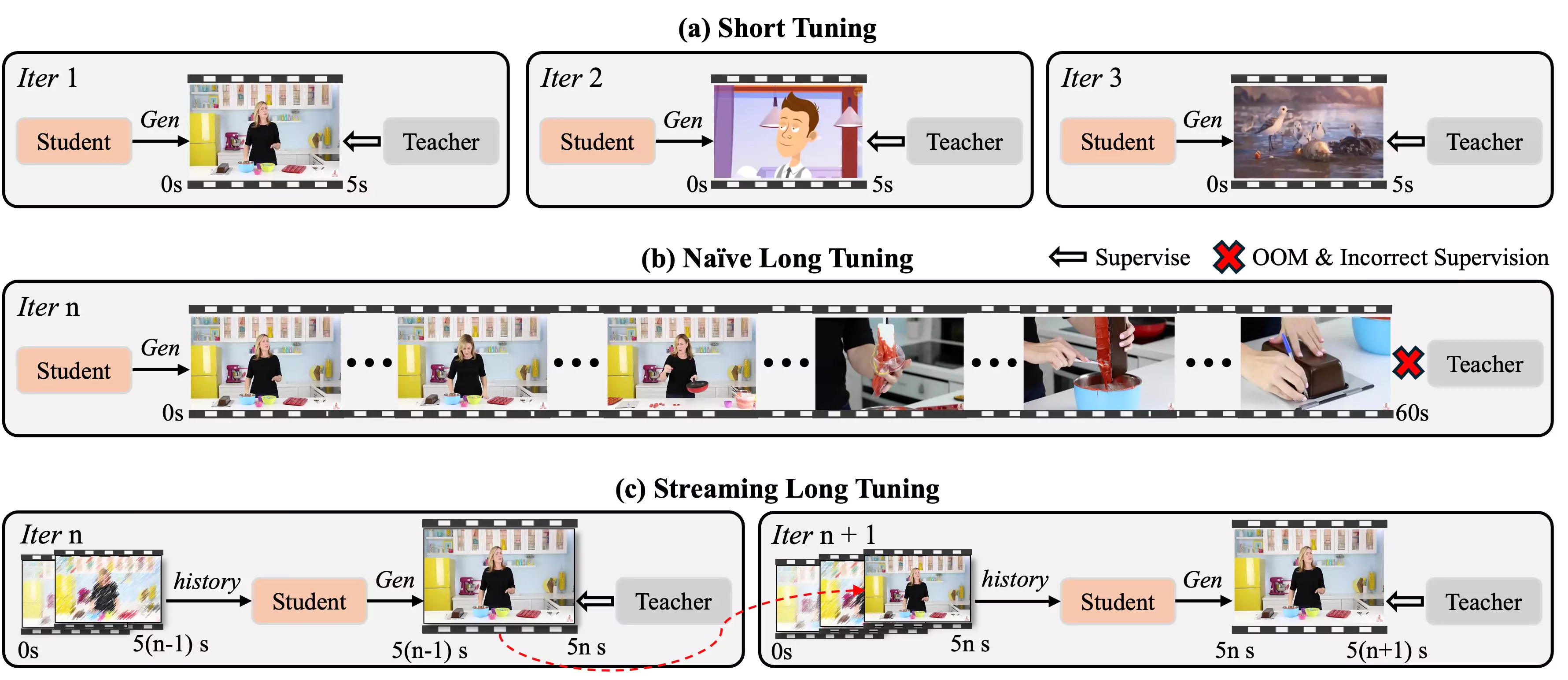
Causal AR design with KV refresh
LongLive’s core is an autoregressive generator that emits one frame at a time while conditioning on prior frames. It maintains a cache of key-value (KV) states for efficient reuse. When you change the prompt mid-sequence, a KV refresh mechanism updates cached states to match the new conditioning, allowing smooth transitions rather than abrupt context breaks.

Attention scheme and long-range coherence
Instead of relying on full-sequence attention that scales poorly with length, LongLive uses short-window attention paired with frame-level synchronization. This preserves long-range consistency by coordinating frame updates while keeping memory and compute in check. The result is a balanced approach: local detail is handled within windows, and cross-frame structure is sustained over time.
Training–inference alignment and streaming
The model is tuned for continuous generation (“streaming long tuning”), aligning its training regime with how it’s actually used. This reduces drift over minute-long outputs and improves stability during interactive prompting. Together with LoRA adaptation on VAN 2.1, the design focuses on reliable coherence and responsiveness at inference time.
How to use LongLive
Prerequisites
- Operating system:
- Linux (tested on Ubuntu).
- GPU:
- A100 or H100 recommended for long videos due to KV cache growth; 48 GB+ VRAM is advisable for multi-scene runs.
- Software:
- CUDA/CUDA Toolkit, PyTorch with CUDA support, and the repository’s Python dependencies.
- Accounts and tokens:
- Hugging Face account and a read token to download the base model and LongLive LoRA.
Step-by-step setup
-
Clone the repository:
git clone <longlive_repo_url>cd longlive
-
Create and activate a virtual environment:
python -m venv .venvsource .venv/bin/activate
-
Install prerequisites:
- Install the required CUDA/CUDA Toolkit and Python dependencies listed by the repository (pip install commands and torch with matching CUDA build).
- Expect 10–15 minutes or more for full setup depending on your system.
-
Log in to Hugging Face:
huggingface-cli login- Provide your read token from your Hugging Face profile.
-
Download the base model (VAN 2.1):
- Use Hugging Face CLI to pull VAN 2.1 locally (as specified in the repo instructions).
-
Download the LongLive LoRA:
- Use Hugging Face CLI again to fetch the LongLive adaptation weights.
-
Verify files:
- Ensure both the VAN 2.1 base and LongLive LoRA are present in the expected directories used by the inference scripts.
Running single-prompt inference
-
Use the provided inference script:
- A shell script calls the main
inference.py, sets up CUDA, loads the base model + LoRA, configures schedulers, and encodes outputs. - The pipeline handles preprocessing and postprocessing, including VAE operations.
- A shell script calls the main
-
Provide a prompt:
- You can specify a single textual description (e.g., camera movement, lighting, and scene details).
- Example structure: “A wide aerial shot of [scene]. Gentle camera pan. Cinematic lighting. Close-up of [detail].”
-
Monitor VRAM:
- Tools such as
nvtopcan show VRAM growth as frame generation proceeds; KV cache may push usage into the 20–40 GB range on longer runs.
- Tools such as
-
Find outputs:
- Generated videos are saved under
videos/longby default.
- Generated videos are saved under
Running interactive multi-prompt inference
-
Prepare a JSONL file:
- Each line contains a prompt (and optional timing/scene metadata; follow the repo’s format).
- You can define a series of scenes: entry, movement, transitions, spotlights, and closing shots.
-
Run the interactive script:
- The repo includes a bash script (e.g.,
bash interactive) that stitches segments and frames into a single video.
- The repo includes a bash script (e.g.,
-
Find outputs:
- Stitched results are stored under
interactive.
- Stitched results are stored under
Performance and hardware observations
-
GPU memory:
- During single and multi-scene runs, VRAM usage ranged from ~20 GB up to the mid-30s, occasionally touching ~40 GB when caches grew. That kept runs feasible on a 48 GB card for the tested lengths.
-
Throughput:
- The model targets ~20–25 FPS on an H100 for extended sequences; a 29-second clip took roughly 6–7 minutes to generate in one of my tests.
-
Stability:
- Long-form stability was reasonable for non-human scenes. Human-focused scenes showed weaknesses (notably eyes and facial fidelity), with occasional limb artifacts.
Results and observations
Single-prompt runs
-
Coastal city at sunset:
- A 29-second sequence featuring a wide aerial view and gentle camera pan. Visual quality was solid for a first pass, slightly soft at times.
-
Waves crashing on rocks:
- Water motion and foam looked convincing. Some rock surfaces appeared artificial, but overall physics were handled well for the scene length.
-
Night drone pass over neon-lit streets:
- Vibrant ambience with passable motion. Minor imperfections appeared during zoom transitions, but the overall clip held together over the full duration.
Human-focused prompts
- Runway catwalk (two prompts):
- Outputs were safe and coherent, but eyes often appeared unnatural or inconsistent. Limbs were mostly acceptable, though some malformations appeared in certain frames.
- The stage environment rendered well, and walking motion improved toward the end of segments. Facial fidelity and eye tracking remained the main deficiencies.
Interactive multi-scene stitching
- JSONL-driven runway sequence:
- The model generated a multi-part video stitched from successive prompts: entry from stage left, walking, turning, and a return segment.
- It sometimes deviated from exact scene instructions (e.g., unexpected wardrobe changes), and eye/face artifacts persisted. Still, transitions between segments were acceptable for a first attempt at multi-scene continuity.
Non-human object test
- Hourglass on a wooden desk:
- The model handled color, lighting, and particle detail (dust plumes, grain flow) with decent fidelity. It attempted close-ups and responded to camera direction.
- Some requested beats (like a full “fresh cycle”) were missed, but object consistency and micro-details looked stronger than in human-focused scenes.
FAQs
-
What GPU do I need to run LongLive locally?
- For long-form videos with interactive prompting and KV caches, A100 or H100 GPUs are recommended. In tests, VRAM usage ranged from ~20 GB to ~40 GB for minute-scale runs. A 48 GB card can be sufficient for many prompts.
-
How fast is generation?
- The target is around 20–25 FPS on an H100 for long sequences. In one run, generating a ~29-second clip took around 6–7 minutes.
-
Can I run multi-scene videos with transitions?
- Yes. Prepare a JSONL file with scene-by-scene prompts and run the provided interactive script. The tool stitches segments and frames into a single output video.
-
How well does the model follow instructions?
- It follows scene and camera directions reasonably well across non-human content. For human subjects, it may struggle with facial details and eye consistency, and occasionally deviates from strict scene instructions.
-
Do I need the base model installed separately?
- Yes. LongLive uses LoRA weights over the VAN 2.1 base model. You’ll download both via Hugging Face.
-
Where are outputs saved?
- Standard runs go to
videos/long. Interactive runs go tointeractive.
- Standard runs go to
-
What file handles prompting and configuration?
- The Python inference script loads configs, applies LoRA to the base model pipeline, and handles preprocessing/postprocessing, VAE, scheduling, and video encoding. Utilities include dataset code to build prompts and parse configurations.
-
Can I change prompts mid-generation?
- Yes. The model’s KV refresh mechanism is designed to handle prompt changes with smooth transitions while preserving overall coherence.
Conclusion
LongLive brings minute-scale, interactive video generation into practical local workflows. Its frame-level autoregressive design, KV refresh for prompt changes, and short-window attention with frame sync give it a workable balance: coherent long sequences with responsive inference.
In practice, the model handled non-human scenes well, produced workable transitions across prompts, and kept VRAM within a range that fits upper-tier consumer and data-center GPUs. Human-focused scenes exposed its current limits—especially eyes, facial fidelity, and occasional limb artifacts—yet overall motion and staging were serviceable.
With a 1.3B-parameter footprint, LoRA adaptation over VAN 2.1, and training aligned to streaming inference, LongLive is a clear step toward locally generated, minutes-long videos with scene-by-scene control. Expect improvements in instruction adherence and human fidelity as the base and fine-tuned components evolve.
Subscribe to our newsletter
Get the latest updates and articles directly in your inbox.

Related Posts

8 Best Claude Code Plugins in 2026 (You Need to Know)
8 Best Claude Code Plugins in 2026 (You Need to Know)

7 Best Claude Code Skills (You Need to Know)
7 Best Claude Code Skills (You Need to Know)

Claude Code Desktop IDE Features (You Need to Know)
Claude Code Desktop IDE Features (You Need to Know)